📄 Content-Preserving Speech Representation Learning Via Adaptive Segment-Level Alignment
#语音识别 #自监督学习 #数据增强 #基准测试 #鲁棒性
✅ 7.5/10 | 前25% | #语音识别 | #自监督学习 | #数据增强 #基准测试
学术质量 7.5/7 | 选题价值 7.5/2 | 复现加成 7.0 | 置信度 高
👥 作者与机构
- 第一作者:Ling Dong(昆明理工大学,云南人工智能重点实验室)
- 通讯作者:Zhengtao Yu(昆明理工大学,云南人工智能重点实验室),Yuxin Huang(昆明理工大学,云南人工智能重点实验室)
- 作者列表:Ling Dong(昆明理工大学,云南人工智能重点实验室),Wenjun Wang(昆明理工大学,云南人工智能重点实验室),Zhengtao Yu(昆明理工大学,云南人工智能重点实验室),Yan Xiang(昆明理工大学,云南人工智能重点实验室),Yantuan Xian(昆明理工大学,云南人工智能重点实验室),Yuxin Huang(昆明理工大学,云南人工智能重点实验室)
💡 毒舌点评
亮点:方法设计轻量高效,仅需100小时(远少于SPIN的356小时)的自监督微调即可在多个内容相关任务上取得显著提升,尤其是音素识别错误率(PER)大幅下降。短板:核心创新(结构熵分割)虽然巧妙,但严重依赖预训练好的S3M(如HuBERT/WavLM),并非从头构建,其普适性和在更复杂场景(如极低资源、多语言)下的有效性有待进一步验证,且引入的结构熵计算(图构建与优化)会带来一定的计算开销。
🔗 开源详情
- 代码:论文中未提及明确的开源代码仓库链接。
- 模型权重:未提及开源本方法微调后的模型权重。上游预训练模型(HuBERT, WavLM)提供了下载链接。
- 数据集:使用公开的LibriSpeech和DEMAND数据集,但论文未提及提供处理好的增强数据集。
- Demo:未提供在线演示。
- 复现材料:提供了非常详细的训练配置,包括模型架构、超参数、优化设置、训练硬件等,构成良好的复现基础。
- 论文中引用的开源项目:引用了
HuBERT和WavLM作为上游模型。代码框架和评测工具可能基于s3prl(论文提及遵循其评测设置)。
📌 核心摘要
本文旨在解决自监督语音模型(S3Ms)提取的表征会纠缠语音内容与说话人/环境信息的问题,这影响了其在内容导向任务上的性能。为此,论文提出了一种轻量的自监督微调框架,核心是通过结构熵(SE)对帧级表征进行在线、自适应的分割,获得语言学上有意义的段级单元,然后在一个教师-学生架构中,教师网络从干净语音中提取这些段原型,学生网络通过注意力机制对受扰动的语音进行软分割并对齐,从而学习内容保持的鲁棒表征。与现有方法(如固定聚类数的SPIN、帧级对齐的SCORE)相比,其新意在于:1)实现了无需预设分割数的在线自适应分割;2)在段级而非帧级进行对齐,更稳定;3)整个框架轻量且端到端。