📄 Coupling Acoustic Geometry and Visual Semantics for Robust Depth Estimation
#空间音频 #多模态模型 #时频分析 #鲁棒性
✅ 7.5/10 | 前25% | #空间音频 | #多模态模型 | #时频分析 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
基于论文内容提取如下:
- 第一作者:Anjie Wang(北京大学电子与计算机工程学院,鹏城实验室)
- 通讯作者:Zhijun Fang(复旦大学可信具身AI研究所,东华大学信息与智能科学学院)(论文中注明“Corresponding author: Zhijun Fang (zjfang@fudan.edu.cn)”)
- 作者列表:
- Anjie Wang(北京大学电子与计算机工程学院,鹏城实验室)
- Mingxuan Chen(上海工程技术大学电子与电气工程学院)
- Xiaoyan Jiang(上海工程技术大学电子与电气工程学院)
- Yongbin Gao(上海工程技术大学电子与电气工程学院)
- Zhijun Fang(复旦大学可信具身AI研究所,东华大学信息与智能科学学院)
- Siwei Ma(北京大学计算机科学学院)
💡 毒舌点评
亮点在于其融合策略的精巧设计,通过语义查询注入(SQI)和条件解码器(SGCD)明确地解决了声学稀疏几何与密集视觉语义间的对齐难题,并用不确定性门控(DUGF)实现了自适应的模态平衡,这在思想上比简单的拼接或注意力融合更进了一步。然而,所有实验均基于合成声学数据(Echo simulation),且数据集均为室内场景,其结论在真实世界复杂声学环境(如室外、多声源干扰)中的泛化能力未经验证,这是其最大的短板。
🔗 开源详情
根据论文内容:
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开模型权重。
- 数据集:使用的是公开数据集Replica和Matterport3D。但声学数据(回声频谱图)是基于这些数据集场景模拟生成的,具体的模拟脚本或数据未提及公开。
- Demo:未提供在线演示。
- 复现材料:论文提供了一定的训练细节(优化器、学习率、轮数、批量大小、损失函数权重λ)和网络超参数,但缺乏预训练骨干网络的具体配置、数据模拟的详细参数、以及完整的训练/评估脚本。
- 论文中引用的开源项目:引用了多个开源方法作为基线(如VisualEchoes [1], BI2D [2]),但未明确说明其代码是否被用于实现或复现。
📌 核心摘要
- 要解决什么问题:单目深度估计在低纹理、反射、光照差和遮挡等场景下性能下降严重;而主动声学(如回声)能提供几何互补线索,但存在数据稀疏、与图像不对齐的问题。现有音视觉融合方法未能充分解决这种模态间的异质性。
- 方法核心是什么:提出了EchoFormer框架,���核心是三个组件:(1)语义查询注入(SQI):将DINOv2提取的全局图像语义作为查询,通过交叉注意力引导对回声特征的关注;(2)语义-几何条件解码器(SGCD):使用图像特征和语义查询通过FiLM调制来条件化地解码多尺度回声特征;(3)动态不确定性感知门控融合(DUGF):一个轻量级卷积头预测像素级置信度权重,自适应地融合视觉和回声特征。
- 与已有方法相比新在哪里:与先前简单的拼接或浅层融合(如VisualEchoes, BI2D)不同,EchoFormer显式地将高层语义信息作为桥梁来耦合稀疏的声学几何特征和密集的视觉语义特征。DUGF模块引入了像素级的不确定性感知,使模型能在纹理丰富区域更信赖视觉,在黑暗或反光区域更信赖声学,这比全局加权融合更精细。
