📄 Conditional Diffusion Models for Mental Health-Preserving Voice Conversion
#语音转换 #扩散模型 #语音匿名化 #语音生物标志物 #零样本
🔥 8.0/10 | 前25% | #语音转换 | #扩散模型 | #语音匿名化 #语音生物标志物
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Siddharth Kalyanasundaram(科罗拉多大学博尔德分校认知科学与计算机科学研究所)
- 通讯作者:未说明(从邮箱格式和惯例推断,Theodora Chaspari可能为通讯作者,但论文未明确标注)
- 作者列表:Siddharth Kalyanasundaram(科罗拉多大学博尔德分校认知科学与计算机科学研究所)、Theodora Chaspari(科罗拉多大学博尔德分校认知科学与计算机科学研究所)
💡 毒舌点评
这篇论文巧妙地将扩散模型用于一个“政治正确”但技术挑战十足的场景——在给抑郁症语音“变声”脱敏的同时,还要保住其病情线索,想法和落点都值得称赞。但遗憾的是,模型的训练“粮草”太少(仅28小时语音),导致其在通用语音质量(自然度、可懂度)上略逊于“吃得多”的基线,显得“巧妇难为无米之炊”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用了E-DAIC-WOZ数据集,这是一个公开但需要申请获取的数据集(论文未提供获取方式)。
- Demo:提供在线演示链接:https://sidks.github.io/icassp26_vcdemo/。
- 复现材料:给出了模型规模(23M/67M)、优化器(AdamW)、学习率(5e-5)、训练轮数(446)、批大小(32)、训练硬件(单A100)和时长(72小时)等关键信息。
- 论文中引用的开源项目/工具:引用了XLS-R (Wav2Vec 2.0)、VQ-VAE、YAAPT、OpenSMILE(eGeMAPS特征)、Whisper、StyleEncoder、Vevo-Voice、QuickVC等相关模型或工具,但未指明本文是否直接依赖这些项目的开源代码。
- 整体开源情况:论文中未提及完整的开源计划。
📌 核心摘要
- 解决的问题:语音是心理健康(如抑郁症)的重要生物标志物,但包含说话人身份等敏感信息,阻碍了数据共享与研究复现。需要在匿名化语音的同时,保留对心理健康研究至关重要的副语言信息。
- 方法核心:提出一种基于条件扩散模型(DM)的语音转换(VC)框架。首先,将语音解耦为内容(w2v)、音高(f0)、说话人身份(s)和抑郁(d)四个嵌入表示。然后,以目标说话人嵌入(s’)和抑郁嵌入(d)作为条件,指导扩散模型的反向去噪过程,生成既改变身份又保留抑郁线索的新语音。
- 与已有方法的新意:首次将扩散模型应用于明确保留抑郁线索的语音转换任务。现有VC方法(如基于VAE、GAN的模型)在匿名化时会严重退化副语言信息(如情绪、抑郁线索),而本文通过将抑郁嵌入作为扩散过程的显式条件,实现了对关键生物标志物的保护。
