📄 CASTELLA: Long Audio Dataset with Captions and Temporal Boundaries
#音频检索 #多模态模型 #预训练 #迁移学习 #数据集
🔥 8.5/10 | 前25% | #音频检索 | #迁移学习 | #多模态模型 #预训练
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Hokuto Munakata(LY Corporation)
- 通讯作者:未说明(论文中通讯作者符号*对应作者列表第二位Takehiro Imamura,但未明确其通讯作者身份)
- 作者列表:Hokuto Munakata(LY Corporation)、Takehiro Imamura(名古屋大学)、Taichi Nishimura(LY Corporation)、Tatsuya Komatsu(LY Corporation)
💡 毒舌点评
本文最大的贡献是为音频时刻检索任务“修桥铺路”,用一个规模空前(相比前作大24倍)且质量可控的真实世界数据集,终结了该任务依赖合成数据或极小测试集的尴尬历史,让后续研究得以立足于可靠地基之上。然而,它也清晰地揭示了一个残酷现实:即便有了优质数据,当前模型在检索短时刻(<10秒)时依然表现糟糕,这恐怕是未来比数据规模更难啃的骨头。
🔗 开源详情
- 代码:论文未直接提供代码仓库链接,但承诺“Upon paper acceptance, we will provide the recipe for this experiment”,并提及实验基于开源库
Lighthouse。因此,复现所需的训练脚本、配置文件等预计将在论文接收后开源。 - 模型权重:未提及公开预训练或微调后的模型权重。
- 数据集:是,CASTELLA数据集已公开。获取地址:
https://h-munakata.github.io/CASTELLA-demo/。 - Demo:是,提供了数据集的在线演示页面(同上链接)。
- 复现材料:提供了实验的超参数设置(优化器、学习率、批大小)、使用的特征提取器(MS-CLAP)、以及训练框架(Lighthouse)。
- 论文中引用的开源项目:
- 特征提取器:MS-CLAP [14] (
https://github.com/LAION-AI/CLAP) - 实验框架:Lighthouse [30] (
https://github.com/taichi-m108/lighthouse) - DETR网络:引用了QD-DETR [24], Moment-DETR [25], UVCOM [26] 的原始论文。
- 优化器:AdamW [29]。
- 特征提取器:MS-CLAP [14] (
📌 核心摘要
- 要解决什么问题:音频时刻检索(AMR)任务长期缺乏大规模、真实世界的人工标注基准数据集,导致现有模型性能评估不可靠,且训练严重依赖合成数据。
- 方法核心是什么:构建了CASTELLA数据集。它包含1862个1-5分钟的YouTube音频,每个音频配有全局摘要描述、多个局部关键事件描述及其精确的起止时间边界。同时,基于该数据集,采用预训练音频-文本模型(CLAP)结合检测Transformer(DETR)架构建立了基线模型。
- 与已有方法相比新在哪里:CASTELLA是首个满足AMR任务三大核心需求(长音频、自由格式描述、时间边界)的大规模真实世界数据集。其标注规模(约1.9k音频)是此前人工标注数据集(UnAV-100子集)的24倍以上。此外,论文首次系统验证了“在合成数据上预训练,再在真实数据集上微调”的两阶段训练策略的有效性。