- 主要实验结果如何:在Replica和Matterport3D两个室内基准上,EchoFormer(Mono+Echo)全面超越了现有回声单模态、单目单模态及融合方法。在Replica上,RMSE从最强基线[15]的0.246降至0.186,δ<1.25从0.865提升至0.919。在Matterport3D上,RMSE从0.845降至0.812。消融实验证实SGCD和DUGF均带来持续性能提升。
- 实际意义是什么:为机器人导航、增强现实、三维重建等应用在视觉受限的恶劣环境中提供了更鲁棒的深度感知解决方案,推动了多模态感知在复杂真实场景中的落地。
- 主要局限性是什么:实验完全基于模拟生成的回声数据,缺乏真实世界采集的音视觉配对数据的验证;仅评估了室内场景;声学模型单一(仅模拟了单回声源),未考虑更复杂的声学环境。
EchoFormer的整体架构如图1所示,其输入为128x128的RGB图像和对应的回声频谱图,输出为密集深度图。
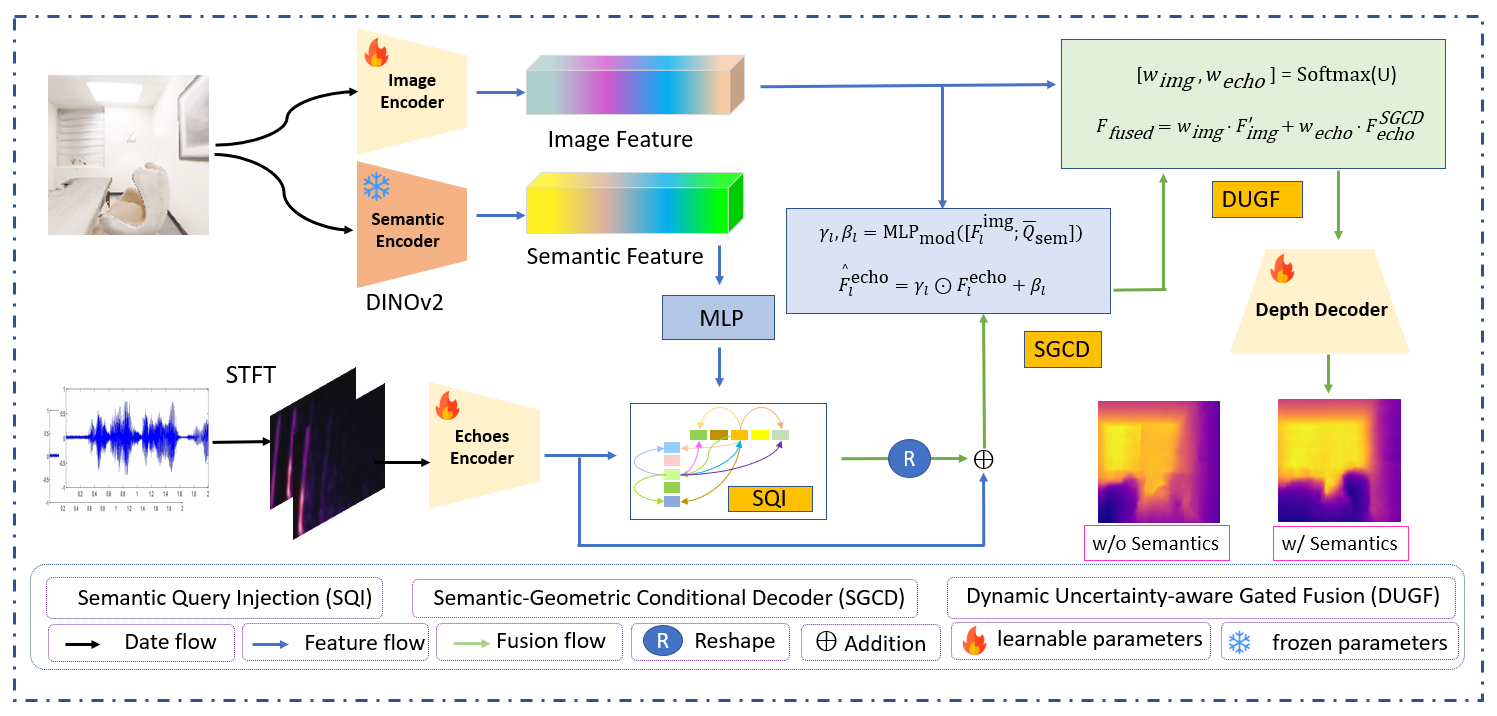 架构主要包含以下组件和数据流:
架构主要包含以下组件和数据流:
编码器:采用三个预训练骨干网络。
- RGB编码器:使用ResNet-50提取图像特征。
- 回声编码器:使用U-Net处理回声频谱图(2通道,尺寸因数据集而异)。
- 语义编码器:使用冻结的DINOv2 ViT-B/14模型提取高分辨率视觉语义补丁特征。这些特征通过一个MLP压缩为Nq个全局语义查询(论文中Nq=8,维度256)。 所有编码器输出通过1x1适配器投影到一个公共的潜在空间(步长s=4,通道C=256),以匹配后续模块的输入分辨率。
语义查询注入(SQI):将回声编码器输出的扁平化声学token(E)作为输入。全局语义查询(Qsem)作为查询,声学token作为键和值,计算交叉注意力(公式1)。注意力输出经投影后,残差连接回原始回声特征,得到语义引导后的回声特征 F_SQI_echo(公式2)。此步骤旨在让图像语义引导模型关注声学特征中的关键几何信息。
语义-几何条件解码器(SGCD):接收F_SQI_echo及其多尺度表示。在每个解码阶段,当前层的回声特征(F_echo_l)与来自ResNet对应层的图像特征(F_img_l)以及全局语义查询的池化表示(Qsem_bar)一起,通过一个共享的MLP(MLPmod)生成FiLM调制的仿射参数(γl, βl)(公式3)。回声特征通过该调制进行变换(公式4)。最终,经多尺度上采样和跳跃连接输出F_SGCD_echo。此模块的核心思想是利用视觉语义和图像特征,逐层条件化地重建和细化声学几何特征。
动态不确定性感知门控融合(DUGF):这是一个轻量级的融合模块。它将投影后的图像特征F’_img和SGCD处理后的回声特征F_SGCD_echo拼接,通过一个3x3卷积(Convgate)和softmax生成像素级的模态置信度权重(wimg, wecho)(公式5)。最终融合特征Ffused为两个模态特征的加权和(公式6)。这使得模型能够根据每个像素的可靠性自适应地分配不同模态的贡献。
深度头与不确定性分支:融合特征Ffused送入一个三阶段的上采样解码器(双线性插值+3x3卷积),通过1x1卷积回归出预测深度D̂(公式7)。并行地,另一个1x1卷积头预测每个像素的同方差不确定性σ²(通过Softplus激活确保正值)(公式8)。不确定性分支在训练时用于计算损失,但在推理时被忽略。
语义查询注入(SQI)与语义-几何条件解码器(SGCD):
- 是什么:通过交叉注意力将高层视觉语义(来自DINOv2)注入到声学特征解码过程中,并在解码器各阶段使用图像特征和语义信息进行条件调制。
- 之前方法的局限:先前音视觉融合方法(如VisualEchoes, BI2D)通常采用浅层融合(如拼接、简单注意力)或未能有效利用高层语义来指导稀疏声学特征的密集解码,导致模态间信息交互不充分。
