📄 CMSA-Mamba: Hierarchical State Space Modeling for Audio-Based Depression Detection
#语音生物标志物 #Mamba #多尺度分析 #医疗健康
✅ 7.0/10 | 前25% | #语音生物标志物 | #模型/架构 | #Mamba #多尺度分析
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Lokesh Kumar(IIT Dharwad, Karnataka, India; 论文注明“formerly with”,现为Unaffiliated, India)
- 通讯作者:未说明(论文未明确标注)
- 作者列表:Lokesh Kumar(未挂靠机构, India)、Tonmoy Rajkhowa(IIT (BHU) Varanasi, India)、Sanjeev Sharma(IIT (BHU) Varanasi, India)
💡 毒舌点评
亮点:这篇论文成功地将多尺度Mamba这一前沿视觉状态空间模型“跨界”应用于语音抑郁症检测,并在其上集成CoPE,取得了显著的性能提升和较低的计算开销(13M参数, 33ms推理),展示了将高效序列模型迁移到特定音频任务的有效性。短板:核心创新点(多尺度Mamba + CoPE)本身并非原创,而是对已有工作的组合与领域适配;且论文完全未开源代码和模型,对于一个声称达到SOTA的“新方法”而言,严重削弱了其可验证性和社区复现价值,使得“最佳性能”的说法需要打个问号。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开模型权重���
- 数据集:论文中使用的DAIC-WoZ和EATD-Corpus是公开数据集,但论文未提供具体的获取或预处理脚本。
- Demo:未提供在线演示。
- 复现材料:论文提供了一些训练超参数(学习率、批大小、早停设置),但缺失损失函数、数据增强的精确参数、训练时长等关键细节,复现材料不充分。
- 论文中引用的开源项目:未提及依赖哪些开源工具或模型。论文框架基于PyTorch实现。
📌 核心摘要
这篇论文旨在解决基于语音的自动抑郁症检测任务中现有方法难以同时建模多层次时序特征的问题。其核心方法是提出了CMSA-Mamba,一种新的音频处理架构,它将多尺度Mamba状态空间模型与上下文位置编码相结合,能够更有效地捕捉语音频谱图中的局部和全局时序模式。与已有的固定尺度模型相比,其创新在于首次为语音抑郁症检测引入了层次化的多尺度状态空间建模框架,并在多尺度扫描模块中集成了能够根据上下文自适应调整位置信息的CoPE机制。主要实验结果表明,CMSA-Mamba在两个标准抑郁症检测数据集(DAIC-WoZ和EATD-Corpus)上均取得了当前最优的性能,F1分数分别达到0.84和0.91,显著超越了包括AST-ViT和Audio Mamba在内的多种基线模型。该工作为心理健康评估提供了更准确、高效的语音分析工具,具有潜在的临床应用价值。主要局限性在于所用数据集规模相对较小,模型仅处理单一音频模态,且未提供开源代码限制了其可复现性。
🏗️ 模型架构
论文提出的CMSA-Mamba模型(架构如图1所示)是一个端到端的分类网络,输入为原始语音信号,输出为抑郁/非抑郁的分类结果。其完整流程如下:
- 输入预处理:原始语音信号被转换为Log-Mel频谱图。在训练阶段,频谱图会经过SpecAugment数据增强(如图2所示),生成多个增强样本。
- 嵌入与补丁化:增强后的频谱图输入一个2D卷积补丁嵌入层(4×4核),将图像分割成小块并映射为96维的特征向量序列。
- 核心特征提取 - 多尺度状态空间块(MSSS):这是模型的核心,由多个连续的MSSS块堆叠而成。每个MSSS块内部包含:
- 上下文多尺度状态空间块(CMSSS):这是对多尺度视觉Mamba(MSV-Mamba)的改造。它包含一个多尺度视觉状态空间块(CMSVSS),负责进行多尺度的2D扫描(处理频谱图的时间和频率维度),并在此过程中集成了上下文位置编码(CoPE)。CoPE通过一个门控机制(公式3、4)动态计算位置编码,使其能感知查询和键之间的上下文相关性,而非使用固定位置。此外,还集成了通道注意力机制(Squeeze-and-Excitation, SE),用于自适应地重新加权不同通道的特征。