实验在SUPERB基准测试的语音识别(ASR)、音素识别(PR)、关键词检索(KS)等任务上进行,结果显示,该方法将HuBERT-base的PR错误率(PER)从5.41降至4.01,WavLM-base的PER从4.84降至3.82,在多个任务上优于或匹配现有最佳微调方法,且仅需100小时训练。该工作的实际意义在于能以较低成本显著提升现有预训练语音模型在内容相关任务上的性能与鲁棒性。主要局限性在于其依赖现有的强大预训练模型,且未探讨在更复杂噪声或多语言场景下的表现。
🏗️ 模型架构
论文提出的框架整体如图1所示,基于BYOL(Bootstrap Your Own Latent)式的自蒸馏框架。
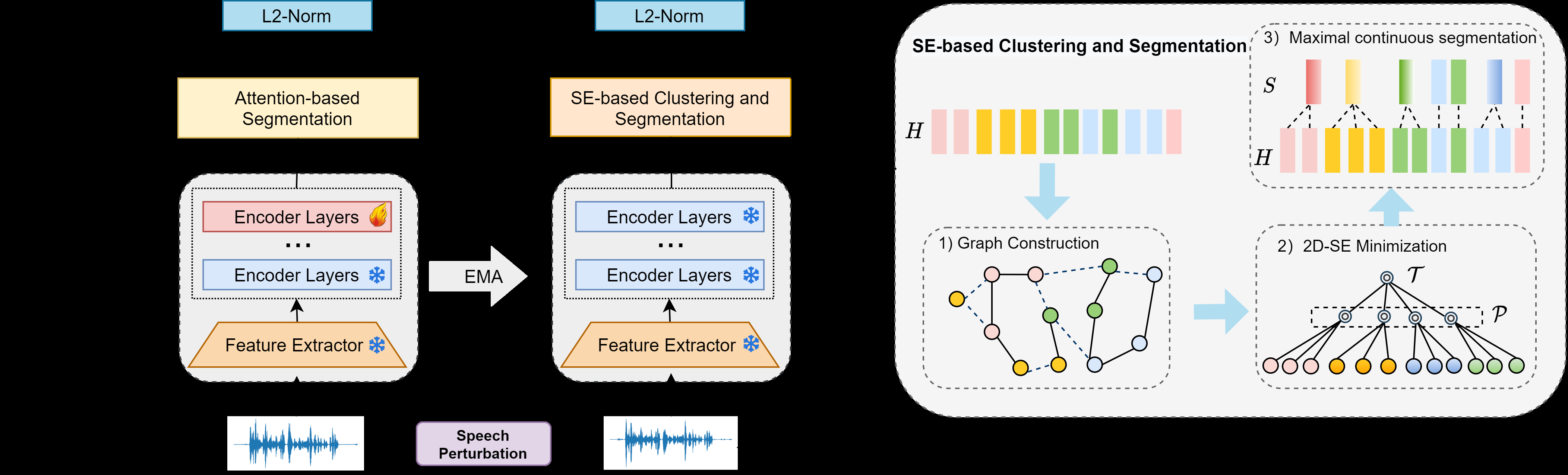 图1:提出的自监督微调框架整体架构(左)和基于SE的教师网络聚类与分割示意图(右)。
图1:提出的自监督微调框架整体架构(左)和基于SE的教师网络聚类与分割示意图(右)。
整体流程:
- 输入:原始语音
X和经过速度、说话人、噪声扰动后的增强版本X'。 - 编码:
X通过教师编码器提取隐藏状态H;X'通过学生编码器提取隐藏状态H'。编码器均来自预训练的S3M(如HuBERT/WavLM)。 - 核心任务(辅助对齐任务):在标准的对比损失(可能来自原始自监督任务)之外,引入一个段级对齐损失
L_seg,以鼓励内容保持。 - 教师更新:教师网络的参数
θ_teacher通过学生网络参数θ_student的指数移动平均(EMA)进行更新(公式8)。
- 输入:原始语音
教师分支(用于生成对齐目标):
- 图构建:以教师隐藏状态
H = {h1, ..., hT}的每个帧为节点,构建相似度图G=(V,E,W)。边权重w(i,j)为两个帧特征的余弦相似度。仅当相似度超过阈值时才创建边,阈值通过搜索最小化一维结构熵(1D-SE)来确定。 - SE分割:对图
G执行二维结构熵(2D-SE)最小化,得到帧的划分P = {p1, ..., pM}。为保证时间一致性,每个划分pm被分解为最大的连续片段,最终得到有序片段集合S = {S1, ..., SN}。 - 原型计算:对每个片段
Si内的帧特征进行平均池化,得到该片段的原型表示si(公式4)。这些原型{s1, ..., sN}作为对齐的“教师”目标。
- 图构建:以教师隐藏状态
学生分支(用于生成待对齐表示):
- 软分段器:学生网络产生特征
H' = {h'1, ..., h'T'}。通过可学习的投影矩阵Wq和Wk,将H'和教师原型S映射到共享潜在空间,计算帧对片段的软分配矩阵A = softmax(QK^T)(公式5)。 - 段表示聚合:学生网络的帧特征根据软分配矩阵
A进行加权聚合,得到每个片段对应的“学生”段表示^si(公式6)。此过程可微分。 - 段级对齐:将学生段表示
^si与教师原型si进行L2归一化后,计算均方误差(MSE)损失L_seg(公式7)。
