📄 Curriculum Learning with Contrastive Loss for Lightweight Speaker Verification
#说话人验证 #对比学习 #课程学习 #知识蒸馏
✅ 6.5/10 | 前25% | #说话人验证 | #对比学习 #课程学习 | #对比学习 #课程学习
学术质量 7.0/7 | 选题价值 6.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Jin Li(香港理工大学电机工程系)
- 通讯作者:未说明
- 作者列表:Jin Li(香港理工大学电机工程系;布尔诺理工大学Speech@FIT)、Man-Wai Mak(香港理工大学电机工程系)、Johan Rohdin(布尔诺理工大学Speech@FIT)、Oldřich Plchot(布尔诺理工大学Speech@FIT)
💡 毒舌点评
亮点:将课程学习思想精巧地应用于对比学习的负样本选择,并通过一个“教师网络”来量化和迁移“难度”,这一设计既直观又有效,避免了手动筛选困难负样本的武断。短板:论文的实验部分略显“安全牌”,主要验证了在VoxCeleb单一数据集上的有效性,且基线模型(如ECAPA-TDNN的轻量化版本)未得到充分讨论,使得“state-of-the-art”的宣称需要读者自行查阅更多文献才能完全确认。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:GitHub (https://github.com/happyjin/CurriNegAMS)。
- 模型权重:论文中未提及公开预训练模型权重。
- 数据集:实验使用公开的VoxCeleb1和VoxCeleb2数据集。
- Demo:未提供在线演示。
- 复现材料:论文详细说明了训练细节,包括特征提取(40维梅尔滤波器组)、数据增强(MUSAN, RIR)、优化器设置(Adam, lr=0.001, 5%/16epochs decay)、批量大小(200)、损失函数超参数(τ=0.1, m=0.3, s=30)以及节奏函数的选择。这些信息为复现提供了必要基础。
- 引用的开源项目:论文引用并使用了Fast ResNet34的官方实现(https://github.com/clovaai/voxceleb_trainer)。
📌 核心摘要
解决的问题:在资源受限的移动设备上部署说话人验证系统时,需要在模型轻量化(低参数量、低计算量)与高精度之间取得平衡。现有轻量级模型性能仍有提升空间,而标准对比学习在训练中对负样本的选择缺乏策略。
方法核心:提出CurriNeg-AMS训练框架。核心是CurriNeg课程策略:使用一个预训练的教师网络评估所有负样本相对于锚点的难度(余弦相似度),并通过一个节奏函数控制,在训练过程中由易到难地将负样本引入学生的对比学习损失(LCurriNeg)计算。同时,结合AM-Softmax损失(LCurriNeg-AMS)以增强类内紧凑性和类间可分性。
创新之处:不同于传统对比学习随机或基于启发式选择负样本,本文首次将课程学习系统地引入负样本选择,并通过教师-学生架构实现难度评估的迁移。这种“难度感知”的渐进式学习更符合认知规律,提升了学习效率。
