📄 CTC-DID: CTC-Based Arabic Dialect Identification for Streaming Applications
#语音识别 #自监督学习 #低资源 #流式处理 #数据增强
✅ 6.5/10 | 前50% | #语音识别 | #自监督学习 | #低资源 #流式处理
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Muhammad Umar Farooq (Emotech Ltd., UK)
- 通讯作者:未说明
- 作者列表:Muhammad Umar Farooq (Emotech Ltd., UK), Oscar Saz (Emotech Ltd., UK)
💡 毒舌点评
亮点在于极具创意地将ASR的CTC范式“移植”到方言识别任务中,实现了对短语音的鲁棒性和天然的流式支持,是一个优雅的“降维打击”。然而,论文对模型训练的关键细节(如优化器、学习率、batch size)惜墨如金,使得复现其优异结果如同“盲人摸象”,大大削弱了学术贡献的可验证性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及是否公开预训练或微调后的模型权重。
- 数据集:使用了公开的ADI-17和Casablanca数据集,但未说明如何获取或处理。
- Demo:未提供在线演示。
- 复现材料:论文给出了算法伪代码(Algorithm 1)和部分超参数(如模型维度、测试的chunk size),但缺少优化器、学习率、batch size等关键训练细节,不足以完全复现。
- 论文中引用的开源项目:引用了Silero VAD [13]用于语音活动检测。
- 总结:论文中未提及任何开源计划,主要依赖对公开数据集的实验和引用的开源工具。
📌 核心摘要
这篇论文旨在解决阿拉伯语方言识别(DID)在流式应用场景下的挑战,包括对短语音的处理和实时性要求。其核心方法是将DID任务重新定义为一个有限词汇的自动语音识别(ASR)问题,使用连接主义时序分类(CTC)损失进行模型训练。具体地,为每段语音生成由目标方言标签重复多次构成的“转录文本”,重复次数通过轻量级语言无关启发式(LAH)或预训练ASR模型估算。与传统的基于整句嵌入(如ECAPA-TDNN)或固定窗口处理(如Whisper)的方法不同,CTC-DID能够产出帧级别的方言标签序列,从而支持流式推理并处理包含语码转换的语音。主要实验结果显示,基于mHuBERT的CTC-DID模型在仅使用10小时/方言的有限数据训练时,在ADI-17测试集上F1分数达86.98%(微调SSL),显著优于Whisper-medium(92.88%使用全量数据训练)和ECAPA-TDNN(28.71%)。