📄 Compression meets Sampling: LZ78-SPA for Efficient Symbolic Music Generation
#音乐生成 #自回归模型 #压缩感知 #高效计算
✅ 7.5/10 | 前25% | #音乐生成 | #自回归模型 | #压缩感知 #高效计算
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 中
👥 作者与机构
- 第一作者:Abhiram Gorle(斯坦福大学电气工程系)
- 通讯作者:未说明
- 作者列表:Abhiram Gorle(斯坦福大学电气工程系)、Connor Ding(斯坦福大学电气工程系)、Sagnik Bhattacharya(斯坦福大学电气工程系)、Amit Kumar Singh Yadav(普渡大学电气与计算机工程学院)、Tsachy Weissman(斯坦福大学电气工程系)
💡 毒舌点评
亮点:论文将“压缩即学习”的思想应用于符号音乐生成,提供了扎实的理论保证(如有限样本边界),并以惊人的计算效率(30倍训练加速、300倍生成加速)挑战了深度学习模型在资源消耗上的“暴力美学”。短板:作为生成模型,其音乐创作的“灵魂”——即长期结构、复杂和声与旋律发展——可能受限于LZ78上下文树的局部性,论文在“无条件生成”上的成功是否能扩展到更有用的“条件生成”场景存在疑问。此外,将训练1小时的扩散模型(ASD3PM A1)作为主要效率对比对象,虽然体现了计算预算匹配,但难免让人感觉像是在和“半成品”赛跑。
🔗 开源详情
- 代码:论文未直接提供代码仓库链接,但指出更长版本可能包含更多信息(“longer version”)。
- 模型权重:未提及公开模型权重。
- 数据集:使用公开的Lakh MIDI Dataset (LMD),未提及自行托管。
- Demo:提供了部分生成的音频样本链接(
https://shorturl.at/Yk1cO)。 - 复现材料:论文附录中声称包含所有定理证明、基线和超参数的更多细节,以及FLOPs比较和LLM-as-Judge评估。
- 引用的开源项目/工具:
- 评估:使用VGGish模型计算FAD。
- 音频渲染:使用FluidSynth将MIDI转换为WAV。
- 超参数优化:使用Optuna。
- 基线模型:引用了MusicVAE, CTW, ASD3PM等工作的开源实现或论文。
📌 核心摘要
- 要解决什么问题:现有的符号音乐生成深度学习模型(如Transformer、扩散模型)计算成本高昂,严重限制了其可扩展性和在通用CPU设备上的部署。
- 方法核心是什么:提出LZMidi框架,它基于LZ78压缩算法构建一个序列概率分配器(SPA)。该方法通过增量解析训练MIDI序列来构建一棵树,树的每个节点记录上下文出现后各符号的频率,从而隐式地学习数据分布。生成时,从树中采样下一个符号,无需反向传播或梯度更新。
- 与已有方法相比新在哪里:首次将具有理论保证的LZ78-SPA系统性地应用于符号音乐生成任务,并提供了从渐近收敛到有限样本性能的完整理论分析。与深度生成模型相比,它彻底摆脱了对GPU的依赖,实现了极低的训练和推理成本。
- 主要实验结果如何:在Lakh MIDI数据集上,LZMidi在生成质量(FAD, WD)上与经典基线(HMM,CTW)和轻量级深度基线(MusicVAE,训练1小时的ASD3PM)相比具有竞争力,有时甚至更优。在计算效率上,与ASD3PM相比,训练速度快30倍,单样本生成速度快300倍,能耗降低数个数量级。
关键实验结果表格:
表1:一致性(C)和方差(Var)指标(↑更好)
| 模型 | 训练集-音高C | 训练集-音高Var | 训练集-时值C | 训练集-时值Var | 测试集-音高C | 测试集-音高Var | 测试集-时值C | 测试集-时值Var |
|---|---|---|---|---|---|---|---|---|
| LZMidi | 0.97 | 0.92 | 0.97 | 0.93 | 0.97 | 0.93 | 0.97 | 0.94 |
| ASD3PM(A2) | 0.98 | 0.86 | 0.98 | 0.87 | 0.99 | 0.89 | 0.96 | 0.87 |
| HMM | 0.91 | 0.75 | 0.92 | 0.78 | 0.90 | 0.76 | 0.91 | 0.77 |