- 软分段器:学生网络产生特征
关键设计选择及动机:
- 结构熵分割:动机是克服帧级对齐的脆弱性和固定聚类数的局限性。SE能在线、自适应地发现与内容结构对齐的、粒度适中的片段,无需外部强制对齐工具或预定义码本大小。
- 段级而非帧级对齐:动机是段级单元包含更丰富的上下文和更稳定的时间结构,能更好地抵抗声学扰动,从而学习到更鲁棒的内容表示。
- EMA教师:动机是通过平滑的教师目标提供稳定的学习信号,防止训练崩溃,这是自蒸馏框架(如BYOL)的常见且有效做法。
- 注意力软分段:动机是使分段过程可微分,允许端到端训练,并能灵活处理因速度扰动导致的时长差异。
💡 核心创新点
- 基于结构熵的在线自适应语音分割:这是最核心的创新。它利用结构熵最小化对语音帧的相似度图进行划分,能够在线、无监督、无需预设分割数量地发现时序上连贯、内容上一致的片段单元。这克服了现有方法(如K-Means聚类、固定间隔合并)需要离线统计或预定义参数的限制,使模型能更灵活地适应输入语音的内在结构。
- 端到端的段级自蒸馏对齐框架:将SE分割得到的教师原型与学生网络通过注意力机制产生的软段表示进行对齐。这种设计:
- 实现了无需外部强制对齐工具(如MFA)的端到端训练。
- 通过软分配允许梯度回传,优化整个分割与对齐过程。
- 在段级进行MSE对齐,比帧级对齐更稳定,能更好地建模语言单元。
- 轻量高效的微调方案:整个框架旨在高效改进预训练模型。实验表明,仅需更新学生网络的顶层6-8层参数(约42.7M),并在100小时(单张4090 GPU上约3600步)的自监督微调下,就能在多个下游任务上取得显著提升,远比从头训练(如DinoSR)或更长时间微调(如SPIN的356小时)更经济。
🔬 细节详述
- 训练数据:使用LibriSpeech的
train-clean-100子集(约100小时)进行微调。 - 数据增强:对原始语音
X生成扰动版本X',依次随机应用:- 速度扰动:因子为0.9, 1.0, 1.1, 1.2。
- 说话人扰动:采用[18]中的算法,随机缩放共振峰频率和基频(F0),并随机进行均衡化。
- 加性噪声:使用DEMAND数据库中的噪声,信噪比(SNR)在5到20dB之间均匀采样。 所有增强操作是随机采样并依次应用的。
- 损失函数:主要介绍了段级对齐损失
L_seg(公式7),即归一化后的教师原型与学生段表示之间的均方误差。论文未明确提及是否同时优化了原始S3M的预训练目标(如掩码预测损失),但基于其“自监督微调”的设定和框架描述,很可能是在原有损失基础上增加了L_seg。 - 训练策略:
- 优化器:AdamW。
- 学习率:5e-5。
- 批次大小:8。
- 训练步数:3600步。
- 微调深度:仅微调学生编码器的第7至12层(顶部6层)。
- EMA动量:教师网络通过EMA更新,动量系数
α=0.90。 - 教师分割:教师隐藏状态(768维)用于执行2D-SE聚类。