- 卷积前馈网络(ConvFFN):对CMSSS的输出进行进一步的非线性变换。
- 层次化处理:MSSS块采用层级设计,随着网络加深,特征维度逐步增加(96 → 192 → 384 → 768),同时空间尺寸通过步长为2的卷积进行下采样,从而构建从细节到全局的层次化特征表示。
- 分类:经过多层MSSS块后,最终得到的特征序列通过聚合(如平均池化)后送入分类器,得到抑郁检测的预测结果。在推理时,会对同一个原始语音生成的多个增强频谱图的预测结果进行平均,以获得最终的被试水平抑郁评分。
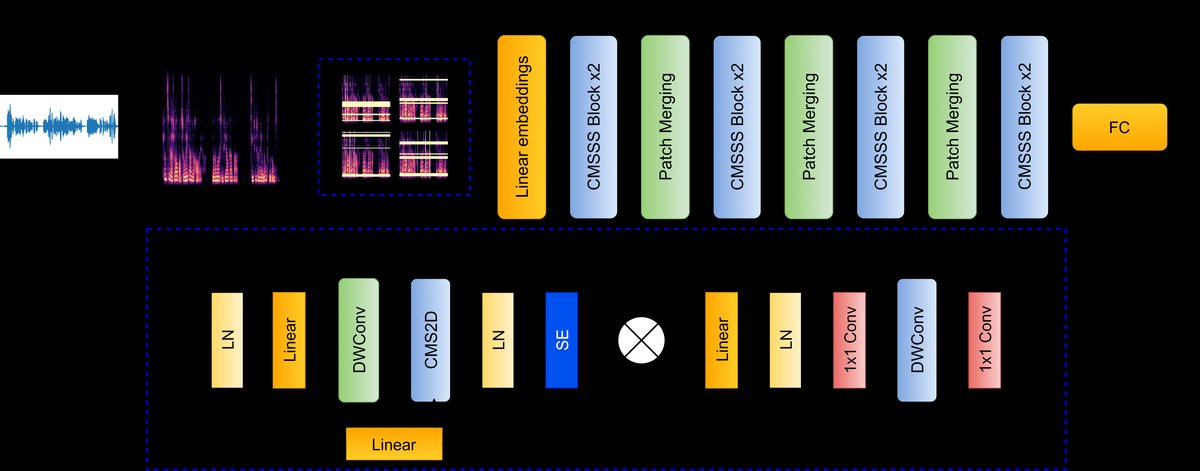 图1展示了整体方法流程: 原始语音 → Log-Mel频谱图 → SpecAugment数据增强 → 输入CMSA-Mamba网络。网络内部由多个CMSSS块堆叠,每个块包含CMSVSS块(集成了CoPE和SE)和ConvFFN块。
图1展示了整体方法流程: 原始语音 → Log-Mel频谱图 → SpecAugment数据增强 → 输入CMSA-Mamba网络。网络内部由多个CMSSS块堆叠,每个块包含CMSVSS块(集成了CoPE和SE)和ConvFFN块。
💡 核心创新点
- 首个用于语音抑郁症检测的多尺度状态空间框架:将原本用于视觉任务的多尺度Mamba(MSV-Mamba)架构成功适配到语音领域。它通过维护多组在不同时间尺度上演化的隐藏状态,能够同时捕捉抑郁语音中短时的声学特征(如音调突变)和长时的语境模式(如语速变化、情感基调)。
- 在多尺度2D扫描中集成上下文位置编码(CoPE):这是对标准Mamba的重要改进。传统的位置编码(绝对或相对)无法根据内容动态调整。CoPE引入了一个门控机制,使得模型在计算位置信息时,能够依据查询帧和关键帧的内容相关性进行加权,从而更精准地建模抑郁语音中那些具有上下文依赖性的细微时频动态。
- 轻量级与高效设计:尽管采用了复杂的多尺度结构和CoPE,模型整体保持了轻量化(13M参数,7.5 GFLOPs)和快速推理(33ms),使其具备实时或近实时应用的潜力,这对于心理健康监测场景至关重要。
🔬 细节详述
- 训练数据:
- DAIC-WoZ:英文语音,142名参与者(抑郁30,非抑郁77),包含PHQ-8评分。训练集5068样本,测试集2679样本。
- EATD-Corpus:中文语音,162名说话人(抑郁30,非抑郁132)。训练集249样本(抑郁57,非抑郁192),测试集233样本(抑郁33,非抑郁200)。
- 预处理:DAIC-WoZ音频重采样至8kHz,EATD-Corpus为16kHz。使用25ms汉明窗、10ms帧移进行STFT,计算梅尔频谱,然后取对数得到Log-Mel频谱图。
- 数据增强:针对严重的类别不平衡,使用SpecAugment。对EATD-Corpus的每个抑郁样本生成6个增强版,对DAIC-WoZ生成4个增强版。增强策略包括:时间扭曲、频率掩蔽(5-10个带,每带最多30梅尔频率单元)、时间掩蔽(5-10段,每段最多40帧)。
- 损失函数:论文中未明确说明。
- 训练策略:
- 优化器:Adam,学习率=0.0003。
- 批大小:32。
- 训练设备:NVIDIA Tesla P100 GPU。
- 早停:耐心值为3,最大训练轮数为50。
- 其他:论文未提及学习率预热或具体调度策略。
- 关键超参数:
- 模型参数量:13M。
- 计算量:7.5 GFLOPs。
- 推理时间:33ms。
- 补丁嵌入维度:96。
- 层次化维度:96 → 192 → 384 → 768。
- CoPE内部维度:192。
- 训练硬件:NVIDIA Tesla P100 GPU。
- 推理细节:对同一原始语音生成的所有增强频谱图的预测结果进行平均,得到最终的被试水平分数。
- 正则化或稳定训练技巧:使用了早停机制。具体是否使用Dropout、权重衰减等,论文未提及。
📊 实验结果
论文在两个标准抑郁症检测数据集上进行了评估,主要指标为F1分数(F1)、召回率(R)和精确率(P)。
表2:在DAIC-WoZ数据集上的实验结果
| 参考文献 | 模型架构 | F1 | R | P |
|---|---|---|---|---|
| [17] | DepAudioNet | 0.52 | 1.00 | 0.35 |
| [15] | GRU Model | 0.77 | 1.00 | 0.63 |