在Casablanca数据集的零样本评估中,CTC-DID(56.02%)同样大幅超越Whisper-medium(使用全量数据训练后为53.84%)。该方法的实际意义在于为资源受限的场景提供了高效、可流式的方言识别解决方案。其主要局限性在于未公开完整的训练细节和模型代码,且LAH方法的普适性有待更多语言验证。
主要实验结果表格(表1):
| 方法 | 训练数据 | ADI-17 (F1) | Casablanca (F1) |
|---|---|---|---|
| 10-hour (per dialect) training | |||
| Whisper-medium | 全量数据(引用[8]) | 92.88 | - |
| ECAPA-TDNN | 10小时/方言 | 28.71 | 10.18 |
| Whisper-base | 10小时/方言 | 65.05 | 32.23 |
| CTC-DID (冻结SSL) | 10小时/方言 | 77.34 | 51.36 |
| CTC-DID (微调SSL) | 10小时/方言 | 86.98 | 56.02 |
| 50-hour (per dialect) training | |||
| Whisper-medium | 全量数据(引用[8]) | 95.29 | - |
| CTC-DID (冻结SSL) | 50小时/方言 | 93.58 | 58.12 |
| CTC-DID (微调SSL) | 50小时/方言 | 96.01 | 60.23 |
| Full-data training | |||
| Whisper-medium | 全量数据(引用[8]) | 95.46 | 53.84 |
| Hubert | 引用[15] | - | 39.24 |
相关图表描述:
- 图2: 展示了不同模型在测试语音时长缩短时的相对F1分数下降情况。CTC-DID模型的曲线在所有时长阈值下(3-15秒)都处于最下方,表明其性能衰减最小,对短语音最鲁棒。
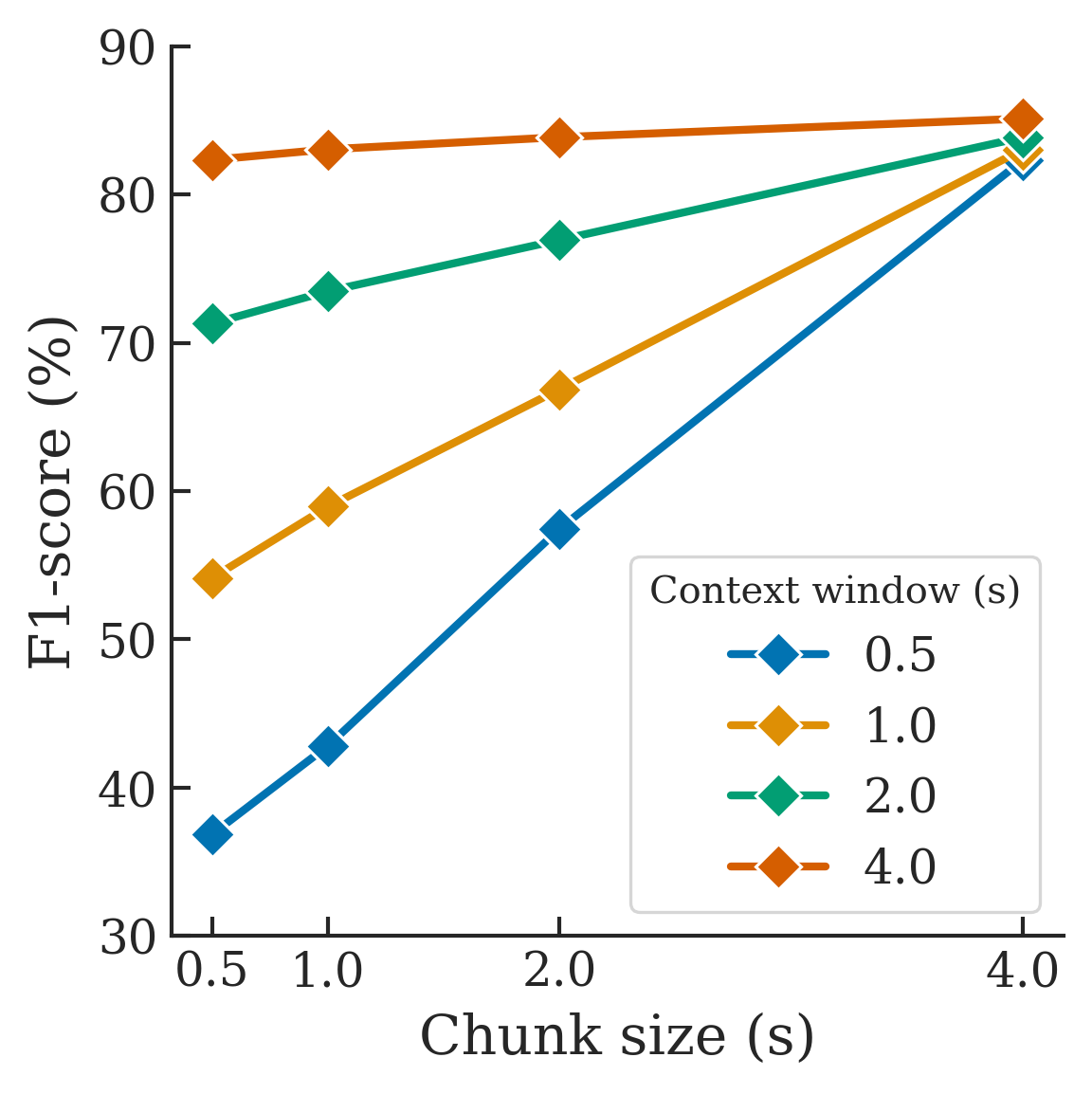
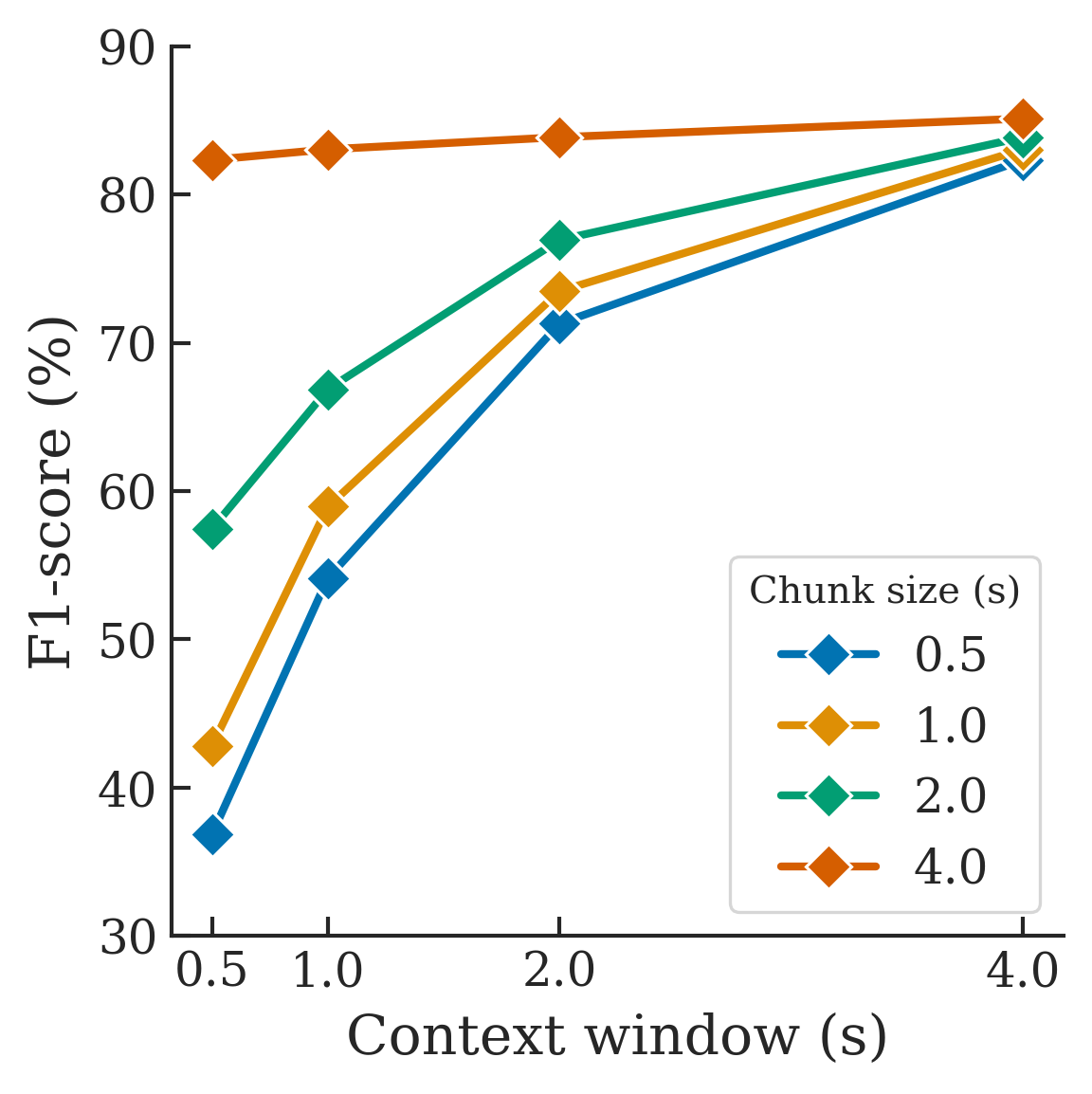
- 图3: 展示了流式推理中,不同音频块大小(chunk size)和上下文窗口(context window)组合对F1分数的影响。图3(a)表明,对于固定chunk size,增大context window能指数级提升性能;图3(b)表明,总窗口(chunk + context)大于4秒时,流式F1分数(82.34)已接近全句推理(86.98)。
🏗️ 模型架构