- 如何起作用与收益:SQI让模型知道“看”回声特征的哪个部分;SGCD则让声学特征的解码过程受到视觉语义和结构的约束和指导。这有效耦合了异质模态,提升了在视觉退化区域利用声学信息恢复几何结构的能力。消融实验显示,添加SGCD后,Replica数据集上RMSE从0.218降至0.192,δ<1.25从0.874提升至0.915。
动态不确定性感知门控融合(DUGF):
- 是什么:一个预测像素级置信度权重的模块,用于自适应地融合视觉和声学特征。
- 之前方法的局限:传统融合方法通常采用固定的融合权重或仅通过损失函数隐式学习重要性,无法灵活应对每个像素处不同模态可靠性的变化。
- 如何起作用与收益:DUGF显式建模每个像素的不确定性,使得模型在纹理清晰处更依赖视觉,在低光/反光区域更依赖声学。这提升了融合的鲁棒性和最终深度预测的精度。消融实验显示,添加DUGF后,Replica上RMSE进一步从0.192降至0.186。
基于模拟回声的多模态深度估计框架:
- 是什么:构建了一个完整的、从RGB图像和回声频谱图预测密集深度的端到端框架。
- 之前方法的局限:尽管有音视觉融合工作,但针对回声-视觉融合的系统性框架研究相对较少,且缺乏对跨模态对齐问题的专门设计。
- 如何起作用与收益:EchoFormer提供了一个有效整合声学几何与视觉语义的范例,在合成数据上取得了SOTA性能,验证了该技术路线的可行性,为未来真实数据集的研究奠定了基础。
- 训练数据:
- 数据集:Replica(合成室内场景)和Matterport3D(真实世界室内扫描)。
- 回声模拟:对每个相机位姿,使用几何射线追踪计算房间冲激响应(RIR),并与啁啾信号卷积以合成回声频谱图,生成同步的RGB-回声对。具体模拟细节(如声源位置、RIR计算参数)未提供。
- 预处理:RGB图像和回声频谱图尺寸为128x128。回声频谱图通过STFT(512点FFT,汉宁窗)生成,不同数据集的窗长/步长设置导致最终尺寸不同:Replica为2x257x166,Mp3D为2x257x121。
- 数据增强:论文中未提及使用数据增强。
- 损失函数:总损失Ltotal = Lsi + λ Lnll, λ=0.1。
- Lsi:尺度不变的对数深度回归损失(公式9),衡量预测深度和真实深度对数差异的平均绝对值,鼓励跨场景尺度的尺度不敏感准确性。
- Lnll:高斯负对数似然损失(公式10),将预测不确定性σ²解释为像素级噪声水平,对不确定像素的梯度进行衰减,提升训练稳定性。
- 训练策略:
- 优化器:Adam。
- 学习率:初始lr=1e-4,在训练总轮数的80%时衰减至0.1倍。
- 批量大小:8。
- 训练轮数:Replica为150 epochs,Matterport3D为100 epochs。
- 训练硬件:2块NVIDIA A100 GPU。训练时长未说明。
- 关键超参数:
- 特征投影维度:D=256。
- 语义查询数量:Nq=8,维度256。
- SGCD中MLP:2层,隐藏层维度512,ReLU激活。
- DUGF门控卷积:3x3。
- 深度头上采样:3个阶段(双线性插值 + 3x3卷积)。
- 不确定性输出:通过Softplus激活。
- 推理细节:推理时仅使用预测深度D̂,忽略不确定性分支σ²。解码策略、温度、beam size等不适用。
- 正则化或稳定训练技巧:主要依靠损失函数中的不确定性项(NLL损失)来稳定训练,使模型能自动降低不可靠像素的梯度权重。
主要对比实验结果如下表所示。EchoFormer在两个数据集的所有评估指标上均优于所有对比方法。
表1:Replica数据集上的性能对比
| 方法 | 输入 | RMSE ↓ | AbsRel ↓ | log10 ↓ | δ<1.25 ↑ | δ<1.25² ↑ | δ<1.25³ ↑ |
|---|---|---|---|---|---|---|---|
| Parida et al. [2] | Echo | 0.995 | 0.638 | 0.208 | 0.338 | 0.599 | 0.742 |