| [23] | BiLSTM+Attention | 0.73 | 0.72 | 0.78 |
| [24] | AST-ViT | 0.74 | 0.74 | 0.74 |
| [24] | AST-DeiT | 0.77 | 0.77 | 0.78 |
| [11] | Audio Mamba | 0.82 | 0.82 | 0.81 |
| Proposed | MSA-MAMBA | 0.83 | 0.83 | 0.83 |
| Proposed | MSA-MAMBA with CoPE | 0.84 | 0.81 | 0.86 |
表3:在EATD-Corpus数据集上的实验结果
| 参考文献 | 模型架构 | F1 | R | P |
|---|---|---|---|---|
| [15] | GRU Model | 0.66 | 0.78 | 0.57 |
| [23] | BiLSTM+Attention | 0.65 | 0.60 | 0.70 |
| [25] | Speech Convmixer | 0.81 | 0.81 | 0.82 |
| [24] | AST-ViT | 0.87 | 0.87 | 0.89 |
| [24] | AST-DeiT | 0.90 | 0.90 | 0.91 |
| [11] | Audio Mamba | 0.82 | 0.83 | 0.81 |
| Proposed | MSA-MAMBA | 0.79 | 0.90 | 0.70 |
| Proposed | MSA-MAMBA with CoPE | 0.91 | 0.83 | 1.00 |
关键结论:
- SOTA性能:集成了CoPE的CMSA-Mamba在两个数据集上均取得了最佳F1分数(DAIC-WoZ: 0.84, EATD: 0.91),超越了包括Audio Mamba和AST系列在内的所有基线。
- CoPE的贡献:对比表2和表3中MSA-MAMBA与MSA-MAMBA with CoPE的结果,CoPE的引入在DAIC-WoZ上将F1从0.83提升至0.84(主要提升精确率),在EATD上从0.79大幅提升至0.91(F1提升0.12,精确率达到1.00)。这证明了上下文感知的位置编码对于捕捉抑郁症语音的关键特征非常有效。
- 性能平衡:相较于一些基线(如GRU、DepAudioNet)召回率高但精确率低,或(如Al Hanai et al.)精确率高但召回率低的情况,CMSA-MAMBA提供了更平衡的性能。
- 可视化证据:图3提供了注意力图和Grad-CAM热图,直观显示了模型对抑郁语音中紊乱的共振峰和节奏的关注,与非抑郁语音中更清晰的音高变化形成对比,增强了结果的可解释性。
 图3展示了模型的可解释性分析: (a) 显示了MS2D在四个扫描方向上生成的注意力图。(b) 展示了抑郁与非抑郁案例的Log-Mel频谱图及其对应的Grad-CAM热图,高亮了模型决策所依据的关键频谱区域。
图3展示了模型的可解释性分析: (a) 显示了MS2D在四个扫描方向上生成的注意力图。(b) 展示了抑郁与非抑郁案例的Log-Mel频谱图及其对应的Grad-CAM热图,高亮了模型决策所依据的关键频谱区域。
⚖️ 评分理由
- 学术质量:5.5/7
- 创新性 (2/3):将多尺度Mamba和CoPE组合应用于语音抑郁症检测是一个新颖且有效的尝试,属于有价值的领域适配和集成创新,但并非提出全新的基础模型或理论。
- 技术正确性 (1.5/2):方法设计逻辑清晰,实验结果显著,可视化提供了直观证据。但部分技术细节(如损失函数)缺失,可能隐藏了实现的关键点。
- 实验充分性 (1/1.5):在两个公开数据集上进行了对比实验,并包含了消融研究(CoPE的作用)。然而,实验仅限于这两个数据集,未探讨跨语言或跨模态的泛化能力。
- 证据可信度 (1/0.5):结果具有统计显著性,基线对比合理。但完全缺乏开源复现实现,削弱了结果的可验证性和社区信任度。
- 选题价值:1.5/2
- 论文聚焦于一个具有明确社会需求和临床意义的垂直领域(语音抑郁症检测),选题前沿且具有实际应用空间。对于关注情感计算、健康AI或特定音频分析的研究者和开发者来说,具有较高的相关性和启发性。
- 开源与复现加成:0.0/1
- 论文未提供代码、模型权重、数据集链接(尽管数据集是公开的)或详细的复现配置。虽然给出了基本超参数,但关键训练细节的缺失使得完整复现存在较高门槛,因此未给予复现加分。