📄 Bridging the Semantic Gap: Cross-Attentive Fusion for Joint Acoustic-Semantic Speech Quality Assessment
#语音质量评估 #对比学习 #预训练 #交叉注意力 #跨域泛化
🔥 8.5/10 | 前25% | #语音质量评估 | #对比学习 | #预训练 #交叉注意力
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zhaoyang Wang(中国科学院声学研究所)
- 通讯作者:论文中未明确标注。
- 作者列表:Zhaoyang Wang(中国科学院声学研究所;中国科学院大学), Chengzhong Wang(中国科学院声学研究所;中国科学院大学), Jiale Zhao(中国科学院声学研究所;中国科学院大学), Dingding Yao(中国科学院声学研究所;中国科学院大学), Jing Wang(北京理工大学), Junfeng Li(中国科学院声学研究所;中国科学院大学)。
💡 毒舌点评
亮点:论文概念清晰,直指“语义鸿沟”这一现有SQA模型的痛点,并通过设计合理的双分支架构和两阶段训练策略进行解决,实验对比充分,结论有说服力。 短板:其核心创新——利用预训练的Whisper和DAC模型通过双向交叉注意力融合——在方法层面更像是一个工程化设计,缺乏理论上的新颖性或对融合机制本身的深入探究。同时,对比方法虽然包括了主流基线,但未能涵盖所有最新的顶尖模型。
🔗 开源详情
- 代码:提供了GitHub仓库链接:https://github.com/kalenon/JASSQA
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文中使用的NISQA, VoiceMOS Challenge 2023, Tencent, BVCC等数据集均为公开或比赛提供的数据集,但论文未说明其JASSQA模型是否提供了特定的数据预处理脚本或合并后的数据集。
- Demo:论文中未提及在线演示。
- 复现材料:论文给出了主要超参数(学习率、批量大小、优化器、早停轮数)和两阶段训练策略的描述。模型架构图(图1)也提供了必要的设计细节。但未提供具体的代码注释、配置文件、检查点或更详尽的附录说明。
- 论文中引用的开源项目:论文依赖以下开源模型/工具:Descript Audio Codec (DAC) [14], Whisper [9]。
- 总结:论文代码开源,这是复现的重要基础。但完整的端到端复现可能需要研究者自行准备数据集并下载预训练的DAC和Whisper模型,并按照论文描述的策略进行训练。
📌 核心摘要
- 问题:现有非侵入式语音质量评估(SQA)模型过度依赖语义预训练模型(如Wav2Vec, Whisper),这些模型在训练时追求对声学变异(如噪声、通道效应)的不变性,却忽略了人类感知质量所依赖的精细声学线索,导致“语义鸿沟”,影响模型在多样化场景下的泛化能力。
