📄 Condition-Invariant fMRI decoding of speech intelligibility with deep state space model
#神经解码 #状态空间模型 #语音可懂度解码 #跨条件迁移 #鲁棒性
✅ 7.0/10 | 前25% | #神经解码 | #状态空间模型 | #语音可懂度解码 #跨条件迁移
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 中
👥 作者与机构
- 第一作者:论文中提到Ching-Chih Sung, Shuntaro Suzuki, Francis Pingfan Chien贡献相等,未明确第一作者。
- 通讯作者:论文中未明确标注通讯作者。
- 作者列表:Ching-Chih Sung (Academia Sinica, Taiwan; Graduate Institute of Communication Engineering, National Taiwan University, Taiwan), Shuntaro Suzuki (Keio University, Japan), Francis Pingfan Chien (Academia Sinica, Taiwan; Taiwan International Graduate Program in Interdisciplinary Neuroscience, National Taiwan University, Taiwan), Komei Sugiura (Keio University, Japan), Yu Tsao (Academia Sinica, Taiwan)。
💡 毒舌点评
亮点在于首次尝试在嘈杂和增强语音等多种声学条件下解码大脑对语音可懂度的神经表征,并验证了其“条件不变”性,这比仅在干净语音上做解码更有科学意义。短板是fMRI数据量(25名被试)在深度学习时代略显单薄,且论文未开源代码和数据,极大限制了该方法的验证与推广。
🔗 开源详情
代码:论文中未提及代码链接。 模型权重:未提及。 数据集:未提及。 Demo:未提及。 复现材料:论文中未提及开源计划。提供了部分超参数(学习率、批大小、epoch数、L、r),但缺少模型架构细节(如嵌入维度D)、训练硬件信息和预处理脚本。 论文中引用的开源项目:SEMamba [17](用于生成DNN-SE刺激)、SPM12 [19](用于fMRI预处理)、MarsBaR [20](用于提��ROI)。
📌 核心摘要
本论文旨在解决一个关键问题:大脑在不同声学环境(如噪声、不同语音增强算法)下,是否使用一套“条件不变”的神经编码来表征语音的可懂度?为解决此问题,作者提出了一种基于双向深度状态空间模型(Deep SSM)的新架构,用于从fMRI体素时序信号中解码可懂度。与传统MVPA+SVM或Transformer方法相比,新方法在多个脑区(特别是颞叶、额叶和顶叶)的解码准确率上持续优于基线,首次实现了跨声学条件的解码。