📄 Context-Aware Dynamic Graph Learning for Multimodal Emotion Recognition with Missing Modalities
#语音情感识别 #多模态模型 #大语言模型 #多任务学习 #鲁棒性
🔥 8.8/10 | 前10% | #语音情感识别 | #多模态模型 | #大语言模型 #多任务学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Miree Kim(首尔淑明女子大学软件系)
- 通讯作者:Sunyoung Cho(首尔淑明女子大学软件系)
- 作者列表:Miree Kim(首尔淑明女子大学软件系)、Sunyoung Cho(首尔淑明女子大学软件系)
💡 毒舌点评
亮点在于将大语言模型从“黑盒”生成器改造为上下文感知的情感特征提取器,生成的关键词作为引导信息注入图神经网络,这种“LLM作为特征增强器”的思路比端到端微调更轻量且针对性强。短板是模拟缺失场景的方式(随机丢弃)可能过于理想化,与真实世界中模态缺失的关联性(如特定情境下语音质量差)不符,且未深入讨论LLM引入带来的计算开销。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/premiree/CDAGL.git
- 模型权重:未提及是否公开预训练模型权重。
- 数据集:使用公开数据集IEMOCAP和MELD,但未说明具体获取方式或预处理脚本。
- Demo:未提供在线演示。
- 复现材料:论文“Implementation details”小节提供了较为详细的超参数设置(特征提取器、模型维度、优化器、损失权重等),对复现核心方法有帮助。
- 引用的开源项目:Qwen-7B(LLM)、AudioCLIP、BERT、DenseNet-121、MMIN[8]中的Imagination Module。
📌 核心摘要
- 问题:对话场景下的多模态情感识别(MERC)在实际应用中面临模态缺失(如文本、音频、视频不全)的挑战,现有方法难以在缺失条件下保持语义一致性和鲁棒性。
- 方法核心:提出一个统一框架,包含三个核心组件:(1) 一个自适应对话图,利用改进的动态图常微分方程(DGODE)建模说话人及时间动态;(2) 利用大语言模型(Qwen-7B)提取条件化的、情感相关的关键词,作为重构缺失模态的语义引导;(3) 引入基于AudioCLIP的跨模态对齐损失,强制重建模态与可用模态语义一致。
- 创新点:相比传统统计填充或简单生成模型,本方法创新性地结合了图动态建模、大语言模型上下文引导的语义增强和跨模态对比对齐,实现了在缺失模态下的高质量重构与情感识别。
- 主要实验结果:在IEMOCAP和MELD数据集上,该方法在6种模态缺失场景的平均F1分数(Avg. F1)分别达到69.13%和62.39%,显著优于之前SOTA方法(如MPLMM:67.22%, 60.56%)。在全模态设置下也达到最优(IEMOCAP:73.74% F1; MELD:70.22% F1)。消融实验证实了LLM关键词(带来约1.8-2.6% F1提升)和AudioCLIP对齐(带来约1.2-1.7% F1提升)的有效性。
| 数据集 | 方法 | {a} F1 | {v} F1 | {t} F1 | {a,v} F1 | {a,t} F1 | {v,t} F1 | Avg. F1 |
|---|---|---|---|---|---|---|---|---|
| IEMOCAP | Ours | 61.28 | 58.14 | 70.91 | 69.15 | 78.22 | 77.05 | 69.13 |