- 主要实验结果:在未见说话人的零样本设置下,所提模型(DM-23M, DM-67M)与SOTA基线(Vevo-Voice, QuickVC)在语音可懂度(WER/CER)和说话人相似度(SECS)上表现相当。核心优势在于抑郁信息保留:所提模型转换后语音的抑郁严重程度(PHQ-8)预测平均绝对误差(MAE)显著低于基线(DM-23M:5.025 vs. Vevo-Voice:5.478, QuickVC:5.804),且预测分数分布与原始语音更接近(KL散度约0.06 vs. 24+)。
模型 WER ↓ CER ↓ SECS ↑ PHQ-8 MAE ↓ nMOS ↑ sMOS ↑ 原始语音 0.046 0.025 0.872 4.522 4.17 3.85 Vevo-Voice 0.078 0.043 0.850 5.478 4.14 3.74 QuickVC 0.059 0.046 0.731 5.804 4.04 3.59 DM-23M (本文) 0.082 0.047 0.804 5.025 3.97 3.71 DM-67M (本文) 0.068 0.041 0.829 5.055 4.03 3.78 - 实际意义:为心理健康研究提供了一种潜在的隐私保护工具,可以在保护参与者隐私的前提下,促进脱敏语音数据的共享与分析,有助于推动该领域的研究复现和跨机构合作。
- 主要局限性:训练数据规模较小(仅28小时),限制了模型生成语音的自然度和可懂度;仅针对抑郁症进行评估,未验证对其他副语言信息(如情绪、认知状态)的保留能力;隐私-效用权衡(EER指标)显示匿名化程度还有提升空间。
🏗️ 模型架构
论文提出的模型架构遵循“源-滤波器”分解框架,并采用扩散模型进行条件生成。整体流程如图1所示。
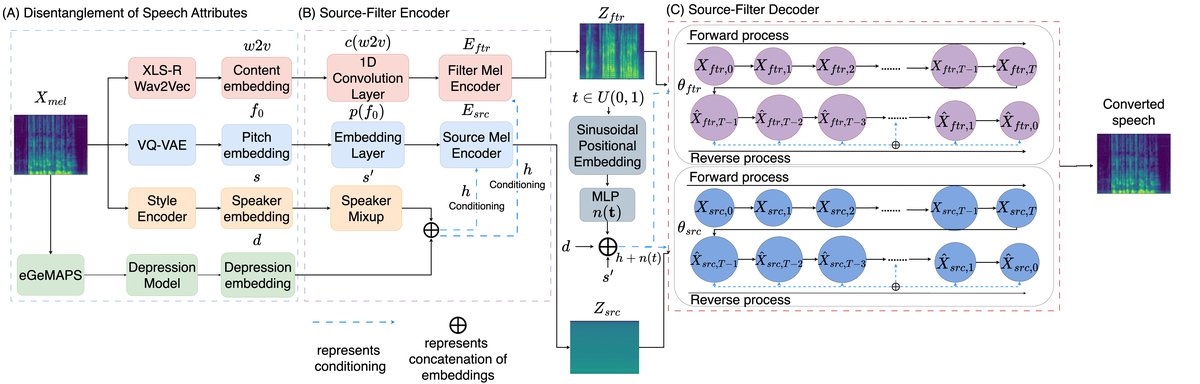
完整输入输出流程:输入源语音Xmel,经过特征解耦网络(图1-A),提取出四个嵌入:内容嵌入w2v、音高嵌入f0、源说话人嵌入s、以及抑郁嵌入d。在训练时,s用于重建;在转换时,使用目标说话人嵌入s’。这四个嵌入与原始Mel谱图一起,输入到条件扩散模型(图1-B, C)中,最终输出转换后的语音波形。
主要组件与内部结构:
- 特征解耦模块 (图1-A):
- 内容嵌入 (w2v):使用预训练的XLS-R模型(第12层)从语音中提取,捕捉语言学信息。
- 音高嵌入 (f0):使用VQ-VAE模型对基频(F0)轨迹进行离散化编码,捕捉超音段信息。
- 说话人嵌入 (s/s’):使用StyleEncoder模型提取。
- 抑郁嵌入 (d):一个从头训练的Transformer编码器,输入eGeMAPS声学特征,通过注意力池化输出256维向量,代表抑郁症严重程度。
- 扩散模型框架 (图1-B, C):
- 源-滤波器编码器 (Esrc, Eftr):并行处理音高(源)和内容(滤波器)。Esrc将p(f0)、s’、d融合;Eftr将c(w2v)、s’、d融合。输出作为扩散过程的先验条件Zsrc和Zftr。
- 扩散过程 (图1-C):包含前向加噪和反向去噪过程。关键创新在于,解码器(θsrc, θftr)在每个去噪时间步t都接收条件信号:目标说话人嵌入s’、抑郁嵌入d、以及时间步嵌入n(t)的串联h。这使得生成过程全程受目标身份和抑郁状态的引导。
- 解码器:两个独立的分数扩散网络,分别对Zsrc和Zftr进行去噪,生成最终的Mel谱图。
组件间数据流与交互:条件嵌入s’和d在两个层面注入模型:
- 编码器层面:在扩散过程开始前,将身份和抑郁信息“烘焙”到先验表示Zsrc和Zftr中。
- 解码器层面:在扩散去噪的每一步,持续提供s’和d作为信号,动态引导生成方向,确保输出语音持续符合目标条件。这种双重条件化设计旨在更精细地控制生成结果。
关键设计选择及动机:
- 选择扩散模型:动机在于其强大的生成能力和通过条件信号进行精细控制的潜力,适合处理多属性解耦与控制任务。
- 显式抑郁嵌入条件化:这是本文的核心创新,直接针对“保留MH信息”的目标,通过将抑郁嵌入作为条件,强制扩散模型在改变说话人身份时保留这些关键线索。
- 源-滤波器分解与并行去噪:将语音属性(音高、内容)分离后独立建模,允许更灵活、可控的转换。
💡 核心创新点
- 首个面向心理健康保护的条件扩散语音转换模型:将扩散模型应用于语音匿名化,并首次在生成过程中引入抑郁嵌入作为显式条件,以解决副语言信息(特别是抑郁线索)在传统VC中丢失的问题。
- 双重条件注入的扩散框架:设计在编码器和解码器阶段均注入说话人与抑郁条件。编码器注入定义目标先验,解码器在每一步去噪中持续注入,实现了对生成过程更稳定、更精细的引导,增强了对目标属性的控制力。
- 系统性验证VC对抑郁信息保留的退化:不仅提出了新方法,还通过实验证实了现有的SOTA VC系统(如Vevo-Voice, QuickVC)会显著破坏语音中的抑郁相关线索(PHQ-8预测MAE升高,分布KL散度巨大),突显了本文工作的必要性和价值。
- 端到端的解耦与生成流程:构建了一个从特征解耦(使用预训练或从头训练模型)到条件扩散生成的完整流程,展示了如何在特定垂直领域(心理健康)定制语音生成系统。
🔬 细节详述
- 训练数据:
- 抑郁症嵌入模型:使用E-DAIC-WOZ数据集训练。包含275名参与者(66名抑郁症患者)的访谈语音,平均时长约14分钟。训练集182人,验证集28人,测试集56人。
- 扩散模型:使用E-DAIC-WOZ数据集中信噪比(SNR)较高的子集(122个文件,平均SNR 8.34 dB)进行训练,最终包含6,250个语句(时长>2秒)。所有语音重采样至16kHz,生成梅尔频谱图(跳数320样本)。
- 损失函数:
- 扩散损失 (Ldiff):标准分数扩散模型损失(公式5),衡量预测分数与真实分数梯度的差异。
- 重建损失 (Lrec):L1损失(公式2),确保编码器输出的潜在表示之和(Zsrc + Zftr)能还原原始梅尔谱图,避免解耦过程引入失真。
- 总损失 (Ltotal):Ldiff + λrec*Lrec,其中λrec=1。
- 训练策略:
- 抑郁症模型:SGD优化器,学习率3e-5,100轮,批大小16。
- 扩散模型:AdamW优化器,初始学习率5e-5,446轮,批大小32。
- 训练硬件:单块NVIDIA A100 GPU。
- 训练时长:72小时。
- 条件混合策略:在训练编码器时,40%的时间使用原始说话人嵌入s,60%的时间使用随机目标说话人嵌入s’,以促进说话人泛化。
- 关键超参数:
- 模型规模:实验了两种尺寸,DM-23M(约2300万参数)和DM-67M(约6700万参数)。
- 抑郁嵌入维度:256维。
- 输入特征:抑郁症模型输入88维eGeMAPS声学特征;扩散模型输入梅尔频谱图。
- 训练硬件:未提及具体GPU型号以外的详细信息(如显存、数量),仅说明使用单块A100。