- 关键超参数:模型规模基于HuBERT-base或WavLM-base(具体参数量未说明,但base模型通常约90M参数)。微调时更新参数约42.7M。结构熵计算中,图的边权重阈值通过搜索确定。
- 训练硬件:单张NVIDIA-4090 GPU。
- 推理细节:论文未明确说明推理时的解码策略等细节,因为其主要贡献在表征学习阶段。
- 正则化或稳定训练技巧:核心的稳定训练技巧是EMA更新教师网络。消融实验(表3)显示,禁用EMA(
α=1.0)会导致性能急剧下降(PER从4.01升至4.57)。
📊 实验结果
主要在SUPERB基准测试的内容相关任务上进行评估。任务包括:自动语音识别(ASR,WER↓)、音素识别(PR,PER↓)、关键词检索(QbE,MTWV↑)、关键词识别(KS,Acc↑)、意图分类(IC,Acc↑)、槽位填充(SF,CER↓/F1↑)。
表1:在SUPERB基准测试中内容相关下游任务上与基线模型的对比。
| 模型 | SSFT时间(小时) | ASR (WER ↓) | PR (PER ↓) | QbE (MTWV ↑) | KS (Acc ↑) | IC (Acc ↑) | SF (CER ↓/ F1 ↑) |
|---|---|---|---|---|---|---|---|
| HuBERT-base | 0 | 6.42 | 5.41 | 7.36 | 96.30 | 98.34 | 88.53 / 25.20 |
| ContentVec500 | 76K | 5.70 | 4.54 | 5.90 | 96.40 | 99.10 | 89.60 / 23.60 |
| HuBERT-base + SPIN256 | 356 | 6.34 | 4.39 | 9.12 | 96.53 | 98.34 | 89.00 / 24.32 |
| HuBERT-base + SCORE | 100 | 6.35 | 4.84 | 8.10 | 96.04 | 96.78 | 85.95 / 29.47 |
| HuBERT-base + LASER | 100 | 6.18 | 4.61 | 8.91 | 95.84 | 98.62 | 86.09 / 28.68 |
| HuBERT-base + Ours | 100 | 6.09 | 4.01 | 8.98 | 96.95 | 98.95 | 89.57 / 23.31 |
| WavLM-base | 0 | 6.21 | 4.84 | 8.70 | 96.79 | 98.63 | 89.38 / 22.86 |
| WavLM-base + SPIN256 | 356 | 5.88 | 4.18 | 8.79 | 96.20 | 98.52 | 88.84 / 24.06 |
| WavLM-base + SCORE | 100 | 6.15 | 4.72 | 9.18 | 96.29 | 97.86 | 88.63 / 25.10 |