- 方法核心:提出JASSQA模型,采用双分支架构。声学分支利用Descript Audio Codec (DAC) 提取离散声学token并通过双路径(直接映射+编码器)生成特征;语义分支利用Whisper提取语言特征。核心融合机制为双向跨注意力,允许两个分支的特征相互查询与增强,随后拼接并通过MLP预测MOS分数。
- 创新点:与已有简单拼接特征的方法(如MOSA-Net+)相比,JASSQA通过双向跨注意力实现了声学与语义表征的深度交互式融合;提出两阶段训练策略,第一阶段使用对比回归损失预训练声学编码器以构建感知有序的表征空间,第二阶段冻结部分组件进行端到端微调。
- 主要结果:在NISQA和VoiceMOS Challenge 2023(Track 3)数据集上,JASSQA在SRCC、LCC和MSE三项指标上均优于MOS-SSL, UTMOS, MOSA-Net及MOSA-Net+等基线。例如,在NISQA上,JASSQAlarge的SRCC达到0.904, LCC达到0.907。在跨域泛化测试(腾讯会议数据、BVCC语音转换数据)中,JASSQA同样表现出显著的性能优势。
- 实际意义:该工作为构建更鲁棒、泛化能力更强的自动化语音质量评估系统提供了一种有效框架,可应用于语音合成、语音增强、在线会议等系统的质量监控与优化。
- 主要局限性:模型架构是现有组件(Whisper, DAC, 交叉注意力)的组合,缺乏机制层面的根本创新。消融实验显示,仅使用声学分支性能下降明显,表明模型对强大的语义预训练特征仍有较强依赖。
🏗️ 模型架构
JASSQA的整体架构(如图1所示)分为并行特征提取、双向跨注意力融合和分数预测三个核心模块。
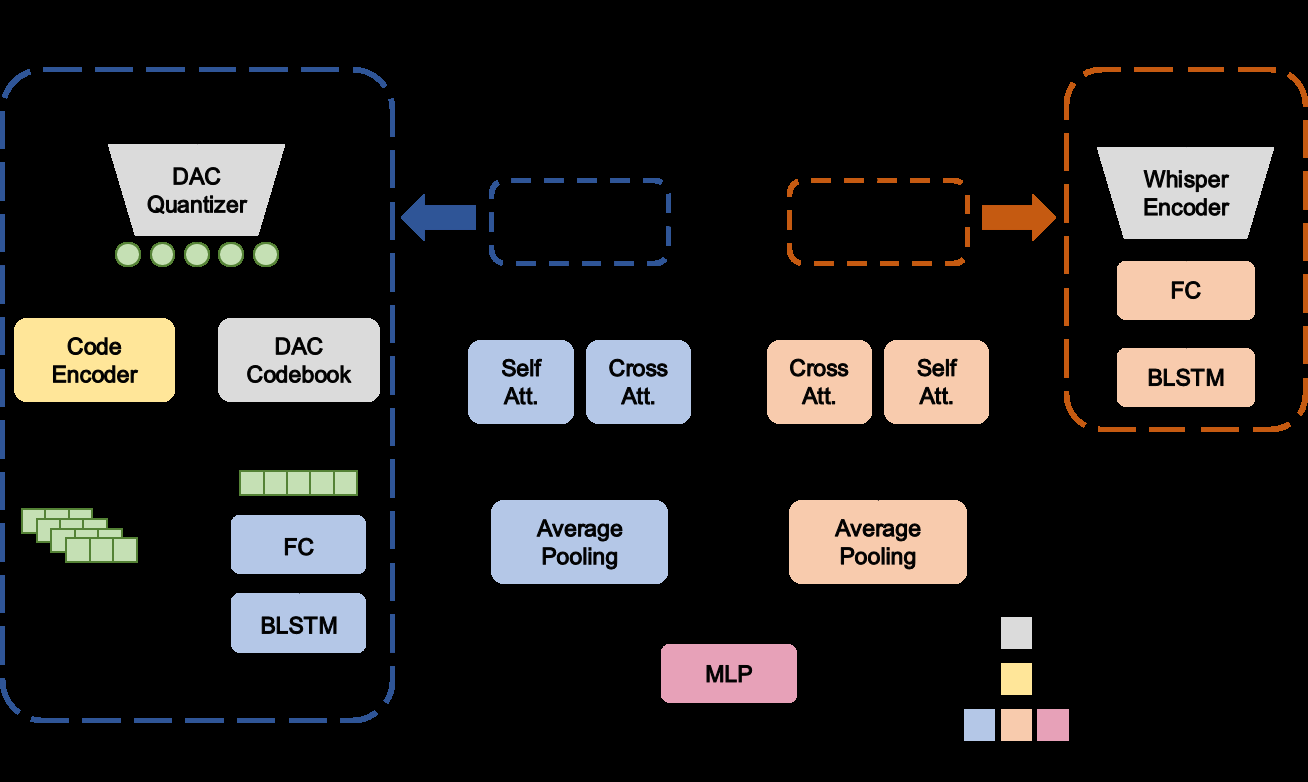 图1:JASSQA模型架构。左侧为并行的双分支结构:上方是语义分支(Semantic Branch),处理由Whisper编码器输出的特征;下方是声学分支(Acoustic Branch),处理由DAC量化器输出的离散声学token。声学分支内部包含两条路径:一条是直接的码本查找(Direct Codebook Lookup),另一条是包含嵌入层和两层Transformer的编码器(Dedicated Code Encoder)。两条路径的输出拼接后通过一个全连接层(FC)和BiLSTM。两个分支的输出进入中间的“双向跨注意力融合(Bidirectional Cross-Attention Fusion)”模块,该模块由两个多头注意力层组成,分别以声学特征为查询、语义特征为键/值,和以语义特征为查询、声学特征为键/值。融合后的特征经过平均池化(Average Pooling)得到句级表示,再拼接后输入最终的多层感知机(MLP)进行MOS分数回归。