主要结果表明:1) 该模型在三种条件下(嘈杂、DNN增强、经典增强)的12个脑区中均表现出竞争力或最优的解码性能(Table 1),例如在嘈杂条件下右侧PreCG达到73.00%;2) 从嘈杂条件训练的模型可以成功迁移到两种增强条件(Table 2),表明存在条件不变的神经码;3) 消融实验证实双向扫描和S5层对性能有贡献(Table 3)。这项研究为理解大脑抽象语言表征提供了新工具,并启示了利用神经信号指导语音增强的潜力。主要局限在于fMRI数据规模有限,且未涉及实时或高时间分辨率神经信号的整合。
🏗️ 模型架构
本文提出的方法旨在从给定感兴趣脑区的fMRI体素时间序列中,分类每次扫描时的语音可懂度(高/低)。其核心架构基于深度状态空间模型(Deep SSM),具体扩展了S5模型以处理双向序列。
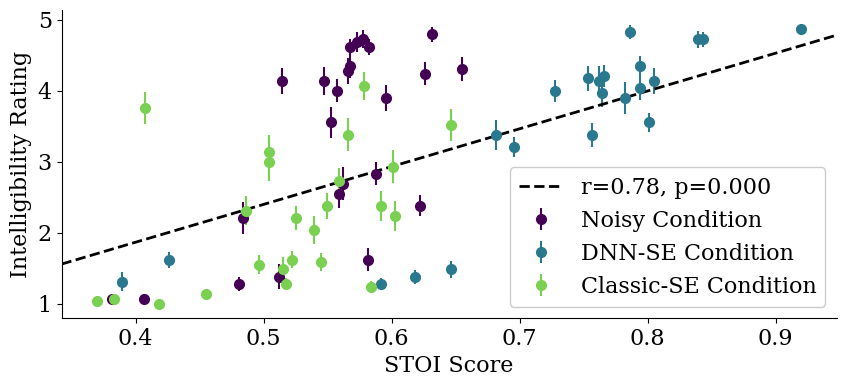 图3:所提方法的架构概览。
图3:所提方法的架构概览。
整体流程如下:
- 输入:对于单个试验,输入是该ROI内所有体素在fMRI扫描时间点上的BOLD信号序列,表示为一个矩阵
x ∈ R^{T×P},其中T是时间步数(TR数量),P是ROI内的体素数量。 - 嵌入层:输入首先通过一个线性嵌入层,将维度从P映射到一个隐藏维度D。
- 双向状态空间模型块(S5 Bidir.):这是架构的核心。由于fMRI序列不具有因果时序性(整个任务期间的脑活动是同时相关的),作者将标准的前向S5扩展为双向形式。该块包含两个并行的S5模块,一个处理原始时间序列
h_t = A h_{t-1} + B x_t,另一个处理时间反转的序列h'_t = A h'_{t-1} + B x_{T-t}。最后,将两个方向的隐状态h_t和h'_t以及输入x_t和x_{T-t}拼接,并通过一个调制矩阵(C~,D~)进行融合,得到输出y_t。这种设计允许模型同时捕捉来自序列过去和未来的上下文信息。 - 堆叠块:上述双向S5块与层归一化(LayerNorm)和前馈网络(FFN)组合,构成一个完整的Transformer风格块。整个模型由L=2个这样的块堆叠而成。
- 输出头:堆叠块的输出经过平均池化(对所有时间步取平均),然后通过一个投影层和sigmoid激活函数,输出该试验可懂度高的概率
ŷ。
关键设计选择:
- 选择深度SSM(S5)而非Transformer:动机在于fMRI ROI内的体素序列非常长(如MTG可达11,669个体素),而SSM在处理长序列时具有线性复杂度的高效性。
- 双向建模:直接针对fMRI数据非因果的特性,确保模型能整合整个试验时长内的信息。
- ROI-wise建模:对每个ROI单独训练一个模型,以便于神经科学解释。
💡 核心创新点
- 跨声学条件可懂度解码的首次尝试:这是论文最核心的贡献。以往研究大多局限于干净语音,本工作首次系统性地在噪声(Noisy)和两种语音增强(DNN-SE, Classic-SE)条件下解码可懂度,并验证了跨条件迁移能力。