模型整体架构分为编码器、下游任务头和CTC解码器三部分。
- 输入与编码器:输入为原始音频波形。使用预训练的mHuBERT(119M参数)作为自监督学习(SSL)编码器。其核心是一个Transformer编码器,将输入的音频信号编码为高层特征表示。在训练阶段,该编码器的权重可以选择冻结或与下游头联合微调。
- 下游任务头:在SSL编码器之上,连接一个基于Transformer的分类头(25M参数)。该头包含4个Transformer块(模型维度768,前馈维度2048,8个注意力头)。其输入是SSL编码器的输出帧序列,输出是每个时间步上对应于所有方言标签(加一个空白符号
<blank>)的logits分数。 - CTC损失训练:训练时,对于一段语音,其目标序列
Y由单一的方言标签重复L次构成(L由LAH或ASR估算)。模型输出logits序列X与目标Y通过CTC损失函数进行对齐和训练。CTC允许模型在不知道精确帧-标签对齐的情况下进行学习,鼓励模型在每个时间步都输出正确的方言标签。 - 推理与解码:在推理时,模型输出整个语音的logits序列。采用CTC解码(本文仅使用贪心解码),得到一条由方言标签和
<blank>符号组成的序列。最后,通过一个简单的后处理步骤:统计序列中各方言标签(去除<blank>和重复符号后)出现的频率,选择出现次数最多的标签作为最终的整句方言预测结果。
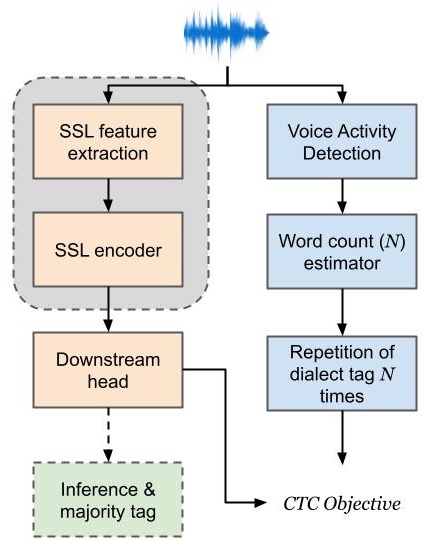
- 图1说明:清晰展示了上述流程。输入音频经过冻结或可微调的SSL编码器(如mHuBERT),再经过Transformer任务头,得到帧级logits。训练阶段使用CTC损失计算目标(重复的方言标签)。推理阶段,经过CTC解码和频率投票,输出最终的方言标签。图中灰色框内的组件(SSL编码器和Transformer头)是可配置为冻结或微调的训练部分,绿色框为推理流水线。
💡 核心创新点
- 将方言识别重构为序列预测问题:创新点:首次将CTC损失引入方言识别,将其建模为“有限词汇ASR”问题。之前局限:传统ECAPA-TDNN等方法将语音聚合为单个向量后进行分类,丢失了时序细节,且无法处理流式输入或语码转换。如何起作用:通过重复标签构建目标序列,使模型学习为每个音频帧分配方言标签。收益:获得了帧级预测能力,支持流式推理,理论上可处理同一语音中不同方言的切换。
- 提出语言无关的启发式(LAH)数据标注方法:创新点:提出了一种无需依赖特定语言ASR系统来估算语音中单词数(即标签重复次数)的轻量级方法。之前局限:使用ASR系统计数词数虽然准确,但限制了方法的可移植性(需要该语言的ASR)。如何起作用:利用Silero VAD模型检测语音活动时长,然后假设一个固定的语速(如5词/秒)来估算词数。收益:使CTC-DID框架更具语言通用性,且实验表明性能与ASR方法相当。