| MPLMM | 59.71 | 56.98 | 69.28 | 67.37 | 75.44 | 74.51 | 67.22 | |
| MELD | Ours | 55.21 | 51.64 | 67.71 | 59.97 | 69.67 | 70.15 | 62.39 |
| MPLMM | 52.95 | 50.41 | 65.28 | 58.14 | 68.29 | 68.31 | 60.56 |
- 实际意义:为构建在现实复杂环境下(传感器不稳定、数据部分丢失)仍能稳定工作的情感计算系统提供了有效的解决方案。
- 主要局限性:模态缺失模拟方式(随机丢除)可能与真实场景不完全一致;框架依赖多个预训练模型(BERT, AudioCLIP, DenseNet, Qwen),推理流程相对复杂;未详细分析大语言模型推理带来的额外计算成本。
🏗️ 模型架构
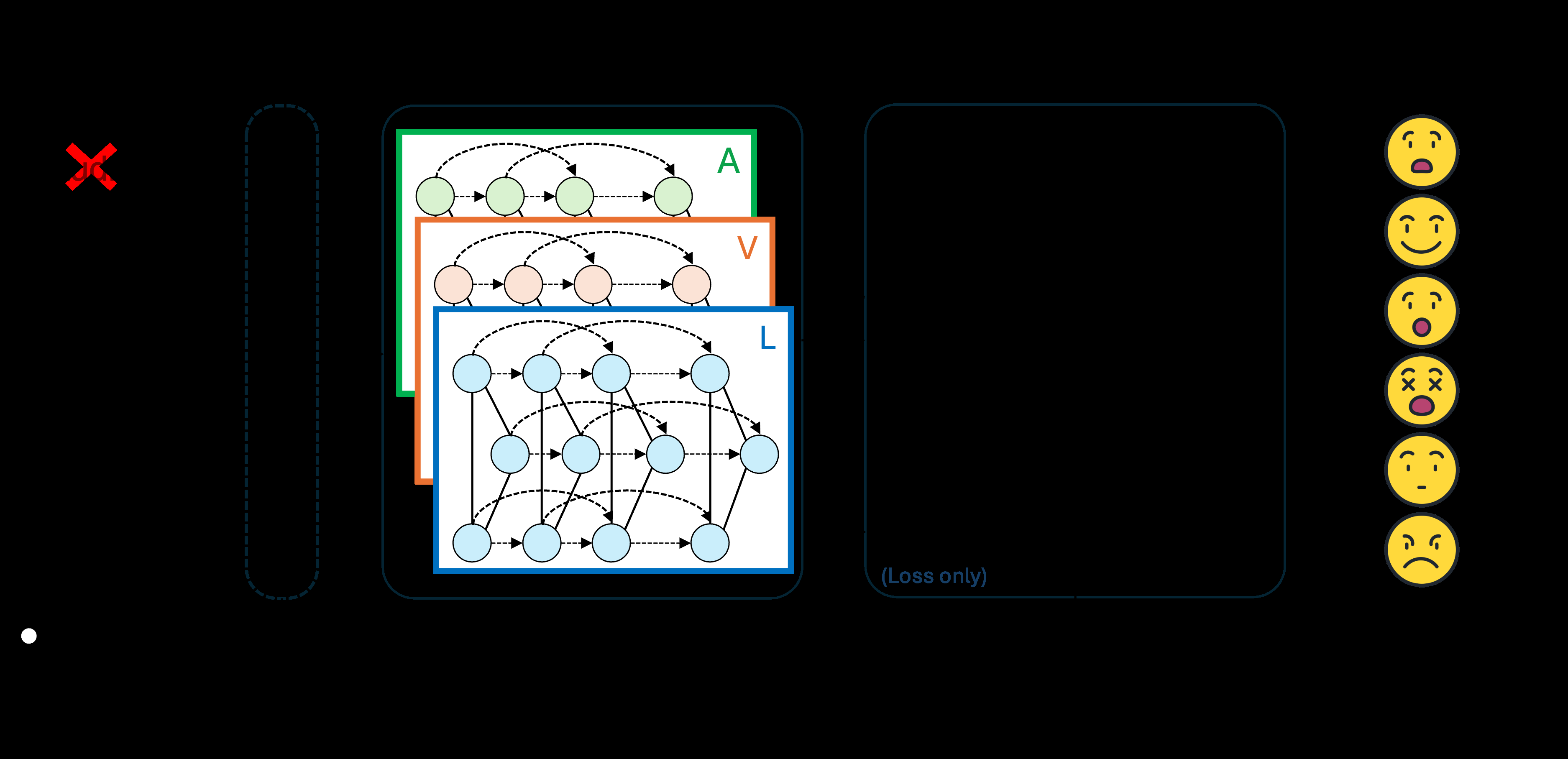 模型架构(如图1所示)是一个端到端的联合优化框架,主要包含以下模块和数据流��
模型架构(如图1所示)是一个端到端的联合优化框架,主要包含以下模块和数据流��
- 输入表示:对于对话中的每个话语\(u_i\),其初始节点表示\(h_i\)由可用模态特征(音频、视频、文本)与说话人嵌入拼接而成(公式1)。缺失模态用0填充。
- 自适应对话图构建与动态建模:
- 图结构:构建图\(G=(V,E)\),节点是话语。边权\(a_{ij}\)由时间衰减、说话人关系(同/异说话人)和模态可用性一致性\(\sigma(\lambda_i, \lambda_j)\)共同决定(公式2)。这鼓励了时间上相邻、尤其是同一说话人的连接,并抑制了模态不匹配的话语之间的噪声传播。
- 图动态演化:节点状态\(h_i(t)\)通过一个由GRU实现的神经ODE函数\(f_{ODE}\)在连续时间上演化(公式3)。通过ODE求解器(如DOPRI5)积分,得到考虑了整个对话图上下文的最终表示\(h_{ctx}^i\)(公式4)。这捕获了动态的、长程的对话依赖关系。
- LLM引导的缺失模态重构:
- 情感关键词提取:使用大语言模型(Qwen-7B)为每个话语生成N个情感关键词。提示(Prompt)包含当前话语文本、前3个预测情感及概率、情感趋势和说话人ID,实现了上下文感知。
- 重构模块:对于缺失模态(如音频),重构器\(f_{rec}^m\)(一个3层MLP)接收可用模态特征、LLM关键词嵌入\(k_i\)、图上下文\(h_{ctx}^i\)和说话人嵌入,生成重构表示\(\hat{h}_i^m\)(公式5)。
- 语义对齐:为了确保重构的音频与可用文本语义一致,使用AudioCLIP编码器计算并最小化它们在语义空间中的L1距离(公式7)。
- 表示融合与预测:最终每个模态的表示\(\tilde{h}_i^m\)由原始特征(若可用)或重构特征(若缺失)组成(公式8)。所有模态特征拼接后,通过一个带有跳跃连接的分类器预测情感概率\(\hat{y}_i\)(公式10-11)。
- 优化:模型通过总损失函数\(L_{total}\)(公式12)联合优化情感分类损失、模态重构损失、跨模态对齐损失和同情感一致性损失。
💡 核心创新点
- 上下文感知的动态图与LLM引导相结合:不仅用改进的图ODE建模说话人和时间动态,更创新地将大语言模型作为“情感关键词提取器”,利用对话历史和说话人信息为每个话语生成条件化的情感关键词。这些关键词作为高质量、高阶的语义特征,用于引导缺失模态的重构,解决了直接使用原始文本噪声大、情感线索不足的问题。
