📄 Content Leakage in Librispeech and its Impact on the Privacy Evaluation of Speaker Anonymization
#语音匿名化 #模型评估 #数据集 #鲁棒性
✅ 7.5/10 | 前25% | #语音匿名化 | #模型评估 #数据集 | #模型评估 #数据集
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Carlos Franzreb(DFKI, 德国)
- 通讯作者:未说明
- 作者列表:Carlos Franzreb(DFKI, 德国)、Arnab Das(DFKI, 德国)、Tim Polzehl(DFKI, 德国)、Sebastian Möller(柏林工业大学, 德国)
💡 毒舌点评
亮点:论文像一名侦探,敏锐地抓住了“说话人匿名化”评估中的一个核心悖论——如果匿名化旨在隐藏身份但保留内容,而内容本身却能暴露身份,那么评估就失去了公平性。研究通过严密的实验设计,将这个潜在的“房间里的大象”清晰地揭示了出来。 短板:文章的核心贡献是提出了问题并推荐了一个更好的“考场”(EdAcc),而非提供解决“考试作弊”(内容泄露攻击)的新“防作弊技术”或新的匿名化算法。对于寻求具体算法改进的读者而言,其直接的技术增量有限。
🔗 开源详情
- 代码:论文中未提及提供新的代码仓库。评估框架SpAnE [5]是作者此前工作,但论文未给出链接。
- 模型权重:未提及公开本文使用的模型权重。
- 数据集:使用了两个公开数据集Librispeech和EdAcc。论文未提供EdAcc的获取链接,但EdAcc [4]是公开发布的。
- Demo:未提及。
- 复现材料:论文详细描述了评估流程、数据划分、特征提取方法(音素识别器、ECAPA-TDNN),足以让同行按照相同设置进行复现分析。
- 论文中引用的开源项目:
- SpeechBrain ECAPA-TDNN [7]
- Whisper ASR [10]
- NeMo TTS (FastPitch + HiFiGAN) [11, 12]
- SpAnE评估框架 [5]
- private kNN-VC中的音素识别器 [15]
- g2p模型和CMU发音词典(用于音素转换)
📌 核心摘要
- 问题:当前评估说话人匿名化系统(隐私保护能力)的标准数据集Librispeech存在严重缺陷:由于是有声书录音,不同说话人朗读的书籍内容差异巨大,导致攻击者可以仅通过识别说话的“词汇内容”来识别身份,即使身份信息(音色等)已被完美匿名化。
- 方法:作者提出并验证了这一假设。他们采用了一个“完美”的匿名化器(STT-TTS流水线),它转换了所有副语言信息,只保留转录文本。通过设计仅利用音素频率、音素时长或纯音素序列的攻击者,证明了即使匿名化后,Librispeech的说话人仍能被较好地识别(EER低至32.3%),其根源就是泄露的内容。
- 创新:1) 首次系统性地揭示了Librispeech内容泄露对隐私评估的干扰;2) 提出并证明EdAcc(自发对话数据集)的内容泄露显著更少,是更公平的评估数据集;3) 提出利用EdAcc的丰富元数据(如口音)进行“人口统计学分段”的隐私评估(内/组间EER),以检测匿名化对不同人群的公平性。
- 主要实验结果:关键数据见下表。实验表明,对于STT-TTS匿名化后的Librispeech,使用音素时长特征攻击的EER(34.5%)与使用频谱图特征(34.8%)几乎相同,证实了攻击完全基于内容。而EdAcc在相同条件下的EER显著更高(45.0%),证明其内容泄露更少。
