📄 Cross-Architecture Knowledge Distillation of WavLM for Lightweight Speaker Verification
#说话人验证 #知识蒸馏 #自监督学习 #模型压缩 #语音表示学习
🔥 8.0/10 | 前25% | #说话人验证 | #知识蒸馏 | #自监督学习 #模型压缩
学术质量 6.5/7 | 选题价值 7.0/2 | 复现加成 8.0 | 置信度 高
👥 作者与机构
- 第一作者:Jungwoo Heo (University of Seoul, Republic of Korea)
- 通讯作者:Ha-Jin Yu (University of Seoul, Republic of Korea)
- 作者列表:Jungwoo Heo (University of Seoul, Republic of Korea)、Hyun-seo Shin (University of Seoul, Republic of Korea)、Chan-yeong Lim (University of Seoul, Republic of Korea)、Kyowon Koo (University of Seoul, Republic of Korea)、Seung-bin Kim (University of Seoul, Republic of Korea)、Jisoo Son (University of Seoul, Republic of Korea)、Kyung Wha Kim (Supreme Prosecutors’ Office Republic of Korea)、Ha-Jin Yu (University of Seoul, Republic of Korea)
💡 毒舌点评
这篇论文精准地切中了当前自监督语音模型“大而不能用”的痛点,其提出的任务引导学习(TGL)和代理对齐蒸馏(PAD)组合拳,确实为异构架构间的知识传递提供了系统化的解决方案,在VoxCeleb和VoxSRC等标准基准上取得了令人印象深刻的性能提升。然而,实验部分主要围绕其自身方法的变体展开,与当前最前沿的、同样专注于轻量化或高效说话人验证的最新方法(如2025年的SEED, LAP等)的横向对比深度稍显不足,使得其“最佳”地位的论证链条不够完整。
🔗 开源详情
- 代码:论文中明确提供了代码仓库链接:https://github.com/Jungwoo4021/SV-Mixer-TGL-PAD。
- 模型权重:论文提及“pretrained models are available”,表明计划或已经开源模型权重。
- 数据集:使用的是公开数据集VoxCeleb1/2, MUSAN等,但论文未提及新的数据集。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了详尽的训练细节、配置、关键超参数,足以支持复现。未提及是否提供具体的检查点或附录。
- 论文中引用的开源项目:WavLM [1], ECAPA-TDNN(作为后端,论文未直接引用但SV-Mixer原始工作使用), AAM-Softmax [19]。