- 跨模态语义对齐损失:引入基于AudioCLIP的对齐损失,强制要求重构的模态(如音频)与可用的其他模态(如文本)在语义空间上接近。这为重构过程提供了明确的语义监督信号,提升了重构特征的语义保真度,而不仅仅是像素/信号层面的相似。
- 模态一致性惩罚的图邻接矩阵:在构建图邻接矩阵时,引入了项\(\sigma(\lambda_i, \lambda_j)\),对模态可用性不一致的节点对进行惩罚。这使得图结构能自适应地反映模态缺失模式,抑制因模态不齐带来的噪声传播,增强了图结构在缺失场景下的鲁棒性。
🔬 细节详述
- 训练数据:IEMOCAP(约7433个话语,6种情感)、MELD(约13708个话语,7种情感)。论文未详细说明预处理和数据增强策略,仅提到遵循先前工作。
- 损失函数:
- \(L_{cls}\):情感分类交叉熵损失。
- \(L_{recon}\):缺失模态重构的L1损失(公式6)。
- \(L_{align}\):重构音频与可用文本在AudioCLIP空间中的L1对齐损失(公式7)。
- \(L_{consist}\):鼓励相同情感类别的话语在重构表示空间中更接近的余弦一致性损失(公式9)。
- 总损失权重:\(\gamma_1=0.3, \gamma_2=0.2, \gamma_3=0.1\)。
- 训练策略:优化器AdamW,学习率1e-4,Batch size 32,训练50个epoch。DGODE模块使用DOPRI5求解器,容差1e-3。
- 关键超参数:图邻接矩阵参数\(\alpha_1=1.0, \alpha_2=0.5, \beta=0.3\)。LLM提取关键词数量N,消融实验显示N=3最佳。节点特征维度由BERT(768)、AudioCLIP(512)、DenseNet(512)和说话人嵌入决定,具体维度未说明。DGODE内部GRU隐藏层大小为256。
- 训练硬件:论文中未提及。
- 推理细节:论文中未提及,应与训练时的ODE求解和分类器前向传播一致。
- 正则化:未明确提及Dropout等技术,但损失函数中的各项本身有正则化效果。
📊 实验结果
主要对比实验和消融实验结果如下表所示。
表1:六种模态缺失场景下的性能对比(Weighted F1 %)
| 数据集 | 方法 | {a} | {v} | {t} | {a,v} | {a,t} | {v,t} | Avg. |
|---|---|---|---|---|---|---|---|---|
| IEMOCAP | MMIN† | 30.67 | 32.41 | 51.82 | 57.59 | 76.93 | 55.95 | 50.89 |
| MPMM | 57.66 | 55.36 | 68.08 | 63.47 | 74.98 | 72.67 | 65.37 | |
| MPLMM | 59.71 | 56.98 | 69.28 | 67.37 | 75.44 | 74.51 | 67.22 | |
| Ours | 61.28 | 58.14 | 70.91 | 69.15 | 78.22 | 77.05 | 69.13 | |
| MELD | MMIN† | 43.12 | 38.05 | 56.21 | 49.77 | 62.41 | 59.88 | 51.57 |
| MPMM† | 51.87 | 49.23 | 64.42 | 56.85 | 67.71 | 67.62 | 59.62 | |
| MPLMM† | 52.95 | 50.41 | 65.28 | 58.14 | 68.29 | 68.31 | 60.56 | |
| Ours | 55.21 | 51.64 | 67.71 | 59.97 | 69.67 | 70.15 | 62.39 |