- 实现对短语音和流式场景的鲁棒性与支持:创新点:由于模型在帧级别进行预测,不强制要求使用完整语音片段。之前局限:Whisper需要固定30秒窗口,ECAPA-TDNN需要整个语音段来提取嵌入,两者在短语音上性能都会下降,且难以高效用于流式。如何起作用:帧级CTC输出允许随时做出局部预测;流式推理通过重叠音频块(Algorithm 1)实现。收益:实验证明CTC-DID在短语音上相对性能下降最小,且流式模式(总窗口>4秒)性能接近离线模式。
🔬 细节详述
- 训练数据:主要使用ADI-17数据集。实验中使用了“有限资源”设置:10小时/方言和50小时/方言的子集进行训练。对于数据量不足的方言(也门、摩洛哥、约旦),使用速度扰动(speed perturbation) 进行数据增强至目标时长。验证集为每方言30分钟的平衡子集。评估集为完整的ADI-17测试集和Casablanca数据集(用于零样本评估)。
- 损失函数:连接主义时序分类(CTC)损失。它用于计算模型输出的logits序列与目标标签序列(重复的方言标签)之间的损失,核心作用是处理输入序列(音频帧)与输出标签序列之间的对齐不确定性。
- 训练策略:论文提到所有模型训练了大约100K步。未说明学习率、优化器、batch size、warmup策略、调度策略等关键超参数。未说明是否使用了标签平滑或其他正则化技巧。
- 关键超参数:
- 模型参数量:SSL编码器(mHuBERT)119M参数,Transformer任务头25M参数。
- Transformer任务头:4层,模型维度768,前馈维度2048,8个注意力头。
- 流式推理:块大小(c)和上下文窗口(l)测试了0.5, 1.0, 2.0, 4.0秒的组合。
- 训练硬件:论文中未提及具体的GPU/TPU型号、数量及训练时长。
- 推理细节:离线推理使用贪心CTC解码。流式推理采用Algorithm 1描述的重叠块方法,每个块包含当前块(c秒)和左上下文(l秒),仅保留当前块对应的输出帧logits进行拼接,最终对拼接后的整个logits序列进行贪心解码和频率投票。
- 正则化或稳定训练技巧:论文中未提及明确的正则化技巧(如Dropout, Weight Decay等)。数据增强方面,使用了速度扰动。
📊 实验结果