| WavLM-base + LASER | 100 | 5.92 | 4.28 | 9.27 | 95.74 | 98.99 | 87.77 / 26.19 |
| WavLM-base + Ours | 100 | 5.80 | 3.82 | 9.28 | 96.99 | 98.81 | 90.24 / 22.27 |
- 关键发现:
- 本文方法(Ours)在HuBERT-base和WavLM-base模型上,在几乎所有任务上都取得了最佳或第二佳的结果。
- 最显著的提升体现在音素识别(PR)任务上:HuBERT的PER从5.41降至4.01(绝对降低1.4),WavLM的PER从4.84降至3.82(绝对降低1.02),优于所有基线,包括SPIN。
- 在关键词识别(KS) 和意图分类(IC) 上也达到了最���水平。
- 与帧级对齐方法(SCORE, LASER)相比,本文的段级方法表现更优且稳定。
- 本文方法仅需100小时微调,效率远高于SPIN(356小时)和ContentVec(76K小时)。
表2:不同对齐粒度在PR任务上的比较(PER ↓)。
| 对齐粒度 | PR (PER ↓) |
|---|---|
| Frame | 4.20 |
| MFA-Merge | 4.12 |
| KMeans-Merge (K=256) | 3.97 |
| AdjMerge (每10帧) | 4.70 |
| AdjMerge (每20帧) | 5.07 |
| SE-Merge (ours) | 4.01 |
- 关键发现:段级方法(MFA, KMeans, SE)普遍优于帧级对齐。KMeans-Merge因利用离线全局统计略优于SE-Merge,但SE-Merge提供了在线、自适应的竞争性替代方案。
表3:PR任务上的超参数分析。
| 设置 | PR (PER ↓) |
|---|---|
| 最优:所有增强,α=0.90,顶层6层 | 4.01 |
| 数据增强:- 速度扰动 | 4.04 |
| 数据增强:- 说话人扰动 | 4.20 |
| 数据增强:- 加性噪声 | 4.24 |
| EMA动量:α = 1.00 | 4.57 |
| EMA动量:α = 0.95 | 4.03 |
| EMA动量:α = 0.80 | 4.06 |
| 微调层:顶层8层 | 4.14 |
| 微调层:顶层4层 | 4.04 |
| 微调层:顶层2层 | 4.44 |
- 关键发现:所有数据增强都有帮助,其中说话人扰动提升最大。EMA对于稳定训练至关重要。微调顶层6层取得了最佳效果与效率平衡。
表4:离散单元质量对比。
| 模型 | ClsPur ↑ | PhnPur ↑ | PNMI ↑ |
|---|---|---|---|
| HuBERT | 0.154 | 0.639 | 0.630 |
| ContentVec500 | 0.154 | 0.639 | 0.629 |