| Irie et al. [13] | Echo | 0.921 | 0.560 | 0.203 | 0.419 | 0.636 | 0.763 |
| Zhang et al. [14] | Echo | 0.913 | 0.604 | 0.194 | 0.515 | 0.668 | 0.764 |
| Gao et al. [1] | Mono | 0.374 | 0.202 | 0.076 | 0.749 | 0.883 | 0.945 |
| Gao et al. [1] | Mono+Echo | 0.346 | 0.172 | 0.068 | 0.798 | 0.905 | 0.950 |
| Parida et al. [2] | Mono+Echo | 0.249 | 0.118 | 0.046 | 0.869 | 0.943 | 0.970 |
| Wang et al. [15] | Mono+Echo | 0.246 | 0.108 | 0.045 | 0.865 | 0.958 | 0.984 |
| EchoFormer (Ours) | Mono+Echo | 0.186 | 0.082 | 0.033 | 0.919 | 0.975 | 0.991 |
表2:Matterport3D (Mp3D) 数据集上的性能对比
| 方法 | 输入 | RMSE ↓ | AbsRel ↓ | log10 ↓ | δ<1.25 ↑ | δ<1.25² ↑ | δ<1.25³ ↑ |
|---|---|---|---|---|---|---|---|
| Parida et al. [2] | Echo | 1.778 | 0.507 | 0.192 | 0.464 | 0.642 | 0.759 |
| Zhang et al. [14] | Echo | 1.702 | 0.512 | 0.187 | 0.481 | 0.659 | 0.770 |
| Parida et al. [2] | Mono | 1.090 | 0.260 | 0.111 | 0.592 | 0.802 | 0.910 |
| Gao et al. [1] | Mono+Echo | 0.998 | 0.193 | 0.083 | 0.711 | 0.878 | 0.945 |
| Parida et al. [2] | Mono+Echo | 0.950 | 0.175 | 0.079 | 0.733 | 0.886 | 0.948 |
| Wang et al. [15] | Mono+Echo | 0.845 | 0.130 | 0.057 | 0.835 | 0.933 | 0.967 |
| EchoFormer (Ours) | Mono+Echo | 0.812 | 0.125 | 0.052 | 0.851 | 0.942 | 0.972 |
关键消融实验如下表所示,证实了SGCD和DUGF模块的有效性。
表3:在Replica和Mp3D上的消融研究
| 数据集 | 方法 | RMSE ↓ | δ1 (δ<1.25) ↑ | δ2 (δ<1.25²) ↑ | δ3 (δ<1.25³) ↑ |
|---|---|---|---|---|---|
| Replica | Baseline (RGB+Echo) | 0.218 | 0.874 | 0.958 | 0.983 |
| +SGCD | 0.192 | 0.915 | 0.972 | 0.990 | |
| +SGCD+DUGF | 0.186 | 0.919 | 0.975 | 0.991 | |
| Mp3D | Baseline (RGB+Echo) | 1.020 | 0.801 | 0.915 | 0.959 |