📌 核心摘要
- 解决的问题:基于Transformer的大规模自监督学习(SSL)模型(如WavLM)在说话人验证任务上表现优异,但其高昂的计算成本严重限制了在移动和嵌入式设备上的部署。现有压缩方法大多保留Transformer骨干,无法根本解决效率问题。
- 方法核心:提出首个用于说话人验证的跨架构知识蒸馏系统框架,将知识从基于Transformer的教师模型(WavLM-Large)蒸馏到基于MLP-Mixer的学生模型(SV-Mixer)。框架包含两个互补组件:任务引导学习(TGL) 通过自适应聚合教师中间层信息,构建富含说话人判别性的监督信号;代理对齐蒸馏(PAD) 通过约束帧级表征的协方差结构,弥合不同架构间的表示差异。
- 创新��处:相较于之前工作(如SV-Mixer)直接沿用同构蒸馏方法,本工作首次系统性地研究并设计了针对异构架构(Transformer vs. MLP-Mixer)的蒸馏策略,明确将跨架构蒸馏作为独立问题处理。
- 主要实验结果:在VoxCeleb1、VCMix、VoxSRC和VOiCES四个测试集上,结合TGL和PAD的完整框架相比基线(SV-Mixer)取得了显著且一致的改进,相对EER降低幅度分别为11.94%、18.22%、8.17%和11.71%。80M参数的17层学生模型在VoxCeleb-O上达到0.58% EER,接近参数量更大的Transformer SOTA模型性能。
关键实验结果表1:组件消融实验 (VoxCeleb1)
| 模型配置 | Vox EER (%) | VCMix EER (%) | VoxSRC EER (%) | VOiCES EER (%) |
|---|---|---|---|---|
| Baseline | 2.18(±0.04) | 6.42(±0.22) | 4.52(±0.10) | 10.98(±0.20) |
| +TGL | 2.11(±0.01) | 5.92(±0.17) | 4.30(±0.13) | 10.49(±0.12) |
| +PAD | 2.11(±0.01) | 6.15(±0.13) | 4.51(±0.11) | 9.99(±0.33) |
| +TGL, PAD | 1.92(±0.06) | 5.25(±0.30) | 4.15(±0.16) | 9.54(±0.23) |
关键实验结果表2:不同压缩比下的性能 (图3总结)
| 压缩策略 | 相对基线性能 |
|---|---|
| 减半通道数(蓝线) | 在各压缩比下均优于基线压缩方法,EER更低 |
| 减少深度(橙线) | 在激进压缩(25-50%)时表现尤为突出,EER最低 |
| 基线压缩方法(绿线) | 在高压缩比下性能下降更严重,EER更高 |
关键实验结果表3:与SOTA模型对比
| 模型 | 参数量 (M) | Vox-O EER (%) | VCMix EER (%) | VoxSRC EER (%) | VOiCES EER (%) |
|---|---|---|---|---|---|
| WavLM (2022) | 100.0 | 0.84 | N/A | N/A | N/A |