- 面向fMRI的双向深度状态空间模型架构:专门针对fMRI数据的高维(大量体素)和长时序特性,设计了基于S5的双向模型。这与主要处理1D音频信号或文本序列的SSM应用不同,展示了该架构在神经影像分析中的新应用。
- 揭示条件不变的神经编码:通过跨条件迁移实验(Table 2)提供了证据,表明在STG、MTG、IFG和PreCG等脑区中,存在与具体声学条件无关的、表征抽象可懂度的神经活动模式。
- 系统性的区域贡献分析:在多种条件下,一致地量化了从初级听觉皮层(HG)到额顶网络(IFG, PreCG, SMG)各ROI的解码贡献,丰富了我们对语音可懂度神经基础的理解。
🔬 细节详述
- 训练数据:来自25名健康普通话母语者的fMRI数据。实验设计包含72个句子,在三种声学条件(各24个试次)下呈现。数据集名称和获取方式未在论文中提及。
- 损失函数:论文未明确说明损失函数名称。根据任务(二分类)和输出(概率),推测使用二元交叉熵损失(Binary Cross-Entropy)。
- 训练策略:使用AdamW优化器,学习率为5.0×10⁻⁶。批大小为8,训练50个epoch。未提及学习率调度、warmup等细节。 关键超参数:堆叠块数 L=2,隐状态扩展比 r=2.0(即隐状态维度Q = rP)。嵌入和隐藏层维度(D)的具体数值未说明。
- 训练硬件:未说明训练所用的GPU型号、数量及训练时长。
- 推理细节:使用4折交叉验证进行评估。推理时,模型输出概率,通过阈值(默认0.5?论文未说明)得到分类结果。
- 正则化:未提及权重衰减、Dropout等额外正则化技巧,优化器名称中的AdamW暗示使用了解耦权重衰减。
📊 实验结果
主要实验结果集中在三个表格中。
表1:三种声学条件下,ROI-wise的解码性能比较(分类准确率%)
| 方法 | 条件 | 左脑 HG | 左脑 STG | 左脑 MTG | 左脑 IFG | 左脑 PreCG | 左脑 SMG | 右脑 HG | 右脑 STG | 右脑 MTG | 右脑 IFG | 右脑 PreCG | 右脑 SMG |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 随机 | - | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 |
| SVM | Noisy | 57.64 | 66.35 | 67.40 | 59.67 | 65.21 | 62.52 | 59.50 | 67.97 | 62.79 | 59.23 | 70.74 | 64.27 |
| Transformer | Noisy | 56.67 | 56.67 | 60.17 | 57.50 | 58.67 | 58.00 | 58.33 | 60.33 | 56.83 | 57.33 | 60.17 | 58.33 |
| Ours | Noisy | 58.33† | 66.50† | 69.83† | 68.00† | 63.33† | 63.00† | 59.50† | 70.17† | 64.50† | 63.50† | 73.00† | 62.67† |