图1:JASSQA模型架构。左侧为并行的双分支结构:上方是语义分支(Semantic Branch),处理由Whisper编码器输出的特征;下方是声学分支(Acoustic Branch),处理由DAC量化器输出的离散声学token。声学分支内部包含两条路径:一条是直接的码本查找(Direct Codebook Lookup),另一条是包含嵌入层和两层Transformer的编码器(Dedicated Code Encoder)。两条路径的输出拼接后通过一个全连接层(FC)和BiLSTM。两个分支的输出进入中间的“双向跨注意力融合(Bidirectional Cross-Attention Fusion)”模块,该模块由两个多头注意力层组成,分别以声学特征为查询、语义特征为键/值,和以语义特征为查询、声学特征为键/值。融合后的特征经过平均池化(Average Pooling)得到句级表示,再拼接后输入最终的多层感知机(MLP)进行MOS分数回归。
组件详解:
- 声学分支:
- 输入:44.1kHz的语音波形。
- 离散化:通过预训练的DAC模型中的残差向量量化(RVQ)器,将语音波形转换为多层级的离散声学token序列,以捕捉不同粒度的信号细节。
- 双路径处理:
- 直接码本查找路径:将每个token映射到其对应的低维嵌入向量。
- 专用编码器路径:包含一个嵌入层和一个两层Transformer编码器,用于生成token的上下文感知表示。
- 特征融合与建模:将上述两条路径的向量序列在特征维度上拼接,通过一个全连接层进行维度对齐,然后输入双向LSTM(BiLSTM)以建模长程时序依赖。
- 语义分支:
- 输入:16kHz的语音波形。
- 特征提取:直接使用预训练Whisper(Medium或Large-v3���编码器的最终隐藏状态作为特征。
- 处理:通过一个全连接层和一个BiLSTM(结构与声学分支对称)处理,提取语言内容的高层表示。
- 双向跨注意力融合:
- 这是框架的核心交互模块。它使用两个独立的多头注意力层:
- 第一层:查询(Q)来自声学特征序列,键(K)和值(V)来自语义特征序列。这让声学特征能够“关注”并吸收与之相关的语义上下文。
- 第二层:查询(Q)来自语义特征序列,键(K)和值(V)来自声学特征序列。这允许语义特征反过来“参考”声学特征来增强自身。
- 每个注意力层的输出会与对应分支的原始自注意力序列输出(或原始特征,文中表述为“self-attention sequence”,可能指分支内BiLSTM后的特征)进行拼接,形成增强后的表示。这确保了交互后的特征既包含了对方的信息,又保留了自身的原始信息。
- 这是框架的核心交互模块。它使用两个独立的多头注意力层:
- 预测头:
- 对增强后的声学和语义特征分别进行平均池化,得到两个句级向量。
- 将这两个向量拼接,输入一个最终的MLP,回归出预测的MOS分数。
💡 核心创新点
- 明确“语义鸿沟”概念与双分支架构设计:
- 是什么:论文明确定义了现有SQA模型因依赖语义预训练模型而产生的“语义鸿沟”问题,并设计了并行的声学(基于DAC)和语义(基于Whisper)特征提取分支。
- 局限:之前工作要么仅依赖单一语义特征(如MOS-SSL),要么虽结合了声学与语义特征但融合方式简单(如拼接)。
- 如何起作用:双分支结构显式地将影响语音质量的两大类信息(声学保真度、内容清晰度)进行分离建模,为针对性提取相关特征提供了架构基础。
