📄 Constructing Composite Features for Interpretable Music-Tagging
#音乐信息检索 #遗传编程 #音频分类 #开源工具
✅ 7.5/10 | 前25% | #音乐信息检索 | #遗传编程 | #音频分类 #开源工具
学术质量 6.5/7 | 选题价值 0.0/2 | 复现加成 +1.0 | 置信度 高
👥 作者与机构
- 第一作者:Chenhao Xue (University of Oxford)
- 通讯作者:未说明
- 作者列表:Chenhao Xue (University of Oxford), Weitao Hu (Independent Researcher), Joyraj Chakraborty (University of Oxford), Zhijin Guo (University of Oxford), Kang Li (University of Oxford), Tianyu Shi (University of Toronto), Martin Reed (University of Essex), Nikolaos Thomos (University of Essex)
💡 毒舌点评
亮点:论文将遗传编程(GP)系统地应用于音乐特征构造,成功地将“可解释性”从特征重要性分析提升到了特征组合公式本身的透明化,为对抗深度学习黑箱提供了一条优雅的符号回归路径。短板:实验所用的GTZAN数据集已被认为过于简单且存在缺陷,在此之上取得的显著提升(如5%准确率)难以证明方法的普适性和先进性;同时,论文声称“接近深度学习SOTA”,但缺乏对当前最强端到端模型(如PANNs, Transformer)在相同条件下的公平对比,使得SOTA宣称略显单薄。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:https://github.com/ChenHX111/GP-Music-Tagging。