| HuBERT + SPIN256 | 0.150 | 0.641 | 0.655 |
| HuBERT + Ours | 0.168 | 0.635 | 0.640 |
| WavLM | 0.178 | 0.624 | 0.640 |
| WavLM + SPIN256 | 0.137 | 0.644 | 0.658 |
| WavLM + Ours | 0.189 | 0.645 | 0.663 |
- 关键发现:本文方法提升了HuBERT和WavLM的聚类纯度(ClsPur),在WavLM上实现了最佳的音素归一化互信息(PNMI),表明学习到的表示与音素内容的相关性更强。
图2:基于SE的分割可视化。
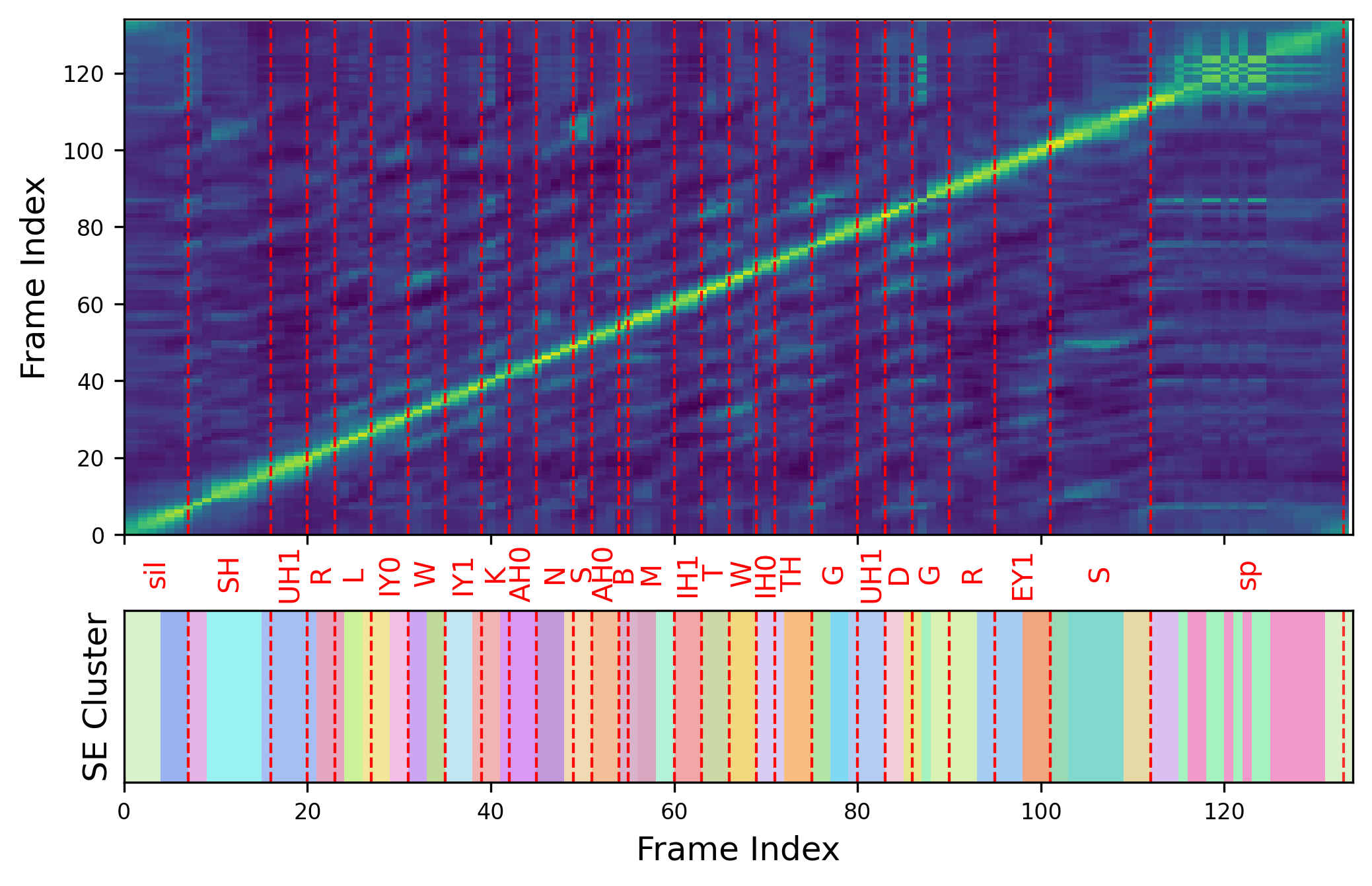 图2:基于SE的HuBERT特征聚类(下)与MFA音素边界(上)的叠加可视化。 红色虚线是MFA音素边界,不同颜色代表SE聚类分配的不同簇。关键结论:SE聚类产生的边界比音素边界更细,但与音素边界对齐良好,表明该方法能在无监督情况下有效捕捉底层内容结构。
图2:基于SE的HuBERT特征聚类(下)与MFA音素边界(上)的叠加可视化。 红色虚线是MFA音素边界,不同颜色代表SE聚类分配的不同簇。关键结论:SE聚类产生的边界比音素边界更细,但与音素边界对齐良好,表明该方法能在无监督情况下有效捕捉底层内容结构。
⚖️ 评分理由
学术质量:6.0/7
- 创新性(1.8/2.5):将结构熵引入语音表示学习的分割阶段是新颖的,解决了自动确定分割粒度的问题,但整体框架仍建立在已有的自蒸馏(BYOL)和自监督微调范式之上。
- 技术正确性(1.5/1.5):方法描述清晰,公式推导正确,实验设置合理。
- 实验充分性(1.5/1.5):在权威基准(SUPERB)上与多种基线进行了全面对比,提供了详细的消融实验(粒度、超参数、单元质量),并包含可视化分析,实验非常充分。
- 证据可信度(1.2/1.5):结果一致且显著,尤其在PR任务上提升明显,证据可信。部分对比模型(如LASER)引用的是预印本,但主流基线(SPIN, SCORE, ContentVec)均为已发表工作。
选题价值:1.5/2
- 前沿性(0.7/1.0):内容保持的语音表示学习是当前语音自监督学习领域持续关注的热点问题。
- 潜在影响与应用空间(0.8/1.0):改进的表征能直接提升语音识别、语音搜索等众多下游任务的性能和鲁棒性,具有明确的实用价值。
- 与读者相关性(高):对从事语音识别、语音表示学习、自监督学习的研究人员和工程师有较高参考价值。
开源与复现加成:0.0/1
- 论文提供了近乎详尽的超参数和训练细节,极大便利了复现。
- 然而,论文未明确声明将公开代码、模型权重或处理后的数据集,也未提供可立即运行的Demo或完整配置文件链接。因此,根据规则,仅给予中性加分(0分)。复现仍需依赖对论文描述的理解和上游模型的准备。