📄 CALM: Joint Contextual Acoustic-Linguistic Modeling for Personalization of Multi-Speaker ASR
#语音识别 #端到端 #多任务学习 #多语言 #跨模态
✅ 7.5/10 | 前25% | #语音识别 | #端到端 | #多任务学习 #多语言
学术质量 7.5/7 | 选题价值 1.8/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Muhammad Shakeel(Honda Research Institute Japan Co., Ltd.)
- 通讯作者:未说明
- 作者列表:Muhammad Shakeel(Honda Research Institute Japan Co., Ltd.), Yosuke Fukumoto(Honda Research Institute Japan Co., Ltd.), Chikara Maeda(Honda Research Institute Japan Co., Ltd.), Chyi-Jiunn Lin(Carnegie Mellon University), Shinji Watanabe(Carnegie Mellon University)
💡 毒舌点评
这篇论文的“胶水”艺术令人印象深刻,将成熟的语音编码器、说话人验证模型和动态词汇扩展技术流畅地整合进一个端到端框架,解决了多说话人ASR中一个长期存在但被割裂对待的问题,实验数据也足够扎实。然而,其主要战场仍是LibriSpeech这类“干净的混合”,在AMI这种真实、嘈杂且充满填充词的会议场景中性能出现明显波动,这暗示了该框架在面对真实世界的混乱时可能过于依赖精心构造的条件。
🔗 开源详情
- 代码:论文中提供代码仓库链接:
https://github.com/2026-icassp/calm。 - 模型权重:论文中未提及公开模型权重。
- 数据集:使用了公开数据集(LibriSpeechMix, CSJMix, AMI),论文中未提及新数据集。
- Demo:论文中未提及提供在线演示。
- 复现材料:提供了非常详细的复现信息,包括:
- 基于ESPnet工具包实现。
- 详细的模型架构参数(编码器/解码器层数、维度、注意力头数等)。
- 训练配置(优化器、学习率调度、warmup步数、批大小、损失权重)。
- 数据处理细节(特征提取、SpecAugment、偏置列表构建方法)。
- 不同数据集的训练轮数。
- 超参数搜索过程(如偏置权重
µ)。
- 论文中引用的开源项目:
- ESPnet (语音处理工具包)
- WavLM-Large (自监督语音模型)
- ECAPA-TDNN (说话人验证模型)
- Conformer (音频编码器)
- Transformer (上下文偏置编码器、解码器)
- DYNAC (动态词汇方法)
📌 核心摘要
- 解决的问题:在多说话人重叠语音场景下,现有多说话人ASR系统面临声学干扰(非目标说话人干扰)和语言适应性差(领域特定词汇、罕见词)的双重挑战,且现有方法大多未能有效联合解决这两类问题。
- 方法核心:提出CALM框架,一个联合声学与语言建模的端到端系统。其核心是通过说话人嵌入驱动的说话人提取(解决声学干扰)与基于动态词汇的上下文偏置(解决语言适应性)的紧密集成。