| LAP (2025) | 96.3 | 0.61 | N/A | N/A | N/A |
| SEED (2025) | 105.6 | 0.81 | 2.29 | 4.94 | N/A |
| SV-Mixer (2025) | 80.3 | 0.78 | 3.29 | 4.89 | 7.85 |
| Ours (17 layer) | 80.0 | 0.58 | 2.34 | 3.98 | 7.11 |
 图2展示了在PAD损失中使用和不使用停止梯度操作时,可学习权重α在学生模型各层的分布。不使用停止梯度时(左图),权重坍缩至单一层;使用后(右图),权重分布更均衡,表明多层均参与学习。
图2展示了在PAD损失中使用和不使用停止梯度操作时,可学习权重α在学生模型各层的分布。不使用停止梯度时(左图),权重坍缩至单一层;使用后(右图),权重分布更均衡,表明多层均参与学习。
- 实际意义:该工作为在资源受限设备上部署高性能说话人验证系统提供了一条有效路径。它证明了通过精心设计的蒸馏策略,轻量级、硬件友好的注意力无关模型(如MLP-Mixer)可以从大型SSL模型中有效继承判别能力,推动了高效语音表征学习的发展。
- 主要局限性:论文中验证的异构组合主要是WavLM (Transformer) 到 SV-Mixer (MLP)。该框架对其他异构组合(如Transformer到CNN、或Mamba等其他新兴架构)的有效性有待验证。实验对比主要集中在与自身变体的比较,与更多最新SOTA方法的横向对比不够充分。
🏗️ 模型架构
本文提出的是一个知识蒸馏框架,而非一个全新的学生模型架构。框架的核心是在训练时连接教师模型(WavLM-Large)和学生模型(SV-Mixer),并在训练后移除教师,仅保留轻量的学生模型用于推理。
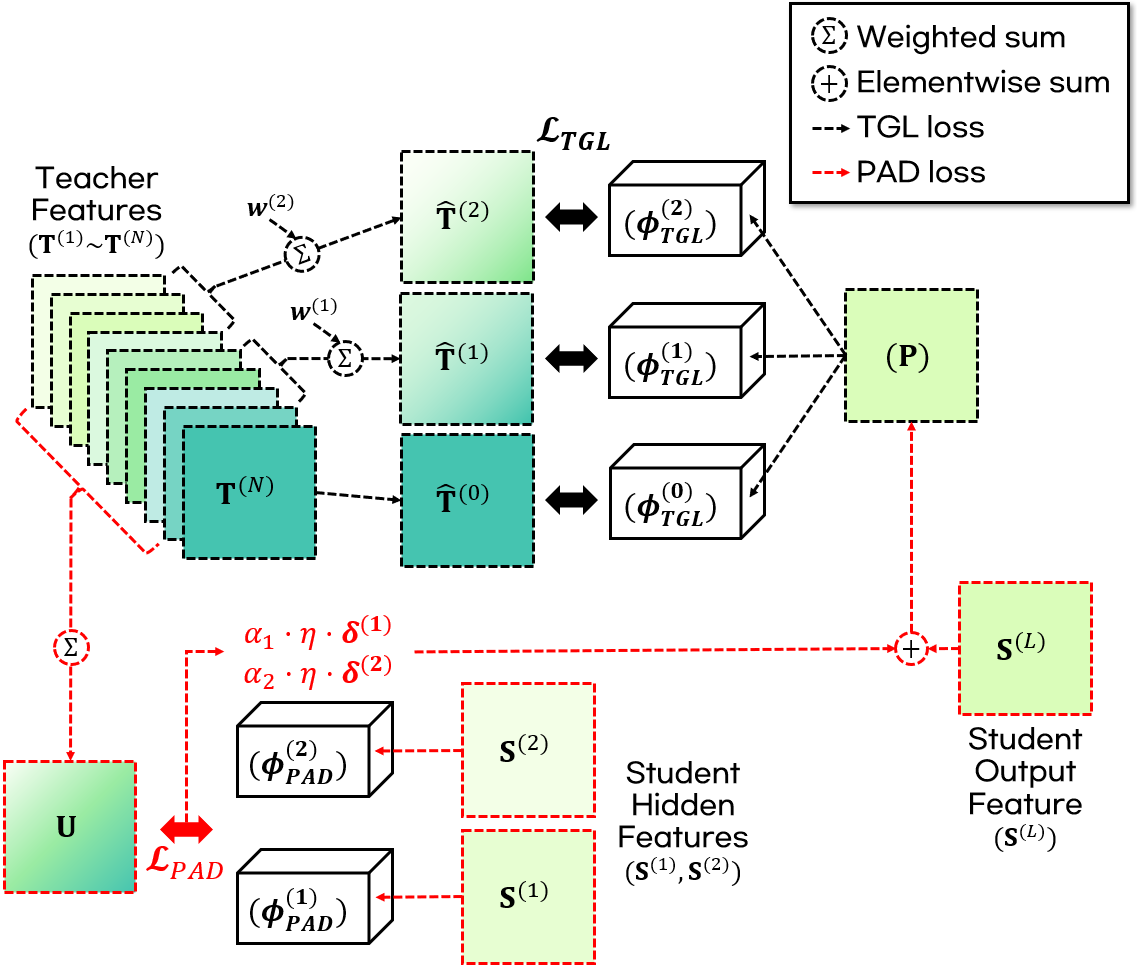 图1展示了完整的框架。左侧为N层的Transformer教师模型,右侧为L层(示例为3层)的MLP-Mixer学生模型。核心数据流包括:(1) 教师产生K+1个监督信号(黑色虚线):最后一个输出层T(N)作为第一个信号,其余N-1层被分成K段,每段通过可学习权重加权聚合为一个信号。(2)学生层输出通过投影头ϕ^{(j)}{PAD}与教师的加权组合U进行协方差对齐(红色虚线),并计算梯度信号δ^{(j)}。(3) 将这些梯度信号加权求和后,从学生最终层输出S(L)中减去,得到代理调整表征P。(4) P通过投影头ϕ^{(k)}{TGL}分别与K+1个教师监督信号进行对齐,计算TGL损失。
图1展示了完整的框架。左侧为N层的Transformer教师模型,右侧为L层(示例为3层)的MLP-Mixer学生模型。核心数据流包括:(1) 教师产生K+1个监督信号(黑色虚线):最后一个输出层T(N)作为第一个信号,其余N-1层被分成K段,每段通过可学习权重加权聚合为一个信号。(2)学生层输出通过投影头ϕ^{(j)}{PAD}与教师的加权组合U进行协方差对齐(红色虚线),并计算梯度信号δ^{(j)}。(3) 将这些梯度信号加权求和后,从学生最终层输出S(L)中减去,得到代理调整表征P。(4) P通过投影头ϕ^{(k)}{TGL}分别与K+1个教师监督信号进行对齐,计算TGL损失。