- 推理细节:未提及解码策略、采样步数、温度等具体推理超参数。仅说明推理100个样本需45秒。
- 正则化或稳定训练技巧:论文未提及除上述损失函数外的其他正则化技巧(如权重衰减、Dropout等),但使用了重建损失来稳定解耦过程。
📊 实验结果
主要基准、数据集与指标:
- 数据集:E-DAIC-WOZ(测试集56名参与者)。
- 设置:零样本(Zero-shot),未见说话人。
- 基线模型:(1) 原始语音 (Ground Truth);(2) Vevo-Voice [26];(3) QuickVC [27]。
- 评估指标:
- 可懂度:词错误率(WER)、字错误率(CER)。
- 转换质量/说话人相似度:说话人编码器余弦相似度(SECS,越高越像目标说话人)、等错误率(EER,衡量转换语音与源语音的相似度,越高表示匿名化越好,理论上限0.5)。
- 心理健康信息保留:预测PHQ-8分数的平均绝对误差(MAE,越低越好)。
- 感知质量(MOS):自然度(nMOS)、可懂度(cMOS)、目标说话人相似度(sMOS),5分制。
关键实验结果与对比: 论文的核心实验证据在表1中完整呈现。本文提出的DM模型(尤其是DM-67M)在抑郁信息保留(PHQ-8 MAE)上显著优于两个强力基线Vevo-Voice和QuickVC(p<0.05),同时在其他指标上保持竞争力。
表1: Zero-shot VC results on unseen speakers] [注:此处使用文本描述代替插入图片]
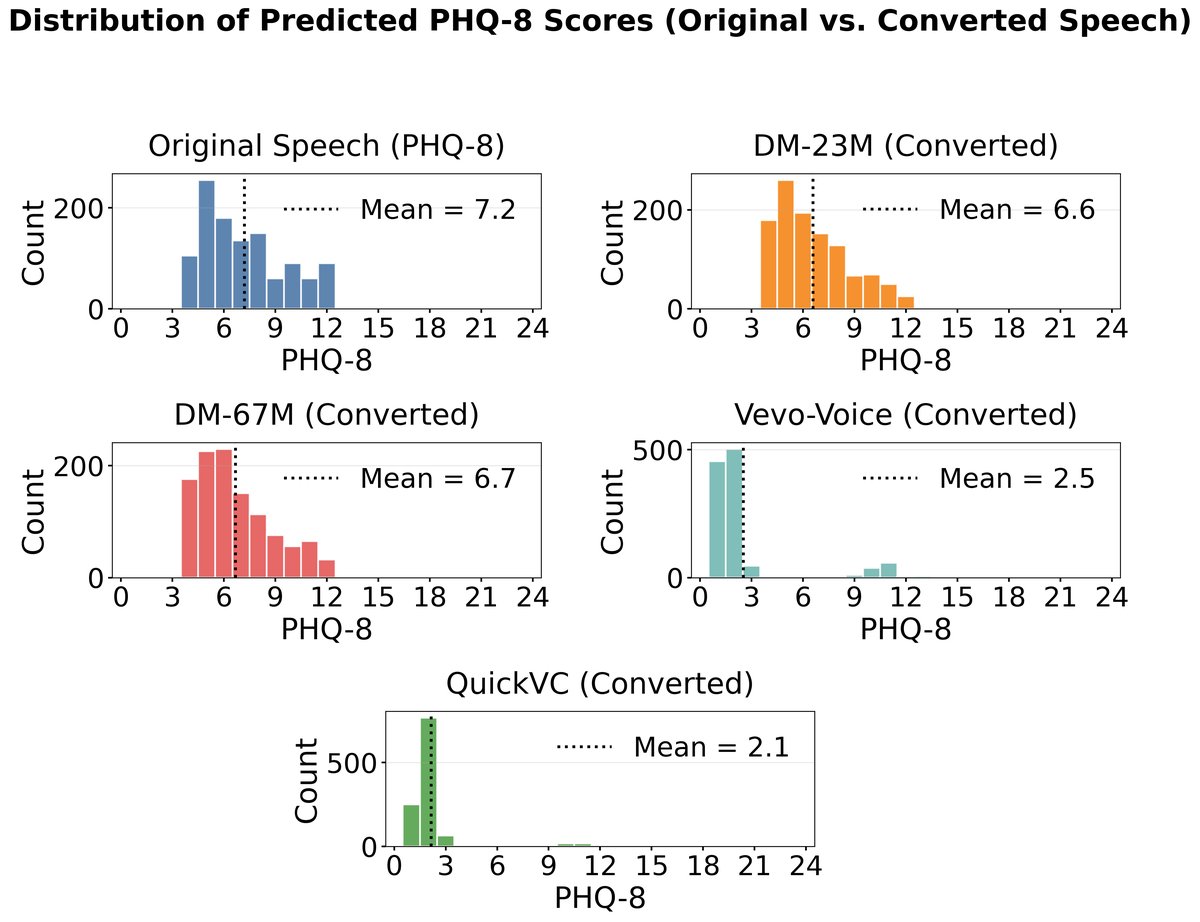 图3显示,原始语音和所提DM模型输出的PHQ-8预测分数分布较广且相似,而基线模型(Vevo-Voice, QuickVC)的预测分数分布严重集中在某一狭窄区间,导致其KL散度巨大(约24),表明它们丢失了抑郁症严重程度的变异信息。
图3显示,原始语音和所提DM模型输出的PHQ-8预测分数分布较广且相似,而基线模型(Vevo-Voice, QuickVC)的预测分数分布严重集中在某一狭窄区间,导致其KL散度巨大(约24),表明它们丢失了抑郁症严重程度的变异信息。
消融与细分结果:
- 论文提供了DM-23M和DM-67M两种规模的对比。DM-67M在CER、SECS、EER上略优于DM-23M,但在最关键的PHQ-8 MAE上几乎持平(5.025 vs. 5.055),表明模型规模对抑郁信息保留的影响不大。
- 在感知评价中,DM-67M在目标说话人相似度(sMOS)上得分最高(3.78),显示其在身份模仿上的优势。
⚖️ 评分理由
- 学术质量:6.5/7。论文创新性强,技术路线清晰且有深度(扩散模型条件化控制),实验设计全面(多基线、多指标、统计检验),证据链完整且可信(客观指标与主观评价结合,分布可视化)。扣分点在于训练数据规模有限,可能制约了模型上限,且部分消融分析(如条件权重)未深入探讨。
- 选题价值:1.5/2。选题精准切��心理健康研究与隐私保护的交叉痛点,具有明确的社会价值和学术意义。虽然应用场景相对垂直,但其提出的“属性保护型匿名化”框架对广泛的语音隐私应用有启发。
- 开源与复现加成:0/1。论文提供了演示链接和核心超参数,有助于理解。但缺乏代码、模型权重和完整复现脚本,使得独立验证和基于此工作的后续研究存在门槛。