- 与已有方法的比较新意:突破了以往将目标说话人ASR(仅处理声学)和上下文偏置(仅处理语言)分开处理的局限。CALM在统一的Conformer编码器架构内,利用FiLM调制注入说话人信息,同时扩展输出层以包含静态词汇和动态偏置词汇,并通过中间层CTC损失(InterCTC)和VAD辅助损失进行联合训练,实现了声学与语言信息的深度耦合。
- 主要实验结果:在英语LibriSpeech2Mix上,CALM将偏置词错误率(B-WER)从基线12.7大幅降低至4.7(绝对降低8.0);在日语CSJMix2上,偏置字符错误率(B-CER)从16.6降至8.4。在标准化会议数据AMI上,也有效降低了B-WER(从34.7降至22.1)。关键结果对比如下表所示:
方法 (ID) 数据集 指标 基线值 CALM (A4)值 改进 (绝对) A2 vs A4 LibriSpeech2Mix (N=2000) B-WER 12.7 4.7 -8.0 A2 vs A4 LibriSpeech3Mix (N=3000) B-WER 17.0 8.3 -8.7 D1 vs D2 CSJMix2 eval1 (N=100) B-CER 16.2 8.3 -7.9 E3 vs E4 AMI-IHM-Mix (N=1000) B-WER 34.7 22.1 -12.6 - 实际意义:为个性化多说话人语音转写(如会议记录、小组讨论)提供了一种有效、可扩展的端到端解决方案,能同时提升对重叠语音和特定领域词汇的识别准确率。
- 主要局限性:主要验证基于模拟的混合语音(LibriSpeechMix, CSJMix),在更复杂、更嘈杂的真实会议场景(如AMI)中,整体WER有所上升,表明框架对真实环境中的插话、填充词和复杂说话人变化的鲁棒性仍有提升空间。
🏗️ 模型架构
CALM是一个端到端的多任务学习框架,旨在联合处理目标说话人提取和上下文偏置。
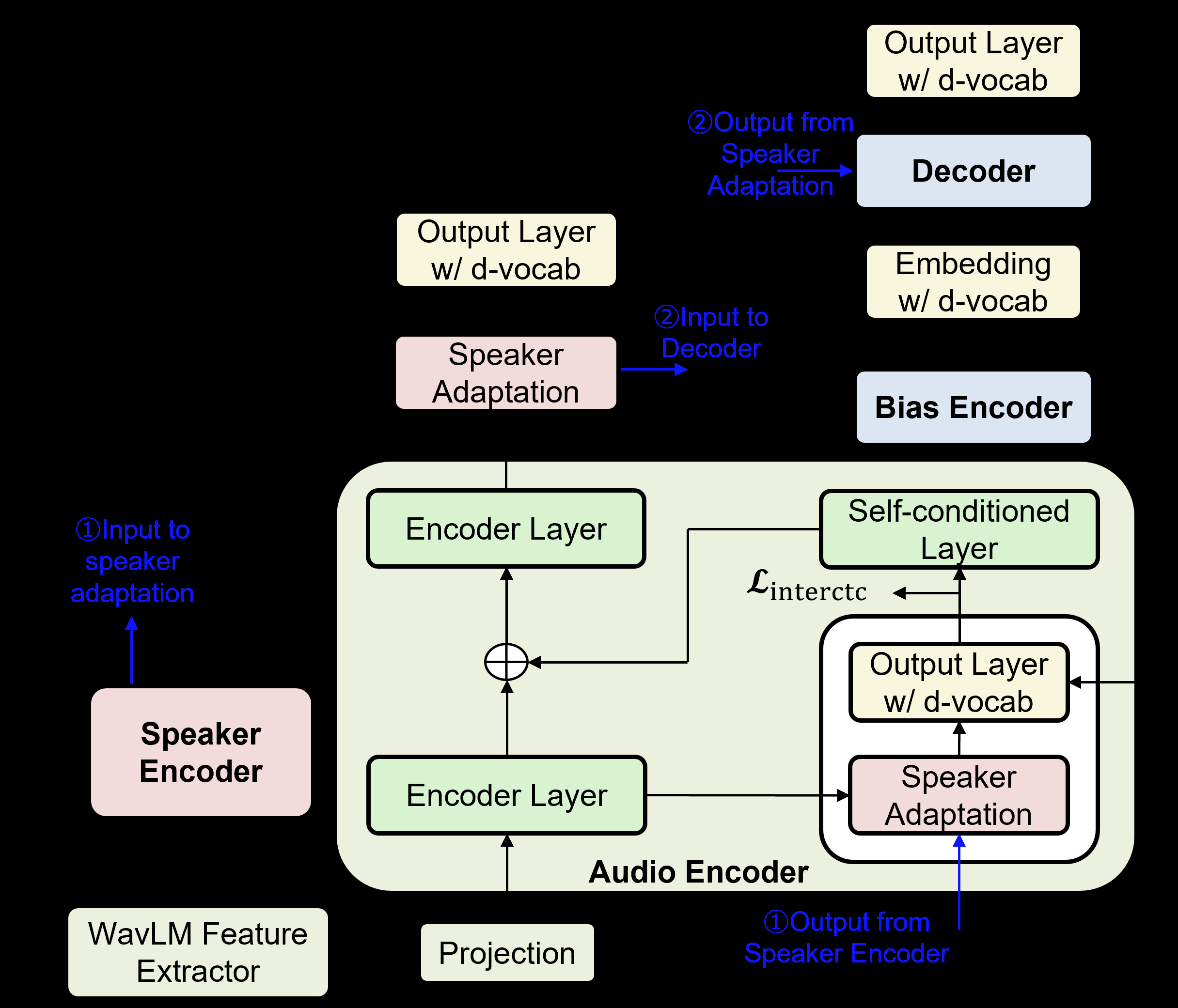 图1: CALM框架示意图
图1: CALM框架示意图
输入与特征提取:
- 输入:多说话人混合音频信号
X。 - 上游模型:使用冻结的
WavLM-Large作为预训练语音编码器,提取帧级特征Xfe。 - 投影:通过线性层将特征投影到编码器空间
Zfe。
- 输入:多说话人混合音频信号
说话人嵌入提取(声学条件化):
- 说话人编码器:使用
ECAPA-TDNN(含注意力池化)和RawNet3投影器,从目标说话人的注册语料Cs中提取说话人嵌入Es。 - 条件化机制:将说话人嵌入
Es作为条件,通过FiLM(Feature-wise Linear Modulation)调制作用于Conformer音频编码器中间层和最终层的隐藏表示H(l),得到适应后的表示ˆH(l)。这实现了基于说话人身份对声学特征的自适应调整。
- 说话人编码器:使用
音频编码与动态词汇偏置(语言适应):
- 音频编码器:采用12层
Conformer编码器,处理特征Zfe,其隐藏状态H(l)被FiLM调制后得到ˆH(l)。 - 上下文偏置编码器:一个6层的
Transformer编码器,负责将偏置短语列表B编码成语义向量V。每个短语被视为一个整体“动态令牌”。 - 动态词汇扩展:在编码器的中间层和最终层,输出层被扩展。线性层分别计算静态词汇表
Vstat的对数分数Ostat(l)和动态词汇Vd-vocab(由偏置短语构成)的对数分数Od-vocab(l)。两者通过拼接后进入带权重的Softmax,得到最终输出分布O(l)。这使得模型在编码过程中就能逐步利用词汇上下文信息。
- 音频编码器:采用12层
损失函数与训练:
- 模型采用多任务联合训练,损失函数包括:
- CTC损失 (
Lctc):在编码器最终层(L(L)_ctc)和选定的中间层(Linterctc, 本实验在第3、6、9层)计算,用于连接时序分类。 - 注意力解码器损失 (
Latt):用于自回归解码,基于动态词汇扩展。 - VAD损失 (
Lvad):通过附加在最终编码器状态ˆH(L)上的VAD头,预测目标说话人的活动概率,并与真实标签计算二元交叉熵损失。
- CTC损失 (
- 总损失
Ltotal是这些损失的加权和,并应用了CTC自条件(将中间层CTC后验反馈回编码器输入)以增强动态词汇信息的传播。
- 模型采用多任务联合训练,损失函数包括:
输出:最终通过CTC或注意力解码器得到目标说话人的转录文本,该文本利用了声学上的说话人区分能力和语言上的上下文词汇偏置。
💡 核心创新点
统一的声学-语言联合建模框架:
- 局限性:先前工作通常将目标说话人提取(解决重叠干扰)和上下文偏置(解决词汇适应性)作为独立模块处理,或仅在解码阶段浅层融合,未能在编码层面深度集成。
- 创新:CALM在一个端到端编码器中,通过
FiLM进行说话人条件化,同时通过动态词汇扩展和中间层CTC损失将上下文信息注入编码过程,使两种信息流相互作用。 - 收益:在重叠语音中,说话人信息能引导模型关注正确的语音流,同时动态词汇信息能即时修正识别结果,实现了“听其声,知其言”的协同效应,显著提升了偏置词的识别率(B-WER/B-CER大幅下降)。
动态词汇的中间层集成与自条件CTC:
- 局限性:传统的上下文偏置方法多在解码器或编码器最后一层注入信息,可能随着网络加深而遗忘,或导致动态词汇过偏置。
- 创新:借鉴DYNAC方法,在编码器多个中间层就扩展输出词汇表,并计算中间层CTC损失。同时,利用CTC自条件将后验概率反馈,使上下文信息贯穿整个编码过程。
- 收益:实验表明,这有效防止了过偏置,在偏置列表增大时,不仅
B-WER降低,U-WER(非偏置词)也保持稳定或改善,证明了模型对整体词汇表的均衡处理能力。
说话人感知的上下文偏置与VAD正则化:
- 局限性:在多说话人对话中,偏置词可能来自任何说话人,无差别偏置可能引入干扰。
- 创新:将说话人嵌入通过
FiLM调制到编码器,使得编码器输出和动态词汇层的交互具有了说话人感知能力,可能隐式地使偏置更针对当前说话人。同时,辅助的VAD损失增强了模型对目标说话人语音活动的时序定位。 - 收益:在实验中,联合VAD损失的版本(A4)在大多数设置下性能更优且更稳定,尤其是在列表较大时,验证了其对齐时序和声学上下文的作用。
🔬 细节详述
- 训练数据:
- 英语:LibriSpeechMix(约960小时),基于LibriSpeech训练集混合WHAM!噪声生成两/三说话人重叠语音。
- 日语:CSJMix(约581小时),对CSJ语料库应用相同混合流程生成。
- 验证/标准化:AMI会议语料(IHM-Mix条件,79.4小时,4-5说话人)。
- 数据增强:所有语料使用
SpecAugment。 - 说话人注册:LibriSpeechMix/CSJMix使用5秒注册语音;AMI使用15秒注册语音(来自同一会议ID)。
- 损失函数:
Lctc(CTC损失):权重λctc = 0.3。内部包含λinterctc = 0.5用于加权中间层CTC损失。Lvad(VAD损失):权重λvad = 0.15。Latt(注意力损失):权重为1 - λctc - λvad = 0.55。- 所有损失均为负对数似然或二元交叉熵。