| CTW | 0.94 | 0.80 | 0.95 | 0.82 | 0.94 | 0.81 | 0.95 | 0.82 |
| MusicVAE | 0.97 | 0.84 | 0.98 | 0.89 | 0.96 | 0.84 | 0.98 | 0.87 |
表2:WD、FAD和KL散度指标(↓更好)
| 模型 | 训练集WD | 训练集FAD | 训练集KL | 测试集WD | 测试集FAD | 测试集KL |
|---|---|---|---|---|---|---|
| LZMidi | 8.57 | 0.69 | 1.42 | 8.39 | 0.64 | 1.37 |
| ASD3PM (A1) | 27.91 | 4.22 | 2.29 | 27.96 | 4.05 | 2.26 |
| HMM | 28.31 | 4.38 | 2.90 | 27.44 | 4.31 | 2.88 |
| CTW | 10.82 | 1.22 | 1.92 | 10.35 | 1.05 | 1.85 |
| MusicVAE | 7.76 | 0.71 | 1.37 | 7.55 | 0.62 | 1.34 |
| ASD3PM (A2) | 7.51 | 0.64 | 1.23 | 7.42 | 0.61 | 1.22 |
表3:训练/生成时间、内存和能耗(ASD3PM (A1)用于对比)
| 模型 | 训练时间(s) | 生成时间(s/样本) | 模型大小(MB) | 训练能耗(kJ) | 生成能耗(J/样本) |
|---|---|---|---|---|---|
| LZMidi | 107.7 | 0.016 | 287.1 | 9.144 | 1.36 |
| ASD3PM | 3480 | 5.4 | 306.2 | 2088 | 3240 |
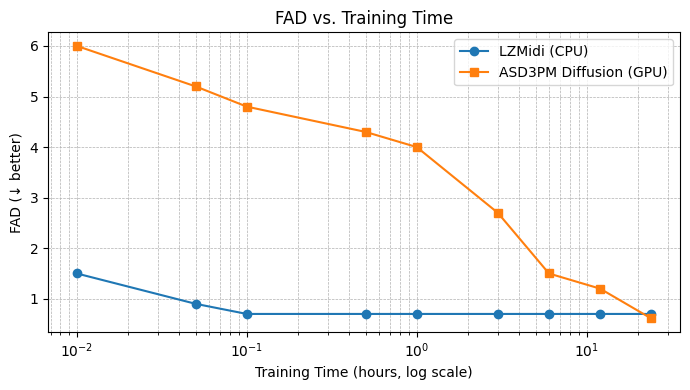 图5显示,在相等的训练时间内,LZMidi的FAD分数(衡量感知质量)远低于ASD3PM,表明其“质量-计算效率”权衡更优。
图5显示,在相等的训练时间内,LZMidi的FAD分数(衡量感知质量)远低于ASD3PM,表明其“质量-计算效率”权衡更优。
- 实际意义是什么:为资源受限环境(如教育软件、移动应用、快速创作原型)下的高质量音乐生成提供了一个轻量级、理论扎实的可行方案。证明了通用压缩算法可以作为参数化深度学习模型的高效替代品,用于特定结构化数据的生成。
- 主要局限性是什么:目前仅支持无条件生成,难以控制生成音乐的特定属性(如风格、和弦进行)。对于需要捕捉极长程音乐结构(如整首歌曲的段落发展)的任务,可能力有不逮。随着训练语料库的急剧增长,LZ树的规模管理将成为挑战。
🏗️ 模型架构
LZMidi并非一个传统的神经网络架构,而是一个基于LZ78压缩算法构建的概率模型。其整体流程可分为“训练(构建树)”和“生成(从树中采样)”两个阶段。
- 核心组件:LZ78树
- 功能:存储从训练数据中学习到的所有上下文-符号对的统计信息。
- 结构:这是一棵多叉树。
- 根节点:代表空上下文。
- 内部节点:代表一个已观察到的“短语”(即一个特定的符号序列上下文)。从根节点到该节点的路径上的符号序列就是该上下文。
- 边:从父节点指向子节点的边标记着一个符号
a(属于字母表X,这里X = {0, 1, ..., 89},代表休止符、延续符和88个音高)。 - 叶节点:没有子节点,但可以被扩展。
- 关键设计选择:选择LZ78而非LZ77或LZMA,因为LZ78天然生成前缀树,每个节点(上下文)明确对应一个统计计数表,这直接对应了式(1)中计算SPA所需的
NLZ(a|xt-1)。这使得概率模型非常直观。
- 训练过程(构建LZ78树)
- 输入:一个MIDI序列,被标记为整数序列
x1, x2, ..., xn。 - 流程:算法从序列头开始,维护一个当前上下文(初始为空)。对于每个位置,算法检查:将当前符号追加到上下文形成的短语,是否已经作为当前上下文的一个子节点存在于树中。
- 如果存在:则将当前符号追加到上下文,继续向后看。
- 如果不存在:则创建一个新节点,将此新短语(当前上下文 + 新符号)添加到树中。然后,重置当前上下文为空,从下一个符号重新开始。