| +SGCD | 0.879 | 0.820 | 0.928 | 0.965 | |
| +SGCD+DUGF | 0.812 | 0.851 | 0.942 | 0.972 |
定性对比与可视化:
图2展示了EchoFormer与VisualEchoes、BI2D等方法在Replica和Mp3D数据集上的定性对比。可以观察到,EchoFormer在纹理稀疏或声学模糊区域能产生更清晰的边界和更连贯的深度结构。
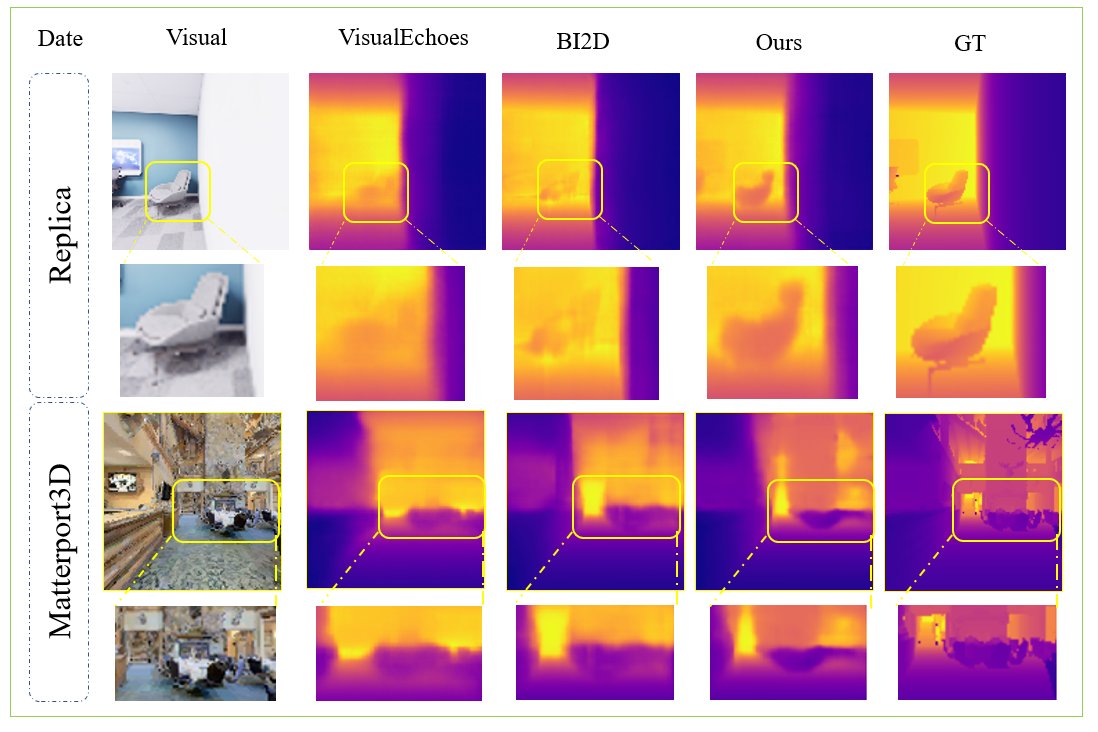
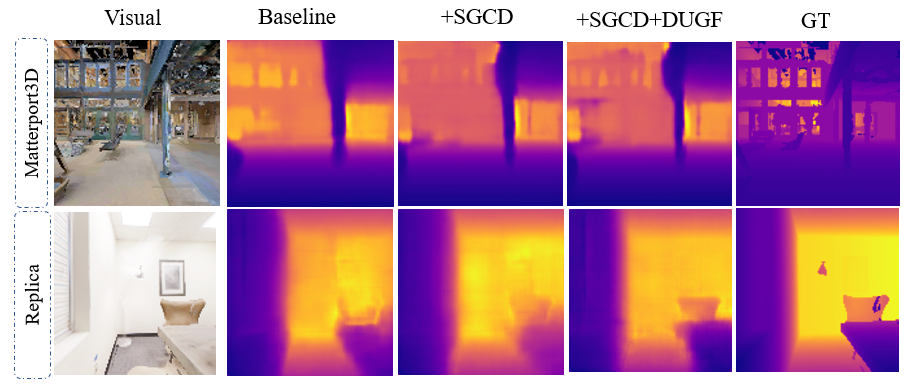
图3是消融研究的可视化结果。从左到右依次为:RGB图像、仅基线模型(Baseline)、基线+SGCD、基线+SGCD+DUGF(即完整模型)、GT(真值)。图像显示SGCD显著改善了几何布局的准确性,而DUGF在退化区域进一步提升了细粒度精度。
学术质量:6.0/7:论文提出了一个技术路径清晰、逻辑自洽的解决方案。创新点(SQI, SGCD, DUGF)针对性地解决了多模态融合中的对齐和自适应加权问题,具有较好的技术新颖性。实验部分在两个标准数据集上进行了全面的定量对比(有明确的SOTA提升数字)和定性分析,消融实验设计合理,证明了各模块的贡献。技术正确性高。主要扣分点在于实验均基于合成声学数据,缺乏真实世界验证,且创新主要局限于融合架构,对单模态或基础模型的突破有限。
选题价值:1.5/2:将主动声学线索与视觉融合用于深度估计是一个有前沿性的交叉研究方向,尤其在机器人、自动驾驶、AR等需要鲁棒感知的领域有明确的应用价值。该工作有效推动了此方向的技术进步。给1.5分而非满分是因为其应用场景目前仍相对垂直和特定。
开源与复现加成:0.0/1:论文全文未提供代码仓库链接、模型权重下载地址或详细的复现配置文件。虽然给出了训练细节(如学习率、轮数),但缺少预训练模型和数据模拟的完整脚本,复现门槛较高。因此不给予加成。
开源详情
根据论文内容:
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开模型权重。
- 数据集:使用的是公开数据集Replica和Matterport3D。但声学数据(回声频谱图)是基于这些数据集场景模拟生成的,具体的模拟脚本或数据未提及公开。
- Demo:未提供在线演示。
- 复现材料:论文提供了一定的训练细节(优化器、学习率、轮数、批量大小、损失函数权重λ)和网络超参数,但缺乏预训练骨干网络的具体配置、数据模拟的详细参数、以及完整的训练/评估脚本。
- 论文中引用的开源项目:引用了多个开源方法作为基线(如VisualEchoes [1], BI2D [2]),但未明确说明其代码是否被用于实现或复现。
🏗️ 模型架构
EchoFormer的整体架构如图1所示,其输入为128x128的RGB图像和对应的回声频谱图,输出为密集深度图。
架构主要包含以下组件和数据流:
- 编码器:采用三个预训练骨干网络。
- RGB编码器:使用ResNet-50提取图像特征。
- 回声编码器:使用U-Net处理回声频谱图(2通道,尺寸因数据集而异)。
- 语义编码器:使用冻结的DINOv2 ViT-B/14模型提取高分辨率视觉语义补丁特征。这些特征通过一个MLP压缩为Nq个全局语义查询(论文中Nq=8,维度256)。 所有编码器输出通过1x1适配器投影到一个公共的潜在空间(步长s=4,通道C=256),以匹配后续模块的输入分辨率。
- 语义查询注入(SQI):将回声编码器输出的扁平化声学token(E)作为输入。全局语义查询(Qsem)作为查询,声学token作为键和值,计算交叉注意力(公式1)。注意力输出经投影后,残差连接回原始回声特征,得到语义引导后的回声特征 F_SQI_echo(公式2)。此步骤旨在让图像语义引导模型关注声学特征中的关键几何信息。