数据集 特征 原始语音EER(%) STT-TTS匿名化EER(%) Librispeech 频谱图 0.4 34.8 音素+时长 23.7 34.5 纯音素 30.4 32.3 EdAcc 频谱图 6.5 45.9 音素+时长 39.0 45.0 纯音素 42.1 48.5 - 实际意义:该研究对语音隐私评估社区有重要警示作用,建议在评估匿名化系统时,必须考虑或换用像EdAcc这样内容泄露更少的数据集,以获得更准确、更公平的隐私保护性能估计。其提出的分段评估方法有助于发现匿名化对不同人群的不公平性。
- 局限性:EdAcc数据集规模远小于Librispeech(22小时 vs 数百小时),可能带来训练数据不足的问题。论文主要诊断了问题,但并未提出直接针对“内容泄露攻击”的新防御方法。内容泄露在EdAcc中依然存在(尽管较弱),并非完全解决。
🏗️ 模型架构
本文并非提出一个新的端到端匿名化模型,而是一项针对评估方法论的分析研究。其核心“架构”是评估流程:
- 输入:原始语音或经匿名化处理后的语音(主要使用STT-TTS流水线)。
- 攻击者(说话人识别模型):采用ECAPA-TDNN(来自SpeechBrain),并探索了两种输入特征:1)标准梅尔频谱图;2)自定义的“音素+时长”或“纯音素”表示矩阵。后者是一种创新的实验设计,旨在剥离所有副语言信息,仅保留语言内容通道。
- 评估流程:遵循VoicePrivacy挑战的范式。攻击者在匿名化语音上训练说话人识别模型。然后,用该模型对“试验集”匿名语音进行识别,与平均化的“注册集”匿名语音的嵌入向量比较(余弦距离),计算等错误率(EER)。
- 数据流:语音 → 特征提取(梅尔频谱图或音素识别器) → 说话人嵌入提取(ECAPA-TDNN) → 身份验证(与注册嵌入比较) → EER。
- 关键设计:使用“完美”的STT-TTS匿名器作为上界,并设计仅基于音素信息的特征表示,这两者是隔离并证明“内容泄露”的核心手段。
💡 核心创新点
- 揭示Librispeech内容泄露漏洞:明确指出Librispeech有声书数据的“一书一读”模式导致词汇内容高度区分性,成为匿名化评估中的“身份后门”。这是对主流评估基准的重要批判性发现。
- 确立EdAcc作为更优评估数据集:通过实验证明,自发对话数据集EdAcc的内容泄露显著低于Librispeech,迫使攻击者去寻找其他身份线索(如韵律),从而更准确地评估匿名化技术的核心能力。
- 提出“人口统计学分段隐私评估”方法:利用EdAcc的丰富元数据(口音、母语者状态等),创新性地提出“组内EER”和“组间EER”指标,以评估匿名化对不同人群的保护公平性,这是单一EER指标无法提供的洞察。
🔬 细节详述
- 训练数据:说话人识别器主要使用Librispeech train-clean-360训练,在部分实验中加入EdAcc dev集进行联合训练。匿名化器使用公开的Whisper-small(ASR)和NeMo多说话人TTS流水线。
- 损失函数:论文中未提及新设计的损失函数。说话人识别器(ECAPA-TDNN)的训练损失未详细说明,采用SpeechBrain默认设置。
- 训练策略:未详细说明ECAPA-TDNN的训练超参数(如学习率、batch size),但基于公开的SpeechBrain库。