- 模型权重:未提及公开GP进化出的特征表达式或XGBoost模型权重。
- 数据集:MTG-Jamendo和GTZAN均为公开数据集,论文中给出了引用。
- Demo:未提及。
- 复现材料:论文详细给出了GP库(DEAP)、所有超参数(种群大小、代数、交叉突变率、复杂度惩罚λ、XGBoost参数)、数据集划分信息(参考文献[5, 26]),复现信息充分。
- 引用的开源项目:Essentia库、Omnizart库、DEAP库、XGBoost。
📌 核心摘要
- 要解决的问题:音乐标签任务中,深度学习模型性能优越但缺乏可解释性,而传统手工特征方法可解释但无法系统地发现有效的特征组合。
- 方法核心:提出一个基于遗传编程(GP)的流水线,通过自动进化数学表达式来组合基础音乐特征(如MFCC、和声特征),生成可解释的复合特征,再输入XGBoost分类器进行标签预测。
- 新在哪里:不同于传统的特征加权或简单的融合,该方法能自动发现特征间复杂的线性、非线性及条件交互关系,且整个组合公式是透明的、人类可读的。
- 主要实验结果:在MTG-Jamendo(多标签)和GTZAN(多分类)数据集上,GP增强的特征集均优于基线。例如,在GTZAN上,使用ALL62基础特征,GP500将准确率从76.5%提升至80.5%(+4.0%);使用E23特征,提升从74.0%到79.0%(+5.0%)。大部分性能增益在数百次GP评估内即可获得。分析了最优复合特征的表达式,发现其包含线性、非线性和条件形式,揭示了有效的特征交互模式(见下表)。