主要实验结果:在VoxCeleb1测试集上,基于Fast ResNet34(1.4M参数)的CurriNeg-AMS将EER从基线的2.28%降低至1.82%(相对降低20.2%),优于包括Angular Prototypical loss在内的多种先进方法。消融实验表明,线性节奏函数效果最佳,且课程学习策略持续优于无课程的监督对比学习。
学生网络 训练集 损失函数 EER (%) minDCF TDNN Vox1-dev Softmax 4.92 0.327 TDNN Vox1-dev AM-Softmax 4.18 0.267 TDNN Vox1-dev AAM-Softmax 4.13 0.279 TDNN Vox1-dev CurriNeg-AMS (ours) 3.82 0.283 Fast ResNet34 Vox2-dev AM-Softmax 2.80 – Fast ResNet34 Vox2-dev AAM-Softmax 2.37 – Fast ResNet34 Vox2-dev Triplet 2.71 – Fast ResNet34 Vox2-dev GE2E 2.37 – Fast ResNet34 Vox2-dev Prototypical 2.32 – Fast ResNet34 Vox2-dev Angular Prototypical 2.22 – Fast ResNet34 Vox2-dev CurriNeg-AMS (ours) 1.82 0.131 表2:不同损失函数在TDNN和Fast ResNet34上的性能对比(论文Table 2) 实际意义:为训练高效、高精度的轻量级说话人验证模型提供了一个新颖且有效的训练框架,有助于推动说话���识别技术在智能手机、IoT设备等端侧的广泛应用。
主要局限性:实验验证集中于VoxCeleb数据集,模型在更复杂噪声环境、跨语言场景或极低资源条件下的泛化能力未被探讨。此外,引入教师网络进行预训练和难度评估,增加了整体训练流程的复杂性和初始成本。
🏗️ 模型架构
本文并未提出全新的神经网络架构,而是专注于一种新颖的训练策略。其核心框架围绕一个教师-学生(Teacher-Student) 架构展开,用于实施课程学习。完整流程如下:
- 输入:原始波形或声学特征(40维梅尔滤波器组)。
- 教师网络:一个预先训练好的说话人编码器(Encpre(·)),架构与学生网络相同(论文中使用了TDNN with ASP和Fast ResNet34)。该网络参数在课程学习阶段被冻结。
- 难度评估与负样本选择:
- 对于每个小批次中的锚点xi和一批负样本xa,教师网络分别计算它们的嵌入zpre_i和zpre_a。
- 计算每个锚点-负样本对的余弦相似度作为难度分数 Si(公式4)。分数越高(越相似),负样本越难。
- 根据难度分数对所有负样本进行排序(从易到难)。
- 根据一个节奏函数 f(t)(如线性、指数、对数函数)确定当前训练轮次t使用的负样本数量Q。
- 从排序列表中选取最容易的Q个负样本的索引,形成集合 ZCL(i)。
- 学生网络:一个待训练的说话人编码器(gθ),架构与教师网络相同。它接收来自教师网络的负样本索引 ZCL(i)。
- 损失计算与优化:
- 学生网络使用原始输入的增强视图计算嵌入z_i, z_p, z_n。
- 学生网络根据教师指定的索引 ZCL(i) 计算课程监督对比损失 LCurriNeg(公式2)。该损失的分母仅包含正样本和由教师选出的Q个“特定难度”的负样本。
- 同时,计算AM-Softmax损失 LAM-Softmax(公式7),其需要所有类(说话人)的权重矩阵。
- 总损失 LCurriNeg-AMS = LCurriNeg + LAM-Softmax(公式6)。
- 输出:优化后的学生网络参数θ,以及其产生的说话人嵌入z,用于后续验证(通过余弦评分)。
架构图引用与说明:
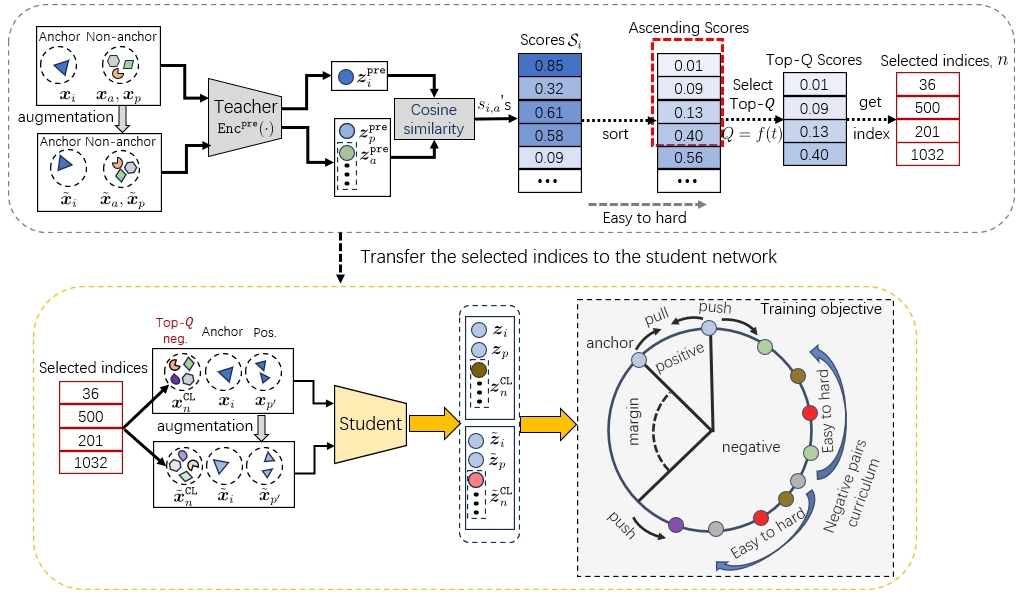 图2详细展示了上述流程:教师网络提取锚点和负样本的嵌入,计算相似度得分并排序,根据节奏函数选择Q个最容易的样本,将索引传递给学生网络,学生网络利用这些负样本计算损失并反向传播。
图2详细展示了上述流程:教师网络提取锚点和负样本的嵌入,计算相似度得分并排序,根据节奏函数选择Q个最容易的样本,将索引传递给学生网络,学生网络利用这些负样本计算损失并反向传播。
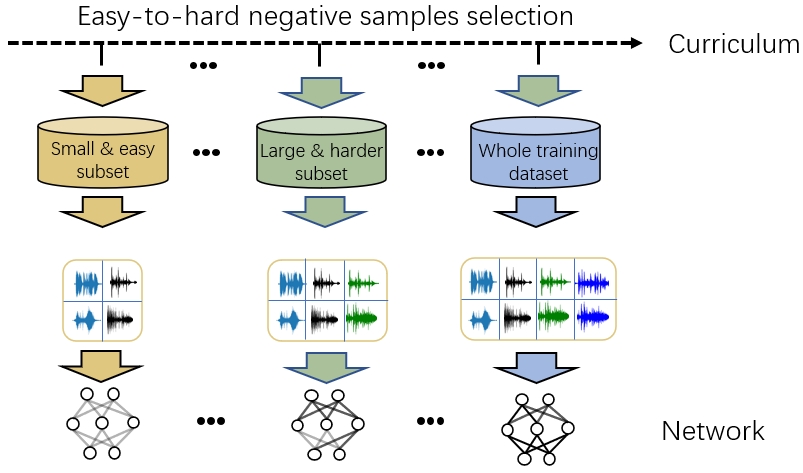 图1直观地说明了课程学习的理念:训练初期只使用少量、容易的负样本,随着训练进行,逐渐引入越来越难的负样本,最后使用全部数据。
图1直观地说明了课程学习的理念:训练初期只使用少量、容易的负样本,随着训练进行,逐渐引入越来越难的负样本,最后使用全部数据。
💡 核心创新点
- CurriNeg课程学习策略:这是最核心的创新。它改变了对比学习中负样本的随机采样范式,提出了一种“由易到难”的渐进式引入机制。通过控制学习难度,使模型先建立粗粒度的判别能力,再专注于区分困难样本,提升了学习稳定性和最终性能。
- 基于教师网络的难度评估与迁移:为课程学习提供了具体实现方案。利用一个能力强的预训练教师网络来客观、量化地评估负样本的“难度”,并将这一“知识”(即样本排序)迁移给学生网络。这比使用启发式规则(如仅基于距离)更可靠,且避免了在训练中动态评估带来的计算开销。
- CurriNeg-AMS损失融合:将CurriNeg损失与AM-Softmax损失相结合。LCurriNeg专注于优化批次内的相对对比关系(拉近正样本,推远特定负样本),而LAM-Softmax则利用全局的说话人类别信息来优化绝对的类间角度间隔。二者互补,共同增强了嵌入空间的判别力。
- 对节奏函数的系统研究:论文不仅提出了方法,还通过实验系统地探讨了不同节奏函数(线性、对数、指数)以及节奏步数对性能的影响,为该方法的实际应用提供了有价值的超参数选择指导。
🔬 细节详述
- 训练数据:
- 数据集:VoxCeleb2开发集(用于训练Fast ResNet34);VoxCeleb1开发集(用于训练TDNN)。
- 预处理:使用40维梅尔滤波器组特征。
- 数据增强:采用MUSAN噪声库和RIR(房间冲激响应)进行数据增强。
- 损失函数:
- LCurriNeg (公式2):监督对比损失的变体。分母中包含正样本和由课程策略选出的Q个负样本。温度参数τ=0.1。
- LAM-Softmax (公式7):加性间隔Softmax损失。使用边距m=0.3,尺度s=30。
