📄 Connecting Layer-Wise Representation of Wavlm with Spectro-Temporal Modulation on Speaker Verification
#说话人验证 #自监督学习 #模型分析 #可解释性
✅ 6.0/10 | 前50% | #说话人验证 | #自监督学习 | #模型分析 #可解释性
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -1.0 | 置信度 中
👥 作者与机构
- 第一作者:Shao-Hsuan Chen (⋆ 国立阳明交通大学电机工程学系)
- 通讯作者:未明确说明(根据惯例,可能是最后作者Tai-Shih Chi或Yuan-Fu Liao)
- 作者列表:
- Shao-Hsuan Chen (⋆ 国立阳明交通大学电机工程学系)
- Pei-Chin Hsieh (⋆ 国立阳明交通大学电机工程学系)
- Yih-Liang Shen (⋆ 国立阳明交通大学电机工程学系)
- Tai-Shih Chi (⋆ 国立阳明交通大学电机工程学系)
- Yuan-Fu Liao († 国立阳明交通大学人工智能创新研究所)
- Chi-Han Lin (‡ 玉山金融控股股份有限公司)
- Juan-Wei Xu (‡ 玉山金融控股股份有限公司) (⋆、†、‡ 标记对应其后机构,机构信息已在列表中明确标注)
💡 毒舌点评
论文最大的亮点在于为理解WavLM这类黑箱模型提供了一种新颖的“神经科学视角”,通过构建频谱-时空调制特征,发现模型中间层确实编码了类似听觉皮层的选择性(如对性别相关的谐波结构敏感),这种交叉学科的分析思路值得肯定。然而,其短板也十分明显:实验设计基本局限于TIMIT数据集的性别子集分析,更像是一个初步的、小规模的现象观察,未能将这些“生物启发式”的发现与提升实际说话人验证系统(如在VoxCeleb大规模数据上的性能)建立直接联系,使得论文的实用价值和影响力打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开的分析模型(如训练好的MLP)权重。论文所使用的WavLM-Large和ECAPA-TDNN是外部引用的开源模型。
- 数据集:未提及开源新的数据集。使用了公开的TIMIT和VoxCeleb数据集,但未说明数据获取或处理的具体方式。
- Demo:未提及。
- 复现材料:未给出分析流程的具体实现代码、训练MLP的超参数、配置文件或检查点。复现依赖于对论文方法的文字描述和引用的开源项目。
- 论文中引用的开源项目:明确引用了WavLM [4]、HuBERT [5]、wav2vec 2.0 [6]、ECAPA-TDNN [14] 等开源模型或框架。
📌 核心摘要