完整输入输出流程与主要组件:
- 输入:3秒的语音片段(经过数据增强)。
- 教师模型 (WavLM-Large):一个预训练的、冻结的Transformer自监督模型,包含N个编码层。其作用是提取丰富的、多层次的语音表征作为知识的来源。
- 学生模型 (SV-Mixer):一个基于MLP-Mixer的轻量级、全注意力的编码器,包含L层(如5、10、17层)。其目标是模仿教师的表征能力。
- 任务引导学习 (TGL) 模块:
- 功能:构建更有监督价值的教师信号。
- 内部结构:首先,教师的N层输出被划分为K个段。每个段通过一个可学习权重向量w^{(k)}进行加权平均,生成一个监督信号ˆT^{(k)}。为避免权重坍缩,这些权重通过停止梯度阻断来自蒸馏损失的梯度,并由一个独立的辅助说话人分类头(使用AAM-Softmax损失)更新。
- 输出:K+1个监督信号:ˆT^{(0)}(教师最后一层)和K个聚合信号。
- 代理对齐蒸馏 (PAD) 模块:
- 功能:弥合架构差异,稳定知识传递,特别是传输帧级关系结构。
- 内部结构:学生模型的每个中间层输出S(j)通过一个投影头ϕ^{(j)}_{PAD},与教师各层输出的加权组合U(权重由可学习向量α控制)计算协方差差异 (Corr)。产生的梯度信号δ^{(j)}被缩放并加权求和(权重α_j被停止梯度)。这个梯度信号被“注入”到学生最终层输出S(L)中,形成代理调整表征P。
- 核心设计选择:使用协方差相关性而非L1距离,因为前者能更好地建模帧间关系;对权重α使用停止梯度,防止训练坍缩(如图2所示)。
- 蒸馏损失 (LTGL):代理调整表征P经过投影头ϕ^{(k)}_{TGL}后,与K+1个教师监督信号分别计算余弦相似度损失和L1距离损失,两者结合指导学生学习。
- 输出:在训练阶段,损失LTGL加上辅助分类损失,共同更新学生模型。推理阶段,仅使用学生模型提取说话人嵌入,输入后续的ECAPA-TDNN后端进行验证。
组件间的数据流:教师中间层输出 -> TGL模块(聚合)-> 教师监督信号。同时,学生各层输出 -> PAD模块(计算关系梯度)-> 形成代理调整表征P -> TGL模块(对齐)-> 计算总损失。PAD的输出(梯度信号)反过来影响学生表征P,从而影响TGL的计算。
💡 核心创新点
- 首个系统性的说话人验证跨架构蒸馏框架:明确将“从Transformer教师到非Transformer学生”的知识蒸馏作为独立问题,而非简单套用同构蒸馏方法。这是对现有模型压缩范式的一个重要推进。
- 任务引导学习 (TGL) 构建判别性监督信号:通过可学习的、任务驱动的加权聚合,自适应地从教师多层特征中提取对说话人验证任务最有用的信息,生成比简单选择几层特征更具信息量的软监督目标。
- 代理对齐蒸馏 (PAD) 稳定异构迁移:创新性地将表征间的协方差结构(而非直接值)作为对齐目标,并通过代理优化策略(将梯度注入最终表征)高效地实现这一目标。这有效缓解了因注意力机制缺失导致的学生模型难以捕获教师模型细粒度时序关系的问题。