- 收益:实验表明,移除任何一个分支都会导致性能显著下降,验证了双分支互补建模的必要性。
- 双向跨注意力融合机制:
- 是什么:取代简单的特征拼接,使用双向的跨注意力层,使声学和语义表征能够动态地、相互地增强对方。
- 局限:之前的特征融合(如拼接)是静态的,无法根据输入内容自适应地调整两类特征的交互权重。
- 如何起作用:通过注意力机制,模型可以学习在预测质量时,哪些声学片段与哪些语义内容最相关,从而进行深度信息交换。
- 收益:消融实验显示,移除跨注意力机制后,模型在跨域数据集(如VoiceMOS)上的性能,尤其是MSE指标,出现显著恶化,证明了该融合策略的有效性。
- 两阶段训练策略(对比回归预训练+监督微调):
- 是什么:第一阶段使用对比回归(CR)损失预训练声学分支的专用编码器,第二阶段冻结预训练部分,优化整体模型。
- 局限:直接端到端训练可能无法让声学编码器很好地学习与感知质量相关的排序关系。
- 如何起作用:CR损失通过三元组样本,强制编码器学习的嵌入空间距离与MOS分数差异成正比,构建了一个感知有序的表征空间。
- 收益:消融实验表明,移除第一阶段训练会导致模型性能(如NISQA上的MSE)轻微但确定的下降。
🔬 细节详述
- 训练数据:
- 域内训练集:NISQA Corpus的TRAIN_SIM分区(约14,000条,涵盖英文、德文,模拟/真实失真);VoiceMOS Challenge 2023 Track 3训练集(8,201条台湾普通话,含噪声和增强语音)。
- 评估数据集:域内测试集(NISQA的三个测试子集,VoiceMOS 2023测试集);跨域测试集(Tencent Corpus:8,366条中文会议语音;BVCC Corpus:1,066条语音转换测试样本)。
- 损失函数:
- 第一阶段:对比回归损失 (L_CR)。该损失函数基于三元组构建,目标是最小化锚样本与正样本(MOS接近)的嵌入距离,同时最大化与负样本(MOS差距大)的嵌入距离。自适应margin m被设置为归一化的MOS距离差。
- 第二阶段:标准L2损失(均方误差,MSE),用于回归预测MOS与真实MOS。
- 训练策略:
- 第一阶段:优化器AdamW,学习率1e-3,批量大小128,线性衰减调度。最大训练1000轮,若验证集损失连续20轮未改善则提前停止。
- 第二阶段:冻结DAC、Whisper编码器和第一阶段预训练好的声学嵌入模块。优化器AdamW,学习率1e-4,批量大小1。
- 关键超参数:
- 模型变体:JASSQAmedium(使用Whisper-medium), JASSQAlarge(使用Whisper-large-v3)。
- 输入采样率:声学分支44.1kHz,语义分支16kHz。
- 融合模块:具体多头注意力的头数、隐藏维度等未在正文中说明。
- 训练硬件:论文中未提及。
- 推理细节:论文中未提及解码策略、温度等,因为这是一个回归模型,输入语音即输出分数。
- 正则化或稳定训练技巧:未明确说明除提前停止外的其他技巧。
📊 实验结果
主要对比实验结果(表1 & 表2):