数据集/基础特征 指标 基线 GP最佳结果 MTG-Jamendo (ALL62) AUC 0.727 0.730 GTZAN (ALL62) ACC 0.765 0.805 MTG-Jamendo (E23) AUC 0.719 0.724 GTZAN (E23) ACC 0.740 0.790 - 实际意义:为音乐信息检索乃至更广泛的音频分析提供了一种新的、兼顾性能与可解释性的特征工程范式,有助于开发者理解模型决策并发现数据偏见。
- 主要局限性:实验规模相对较小,且依赖于可能已过时的基准数据集;方法的计算成本随特征数量增长,且对基础特征的质量和完备性仍有依赖。
🏗️ 模型架构
论文提出的不是传统的端到端神经网络,而是一个三阶段的特征构建与建模流水线(见图1)。
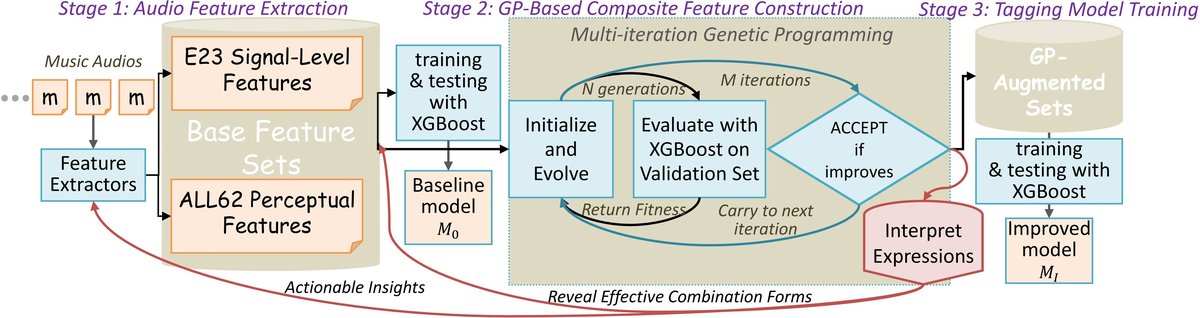
- 音频特征提取:输入音频,提取两组不同抽象层次的基础特征:
- 信号级特征 (E23):使用Essentia库提取的23维特征,如响度、BPM、过零率、频谱质心等。
- 低/中级感知特征 (ALL62):包含E23特征、32个基于和声本体的功能和声特征(通过Omnizart和SPARQL获得),以及7个由CNN从MFCC中回归出的感知特征。
- GP复合特征构建:这是核心创新阶段。
- 输入:标准化后的基础特征集
X = {x1, ..., xn}。 优化目标:找到一个函数集合f1, ..., fM,最大化标签预测性能P(X ∪ {f1(X), ..., fM(X)}, y),同时惩罚表达式复杂度λ Σ ℓ(fi)以鼓励简洁性。 - GP个体:每个个体是一棵表达式树,由基础特征、常数(从U[-2,2]采样)和算子集合(算术、三角、双曲、激活函数、条件语句)构成,输出一个标量值,即一个新的复合特征。