这篇论文旨在探索自监督学习模型WavLM的内部表征与生物听觉系统中关键的频谱-时空调制(STM)特征之间的关联性。论文的核心方法是:1)构建一个模仿初级听觉皮层处理过程的STM特征提取器,生成50种不同速率和尺度的调制响应;2)使用加权典型相关分析(PWCCA)量化WavLM各层表示与这些STM特征的相关性;3)设计一个监督回归任务,用WavLM的层表示来重构经过注意力加权的STM响应。与已有工作多关注声学或语言学特征的分析不同,本文首次系统性地将SSL模型与基于神经科学的调制特征进行对齐分析。实验在TIMIT数据集按性别划分的子集上进行,结果表明:中间Transformer层(约3-11层)与STM特征高度相关;且这种相关性表现出性别特异性:男性语音的表示与较高尺度(4-8 cycles/octave,对应其较低基频)的STM特征匹配,而女性语音则与较低尺度(2-4 cycles/octave)匹配。论文的主要实际意义在于,为理解和解释强大的SSL语音模型提供了来自听觉神经科学的洞见,揭示了模型可能自发地学习到了类似于大脑处理语音的层次化调制特征。其主要局限性是:研究仅限于TIMIT数据集和性别因素的分析,规模较小;未直接验证这些发现能否以及如何用于改进说话人验证系统的实际性能;也未与其他主流分析方法进行充分对比。
🏗️ 模型架构
本文并未提出一个新的端到端说话人验证模型,而是提出了一套分析框架,用于研究预训练WavLM模型的层表示与生物听觉特征(STM)之间的关系。整体分析流程如下图所示:
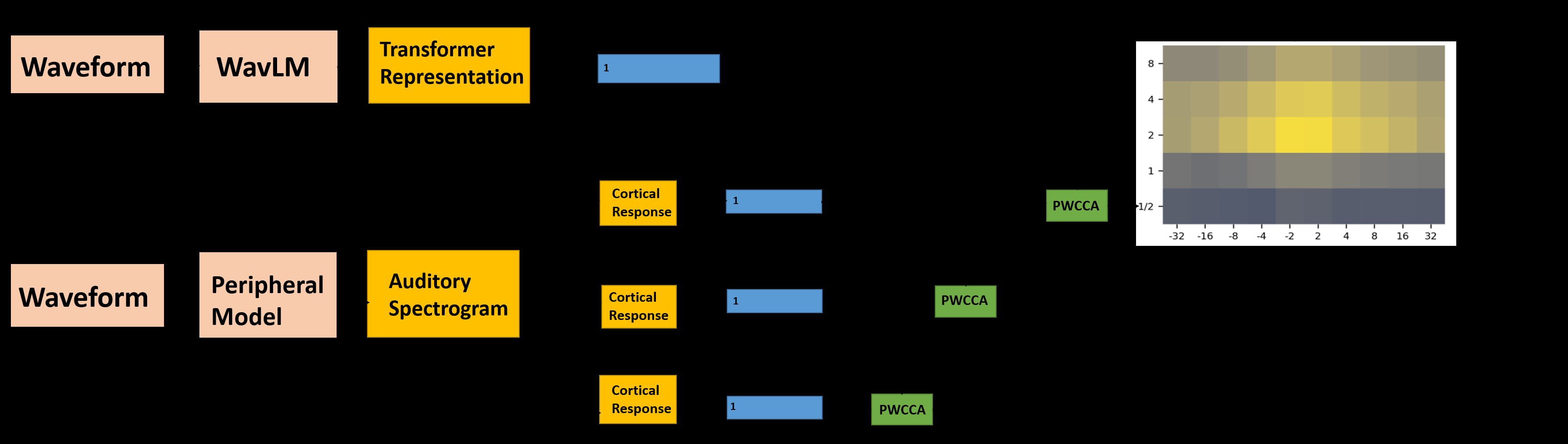
流程详解:
- 输入:语音波形。
- WavLM表示提取:输入波形送入预训练的WavLM-Large模型。WavLM-Large包含1个CNN编码器和24个Transformer编码器层。论文提取了从第1层到第25层(CNN+24 Transformer)的输出表示
M^(ℓ) ∈ R^{1024×T},其中T是时间帧数。为进行对比,对每层表示在时间维度上进行平均池化,得到每层的向量M̄^(ℓ) ∈ R^{1024}。 - STM特征提取:输入波形首先通过一个模拟耳蜗频率分析的前端,生成听觉频谱图
S ∈ R^{128×T}(128个对数频率通道)。然后,使用一组2D频谱-时空调制滤波器组(50个滤波器,对应5种速率×10种尺度组合)对听觉频谱图进行卷积,得到调制响应R_{r,s}(t, f)。最终,对每个调制滤波器计算时间维度的平均,得到50个代表不同调制特性的特征向量。 - 关联分析:
- PWCCA分析:对于每一层WavLM表示(跨语料库的n个语料的矩阵X),与50个STM特征向量(矩阵Y)进行PWCCA分析,计算它们之间的相关性,得到每个层的相关性矩阵
CORR(ℓ) ∈ R^{5×10}(见图2)。 - 监督回归分析:设计一个监督任务来评估重构能力。对于每个层,使用其注意力矩阵
A^(ℓ)对原始STM响应R_{r,s}进行加权,得到目标Ȳ^(ℓ)_{r,s}。然后使用一个简单的两层MLP,以该层WavLM表示M^(ℓ)为输入,预测Ŷ^(ℓ)_{r,s}。通过最小化预测与目标之间的MSE损失来训练MLP。最后,根据MSE损失计算一个相似度得分SIM(ℓ)_{r,s}(见图4和图5)。