表1:在NISQA和VoiceMOS Challenge 2023 (Track 3) 上的性能对比
| 模型 | NISQA SRCC↑ | NISQA LCC↑ | NISQA MSE↓ | VMC 2023 SRCC↑ | VMC 2023 LCC↑ | VMC 2023 MSE↓ |
|---|---|---|---|---|---|---|
| MOS-SSL | 0.824 | 0.816 | 0.552 | 0.403 | 0.518 | 3.356 |
| UTMOS | 0.751 | 0.746 | 0.706 | 0.477 | 0.611 | 2.216 |
| MOSA-Net | 0.760 | 0.762 | 0.512 | 0.749 | 0.781 | 0.358 |
| MOSA-Net+ | 0.886 | 0.885 | 0.217 | 0.780 | 0.803 | 0.343 |
| JASSQAmedium | 0.888 | 0.897 | 0.184 | 0.792 | 0.815 | 0.302 |
| JASSQAlarge | 0.904 | 0.907 | 0.201 | 0.801 | 0.823 | 0.299 |
| 关键结论:JASSQA的两个变体在所有指标上均超过所有基线。在NISQA上,JASSQAlarge的LCC(0.907)相比最强基线MOSA-Net+(0.885)有显著提升,MSE(0.201)也最低。在VMC 2023上,JASSQAlarge的MSE(0.299)优于MOSA-Net+(0.343)。 |
表2:在Tencent和BVCC跨域语料上的泛化性能(所有模型均在NISQA上训练)
| 模型 | Tencent SRCC↑ | Tencent LCC↑ | Tencent MSE↓ | BVCC SRCC↑ | BVCC LCC↑ | BVCC MSE↓ |
|---|---|---|---|---|---|---|
| MOS-SSL | 0.721 | 0.715 | 0.747 | 0.685 | 0.685 | 1.316 |
| UTMOS | 0.824 | 0.822 | 0.627 | 0.582 | 0.544 | 2.379 |
| MOSA-Net | 0.855 | 0.843 | 1.461 | 0.705 | 0.658 | 0.862 |
| MOSA-Net+ | 0.868 | 0.834 | 1.498 | 0.701 | 0.630 | 0.979 |
| JASSQAmedium | 0.904 | 0.912 | 0.427 | 0.717 | 0.695 | 0.805 |
| JASSQAlarge | 0.910 | 0.916 | 0.451 | 0.717 | 0.718 | 0.724 |
| 关键结论:JASSQA在从未见过的Tencent和BVCC数据上表现出显著的泛化优势。尤其在Tencent数据上,其LCC(0.916)远高于MOSA-Net+(0.834),MSE(0.451)也大幅降低。这表明其融合的特征能更好地适应多样化的失真类型。 |