- 训练策略:
- 优化器:Adam。
- 学习率:最大学习率
2e-3,带warmup。 - 训练轮数/步数:LibriSpeechMix 70 epochs;CSJMix 50 epochs;AMI 30 epochs。
- 批大小:以bin为单位,LibriSpeechMix 36M,CSJMix/AMI 40M。
- 偏置列表构建:训练时,每个batch随机生成包含50~200个短语的偏置列表
B。
- 关键超参数:
- 音频编码器:12层Conformer,4头,1024线性单元,卷积核31。
- 偏置编码器:6层Transformer,4头,1024单元。
- 说话人编码器:ECAPA-TDNN (scale 8),输出维度1536,经RawNet3投影至192维。
- 静态词汇表大小:
M = 5000。 - 推理偏置权重:
µ = 0.1(通过网格搜索确定,平衡偏置词和非偏置词识别)。
- 训练硬件:论文中未说明。
- 推理细节:
- 使用加权Softmax,权重
µ控制动态词汇的概率贡献。 - 解码器为6层Transformer(4头,2048单元)。
- 未提及具体解码策略(如beam search大小)。
- 使用加权Softmax,权重
📊 实验结果
表1: LibriSpeechMix数据集上的WER (U-WER/B-WER) 结果
| ID | 方法 | 数据集 | 偏置列表大小 (N) | N=0 | N=100×2 | N=500×2 | N=1000×2 |
|---|---|---|---|---|---|---|---|
| A1 | TS-ASR w/ (SC-CTC/ATTN) | LibriSpeech2Mix | - | 4.6 (3.6/12.9) | 4.6 (3.6/12.9) | 4.6 (3.6/12.9) | 4.6 (3.6/12.9) |
| A2 | A1 w/ VAD loss | LibriSpeech2Mix | - | 4.3 (3.3/12.7) | 4.3 (3.3/12.7) | 4.3 (3.3/12.7) | 4.3 (3.3/12.7) |
| A3 | A1 w/ dynamic vocab. | LibriSpeech2Mix | - | 5.3 (4.1/14.3) | 3.9 (3.8/4.3) | 4.0 (4.0/4.4) | 4.2 (4.1/4.7) |
| A4 | A3 w/ VAD loss (CALM) | LibriSpeech2Mix | - | 4.9 (3.7/14.7) | 3.6 (3.5/4.1) | 3.7 (3.7/4.1) | 4.1 (4.0/4.9) |
关键结论:CALM(A4)在存在偏置列表时,显著降低了B-WER(从12.7降至4.7),同时WER和U-WER也得到改善,表明其有效整合了声学和语言信息。
表2: LibriSpeechMix上不同偏置权重 (µ) 的影响 (WER (U-WER/B-WER))
| ID | µ | LibriSpeech2Mix (N=2000) | LibriSpeech3Mix (N=3000) |
|---|---|---|---|
| B1 (基线) | - | 4.3 (3.3/12.7) | 9.2 (8.3/17.0) |
| B2 | 1.0 | 6.6 (6.9/4.1) | 14.4 (15.2/8.2) |
| B6 (CALM) | 0.1 | 4.1 (4.0/4.9) | 9.1 (9.3/8.3) |