- 数据流:遍历整个训练集,上述过程不断在已有的树上生长新的节点。最终,树的每个节点都记录了其父节点上下文出现后,各个子符号
a出现的次数NLZ(a|xt-1)。
- 概率分配与生成过程
- SPA计算:对于任意给定上下文
xt-1(对应树中的某个节点),预测下一个符号a的概率由Dirichlet平滑的经验频率给出,即论文中的式(1):qLZ,γ(a|xt-1)。其中γ是平滑参数,|X|是字母表大小。 - 生成流程:
- 种子:随机选择一个根节点的直接子节点对应的符号作为序列的第一个符号。这相当于从一个“见过的”短语开始。
- 自回归采样:对于当前序列(上下文),在LZ树中找到对应的节点。根据该节点的子节点统计信息,利用式(1)计算下一个符号的概率分布。然后,使用Top-K采样(论文中K=8)和温度T(论文中T=0.8)从这个分布中采样出下一个符号。
- 重复:将新符号追加到序列中,重复步骤2,直到生成所需长度(256个符号)的序列。
- 后处理:将整数序列映射回MIDI音符,并应用规则(确保“延续符1”不跟在“休止符0”之后)进行清理。
- 组件交互:生成过程完全依赖于训练阶段构建好的静态LZ树。没有可学习的参数(如神经网络权重),只有树的结构和节点中存储的计数。
架构总结:LZMidi将音乐生成问题转化为一个基于数据驱动的、树结构的上下文模型上的序列预测问题。其“架构”就是这棵LZ78树,训练就是构建树,生成就是遍历树并采样。
💡 核心创新点
- 将通用压缩理论系统化应用于符号音乐生成:之前的工作(如[15, 16])使用过LZ类方法进行音乐风格建模或分类,但本文是首个将具有严格理论保证的LZ78-SPA框架完整地、显式地作为生成模型提出,并命名为LZMidi。这不仅是应用,更是将压缩理论与生成任务进行了形式化连接。
- 提供完整的理论性能保证:不仅证明了LZ78-SPA在训练数据量趋于无穷时的渐近收敛性(定理2.1),更关键的是提供了有限样本下的非渐近界(定理2.2-2.4)。这些定理量化了“通用性的代价”,即生成序列长度
n和训练序列数量m如何影响生成分布与真实分布之间的KL散度。这为方法的可靠性提供了强有力的理论支撑,是纯实验性工作所不具备的。 - 在效率上实现量级突破:通过与多种深度生成模型进行严格、公平的对比,实验结果定量地展示了LZ78-SPA在训练速度(30x)、生成速度(300x)和能耗(数个数量级)上的巨大优势。这并非简单的改进,而是一种范式转换的可能性,即用极低的计算成本获得可比的质量,将生成能力从“GPU专享”下沉到“CPU可用”。
- 提出针对计算效率的评估视角:论文不仅报告了绝对性能(FAD, WD),还专门引入了“计算匹配效率”分析(图5),展示了在相等的训练时间预算下,LZMidi能更快地达到较低的FAD。这种评估方式突出了其核心价值主张——“质量-计算”权衡的优越性,为比较不同计算量级的模型提供了新思路。
🔬 细节详述
- 训练数据:
- 数据集:Lakh MIDI Dataset (LMD)。
- 规模:648,574个样本。
- 预处理:每个MIDI样本被处理成固定长度为256的符号序列。符号来自字母表
X = {0, 1, ..., 89},其中0=休止符,1=延续符,2-89=音高。未说明是否做了音高移位、速度归一化等额外的数据增强。
- 损失函数:无显式的损失函数。模型通过最大化训练序列的似然来隐式学习,而LZ78算法的构建过程本身就是在逼近序列的熵率,从而最小化负对数似然。
- 训练策略:
- 优化器:无。模型不是基于梯度下降优化的。
- 训练过程:遍历所有训练序列,对每个序列执行LZ78的增量解析和树更新。
- 学习率/Batch Size:不适用。
- 训练时长:在Apple M1 CPU上,训练Lakh MIDI全集耗时107.7秒(表3)。
- 关键超参数:
- Dirichlet参数 (γ):控制概率平滑程度。通过Optuna扫描发现,较小的值如
5 × 10^-5效果更好。 - Top-K (K):生成时只从概率最高的K个符号中采样。论文中K=8。
- 温度 (T):控制采样分布的“尖锐程度”。T=0.8。
- 最小上下文 (Min. Context):论文中设为64。未详细说明该参数如何具体影响LZ树的构建或生成(可能是指在上下文长度小于此值时不进行预测?)。
- 序列长度:所有实验统一使用256个符号。
- Dirichlet参数 (γ):控制概率平滑程度。通过Optuna扫描发现,较小的值如