- 进化过程:采用锦标赛选择、单点子树交叉(概率0.8)、均匀子树突变(概率0.1)。每一代用XGBoost在验证集上的AUC/准确度评估适应度。通过迭代,逐个添加最有用的复合特征。
- 输出:一组进化得到的、最优的复合特征表达式
f1(X), ..., fM(X)。
- 输入:标准化后的基础特征集
- 标签模型训练:将原始基础特征
X与所有GP生成的复合特征f1(X), ..., fM(X)拼接,输入XGBoost分类器进行最终的多标签(MTG-Jamendo)或多分类(GTZAN)预测。
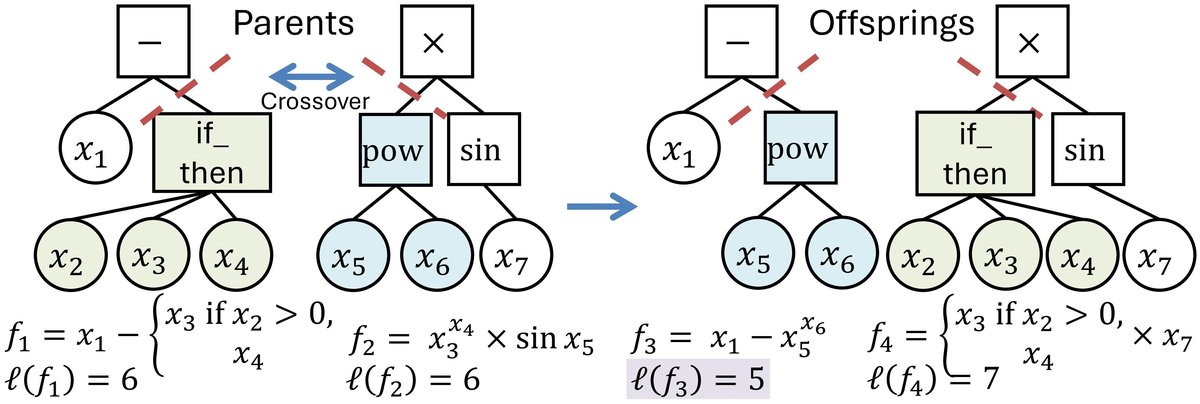 图2展示了GP如何通过交叉操作组合不同的子表达式(如f1和f2)生成新的复合特征表达式(f3),同时,简单性惩罚(parsimony pressure)会倾向于选择像f3这样的较小树而非像f4这样的大树。
图2展示了GP如何通过交叉操作组合不同的子表达式(如f1和f2)生成新的复合特征表达式(f3),同时,简单性惩罚(parsimony pressure)会倾向于选择像f3这样的较小树而非像f4这样的大树。
关键设计选择:
- 使用GP而非神经网络:直接动机是获得可解释的符号表达式。
- 迭代添加特征:每轮GP只进化一个特征,便于量化每个新特征的贡献。
- XGBoost作为评估器:因其在表格数据上的高效性和鲁棒性。
- 复杂度惩罚:这是保持表达式可解释、防止膨胀的关键。
💡 核心创新点
- 用于特征构建的可解释GP流水线:创新性地将遗传编程作为自动化、系统化的特征工程工具,直接生成可读的数学公式来组合音乐特征。这解决了传统手工组合无法规模化,以及深度学习融合不可解释的矛盾。