关键结论:推理时的偏置权重µ需要权衡。µ=0.1在整体WER和B-WER之间取得了最佳平衡。
表3: LibriSpeechMix评估集上的WER对比
| ID | 方法 | LibriSpeech2Mix | LibriSpeech3Mix |
|---|---|---|---|
| C3 | CONF-TSASR (ED=7.5s) | 6.30 | 9.00 |
| C5 | A2 (基线, ED=5s) | 4.28 | 9.21 |
| C7 | A4 (CALM, ED=5s) | 3.56 | 8.35 |
关键结论:CALM在标准WER指标上超越了包括SOTA目标说话人ASR在内的所有基线。
表4: AMI-IHM-Mix真实会议数据集上的结果 (WER (U-WER/B-WER))
| ID | 方法 | N=0 | N=100 | N=500 | N=1000 |
|---|---|---|---|---|---|
| E3 (基线) | A2 (ED=15s) | 37.4 (37.7/34.7) | - | - | 37.4 (37.7/34.7) |
| E4 (CALM) | A4 (ED=15s) | 42.3 (43.2/33.4) | 40.3 (42.0/22.5) | 39.2 (40.9/22.0) | 39.1 (40.7/22.1) |
关键结论:在真实会议场景中,CALM大幅降低了B-WER(如N=1000时,从34.7降至22.1),但总体WER有所上升(从37.4升至39.1)。论文分析这主要由插入错误增加导致,特别是在短片段和存在填充词的场景中。
表5: CSJMix日语数据集上的CER (U-CER/B-CER) 结果(部分关键数据)
| ID | 方法 | 评估集 | N=100 | N=1000 |
|---|---|---|---|---|
| D1 (基线) | A2 | eval1 | 8.2 (7.2/16.2) | 8.2 (7.2/16.2) |
| D2 (CALM) | A4 | eval1 | 7.1 (6.9/8.3) | 7.5 (7.3/8.6) |
| D5 (基线) | A2 | eval3 | 8.2 (7.1/16.6) | 8.2 (7.1/16.6) |
| D6 (CALM) | A4 | eval3 | 6.9 (6.8/7.7) | 7.4 (7.3/8.4) |
关键结论:CALM在日语字符级识别上同样有效,尤其在偏置列表存在时(N=100),B-CER从16.6降至7.7,证明了其跨语言的有效性。
⚖️ 评分理由
- 学术质量:7.5/7:论文提出了一个清晰、完整且有说服力的联合建模框架。创新点(如中间层动态词汇扩展、说话人FiLM调制)技术上合理,并有充分的实验验证(包括消融研究和多个数据集)。实验结果,尤其是在模拟混合语音上的改进,数据可信且显著。扣分点在于对真实复杂场景(如AMI)的分析和改进略显不足,未能完全解决其暴露出的问题。
- 选题价值:1.8/2:多说话人个性化ASR是语音技术走向实用化的关键瓶颈,研究此问题具有很高的前沿性和实际应用价值。论文选题精准,直击现有方法割裂处理的痛点。
- 开源与复现加成:0.8/1:论文提供了代码仓库链接,并详细说明了基于ESPnet的实现、模型配置、训练策略和超参数,为复现提供了良好基础。扣分点在于未提供预训练模型权重,且对推理时的解码细节(如beam size)描述不够详尽。