- 语义-几何条件解码器(SGCD):接收F_SQI_echo及其多尺度表示。在每个解码阶段,当前层的回声特征(F_echo_l)与来自ResNet对应层的图像特征(F_img_l)以及全局语义查询的池化表示(Qsem_bar)一起,通过一个共享的MLP(MLPmod)生成FiLM调制的仿射参数(γl, βl)(公式3)。回声特征通过该调制进行变换(公式4)。最终,经多尺度上采样和跳跃连接输出F_SGCD_echo。此模块的核心思想是利用视觉语义和图像特征,逐层条件化地重建和细化声学几何特征。
- 动态不确定性感知门控融合(DUGF):这是一个轻量级的融合模块。它将投影后的图像特征F’_img和SGCD处理后的回声特征F_SGCD_echo拼接,通过一个3x3卷积(Convgate)和softmax生成像素级的模态置信度权重(wimg, wecho)(公式5)。最终融合特征Ffused为两个模态特征的加权和(公式6)。这使得模型能够根据每个像素的可靠性自适应地分配不同模态的贡献。
- 深度头与不确定性分支:融合特征Ffused送入一个三阶段的上采样解码器(双线性插值+3x3卷积),通过1x1卷积回归出预测深度D̂(公式7)。并行地,另一个1x1卷积头预测每个像素的同方差不确定性σ²(通过Softplus激活确保正值)(公式8)。不确定性分支在训练时用于计算损失,但在推理时被忽略。
💡 核心创新点
语义查询注入(SQI)与语义-几何条件解码器(SGCD):
- 是什么:通过交叉注意力将高层视觉语义(来自DINOv2)注入到声学特征解码过程中,并在解码器各阶段使用图像特征和语义信息进行条件调制。
- 之前方法的局限:先前音视觉融合方法(如VisualEchoes, BI2D)通常采用浅层融合(如拼接、简单注意力)或未能有效利用高层语义来指导稀疏声学特征的密集解码,导致模态间信息交互不充分。
- 如何起作用与收益:SQI让模型知道“看”回声特征的哪个部分;SGCD则让声学特征的解码过程受到视觉语义和结构的约束和指导。这有效耦合了异质模态,提升了在视觉退化区域利用声学信息恢复几何结构的能力。消融实验显示,添加SGCD后,Replica数据集上RMSE从0.218降至0.192,δ<1.25从0.874提升至0.915。
动态不确定性感知门控融合(DUGF):
- 是什么:一个预测像素级置信度权重的模块,用于自适应地融合视觉和声学特征。
- 之前方法的局限:传统融合方法通常采用固定的融合权重或仅通过损失函数隐式学习重要性,无法灵活应对每个像素处不同模态可靠性的变化。
- 如何起作用与收益:DUGF显式建模每个像素的不确定性,使得模型在纹理清晰处更依赖视觉,在低光/反光区域更依赖声学。这提升了融合的鲁棒性和最终深度预测的精度。消融实验显示,添加DUGF后,Replica上RMSE进一步从0.192降至0.186。
基于模拟回声的多模态深度估计框架:
- 是什么:构建了一个完整的、从RGB图像和回声频谱图预测密集深度的端到端框架。
- 之前方法的局限:尽管有音视觉融合工作,但针对回声-视觉融合的系统性框架研究相对较少,且缺乏对跨模态对齐问题的专门设计。
- 如何起作用与收益:EchoFormer提供了一个有效整合声学几何与视觉语义的范例,在合成数据上取得了SOTA性能,验证了该技术路线的可行性,为未来真实数据集的研究奠定了基础。
🔬 细节详述
- 训练数据:
- 数据集:Replica(合成室内场景)和Matterport3D(真实世界室内扫描)。
- 回声模拟:对每个相机位姿,使用几何射线追踪计算房间冲激响应(RIR),并与啁啾信号卷积以合成回声频谱图,生成同步的RGB-回声对。具体模拟细节(如声源位置、RIR计算参数)未提供。
- 预处理:RGB图像和回声频谱图尺寸为128x128。回声频谱图通过STFT(512点FFT,汉宁窗)生成,不同数据集的窗长/步长设置导致最终尺寸不同:Replica为2x257x166,Mp3D为2x257x121。