- 在音乐标签任务上的有效性验证:证明了该方法在不同抽象层级的基础特征和不同标签任务(多标签、多分类)上都能带来一致的性能提升,验证了方法的普适性。
- 基于符号表达式的可解释性分析:超越了特征重要性排序,深入分析进化出的最优表达式(如表2)和特征-算子共现模式(如图7、图8)。这揭示了哪些特征交互(如“频谱扩展”与“音色”特征)和变换(如对时间特征取对数)对标签预测有益,提供了黑箱模型无法给出的洞察。
🔬 细节详述
- 训练数据:
- MTG-Jamendo:18486首歌曲,56个标签(多标签)。论文未说明具体预处理和增强方法,但提到使用与文献[5, 26]相同的训练/验证/测试划分。
- GTZAN:1000段30秒音频,10个流派(多分类)。同样使用标准划分。
- 所有特征在GP前进行了标准化(零均值,单位方差)。
- 损失函数:GP阶段的适应度函数是验证集上的性能指标(AUC或准确度)减去复杂度惩罚项
λ * 节点数,λ=0.01。最终XGBoost训练使用其默认损失(多标签用二元逻辑损失,多分类用多类逻辑损失)。 - 训练策略:
- GP设置:种群大小100或500,运行50代或早期停止(15代无改进或5代内方差<0.0001)。评估次数(evaluations)是主要的成本度量。
- XGBoost超参数:MTG-Jamendo:70个估计器,最大深度3,学习率0.1。GTZAN:最大深度2,学习率0.3。这些与文献[5, 26]一致。
- 关键超参数:GP个体的最大树高限制为6;常数采样范围
[-2, 2];交叉率0.8,突变率0.1,锦标赛大小3。 - 训练硬件:在RTX 3080Ti GPU上运行。每次评估耗时:MTG-Jamendo约5.5秒,GTZAN约1.2秒。
- 推理细节:GP生成的复合特征表达式一旦进化完成,在部署时只需要进行基本的数学运算,计算成本集中于训练阶段。