| SVM | DNN-SE | 61.70 | 64.91 | 61.75 | 56.95 | 61.91 | 56.22 | 55.63 | 64.73 | 59.83 | 59.31 | 64.75 | 57.28 |
| Transformer | DNN-SE | 59.17 | 58.33 | 52.67 | 54.67 | 55.33 | 53.67 | 56.17 | 54.00 | 58.33 | 55.33 | 55.17 | 54.50 |
| Ours | DNN-SE | 57.83† | 66.83† | 64.17† | 59.50† | 64.17† | 57.33† | 58.33† | 64.33† | 61.83† | 60.67† | 67.50† | 62.33†‡ |
| SVM | Classic-SE | 57.71 | 61.30 | 63.47 | 59.54 | 59.66 | 55.64 | 56.75 | 60.92 | 60.51 | 58.77 | 60.42 | 57.21 |
| Transformer | Classic-SE | 61.50 | 64.50 | 60.00 | 60.67 | 61.17 | 57.67 | 60.50 | 59.17 | 63.83 | 57.17 | 63.83 | 64.00 |
| Ours | Classic-SE | 68.50†‡ | 67.67† | 66.17† | 64.50† | 64.50† | 64.33† | 65.33† | 70.17†‡ | 66.50† | 65.50†‡ | 68.50† | 65.33† |
表1关键结论:所提方法(Ours)在大多数ROI上达到了最高或持平的准确率,并显著优于随机猜测(†p<0.05)和/或最佳基线(‡p<0.05)。尤其在Classic-SE条件下,优势更为明显,左脑HG、右脑STG、右脑IFG等区域显著优于最强基线。
表2:跨条件迁移解码结果(左脑ROI,准确率%)
| 迁移任务 | Heschl | STG | MTG | IFG | PreCG | SMG |
|---|---|---|---|---|---|---|
| 随机 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 |
| Noisy→DNN-SE | 58.63† | 60.25† | 61.42† | 59.25† | 61.58† | 57.08† |
| Noisy→Classic-SE | 51.13 | 61.71† | 61.54† | 58.67† | 59.67† | 54.88† |
表2关键结论:在嘈杂条件下训练的模型,在多种增强条件下测试,性能均显著高于随机水平(†p<0.05)。这表���模型学习到了跨声学条件的泛化特征,支持“条件不变神经编码”的假说。PreCG在迁移到DNN-SE时表现最佳(61.58%),STG在迁移到Classic-SE时表现最佳(61.71%)。