- 总损失:LCurriNeg-AMS = LCurriNeg + LAM-Softmax。两项损失的权重未明确说明,应默认为等权重相加。
- 训练策略:
- 优化器:Adam优化器,初始学习率lr=0.001。
- 学习率衰减:每16个epoch衰减5%。
- 批量大小:200。
- 教师网络预训练:教师网络使用监督对比损失和AMS损失的组合进行预训练,之后参数冻结。
- 课程进度:通过节奏函数f(t)控制负样本数量Q。论文测试了线性(Q=t * 步长)、对数(Q=log(t))和指数(Q=exp(t))函数。具体步长和最大Q值未在正文中给出。
- 关键超参数:
- 模型架构:TDNN with ASP(4.5M参数,2.07G MACs), Fast ResNet34(1.4M参数,0.45G MACs)。
- 评估指标:EER(等错误率), minDCF(最小检测代价函数)。
- 训练硬件:论文中未提及具体的GPU型号、数量或训练时长。
- 推理细节:使用余弦评分作为后端。
- 正则化/稳定训练技巧:未明确提及除数据增强外的其他特定技巧。
📊 实验结果
论文在VoxCeleb数据集上进行了充分的实验,主要结果如下表所示:
| 表1:监督对比损失与课程对比损失的对比 | ||||
|---|---|---|---|---|
| 学生网络 | 训练集 | 是否使用SupConLoss | 是否使用CurriNeg | EER (%) |
| TDNN | Vox1-dev | ✗ | ✗ | 4.18 |
| TDNN | Vox1-dev | ✓ | ✗ | 4.09 |
| TDNN | Vox1-dev | ✗ | ✓ | 3.82 |
| Fast ResNet34 | Vox2-dev | ✗ | ✗ | 2.28 |
| Fast ResNet34 | Vox2-dev | ✓ | ✗ | 2.15 |
| Fast ResNet34 | Vox2-dev | ✗ | ✓ | 1.82 |
| 表1:引入课程学习策略(CurriNeg)后,EER均有显著下降(论文Table 1) |
| 表3:不同节奏函数的消融实验 | ||||
|---|---|---|---|---|
| 学生网络 | 训练集 | 节奏函数 | EER | minDCF |
| TDNN | Vox1-dev | ✗ (无课程) | 4.09 | 0.295 |
| TDNN | Vox1-dev | 指数 | 4.09 | 0.292 |
| TDNN | Vox1-dev | 对数 | 4.00 | 0.270 |
| TDNN | Vox1-dev | 线性 | 3.82 | 0.283 |
| Fast ResNet34 | Vox2-dev | ✗ (无课程) | 2.15 | 0.151 |
| Fast ResNet34 | Vox2-dev | 指数 | 1.94 | 0.130 |
| Fast ResNet34 | Vox2-dev | 对数 | 2.10 | 0.148 |
| Fast ResNet34 | Vox2-dev | 线性 | 1.82 | 0.131 |
| 表3:线性节奏函数在两种架构上均取得最佳性能(论文Table 3) |