- 正则化/稳定技巧:使用受保护的运算符(如
log(1+|x|))避免数值错误;对无效值(NaN/∞)进行适应度惩罚;对每个候选特征在评估前进行标准化。
📊 实验结果
主要Benchmark结果(表1): 论文在两个数据集上对比了基线(仅基础特征)与GP增强特征集(GP100表示种群100,GP500表示种群500)的性能。
| 方法 | MTG-Jamendo (AUC) | Δ | GTZAN (ACC) | Δ |
|---|---|---|---|---|
| ALL62 [5, 26] | 0.727 | – | 0.765 | – |
| ALL62 + GP100 | 0.729 [0.724–0.733] | +0.002 | 0.800 [0.760–0.845] | +0.035 |
| ALL62 + GP500 | 0.730 [0.724–0.736] | +0.003 | 0.805 [0.760–0.850] | +0.040 |
| E23 [5, 26] | 0.719 | – | 0.740 | – |
| E23 + GP100 | 0.722 [0.716–0.728] | +0.003 | 0.785 [0.730–0.830] | +0.045 |
| E23 + GP500 | 0.724 [0.717–0.731] | +0.005 | 0.790 [0.735–0.840] | +0.050 |
关键结论:
- 一致性提升:GP在所有配置下均提升性能,尤其在GTZAN上提升显著(4.0%-5.0%)。
- 接近深度学习SOTA:论文声称,仅用5次GP迭代,性能已接近深度学习方法(MTG-Jamendo SOTA AUC=0.781 [29], GTZAN SOTA ACC=0.84 [30])。
