📄 Chunkwise Aligners for Streaming Speech Recognition
#语音识别 #端到端 #流式处理 #模型架构 #自回归模型
✅ 7.5/10 | 前25% | #语音识别 | #端到端 | #流式处理 #模型架构
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Wen Shen Teo(University of Electro-Communications, Japan; NTT, Inc., Japan)
- 通讯作者:未明确说明(论文中标注两位第一作者Equal contribution,但未指定通讯作者)
- 作者列表:Wen Shen Teo(University of Electro-Communications, Japan; NTT, Inc., Japan)、Takafumi Moriya(NTT, Inc., Japan)、Masato Mimura(NTT, Inc., Japan)
💡 毒舌点评
亮点: 巧妙地将“对齐器”模型的全局自转导改造为分块操作,并通过一个简单的可学习“块结束概率”实现了流式解码,这在架构设计上既优雅又实用。 短板: 论文最大的短板在于其性能高度依赖于预训练的CTC模型提供的强制对齐质量,这在一定程度上限制了该方法的独立性和鲁棒性,使其“端到端”的成色打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开权重。
- 数据集:使用了公开的LibriSpeech和CSJ数据集。
- Demo:未提供在线演示。
- 复现材料:论文详细描述了模型架构、训练策略和关键超参数(如学习率、块大小、模型维度),提供了复现所需的理论基础。但未提供训练脚本、配置文件或检查点。
- 论文中引用的开源项目:引用并基于ESPnet工具包进行实验。使用了Montreal Forced Aligner生成对齐。
📌 核心摘要
这篇论文旨在解决流式语音识别中训练效率与准确性之间的权衡问题。现有流式模型如Transducer训练计算成本高昂,而近期提出的Aligner模型虽训练高效,但因丢失了局部时序信息而不适用于流式场景。本文提出的“分块对齐器”是其核心创新:它将输入音频分割为固定大小的块,利用编码器的自注意力模块在每个块内独立进行“自转导”,将每个标签对齐到该块最左侧的帧;同时,引入一个可学习的“块结束概率”来控制是否进入下一个音频块。与Aligner相比,新方法在块内局部对齐,降低了学习难度,并支持了流式解码。实验表明,在LibriSpeech和CSJ数据集上,分块对齐器在离线和流式场景下的词错误率/字符错误率均与Transducer相当,但训练仅使用简单的交叉熵损失,计算成本大幅降低;在解码速度上,其实时因子(RTF)优于Transducer,例如在LibriSpeech离线测试中RTF为0.12 vs 0.30。该方法的实际意义在于为流式ASR提供了一个训练更快、解码更快且精度不妥协的新选项。其主要局限性是对训练时使用的对齐数据质量敏感,在LibriSpeech上使用质量较差的CTC对齐会导致性能下降,未来需探索无对齐依赖的训练框架。
🏗️ 模型架构
本文提出的“分块对齐器”延续了经典的“编码器-预测器-连接器”架构,但对关键组件进行了创新设计以实现分块流式处理。
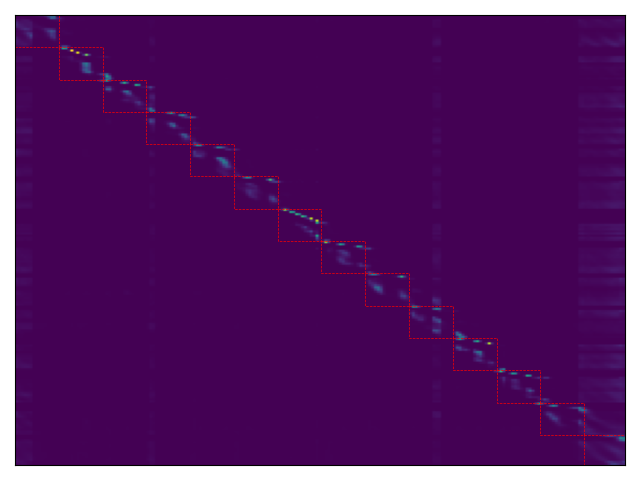 图1:分块对齐器架构示意图。
图1:分块对齐器架构示意图。
- 输入流程:输入语音特征序列被分割为N个固定长度Lc的块。例如,在流式设置中,块大小Lc=15(经4倍降采样后对应600ms延迟)。
- 编码器:采用Conformer块处理每个音频块,生成高级表示
Henc_n。为支持流式,使用了因果深度卷积。其核心创新在于“分块自转导”:编码器内的自注意力模块被训练为在每个块内部,将所有标签信息重新排列,对齐到该块最左侧的帧。这与原Aligner在整句上全局对齐不同,降低了学习难度。 - 预测器:一个LSTM网络,根据已生成的非空白标签自回归产生预测器输出
Hpred。这些输出也被相应地分割到各个块中。 - 连接器(Joiner):这是模型的关键决策点。对于每个块中的每个位置,连接器结合编码器和预测器的输出,通过一个共享的
tanh层生成联合表示hjoiner。然后分出两个分支:- 标签概率���支:使用
Softmax预测当前标签的概率ylabel_un。 - 块结束概率分支:使用