- 主要实验结果如何:实验证明,使用CASTELLA进行微调能显著提升性能。仅在合成数据集(Clotho-Moment)上训练的模型Recall1@0.7为5.8;仅在CASTELLA上训练为9.7;而在合成数据预训练后于CASTELLA微调的模型达到16.2,提升10.4点。不同架构对比中,UVCOM模型表现最优(Recall1@0.7: 20.3)。实验还发现,模型对短时刻(<10秒)的检索能力明显较弱(见图3)。
| 索引 | DETR网络 | 训练数据 | R1@0.5 | R1@0.7 | mAP@0.5 | mAP@0.75 | mAP@avg. |
|---|---|---|---|---|---|---|---|
| 1 | QD-DETR | Clotho-Moment | 10.3 | 5.8 | 9.9 | 4.7 | 5.3 |
| 2 | - | CASTELLA | 19.8 | 9.7 | 17.6 | 5.9 | 7.7 |
| 3 | - | 两者 | 30.6 | 16.2 | 26.5 | 12.2 | 13.7 |
| 4 | Moment-DETR | 两者 | 19.3 | 10.8 | 17.2 | 7.0 | 8.2 |
| 5 | UVCOM | 两者 | 31.7 | 20.3 | 28.4 | 15.2 | 15.9 |
- 实际意义是什么:为音频理解领域,特别是音频时刻检索任务,提供了一个可靠的评估基准和训练资源,推动了该任务从合成数据走向真实应用。
- 主要局限性:1)数据集规模虽相对前作巨大,但对于深度学习而言仍属中等;2)音频均来自YouTube,可能存在领域偏差;3)短时刻检索仍是巨大挑战;4)论文未探索更先进的音频表示学习模型或更复杂的检索架构。
🏗️ 模型架构
论文中的基线模型基于 AM-DETR 架构,该架构受视频时刻检索(VMR)模型启发。
- 整体流程:输入为长音频波形
x和文本查询q。模型首先通过特征提取器获取音频和文本的特征表示,然后送入DETR网络,输出一组预测的音频时刻(开始、结束时间)及其置信度分数。 - 主要组件:
- 特征提取器:使用 MS-CLAP 模型。它接收预处理后的音频波形(下采样至32kHz)和文本,通过滑动窗口(窗口和步长均为1秒)提取音频特征,最终生成融合音频-文本的多模态特征序列。
- DETR网络:论文测试了三种源自VMR的DETR变体:
- QD-DETR:查询依赖的DETR,生成时刻预测。
- Moment-DETR:较早期的时刻检测模型。
- UVCOM:统一的视频理解框架,结合了时刻检索和高亮检测,架构和训练方法有改进。
- 数据流与交互:CLAP特征提取器为音频的每个时间步和文本查询生成一个联合嵌入向量。这些向量序列被输入DETR网络。DETR通过可学习的查询(Queries)与这些特征进行交叉注意力运算,从而定位相关的时间区间(即“音频时刻”)并预测其边界和置信度。最终通过置信度阈值和非极大值抑制(NMS)得到输出预测。
- 关键设计:采用DETR架构的核心动机在于其能够建模序列中不同时间帧之间的长程依赖关系,这对于从长音频中精确定位时刻至关重要。使用CLAP作为特征提取器则利用了其强大的音频-文本对齐能力。
💡 核心创新点
- 首个大规模真实世界AMR数据集:构建了CASTELLA,这是第一个完全满足AMR任务需求(长音频、自由描述、时间边界)的、经过人工标注的、大规模数据集。这直接解决了该领域“无米之炊”的核心瓶颈。
- 两阶段训练策略的验证:通过实验证明了“在合成数据集(Clotho-Moment)上预训练,然后在真实数据集(CASTELLA)上微调”是一种极其有效的训练策略,相比单一数据源训练性能大幅提升(Recall1@0.7提升10.4点)。这为资源有限的真实世界任务提供了有效的训练范式。