- 数据增强:论文中未提及使用数据增强。
- 损失函数:总损失Ltotal = Lsi + λ Lnll, λ=0.1。
- Lsi:尺度不变的对数深度回归损失(公式9),衡量预测深度和真实深度对数差异的平均绝对值,鼓励跨场景尺度的尺度不敏感准确性。
- Lnll:高斯负对数似然损失(公式10),将预测不确定性σ²解释为像素级噪声水平,对不确定像素的梯度进行衰减,提升训练稳定性。
- 训练策略:
- 优化器:Adam。
- 学习率:初始lr=1e-4,在训练总轮数的80%时衰减至0.1倍。
- 批量大小:8。
- 训练轮数:Replica为150 epochs,Matterport3D为100 epochs。
- 训练硬件:2块NVIDIA A100 GPU。训练时长未说明。
- 关键超参数:
- 特征投影维度:D=256。
- 语义查询数量:Nq=8,维度256。
- SGCD中MLP:2层,隐藏层维度512,ReLU激活。
- DUGF门控卷积:3x3。
- 深度头上采样:3个阶段(双线性插值 + 3x3卷积)。
- 不确定性输出:通过Softplus激活。
- 推理细节:推理时仅使用预测深度D̂,忽略不确定性分支σ²。解码策略、温度、beam size等不适用。
- 正则化或稳定训练技巧:主要依靠损失函数中的不确定性项(NLL损失)来稳定训练,使模型能自动降低不可靠像素的梯度权重。
📊 实验结果
主要对比实验结果如下表所示。EchoFormer在两个数据集的所有评估指标上均优于所有对比方法。
表1:Replica数据集上的性能对比
| 方法 | 输入 | RMSE ↓ | AbsRel ↓ | log10 ↓ | δ<1.25 ↑ | δ<1.25² ↑ | δ<1.25³ ↑ |
|---|---|---|---|---|---|---|---|
| Parida et al. [2] | Echo | 0.995 | 0.638 | 0.208 | 0.338 | 0.599 | 0.742 |
| Irie et al. [13] | Echo | 0.921 | 0.560 | 0.203 | 0.419 | 0.636 | 0.763 |
| Zhang et al. [14] | Echo | 0.913 | 0.604 | 0.194 | 0.515 | 0.668 | 0.764 |
| Gao et al. [1] | Mono | 0.374 | 0.202 | 0.076 | 0.749 | 0.883 | 0.945 |
| Gao et al. [1] | Mono+Echo | 0.346 | 0.172 | 0.068 | 0.798 | 0.905 | 0.950 |
| Parida et al. [2] | Mono+Echo | 0.249 | 0.118 | 0.046 | 0.869 | 0.943 | 0.970 |
| Wang et al. [15] | Mono+Echo | 0.246 | 0.108 | 0.045 | 0.865 | 0.958 | 0.984 |
| EchoFormer (Ours) | Mono+Echo | 0.186 | 0.082 | 0.033 | 0.919 | 0.975 | 0.991 |
表2:Matterport3D (Mp3D) 数据集上的性能对比
| 方法 | 输入 | RMSE ↓ | AbsRel ↓ | log10 ↓ | δ<1.25 ↑ | δ<1.25² ↑ | δ<1.25³ ↑ |
|---|---|---|---|---|---|---|---|
| Parida et al. [2] | Echo | 1.778 | 0.507 | 0.192 | 0.464 | 0.642 | 0.759 |