Sigmoid预测一个“块结束概率”yeoc_un,这取代了Transducer中的空白概率。当该概率超过阈值(如0.5)时,解码器将停止处理当前块,携带当前假设和状态进入下一个块。图1中展示了在第二个块中,即使没有预测出标签,只要yeoc超过阈值,模型也会前进到下一个块。
- 标签概率���支:使用
💡 核心创新点
- 分块自转导机制:这是对原Aligner全局自转导的改进。将对齐任务从“将所有标签对齐到整句最左侧”变为“将每个块内的标签对齐到该块最左侧”。之前局限:全局对齐对模型记忆长距离位置和重排信息的能力要求高,易导致在未见过的音频长度上泛化差,且不支持流式。如何起作用:局部对齐缩短了信息重排的距离,使编码器更易学习,提升了模型对不同长度音频的鲁棒性,并自然支持分块流式处理。收益:在LibriSpeech离线测试中,分块对齐器(WER 2.2%/5.0%)优于原Aligner(WER 2.4%/5.7%),且无需使用数据拼接技巧。
- 可学习的块结束概率:引入一个专门的分支来预测何时结束当前块的处理。之前局限:Transducer需要在整个
T×U网格上计算对齐;Aligner缺乏流式切换机制。如何起作用:该概率作为块间的“门控”,当模型认为当前块的相关信息已处理完毕时,触发切换。收益:实现了流式解码,且解码步长与标签长度U成比例,而非音频帧长T,显著减少了计算量。 - 统一的训练目标:将连接器输出优化为两个简单的损失之和:标签概率的交叉熵损失
Llabel和块结束概率的二元交叉熵损失Leoc。之前局限:Transducer训练需要动态规划计算全序列损失,计算密集。如何起作用:预测网格大小从T×U×(V+1)降至U×(V+1) + (U+N)×1,内存和计算量大幅减少。收益:训练速度更快,RTF显著优于Transducer(LibriSpeech上0.12 vs 0.30)。
🔬 细节详述
- 训练数据:
- LibriSpeech:使用标准数据增强(SpecAugment等)。
- CSJ:日语自发语音语料库。
- 对齐生成:使用Montreal Forced Aligner (MFA)。在训练分块对齐器时,也使用了从预训练CTC模型(带Inter-CTC损失)获得的对齐。
- 损失函数:
Ltotal = Llabel + Leoc。Llabel是标签序列的标准交叉熵损失;Leoc是针对每个块最后一个预测位置(以及可能存在的“无标签”情况)的二元交叉熵损失。 - 训练策略:
- 优化器:Adam。
- 学习率:峰值1.5e-3,有25k步的warmup。
- 训练轮数:100 epochs。
- 编码器初始化:使用CTC预训练的参数(包括Inter-CTC损失)。
- 关键超参数:
- 编码器:17层Conformer块(~110M参数)。嵌入层为2层2D CNN(256 filters,4倍降采样,核大小15,使用层归一化)。
- 预测器:640维LSTM。
- 块大小(Lc):离线和流式模式均固定为15帧。
- 流式编码器:当前和历史块大小均为15,深度卷积使用因果版本,算法延迟600ms。
- 解码阈值(τ):0.5。
- 词表大小:LibriSpeech为1000 (word-piece),CSJ为3262 (character)。
- 训练硬件:论文中未提及具体GPU/TPU型号和数量。
- 推理细节:
- 解码策略:基于分块的束搜索(Algorithm 1)。
- 束宽(Beam size):8。
- 流式设置:使用流式编码器,解码器按块进行。
- 实时因子(RTF)测试平台:Intel Xeon Gold 6430 3.4GHz CPU。
- 正则化或稳定训练技巧:使用了预训练编码器(CTC)进行初始化。在训练Aligner和AED基线时,使用了数据拼接(+DataConcat)以提升对长音频的鲁棒性,但分块对齐器未使用此技巧。
📊 实验结果
本文在LibriSpeech(英语)和CSJ(日语)上评估了离线与流式ASR性能,主要指标为词错误率(WER)或字符错误率(CER),以及实时因子(RTF)。
表1:LibriSpeech离线ASR结果(WER%和RTF)
| 模型/方法 | 对齐类型 | WER (clean) | WER (other) | RTF |
|---|---|---|---|---|
| Aligner (+DataConcat) | - | 2.3 | 5.1 | N/A |
| Transducer | - | 2.2 | 4.9 | 0.30 |
| CTC (预训练基线) | - | 2.7 | 6.7 | 0.09 |
| AED (+DataConcat) | - | 2.4 | 5.4 | 0.49 |
| Aligner (+DataConcat) | - | 2.4 | 5.7 | 0.18 |