- 精巧的训练稳定性设计:在TGL的权重w和PAD的权重α上均使用停止梯度操作,并将其更新解耦到专门的路径(辅助分类头和代理优化),有效防止了训练过程中的权重坍缩和捷径学习(如图2所示),这是方法能够成功的关键工程技巧。
- 验证了MLP-Mixer学生在激进压缩下的潜力:通过该框架,5层(33M参数)的SV-Mixer学生模型在多个基准上已经超越了80.3M参数的基线SV-Mixer,证明了在有效蒸馏策略下,更轻量级的架构仍能保持强大性能。
🔬 细节详述
- 训练数据:
- 数据集:VoxCeleb1(用于种子平均的快速训练)和VoxCeleb2(用于基准公平对比)。
- 预处理:未详细说明,但输入为3秒音频片段。
- 数据增强:包括来自MUSAN的加性噪声和音乐,以及使用房间脉冲响应滤波器模拟的混响。
- 损失函数:
- 主蒸馏损失 (LTGL):结合余弦相似度损失和L1距离损失,公式为
µ ||ϕ(P) - ˆT||₁ - λ log σ(cos(ϕ(P), ˆT))。权重µ和λ通过经验搜索固定为1。 - 辅助损失:在构建TGL监督信号时,可学习权重w由一个AAM-Softmax损失(边距0.2,缩放30)训练的线性分类头更新。
- 主蒸馏损失 (LTGL):结合余弦相似度损失和L1距离损失,公式为
- 训练策略:
- 优化器:两阶段训练。先使用AdamW进行预热(warm-up),使用余弦退火并包含学习率小幅爬升;然后切换为带动量的SGD,使用余弦衰减。
- 批大小:128。
- 验证:周期性进行,使用早停策略。
- 关键超参数:
- 学生模型:SV-Mixer,可配置层数(L)和通道数。论文测试了5、10、17层。
- 教师模型:WavLM-Large。
- 蒸馏参数:TGL的段数K(测试了2,3,4,最优为3)。
- 损失权重:µ=1, λ=1。
- PAD梯度缩放因子η:论文中未明确给出具体数值。
- 训练硬件:2块NVIDIA RTX A6000 GPU。
- 推理细节:未详细说明。学生模型提取的帧级表征经过ECAPA-TDNN后端(使用统计池化和AAM-softmax损失)得到最终说话人嵌入用于验证。
- 正则化/稳定训练技巧:如前所述,在TGL和PAD中使用停止梯度是核心稳定技巧。此外,PAD中引入权重α控制各层提示强度,避免强制平均。
📊 实验结果
论文在多个标准基准上进行了全面的实验验证,包括域内(VoxCeleb协议)和跨域(VCMix, VoxSRC, VOiCES)测试。
主要基准测试结果: 如核心摘要中的表1、表2、表3所示。关键结论如下:
- 组件有效性:TGL和PAD单独使用均带来改进,组合使用时产生显著的协同效应(表1)。
- 设计因素分析:
- TGL段数K=3时性能最佳(表1中间块)。
- PAD使用协方差相关性(Corr)远优于L1距离(表1底部块)。
- 与同构蒸馏对比:将该框架应用于同构蒸馏(Transformer到Transformer)也带来5.6%的相对改进,但应用于异构蒸馏(Transformer到Mixer)时改进更大(9.2%),证明了框架对异构场景的特殊价值。
- 鲁棒性与压缩:在不同压缩策略(减通道、减深度)和压缩比下,该框架训练的学生模型均优于基线压缩方法(图3)。