- 性能分布稳定:图3和图4显示,所有GP生成的特征集(而不只是最佳的)的性能分布中位数均优于基线,表明GP普遍有效。
- 高效收敛:图5和图6显示了“任意时间轨迹”,最佳性能在最初几百次评估内快速上升,之后趋于平缓。GTZAN在约300次评估内接近最优,MTG-Jamendo则需要约1000次。
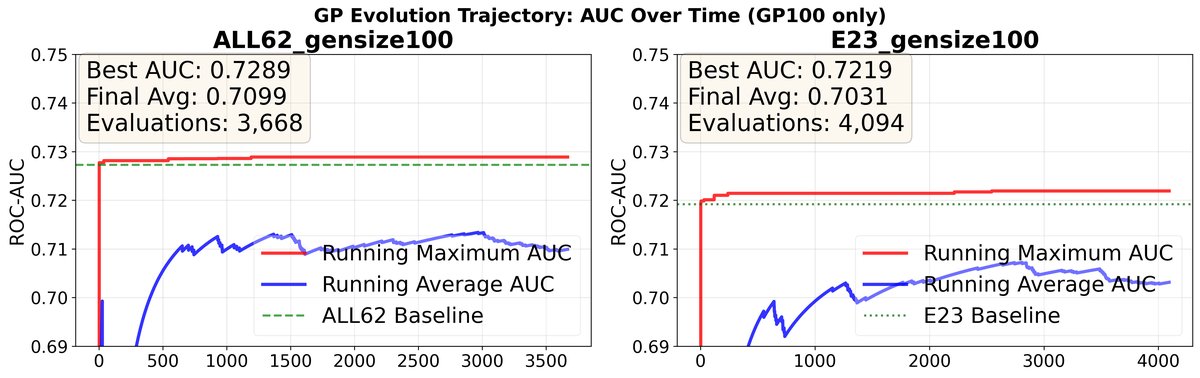 图3显示了所有GP增强特征集在MTG-Jamendo上的AUC分布,中位数均高于基线,且箱体较窄。
图3显示了所有GP增强特征集在MTG-Jamendo上的AUC分布,中位数均高于基线,且箱体较窄。
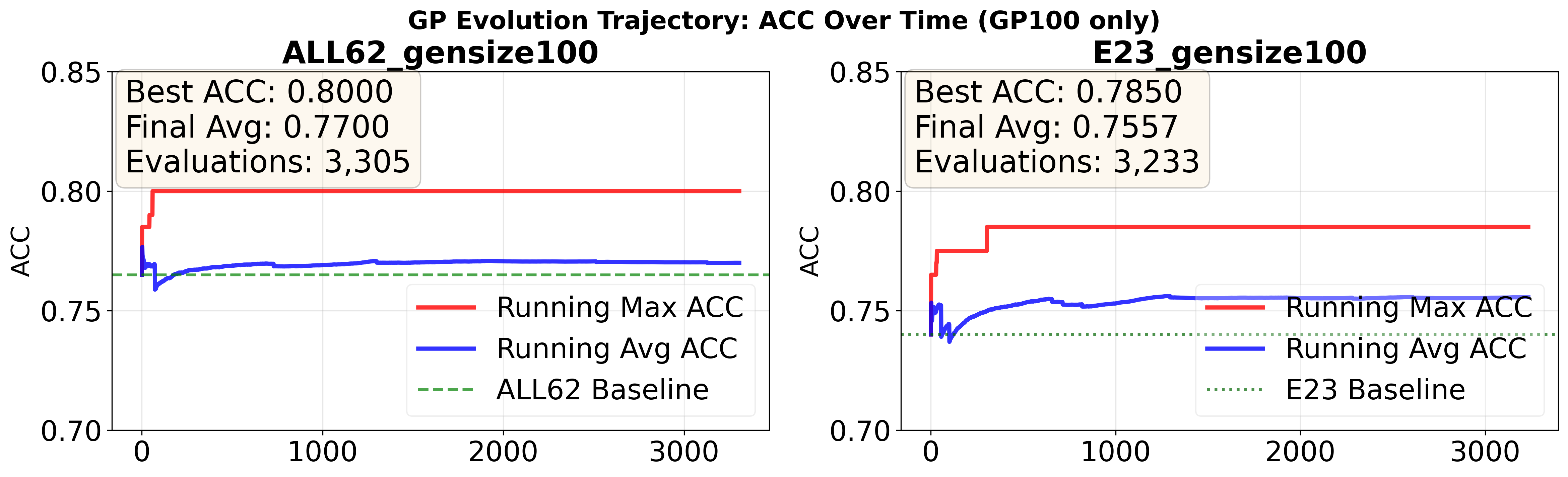 图4显示了所有GP增强特征集在GTZAN上的准确率分布,同样显示中位数提升。
图4显示了所有GP增强特征集在GTZAN上的准确率分布,同样显示中位数提升。
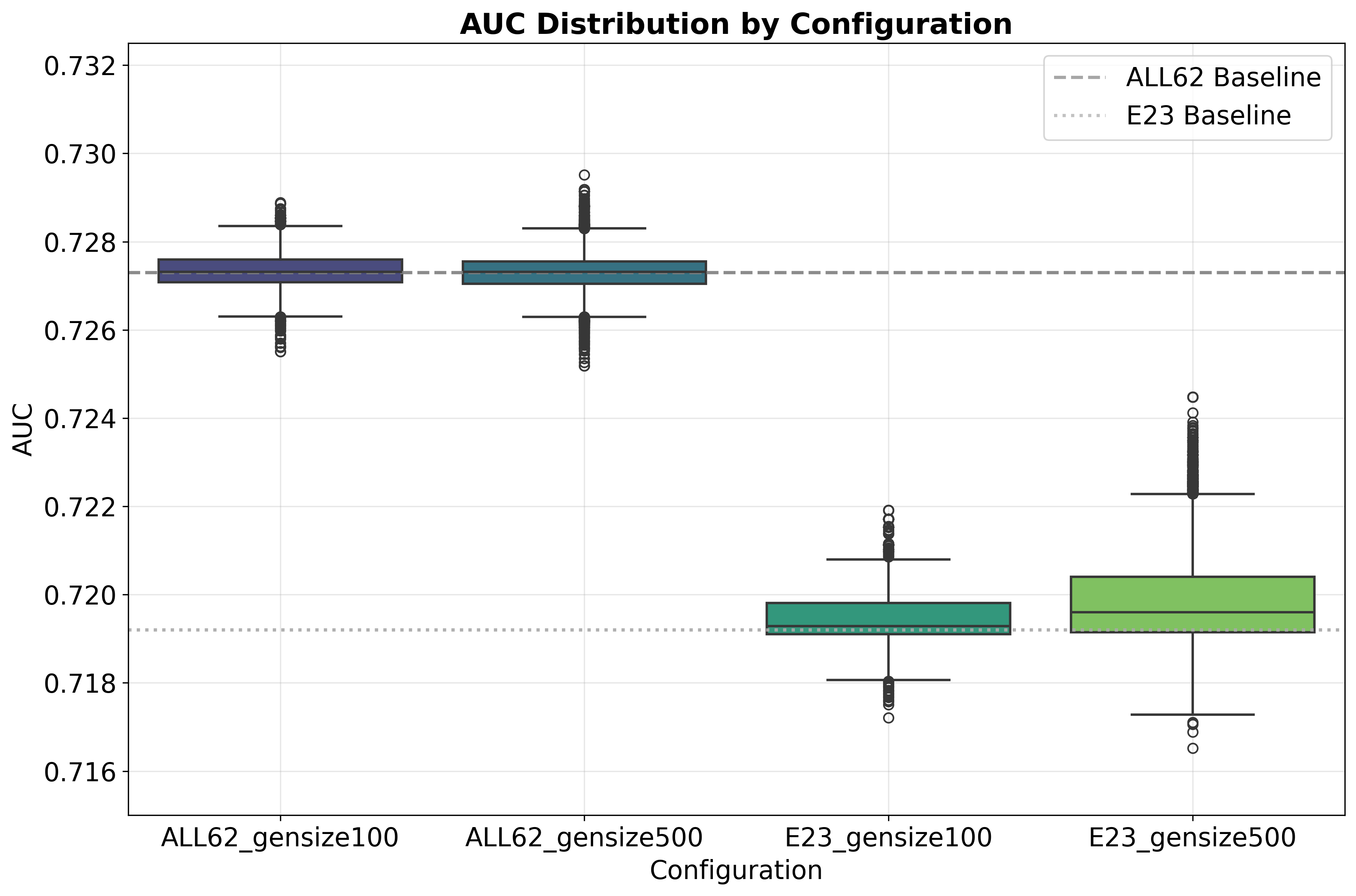 图5显示,随着评估次数增加,最佳AUC和运行平均AUC在早期快速增长。
图5显示,随着评估次数增加,最佳AUC和运行平均AUC在早期快速增长。
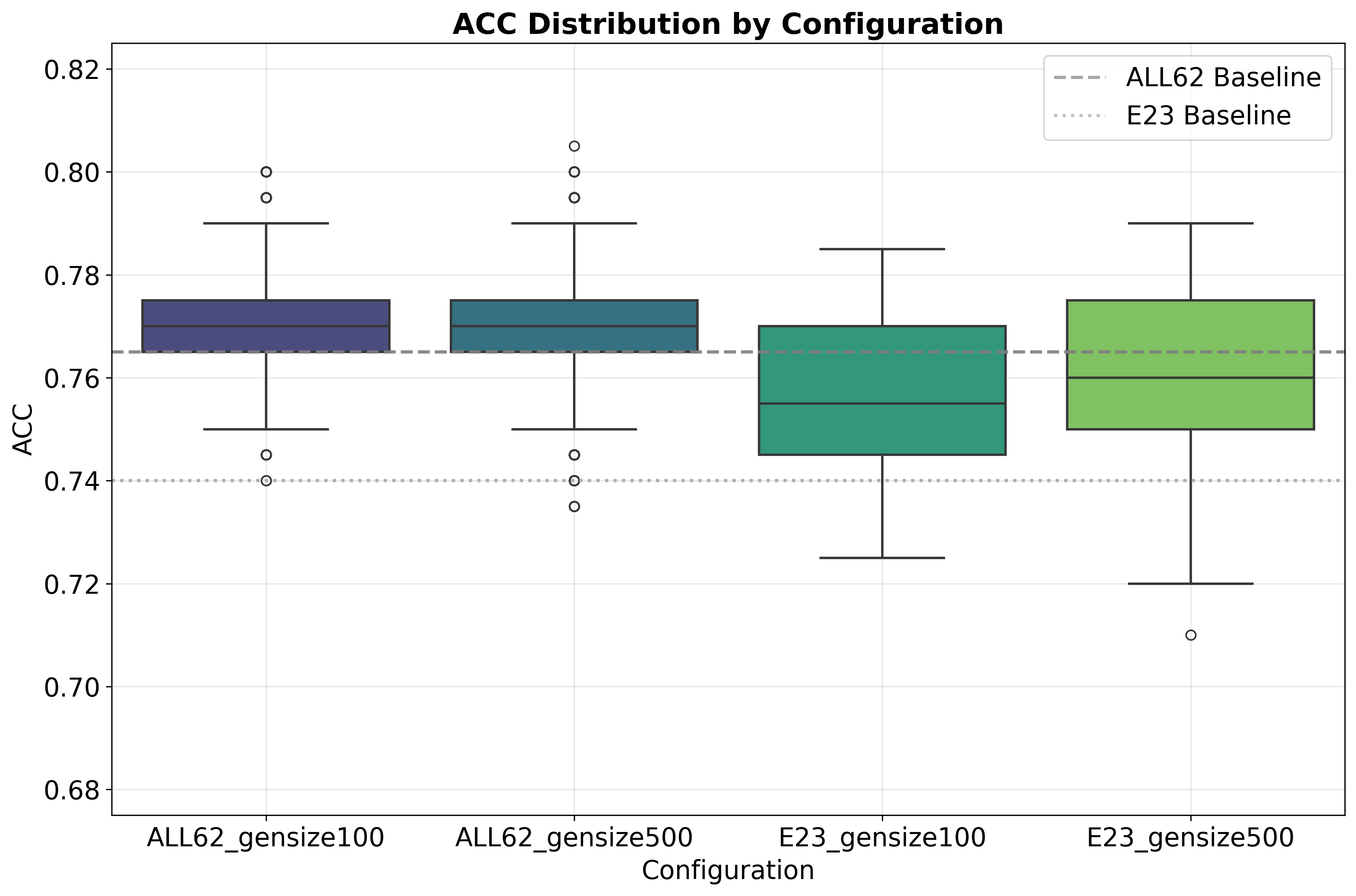 图6显示GTZAN的性能增长更快,在约300次评估后趋于平稳。
图6显示GTZAN的性能增长更快,在约300次评估后趋于平稳。
可解释性分析结果(表2,图7,图8):
- 表达式分析:进化出的表达式形式多样,包括线性(