| Chunkwise Aligner | ground-truth | 2.2 | 5.0 | 0.12 |
| Chunkwise Aligner | offline CTC | 2.2 | 5.0 | 0.12 |
结论:分块对齐器达到了与Transducer相当的WER(2.2%/5.0%),但RTF(0.12)远优于Transducer(0.30),解码速度快2.5倍。同时,其性能优于原Aligner(需数据拼接),且无需数据拼接技巧。使用CTC对齐与使用真实对齐性能一致。
 图2:(a)原Aligner与(b)分块对齐器在第16层编码器中的自注意力权重可视化。
结论:该图直观验证了架构创新。图(a)显示原Aligner将整句标签(34个token)全局对齐到句子开头。图(b)显示分块对齐器在每个块(红框标记)的边界处进行对齐,印证了其“分块自转导”机制,对齐距离更短、更局部。
图2:(a)原Aligner与(b)分块对齐器在第16层编码器中的自注意力权重可视化。
结论:该图直观验证了架构创新。图(a)显示原Aligner将整句标签(34个token)全局对齐到句子开头。图(b)显示分块对齐器在每个块(红框标记)的边界处进行对齐,印证了其“分块自转导”机制,对齐距离更短、更局部。
表2:LibriSpeech流式ASR结果(WER%)
| 模型/方法 | 对齐类型 | 延迟 | WER (clean) | WER (other) |
|---|---|---|---|---|
| Transducer | - | - | 3.1 | 7.6 |
| CTC | - | - | 4.1 | 10.8 |
| Chunkwise Aligner | ground-truth | 0ms | 3.9 | 9.5 |
| Chunkwise Aligner | ground-truth | 160ms | 3.5 | 8.5 |
| Chunkwise Aligner | ground-truth | 320ms | 3.2 | 7.9 |
| Chunkwise Aligner | ground-truth | 480ms | 3.4 | 8.3 |
| Chunkwise Aligner | streaming CTC | 0ms | 3.6 | 9.0 |
结论:在流式设置下,分块对齐器的性能与对齐延迟相关。使用真实对齐并设置320ms延迟时,WER(3.2%/7.9%)与流式Transducer(3.1%/7.6%)非常接近。值得注意的是,使用流式CTC对齐训练的模型,在0ms延迟下性能(3.6%/9.0%)优于使用带延迟的真实对齐(0ms),这可能与对齐质量有关。
表3:CSJ测试集CER%和RTF
| 模型/方法 | 离线 CER (E1/E2/E3) | 离线 RTF | 流式 CER (E1/E2/E3) |
|---|---|---|---|
| Transducer | 4.1 / 3.0 / 3.4 | 0.30 | 5.1 / 3.9 / 4.1 |
| CTC | 4.2 / 3.1 / 3.6 | 0.10 | 5.3 / 4.2 / 4.4 |
| AED | 3.9 / 2.9 / 3.4 | 0.55 | N/A |
| Aligner | 4.2 / 3.2 / 3.6 | 0.22 | N/A |
| Chunkwise Aligner | 4.0 / 2.9 / 3.4 | 0.16 | 5.1 / 3.9 / 4.1 |
结论:在CSJ日语数据集上,结果与LibriSpeech一致。分块对齐器在离线和流式场景下的CER均与Transducer持平,同时RTF(0.16)显著优于Transducer(0.30)。
⚖️ 评分理由
- 学术质量:6.5/7。创新点明确且有效,通过分块和EOC概率设计,成功赋予了Aligner流式能力,并提升了训练和解码效率。技术实现正确,实验全面,涵盖了不同语言、离线/流式设置,并进行了对齐类型的消融研究。论文清晰地展示了方法的优势(效率)和依赖(对齐质量)。扣分点在于,其性能基线(Transducer)并非不可逾越的SOTA,创新更多是架构效率优化而非识别准确率的突破。
- 选题价值:1.5/2。流式语音识别是核心工业应用需求。该方法在效率和准确性之间取得了出色平衡,RTF的显著降低具有很强的实用价值,对实时系统部署有直接吸引力。
- 开源与复现加成:-0.5/1。论文提供了相当详细的架构、训练配方(优化器、学习率、步数)和超参数信息,理论上可支持复现。然而,未提供代码、预训练模型或具体的配置文件,也未提及开源计划。复现者需要自行准备数据集、实现模型和寻找对齐工具,门槛较高。