表3:左脑消融研究(Noisy条件,准确率%)
| 方法 | Heschl | STG | MTG | IFG | PreCG | SMG |
|---|---|---|---|---|---|---|
| 随机 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 |
| Ours (完整) | 58.33 | 66.50 | 69.83 | 68.00 | 63.33 | 63.00 |
| w/o Bidir. | 57.17 | 65.67 | 70.33 | 65.83 | 65.33 | 62.67 |
| w/o S5 | 57.33 | 65.83 | 70.67 | 65.50 | 65.00 | 62.67 |
表3关键结论:完整模型在HG、STG、IFG、SMG上取得最优或并列最优。去掉双向扫描(w/o Bidir.)或替换掉S5层(w/o S5)后,在多个脑区性能有所下降,证明了这两个组件的有效性,但影响幅度不一。
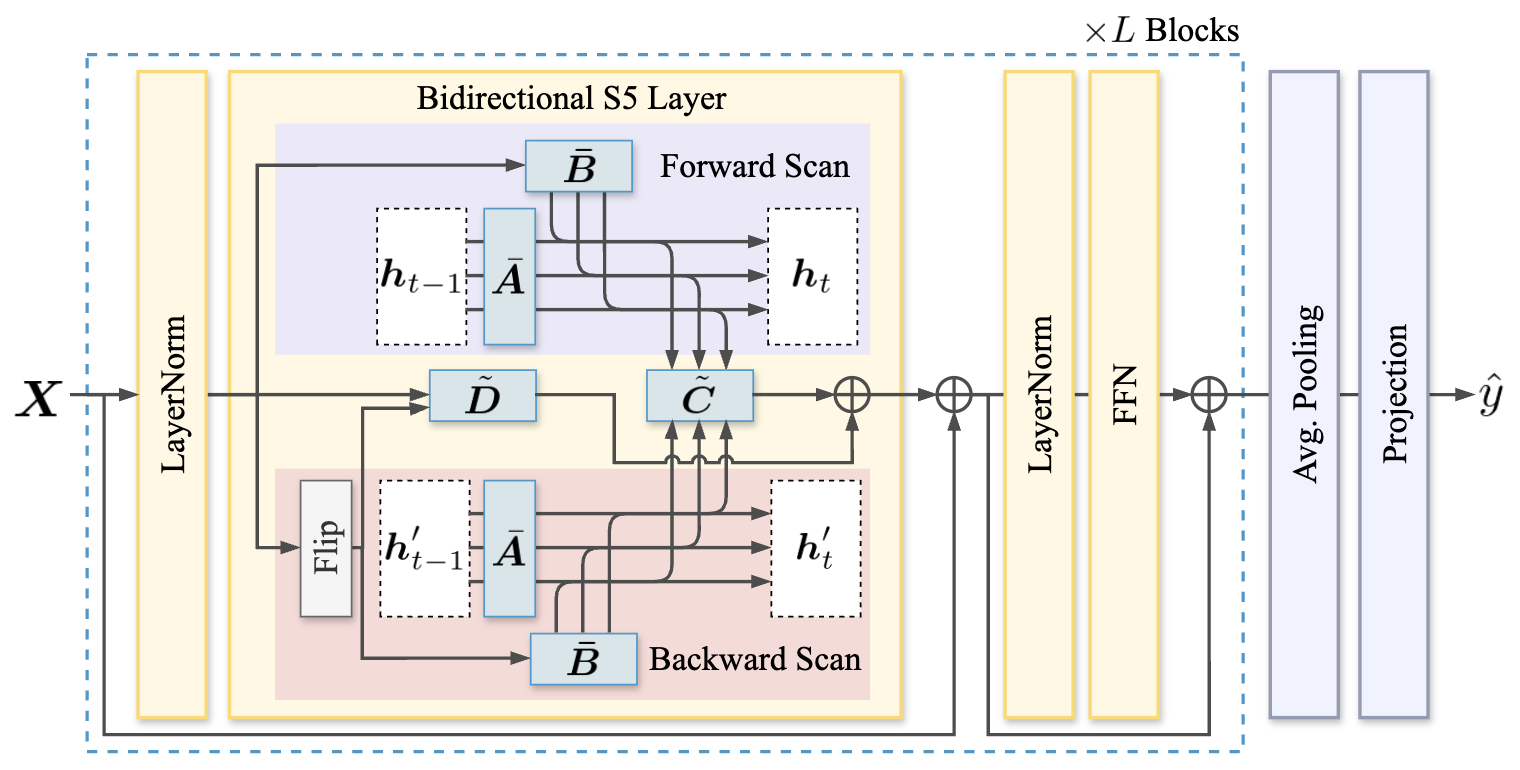 图1:跨不同声学条件的fMRI解码语音可懂度流程图。
图1:跨不同声学条件的fMRI解码语音可懂度流程图。
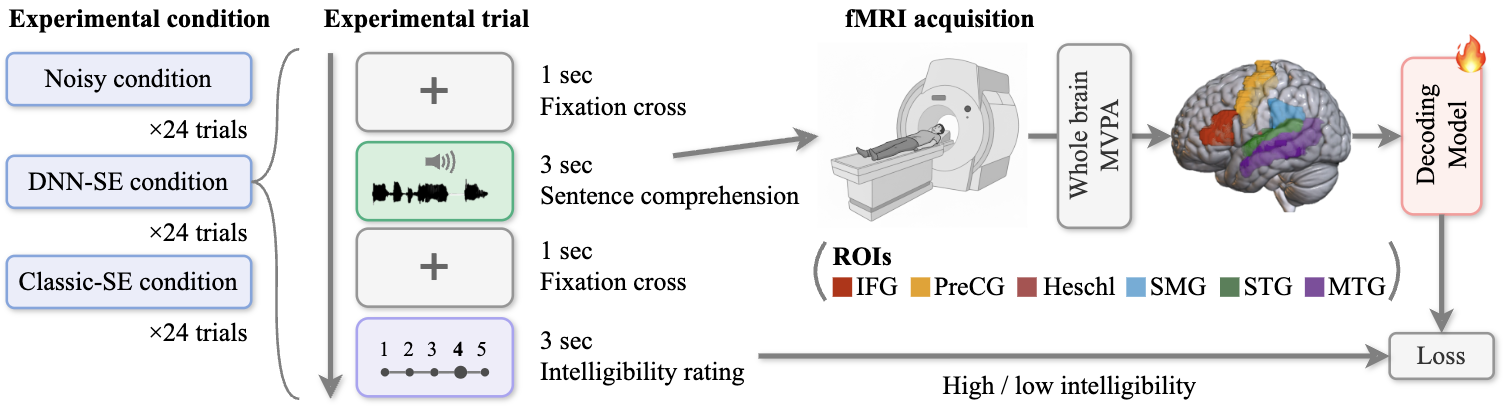 图2:STOI与跨条件感知语音可懂度评分的相关性。 显示主观评分与客观STOI指标高度相关(r=0.78),验证了行为目标的有效性。
图2:STOI与跨条件感知语音可懂度评分的相关性。 显示主观评分与客观STOI指标高度相关(r=0.78),验证了行为目标的有效性。
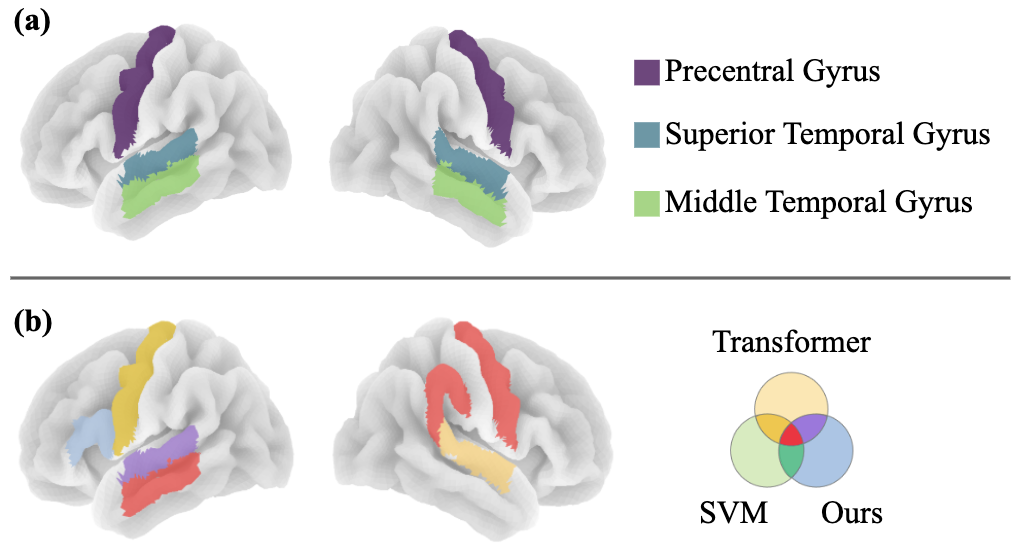 图4:语音可懂度解码显著脑区可视化。(a) 全脑MVPA结果(FWE校正,p<0.001)。(b) 嘈杂条件下解码性能最高的前五个ROI。 该图直观展示了双边STG、MTG、PreCG等区域在解码中的关键作用。
图4:语音可懂度解码显著脑区可视化。(a) 全脑MVPA结果(FWE校正,p<0.001)。(b) 嘈杂条件下解码性能最高的前五个ROI。 该图直观展示了双边STG、MTG、PreCG等区域在解码中的关键作用。
⚖️ 评分理由
- 学术质量:5.5/7。创新性体现在跨条件解码范式和对双向SSM的针对性改造上。技术正确性较好,实验设计(包含多条件、多基线、迁移学习、消融实验)和统计分析(显著性检验)较为充分。证据可信度中等,主要受限于样本量(25人)和未公开代码数据。
- 选题价值:1.5/2。选题位于神经科学与语音处理的前沿交叉点,具有明确的科学问题(条件不变表征)和潜在应用方向(脑启发式语音增强)。对于关注神经解码和鲁棒语音处理的读者有较高参考价值。
- 开源与复现加成:0/1。论文未提供代码、模型权重、数据集或详细的复现配置,这是重大减分项,严重阻碍了社区的验证和后续研究。