- 训练硬件:Apple M1 CPU(单颗)。未说明具体型号(如M1, M1 Pro)和内存大小。
- 推理细节:
- 解码策略:基于LZ树的Top-K采样(K=8, T=0.8)。
- 流式设置:未提及。
- 正则化或稳定训练技巧:无。Dirichlet平滑(γ参数)可以看作是一种防止零概率的正则化手段。
📊 实验结果
论文在Lakh MIDI数据集(80/20划分)上进行了全面的实验对比。
主要Benchmark与基线:
- 基线模型:HMM(二元语法),CTW(上下文树加权),MusicVAE(预训练),ASD3PM(离散扩散模型)。ASD3PM有两个版本:A1(仅训练1小时)和A2(完整训练)。
- 评估指标:
- 质量指标:FAD(↓), WD(↓), KL散度(↓)。
- 统计相似性指标:帧级一致性(Consistency, ↑)和方差(Variance, ↑),基于音高和时值。
- 效率指标:训练时间,单样本生成时间,内存占用,能耗。
主要结果与差距分析:
- 生成质量(表2):
- LZMidi vs. 经典基线:在所有指标上显著优于HMM和CTW。例如,在测试集上,LZMidi的FAD(0.64)远低于HMM(4.31)和CTW(1.05)。
- LZMidi vs. 深度基线:
- 与ASD3PM(A1)相比:LZMidi全面胜出(WD: 8.39 vs 27.96, FAD: 0.64 vs 4.05)。
- 与MusicVAE相比:表现持平或略有胜负。LZMidi在测试集WD上略逊(8.39 vs 7.55),但在FAD和KL上相近或更优。
- 与ASD3PM(A2)相比:ASD3PM(A2)在绝对指标上略优(WD: 7.42 vs 8.39, FAD: 0.61 vs 0.64)。LZMidi在质量和ASD3PM完整训练版本的差距很小。
- 统计相似性(表1):
- LZMidi在一致性(C)和多样性(Var)上都达到了很高的分数(0.92-0.97),与真实数据分布非常接近。其方差分数普遍高于所有基线,表明它生成的音乐在统计特性上更多样,避免了模式崩溃。
- 计算效率(表3与图5):
- 这是论文最强的论证点。LZMidi的训练时间(107.7秒)比ASD3PM(3480秒)快约32倍。
- 生成速度:LZMidi生成一个样本仅需0.016秒,而ASD3PM需5.4秒,快约337倍。
- 能耗:训练能耗LZMidi为9.144 kJ,ASD3PM为2088 kJ,相差228倍。单样本生成能耗相差约2382倍。
- 图5直观显示,在相等的训练时间内(例如300秒),LZMidi的FAD已经降至0.7左右,而ASD3PM仍高于4.0,凸显了其惊人的“计算-质量”效率。
消融实验:论文未进行传统意义上的消融实验(如移除理论保证、改变树结构等)。但其通过超参数扫描(γ, T, K)和与不同复杂度基线的对比,间接验证了各组件的有效性。
关键图表描述:
- 图1:展示了MIDI序列的乐谱视图,帮助理解输入数据格式。
- 图2:显示了数据集中符号(0, 1, 2-89)的原始频率分布,休止符(0)和延续符(1)占主导。
- 图3:展示了实际音高(2-89)的分布,集中在中音区。
- 图4:展示了LZMidi生成的一个样本的MIDI乐谱,直观显示其生成结果。
- 图5:如上述分析,是效率对比的关键证据。
⚖️ 评分理由
- 学术质量:5.5/7。论文在理论层面贡献扎实,将压缩理论与生成任务形式化结合,并提供了严格的数学保证。实验设计全面,对比基线覆盖广,评估维度多元(质量+效率)。主要不足在于,作为生成模型,其最终输出的音乐在感知复杂度和艺术性上,与最顶尖的深度生成模型相比可能并未实现超越,且部分效率对比的设置(ASD3PM A1 vs. A2)需要读者注意其前提。论文的创新更多在于框架的引入和效率的极致展示,而非在生成质量上达到新的SOTA。
- 选题价值:1.5/2。选题切中当前AI模型能耗高、部署难的痛点,具有明确的实用价值和环保意义。将高效计算作为核心卖点,区别于大多数追求生成质量的论文。但符号音乐生成相对于更广泛的语音/音频任务,受众和影响力相对有限。
- 开源与复现加成:+0.3。论文提供了评估样本链接和指向可能包含更多细节的长版本链接,超参数和流程描述清晰,具备中等程度的可复现性。但缺少直接的代码仓库和预训练模型,扣分。