| 表4:与SOTA轻量级模型的对比 | ||||
|---|---|---|---|---|
| 模型 | 参数量 | 损失函数 | EER | minDCF |
| Thin HypResNet-34 | 0.72M | Poincare triplet | 10.96 | – |
| Fast ResNet-34 | 1.4M | Normalised prototypical | 2.09 | 0.156 |
| ResNet34-TM | 1.97M | AAM-Softmax | 3.14 | – |
| ECAPA-TDNN-TM | 0.89M | AAM-Softmax | 1.92 | – |
| Fast ResNet-34 | 1.4M | Contrastive-mixup loss | 2.11 | – |
| DenseNet-based | 1.2M | AM-Softmax | 1.94 | – |
| Thin ResNet-34 | 1.4M | Angular Prototypical | 2.21 | – |
| AMCRN-TM | 1.76M | AAM-Softmax | 1.90 | – |
| Fast ResNet-34 | 1.4M | CBRW-BCE | 1.94 | 0.150 |
| Fast ResNet-34 | 1.4M | CurriNeg-AMS (ours) | 1.82 | 0.131 |
| 表4:在Fast ResNet34架构下,CurriNeg-AMS取得了最优的EER(1.82%)和minDCF(0.131)(论文Table 4) |
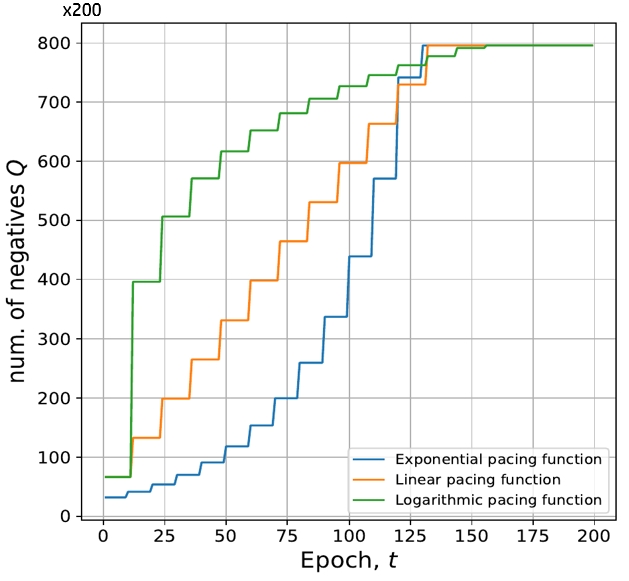 图3展示了三种节奏函数Q=f(t)随epoch增长的趋势:指数增长最快,线性居中,对数最慢。
图3展示了三种节奏函数Q=f(t)随epoch增长的趋势:指数增长最快,线性居中,对数最慢。
(论文中同一页面)
图4(右)显示了线性节奏函数中“步数”(staircase steps)对EER的影响。存在一个最优值(约20步),步数过少或过多都会导致性能下降。
关键结论:
- 课程学习(CurriNeg)相比标准监督对比学习,在两种架构上均带来显著且一致的性能提升。
- 结合AM-Softmax损失后,CurriNeg-AMS在轻量级模型(Fast ResNet34)上取得了当前最优(SOTA)的性能(EER 1.82%)。
- 线性节奏函数被证明是最有效的课程进度策略。
- 节奏函数的超参数(如步数)对性能有重要影响,需要仔细调整。
⚖️ 评分理由
- 学术质量 (5.0/7):创新性良好,提出了一个逻辑自洽且有效的训练框架;技术实现正确,实验设计合理,包含对比实验和消融实验;实验结果证据可信,数值改善明显。扣分点在于创新主要集中在训练策略,且实验场景相对单一。
- 选题价值 (1.5/2):选题切中移动端语音智能的实际痛点,具有明确的应用价值。方法本身(课程对比学习)具有可迁移性。
- 开源与复现加成 (0.5/1):提供了代码仓库,详细列出了网络架构、数据增强方法、关键超参数(温度、AMS参数)以及节奏函数的设计选择,使得复现较为可行。未提供预训练模型权重。