- 关键超参数:使用了标准ECAPA-TDNN(未按VPC 2024缩减通道)。音素识别器来自private kNN-VC,在Librispeech train-clean-100上训练,PER为2%。
- 训练硬件:论文中未说明训练所用的GPU型号和数量。
- 推理细节:评估时,每个说话人使用20条语音注册,其余语音用于试验。使用余弦距离进行匹配。
- 正则化:未提及。
📊 实验结果
主要实验结果已在核心摘要的表格中总结。此外:
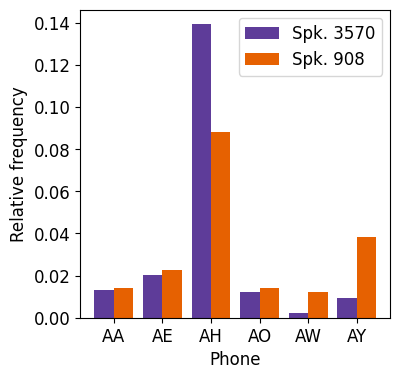
- 相关性分析:音素频率的平均余弦距离与说话人EER的皮尔逊相关系数r=0.59(图2显示了两名说话人以A开头的音素频率差异)。
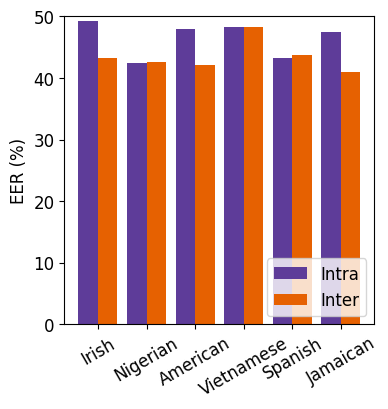
- 口音分段评估(图3):展示了STT-TTS匿名化后,不同口音说话人组的内/组间EER。西班牙/尼日利亚口音的EER较低(易识别),爱尔兰/美国/牙买加口音的组间EER低但组内EER高。
- 基线对比:与VoicePrivacy 2024(VPC 2024)的结果对比,指出使用更大的ECAPA-TDNN会降低EER(从48.2%降至34.8%),表明模型容量增加能更好地利用内容泄露。
图1: pdf-image-page2-idx0
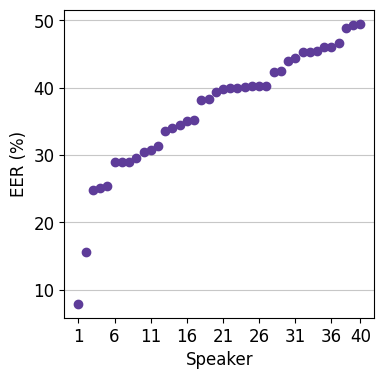
 (图1描述:展示了Librispeech中每个说话人被STT-TTS匿名化后的EER。EER值跨度很大,从低于10%到超过50%,直观地表明某些说话人由于内容独特而更容易被识别。)
(图1描述:展示了Librispeech中每个说话人被STT-TTS匿名化后的EER。EER值跨度很大,从低于10%到超过50%,直观地表明某些说话人由于内容独特而更容易被识别。)
图2: pdf-image-page2-idx1
 (图2描述:对比了两名Librispeech说话人(3570和908)的音素频率。说话人3570的“AH”音素频率更高,而说话人908的“AY”频率更高,这与他们的EER差异(7.9% vs 33.5%)相关。)
(图2描述:对比了两名Librispeech说话人(3570和908)的音素频率。说话人3570的“AH”音素频率更高,而说话人908的“AY”频率更高,这与他们的EER差异(7.9% vs 33.5%)相关。)
图3: pdf-image-page2-idx2
 (图3描述:展示了STT-TTS匿名化后,不同口音人群的组内EER(Intra-EER)和组间EER(Inter-EER)。揭示了匿名化对不同口音群体提供的隐私保护水平存在差异。)
(图3描述:展示了STT-TTS匿名化后,不同口音人群的组内EER(Intra-EER)和组间EER(Inter-EER)。揭示了匿名化对不同口音群体提供的隐私保护水平存在差异。)
⚖️ 评分理由
- 学术质量:5.5/7:论文在问题诊断和评估方法改进上做得非常扎实。创新点在于视角的转换(从内容泄露角度审视评估)和评估维度的扩展(人口统计分段)。技术路径清晰,实验设计能有力支持结论。但因其核心是分析而非构建新模型或算法,在学术突破性上稍显不足。
- 选题价值:1.5/2:选题切中要害,直接影响该领域研究的可信度。对从事语音隐私、说话人识别的学者和工程师有直接参考价值。虽然领域相对细分,但其结论具有普遍意义。
- 开源与复现加成:0.5/1:虽然没有开源新代码,但论文完全基于公开工具和数据集,且描述了详细的复现步骤,降低了复现门槛。