- PWCCA分析:对于每一层WavLM表示(跨语料库的n个语料的矩阵X),与50个STM特征向量(矩阵Y)进行PWCCA分析,计算它们之间的相关性,得到每个层的相关性矩阵
💡 核心创新点
- 首次构建WavLM与生物听觉调制特征的系统分析框架:之前对SSL语音模型的分析多集中于与声学特征(如MFCC)或语言学特征的相关性。本文首次引入了一个基于初级听觉皮层STRFs的、具有生物可解释性的STM特征集,作为分析WavLM层表示的新基准,建立了深度学习与听觉神经科学的连接。
- 揭示WavLM中间层的性别特异性调制选择性:通过PWCCA和监督回归分析,论文发现WavLM的中间Transformer层并非学习单一特征,而是表现出类似听觉皮层的“调谐”特性:对区分说话人性别至关重要的谐波结构(反映在不同频谱尺度上)具有高度敏感性,且这种敏感性与性别(基频)相关。
- 发现WavLM层间存在对应不同时间调制速率的层级组织:分析表明,WavLM的不同层对STM中不同的时间速率(如慢速率的韵律 vs 快速率的瞬态)表现出差异化的重构能力(相似度模式),暗示其内部可能隐式地形成了类似听觉通路中时间信息处理的层级结构。
🔬 细节详述
- 训练数据:
- 用于PWCCA和监督回归分析的数据集:TIMIT。论文提到将TIMIT训练集按性别划分为3260条男性语音和1360条女性语音进行分析。
- 用于评估说话人验证系统(作为背景基准)的数据集:VoxCeleb-O测试集,论文中提到所用的WavLM+ECAPA-TDNN系统在该测试集上达到了0.66%的EER。但论文核心分析并未在该大规模数据集上进行。
- 未说明数据预处理和数据增强细节。
- 损失函数:在监督回归任务中使用了均方误差(MSE)损失,见公式(10)
L^(ℓ)_{r,s} = ||Ŷ^(ℓ)_{r,s} - Ȳ^(ℓ)_{r,s}||²₂。该损失用于训练每个层、每个调制模式对应的MLP。总损失是所有层和50个调制组合的MSE之和。 - 训练策略:对于监督回归MLP的训练,论文未提供学习率、优化器、训练轮数等具体细节。
- 关键超参数:WavLM-Large的模型细节(层数、隐藏维度等)未在文中重复说明,但引用了原始WavLM论文。调制滤波器组的具体参数:速率集合为 {±2, ±4, ±8, ±16, ±32} Hz,尺度集合为 {0.5, 1, 2, 4, 8} cycles/octave。PWCCA分析中,k取min(1024, 128)=128。
- 训练硬件:未说明。
- 推理细节:不适用于本文的分析框架。WavLM和ECAPA-TDNN的推理设置未说明。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
论文的核心实验结果是分析性的,展示了WavLM层表示与STM特征之间的关联模式,而非传统的准确率/EER对比。主要结果如下:
PWCCA相关性分析(图3):
- 结果描述:图3展示了WavLM所有25层(CNN+24 Transformer)表示与50个STM特征之间的PWCCA相关性矩阵热图,分别针对男性和女性语音。
- 关键发现:
- 无论性别,高相关性区域均集中在中间Transformer层(约第3-11层)。
- 尺度选择性:对于男性语音(左图),高相关性出现在较高尺度(Ω ≈ 4-8 cycles/octave);对于女性语音(右图),高相关性出现在较低尺度(Ω ≈ 2-4 cycles/octave)。
- 速率偏好:两者都与较慢的时间调制速率(如±2-4 Hz)有更强关联。
- 图表:

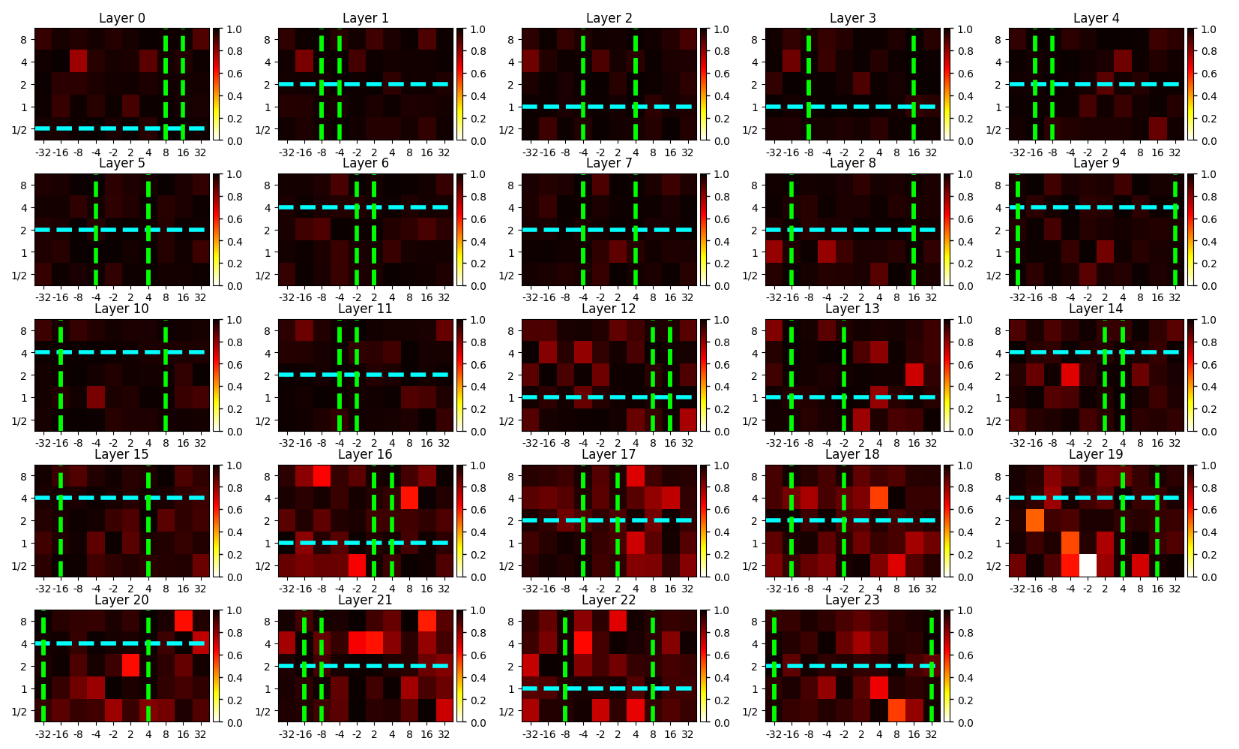
监督回归与相似度分析(图5):
- 结果描述:图5展示了通过监督回归任务得到的相似度得分(SIM)热图,横轴是尺度,纵轴是WavLM的24个Transformer层(Layer 0-23),同样分男性和女性。热图颜色越深,表示该层对该调制模式的重构能力越强(相似度越高)。
- 关键发现:
- 男性语音:在第4-10层,于尺度≈4-8 cycles/octave处出现高相似度区域。
- 女性语音:在第4-10层,于尺度≈2-4 cycles/octave处出现高相似度区域。
- 时间速率对称性:中间层(如5-9层)对正/负速率表现出对称响应,可能编码了对称的时间结构;而早期层(如0, 2, 4层)表现出不对称性,可能偏好特定方向的调制扫频。
- 深层衰减:超过第13层后,相似度得分普遍下降,表明这些层可能更倾向于编码与调制特征无关的高层语义信息。
- 图表:
注:论文未提供将上述发现与改进后的说话人验证系统最终性能(如EER降低)进行关联的具体数值表格。论文中提到的0.66% EER是WavLM+ECAPA-TDNN系统在VoxCeleb-O上的现有基准,而非本研究的直接改进结果。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个创新且有意义的跨学科分析框架,技术路线(PWCCA+监督回归)应用得当,分析结果清晰且具有一定的洞察力(性别特异性、层级选择性)。主要不足在于实验证明力较弱:分析仅限于TIMIT数据集的一个小规模、特定条件(性别)子集;未能将分析发现与解决或改善原始说话人验证任务直接挂钩;也未与现有的其他模型分析方法进行对比。
- 选题价值:1.5/2:选题前沿,将深度学习可解释性与生物听觉机制相结合,提供了新颖的视角,对理解和解释SSL模型有理论价值。然而,该分析方向目前更偏向基础研究,其发现能否转化为实用的系统设计原则或性能提升尚不明确,因此实际应用空间有限。
- 开源与复现加成:-1.0/1:论文完全没有提供代码、数据、模型或详细的复现指南。这是其最大的短板之一,使得其他研究者无法验证其发现或在此基础上进行扩展研究,严重影响了工作的可复现性和影响力。