- 与SOTA对比:80M参数的17层学生模型在VoxCeleb-O上达到了0.58% EER,显著优于同为80.3M参数的SV-Mixer基线(0.78%),并与参数量更大的Transformer模型(如LAP,96.3M,0.61%)性能相当(表2)。在跨域测试集VCMix, VoxSRC, VOiCES上也展示了竞争力。
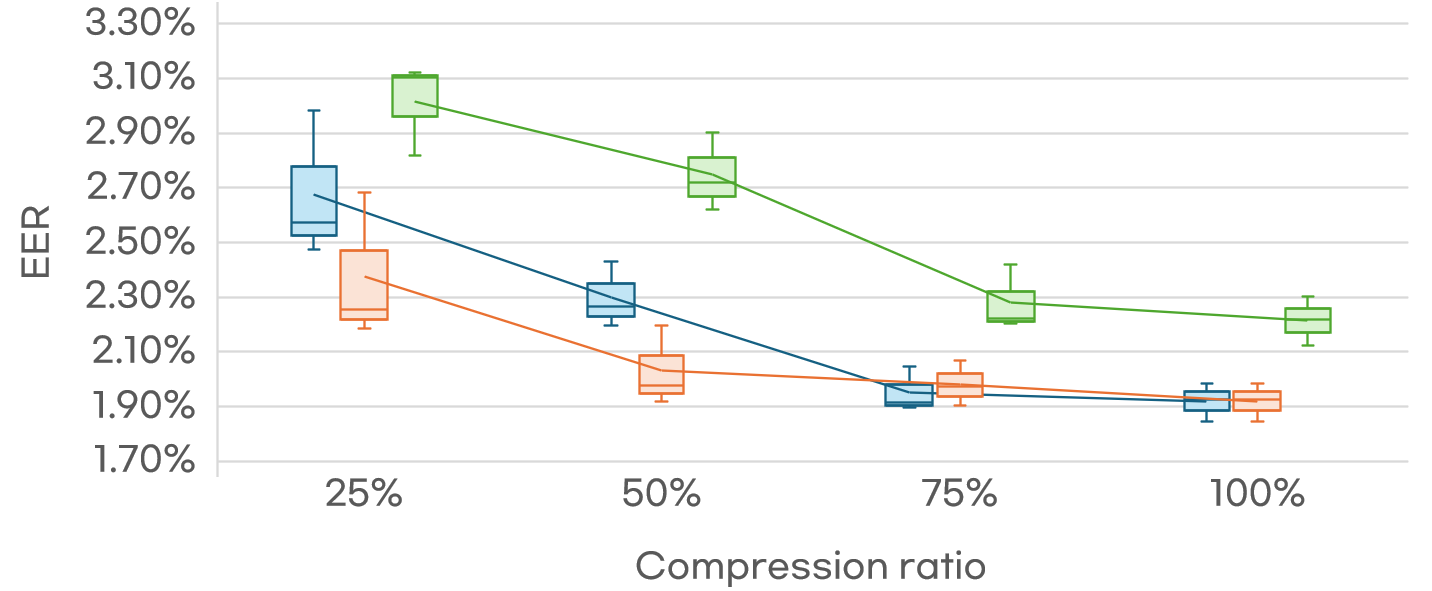 图3显示了以参数量约100M、10层的Transformer为基线(最右侧),在应用不同压缩策略(蓝色:减半通道;橙色:减深度;绿色:基线压缩方法)后,使用本文提出的蒸馏框架训练的学生模型的EER变化。横轴是压缩比(参数量/基线参数量),纵轴是EER(%)。关键结论:蓝色和橙色曲线始终低于绿色曲线,表明该框架训练的学生在同等压缩比下性能更优;橙色曲线(减深度)在左侧高压缩比区域最低,表明其对深度压缩特别有效。
图3显示了以参数量约100M、10层的Transformer为基线(最右侧),在应用不同压缩策略(蓝色:减半通道;橙色:减深度;绿色:基线压缩方法)后,使用本文提出的蒸馏框架训练的学生模型的EER变化。横轴是压缩比(参数量/基线参数量),纵轴是EER(%)。关键结论:蓝色和橙色曲线始终低于绿色曲线,表明该框架训练的学生在同等压缩比下性能更优;橙色曲线(减深度)在左侧高压缩比区域最低,表明其对深度压缩特别有效。
⚖️ 评分理由
- 学术质量:6.5/7
- 创新性:提出了一个新颖且系统的跨架构蒸馏框架,针对说话人验证任务。TGL和PAD的设计有明确的动机和巧思,特别是对停止梯度的使用解决了实际训练中的坍缩问题,显示了良好的工程洞察力。
- 技术正确性:方法描述清晰,公式明确。通过停止梯度、解耦训练等技巧有效解决了文中提出的异构蒸馏挑战。实验设计合理,消融研究充分支持了各组件的作用。
- 实验充分性:实验在多个有代表性的基准上进行,覆盖域内和跨域场景。提供了充分的消融实验(组件贡献、超参数、损失函数变体)和对比实验(同构vs异构、压缩鲁棒性、与SOTA对比)。结果以清晰的表格和图表呈现。
- 证据可信度:实验设置标准(数据集、协议、后端),报告了标准差,代码开源,可信度高。
- 选题价值:1.5/2
- 前沿性:模型压缩和高效部署是当前AI落地,特别是边缘端语音应用的关键挑战。跨架构蒸馏是一个活跃且重要的研究方向。
- 潜在影响与应用空间:该工作直接推动了高性能、低功耗说话人验证系统的实现,对移动设备、物联网等场景有明确的应用价值。其方法论对其他语音任务(如语音识别)的模型压缩也有借鉴意义。
- 与读者相关性:对于关注语音模型轻量化、高效部署、知识蒸馏的音频/语音领域读者,本文具有较高的相关性和参考价值。
- 开源与复现加成:1.0/1
- 论文明确提供了代码仓库链接(https://github.com/Jungwoo4021/SV-Mixer-TGL-PAD),并声明将公开预训练模型。
- 实验细节描述非常充分,包括训练策略(两阶段优化)、超参数(学习率调度、批大小、损失权重)、硬件环境(GPU型号)等,复现友好度很高。
- 依赖的开源项目(WavLM, ECAPA-TDNN后端, AAM-Softmax)在文中均有明确引用。