关键结论:本文方法在所有场景和数据集上均取得最优,平均F1值比第二优方法(MPLMM)在IEMOCAP和MELD上分别高出1.91和1.83个百分点。
表2:全模态条件下的性能对比(Weighted F1 %)
| 方法 | IEMOCAP | MELD |
|---|---|---|
| M3Net [1] | 72.49 | 67.05 |
| Ours | 73.74 | 70.22 |
关键结论:在全模态设置下,本方法也超越了之前基于图的最优方法(如M3Net),表明其统一框架能有效利用完整信息。
表3:关键组件消融实验({v,t}条件下,Weighted F1 %)
| 组件 | IEMOCAP | ∆ | MELD | ∆ |
|---|---|---|---|---|
| Baseline (DGODE) | 72.80 | - | 67.20 | - |
| + LLM Keywords | 75.35 | +2.55 | 68.97 | +1.77 |
| + AudioCLIP Alignment | 77.05 | +1.70 | 70.15 | +1.18 |
关键结论:加入LLM关键词带来最大提升,AudioCLIP对齐进一步提升性能,证实了两个核心组件的有效性。
表4:LLM提取关键词数量消融({v,t}条件下,Weighted F1 %)
| # Keywords | IEMOCAP | MELD |
|---|---|---|
| 1 | 75.92 | 69.23 |
| 3 | 77.05 | 70.15 |
| 5 | 76.48 | 69.87 |
关键结论:3个关键词是最佳平衡点,过少信息不足,过多引入噪声。
表5:不同特征表示对比({v,t}条件下,Weighted F1 %)
| 模态 | 特征 | IEMOCAP | MELD |
|---|---|---|---|
| 音频 | openSMILE | 75.73 | 69.31 |
| AudioCLIP (Ours) | 77.05 | 70.15 | |
| 文本 | Raw text | 76.21 | 69.58 |
| LLM keywords (Ours) | 77.05 | 70.15 |
关键结论��AudioCLIP音频特征显著优于传统openSMILE特征;LLM提取的关键词优于原始文本特征,证明了其信息增益。
表6:不同骨干架构对比({v,t}条件下,Weighted F1 %)
| Architecture | IEMOCAP | MELD |
|---|---|---|
| GCN | 74.12 | 68.45 |
| Transformer | 75.38 | 69.28 |
| DGODE (Ours) | 77.05 | 70.15 |
关键结论:连续时间的图ODE模型在捕获对话动态上优于离散GCN和Transformer。
⚖️ 评分理由
- 学术质量(6.5/7):论文提出了一个创新且有效的统一框架,技术路线清晰,模块设计合理。实验非常充分,覆盖了多种对比方法、多种缺失场景和全面的消融研究,数据详实,证据可信。扣分点在于未探讨更现实的模态缺失模式(非随机),且对LLM引入的效率影响缺乏分析。
- 选题价值(1.5/2):多模态鲁棒情感识别是对话AI落地的重要一环,课题具有明确的研究价值和应用前景。对于关注多模态融合、音频特征增强的读者有直接参考意义。
- 开源与复现加成(0.8/1):提供了核心代码仓库链接,复现所需的大部分超参数和训练设置已公开。未提供预训练模型权重、详细的训练硬件信息和更完整的配置文件,因此加成未给满分。