- 基线模型与多维分析:不仅提供了基线模型,还系统性地比较了不同DETR架构在AMR上的性能,并深入分析了模型在不同时长片段上的表现差异(如图3所示),指出了短时刻检索是当前的主要挑战。
🔬 细节详述
- 训练数据:
- 预训练数据集:Clotho-Moment [6],为合成数据集,通过将Clotho数据集中的短音频叠加到长背景噪声上生成。
- 微调/评估数据集:CASTELLA。数据来源于YouTube,继承自AudioCaps的音频子集,并过滤了时长不足1分钟或超过5分钟的音频。训练、验证、测试集划分明确,见Table 2。
- 损失函数:论文未明确说明损失函数具体公式,但提及训练目标是使预测时刻与真实时刻对齐,并正确预测置信度分数。这通常涉及边界回归损失(如L1损失)和分类/置信度损失。
- 训练策略:
- 优化器:AdamW,学习率
1 × 10⁻⁴。 - 批大小:32。
- 训练轮数:最多100轮,采用基于验证集的早停策略。
- 优化器:AdamW,学习率
- 关键超参数:DETR网络的超参数与原始论文一致,论文未逐一列出。音频特征提取使用滑动窗口(1秒)。
- 训练硬件:论文中未说明。
- 推理细节:论文未详细说明解码策略(如NMS的具体参数),仅提及使用置信度分数过滤输出。
- 正则化/稳定技巧:论文未提及除早停外的其他技巧。
📊 实验结果
主要实验在CASTELLA测试集上进行,评估指标为Recall1@θ 和 mAP@θ(θ=0.5, 0.7, 0.75等)。关键结果汇总于Table 3(已在核心摘要部分以表格形式完整呈现)。
- 训练策略对比:对比QD-DETR模型(索引1, 2, 3),证明合成数据预训练+CASTELLA微调(索引3)远优于仅在合成数据或仅在CASTELLA上训练。Recall1@0.7从5.8和9.7分别提升至16.2。
- 模型架构对比:在相同训练数据(合成+CASTELLA)下,对比不同DETR网络(索引3, 4, 5)。UVCOM(索引5)在各项指标上均最优(Recall1@0.7: 20.3),Moment-DETR(索引4)最差(10.8)。这与VMR任务的趋势一致。
- 细分性能分析(图3):图3显示了Recall1@0.5和@0.7随真实时刻最大时长变化的趋势。结果明确显示,对于短时刻(<10秒),模型性能显著下降。这揭示了AMR任务的一个关键挑战。
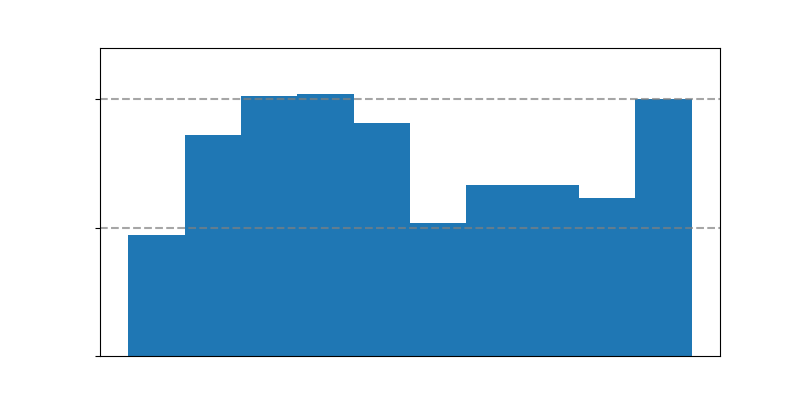 图3说明:横轴为真实音频时刻的最大时长(秒),纵轴为Recall1指标。左右子图分别为IoU阈值0.5和0.7下的结果。图中清晰可见,在0-10秒区间,模型的检索性能(条形高度)远低于更长时长的区间。
图3说明:横轴为真实音频时刻的最大时长(秒),纵轴为Recall1指标。左右子图分别为IoU阈值0.5和0.7下的结果。图中清晰可见,在0-10秒区间,模型的检索性能(条形高度)远低于更长时长的区间。
⚖️ 评分理由
- 学术质量:6.2/7:创新性体现在解决了一个基础但关键的“数据集缺失”问题,而非提出全新的算法。技术实现正确,实验设计合理,对比了不同训练策略和模型架构,并进行了有价值的细分分析。结论基于扎实的实验证据。
- 选题价值:1.5/2:AMR是音频理解中一个有明确应用场景的实用任务。本文工作直接为该任务的后续研究铺平道路,价值明确。但任务本身在音频领域不属于最前沿或最热门的方向。
- 开源与复现加成:0.8/1:提供了高质量数据集的直接下载链接,这是最大的加分项。实验依赖的开源模型(CLAP)和工具库(Lighthouse)均已指明,并承诺提供实验配置。未提供完整代码仓库,但现有信息已足以支撑大部分复现工作。