| Zhang et al. [14] | Echo | 1.702 | 0.512 | 0.187 | 0.481 | 0.659 | 0.770 |
| Parida et al. [2] | Mono | 1.090 | 0.260 | 0.111 | 0.592 | 0.802 | 0.910 |
| Gao et al. [1] | Mono+Echo | 0.998 | 0.193 | 0.083 | 0.711 | 0.878 | 0.945 |
| Parida et al. [2] | Mono+Echo | 0.950 | 0.175 | 0.079 | 0.733 | 0.886 | 0.948 |
| Wang et al. [15] | Mono+Echo | 0.845 | 0.130 | 0.057 | 0.835 | 0.933 | 0.967 |
| EchoFormer (Ours) | Mono+Echo | 0.812 | 0.125 | 0.052 | 0.851 | 0.942 | 0.972 |
关键消融实验如下表所示,证实了SGCD和DUGF模块的有效性。
表3:在Replica和Mp3D上的消融研究
| 数据集 | 方法 | RMSE ↓ | δ1 (δ<1.25) ↑ | δ2 (δ<1.25²) ↑ | δ3 (δ<1.25³) ↑ |
|---|---|---|---|---|---|
| Replica | Baseline (RGB+Echo) | 0.218 | 0.874 | 0.958 | 0.983 |
| +SGCD | 0.192 | 0.915 | 0.972 | 0.990 | |
| +SGCD+DUGF | 0.186 | 0.919 | 0.975 | 0.991 | |
| Mp3D | Baseline (RGB+Echo) | 1.020 | 0.801 | 0.915 | 0.959 |
| +SGCD | 0.879 | 0.820 | 0.928 | 0.965 | |
| +SGCD+DUGF | 0.812 | 0.851 | 0.942 | 0.972 |
定性对比与可视化:
- 图2展示了EchoFormer与VisualEchoes、BI2D等方法在Replica和Mp3D数据集上的定性对比。可以观察到,EchoFormer在纹理稀疏或声学模糊区域能产生更清晰的边界和更连贯的深度结构。
- 图3是消融研究的可视化结果。从左到右依次为:RGB图像、仅基线模型(Baseline)、基线+SGCD、基线+SGCD+DUGF(即完整模型)、GT(真值)。图像显示SGCD显著改善了几何布局的准确性,而DUGF在退化区域进一步提升了细粒度精度。
⚖️ 评分理由
- 学术质量:6.0/7:论文提出了一个技术路径清晰、逻辑自洽的解决方案。创新点(SQI, SGCD, DUGF)针对性地解决了多模态融合中的对齐和自适应加权问题,具有较好的技术新颖性。实验部分在两个标准数据集上进行了全面的定量对比(有明确的SOTA提升数字)和定性分析,消融实验设计合理,证明了各模块的贡献。技术正确性高。主要扣分点在于实验均基于合成声学数据,缺乏真实世界验证,且创新主要局限于融合架构,对单模态或基础模型的突破有限。
- 选题价值:1.5/2:将主动声学线索与视觉融合用于深度估计是一个有前沿性的交叉研究方向,尤其在机器人、自动驾驶、AR等需要鲁棒感知的领域有明确的应用价值。该工作有效推动了此方向的技术进步。给1.5分而非满分是因为其应用场景目前仍相对垂直和特定。
- 开源与复现加成:0.0/1:论文全文未提供代码仓库链接、模型权重下载地址或详细的复现配置文件。虽然给出了训练细节(如学习率、轮数),但缺少预训练模型和数据模拟的完整脚本,复现门槛较高。因此不给予加成。