主要结果(表1已列出): 在低资源(10小时/方言)训练下,CTC-DID(微调SSL)在ADI-17上达到86.98% F1,显著高于使用相同数据量训练的Whisper-base(65.05%)和ECAPA-TDNN(28.71%),并接近于使用全量数据训练的Whisper-medium(92.88%)。在零样本Casablanca评估中,CTC-DID(56.02%)大幅领先于Whisper-base(32.23%),也高于使用全量数据训练的Whisper-medium(53.84%)。增加训练数据到50小时/方言,CTC-DID(微调SSL)在ADI-17上达到96.01% F1,超过了使用全量数据训练的Whisper-medium(95.46%)。
消融实验与分析:
- 数据准备方法对比(表2):使用LAH方法与使用ASR方法准备训练数据,训练出的模型性能相近(ADI-17: 77.34% vs 79.35%),证明LAH方法有效且可替代ASR。
数据准备方法 ADI-17 (F1) Casablanca (F1) LAH 77.34 51.36 ASR 79.35 51.84 - 短语音鲁棒性(图2):CTC-DID模型在所有评估的时长阈值(≤3秒至≤15秒)下,F1分数的相对下降率都是最低的,证明其鲁棒性最强。
- 图2说明:纵轴为F1分数相对下降率,横轴为语音时长阈值。CTC-DID(微调SSL)曲线最低且最平缓,说明其对短语音的性能影响最小。
- 流式推理性能(图3):探索了不同流式配置。关键发现是:随着上下文窗口(context)增加,性能呈指数提升(图3a);随着块大小(chunk)增加,性能呈线性提升(图3b)。当总窗口(chunk+context)大于4秒时,流式F1分数达到82.34,与离线推理的86.98接近。
- 图3a说明:不同chunk size下,F1分数随context window增大的变化。曲线表明增大上下文能快速提升性能。

- 图3b说明:不同context window下,F1分数随chunk size增大的变化。曲线更趋于线性。
- 图3a说明:不同chunk size下,F1分数随context window增大的变化。曲线表明增大上下文能快速提升性能。
- SSL编码器冻结 vs 微调:在所有设置下,微调SSL编码器(“+ fine-tuned SSL”)的性能都优于仅使用其作为特征提取器(冻结)。
⚖️ 评分理由
- 学术质量:5.5/7 - 创新性突出,将CTC框架成功应用于方言识别并取得了有说服力的实验结果。但训练过程的关键技术细节严重缺失,影响了工作的严谨性和可复现性。实验对比充分,证据可信。
- 选题价值:1.5/2 - 解决的是阿拉伯语方言识别这一具体且重要的任务,提出的流式和短语音解决方案具有明确的应用价值。但任务相对垂直,属于语音处理的特定子领域。
- 开源与复现加成:-0.5/1 - 论文完全没有提供代码、模型或复现所需的详细配置,是当前学术交流中的一大遗憾,因此给予负分。