Loudness - BPMdom_dom)、非线性(2·Length - 3·Onset Rate)和条件语句(if(Mode > 0, ...))。低复杂度表达式(节点少)也能达到高性能,证实了复杂度惩罚的有效性。 - 共现分析:图7和图8(以MTG-Jamendo为例)揭示了任务特定的特征协同和算子偏好。例如,对时间特征(Danceability, Onset Rate)取对数频繁出现且性能高,可能反映了人类节奏感知的非线性。
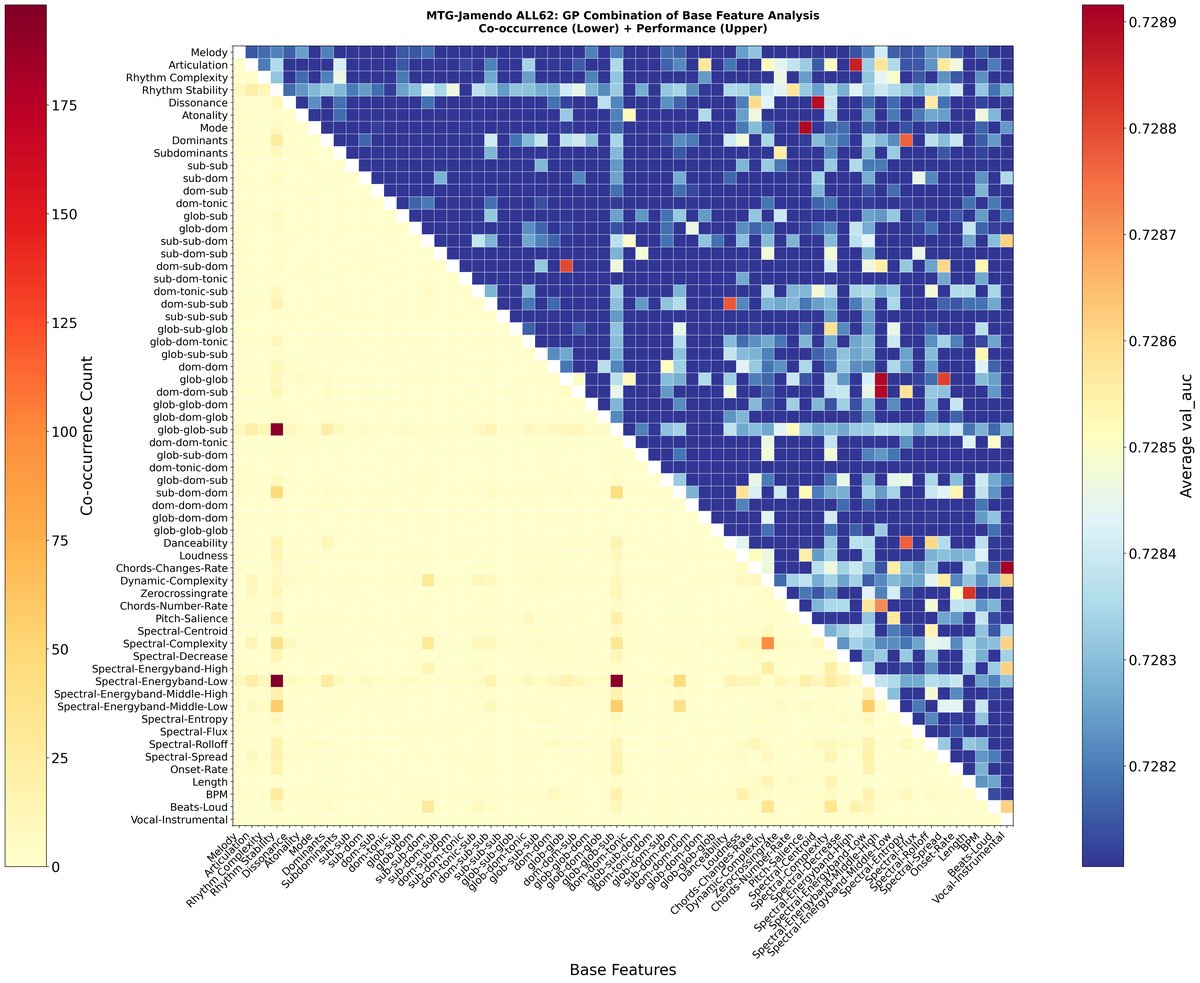 图7的下三角显示了特征对在top-500表达式中的共现频率,上三角显示了共现时的平均AUC。例如,“频谱扩展”与“音色”特征共现时性能较高。
图7的下三角显示了特征对在top-500表达式中的共现频率,上三角显示了共现时的平均AUC。例如,“频谱扩展”与“音色”特征共现时性能较高。
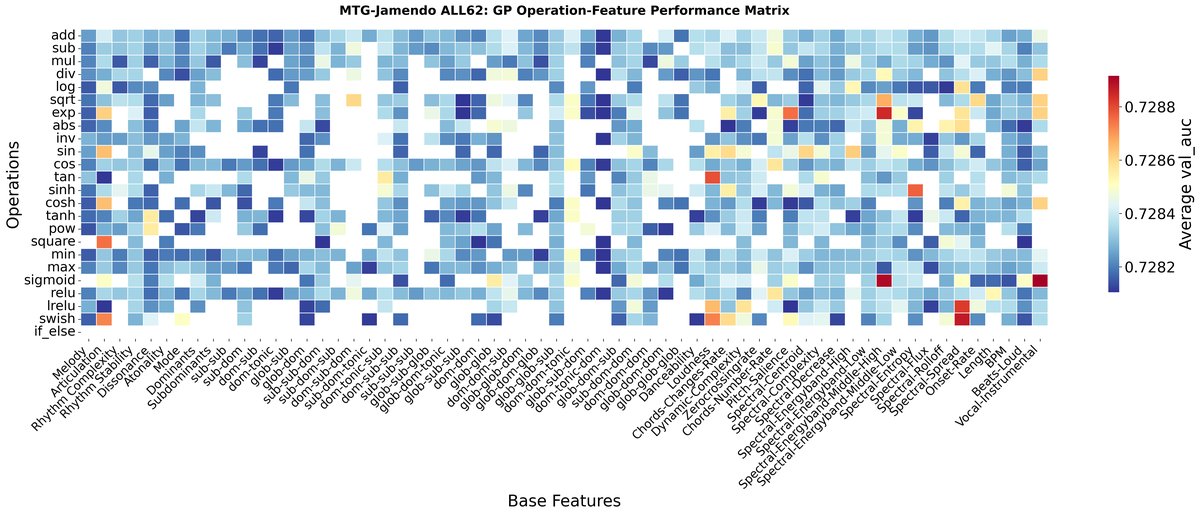 图8显示了特定算子作用于特定特征时的平均AUC。例如,对“可舞性”、“起拍率”等时间特征使用对数(log)运算带来了高AUC。
图8显示了特定算子作用于特定特征时的平均AUC。例如,对“可舞性”、“起拍率”等时间特征使用对数(log)运算带来了高AUC。
⚖️ 评分理由
- 学术质量(6.5/7):方法设计合理,实验充分且结果稳定,分析深入。主要创新点清晰。扣分主要因为:a) 对比的深度学习基线并非当前最强;b) GTZAN数据集的代表性受限,使得“state-of-the-art”宣称的力度打折;c) 未探讨方法在更大规模、更新的数据集(如MusicNet)上的表现。
- 选题价值(0.0/2):问题本身(可解释MIR)重要,但方法(GP)和任务(音乐标签)相对传统和小众,对当前以自监督、大模型为主流的音频领域冲击力有限。
- 开源与复现加成(+1.0/1):代码开源,超参数明确,复现路径清晰,加成满分。