消融实验结果(表3):
表3:在NISQA和VMC 2023上的消融研究(基于JASSQAlarge)
| 配置 | NISQA SRCC↑ | NISQA LCC↑ | NISQA MSE↓ | VMC 2023 SRCC↑ | VMC 2023 LCC↑ | VMC 2023 MSE↓ |
|---|---|---|---|---|---|---|
| JASSQAlarge (完整) | 0.904 | 0.907 | 0.201 | 0.801 | 0.823 | 0.299 |
| w/o 训练阶段1 | 0.899 | 0.904 | 0.239 | 0.795 | 0.814 | 0.310 |
| w/o 跨注意力 | 0.889 | 0.896 | 0.260 | 0.797 | 0.810 | 0.485 |
| w/o 声学分支 | 0.886 | 0.892 | 0.251 | 0.752 | 0.768 | 0.449 |
| w/o 语义分支 | 0.558 | 0.571 | 0.749 | 0.466 | 0.495 | 1.019 |
| 关键结论:1) 移除第一阶段预训练(w/o training stage 1)导致MSE普遍上升。2) 移除跨注意力(w/o cross attention)在跨域数据(VMC 2023)上导致MSE从0.299急剧上升到0.485,影响巨大。3) 移除语义分支(w/o semantic branch)导致所有指标灾难性下降,表明Whisper的语义特征是模型性能的基石。4) 移除声学分支(w/o acoustic branch)导致性能中等程度下降,验证了声学特征的补充作用。 |
双分支表征分析(图2):
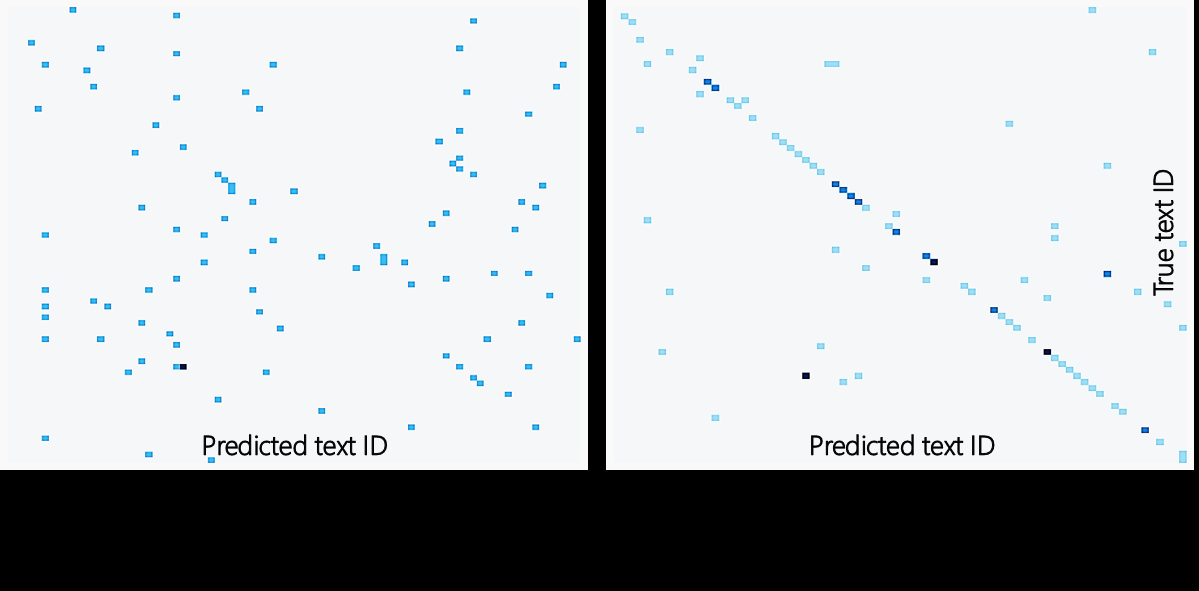 图2 (a):双分支表征的t-SNE可视化。左图显示声学表征按噪声类型(babble, street, pink, white)形成聚类;右图显示语义表征按MOS分数形成连续流形,而非按噪声类型聚类。这直观验证了两个分支的功能分离:声学分支捕捉噪声环境,语义分支编码内容与感知质量。
图2 (a):双分支表征的t-SNE可视化。左图显示声学表征按噪声类型(babble, street, pink, white)形成聚类;右图显示语义表征按MOS分数形成连续流形,而非按噪声类型聚类。这直观验证了两个分支的功能分离:声学分支捕捉噪声环境,语义分支编码内容与感知质量。
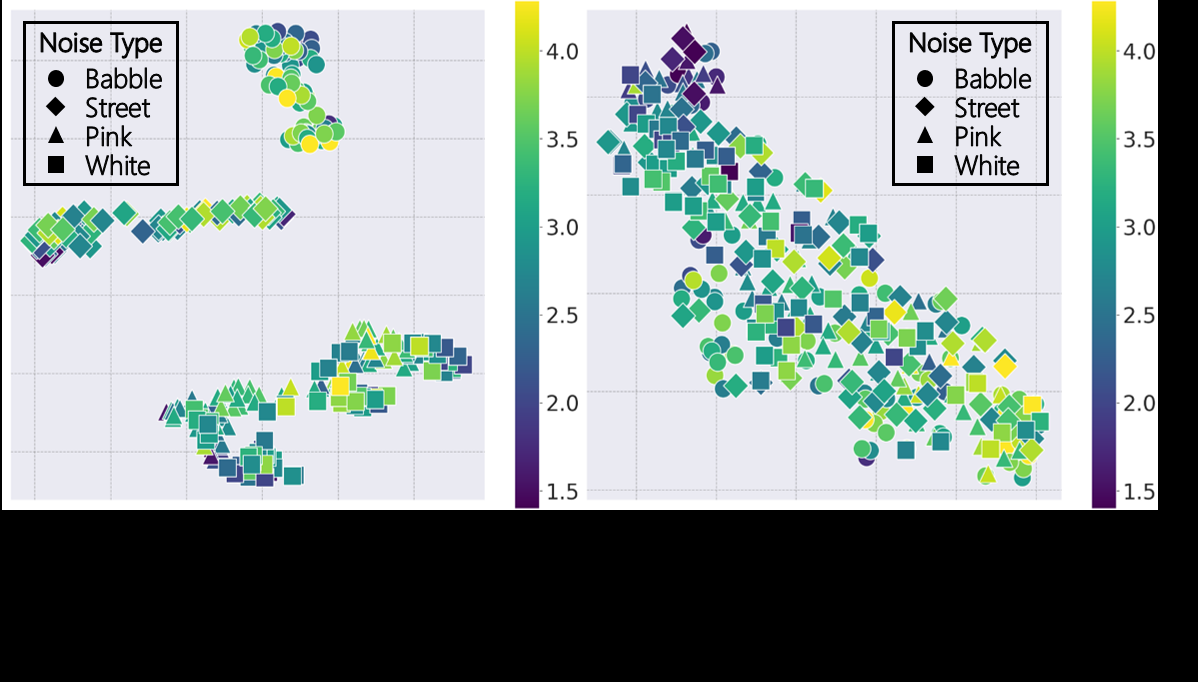 图2 (b):文本内容ID预测的线性探测混淆矩阵。语义表征的混淆矩阵(右)呈现强对角线,表明能准确识别文本内容;声学表征的混淆矩阵(左)杂乱,表明对文本内容不敏感。这定量证实了语义分支编码语言信息,声学分支编码非语言声学信息。
图2 (b):文本内容ID预测的线性探测混淆矩阵。语义表征的混淆矩阵(右)呈现强对角线,表明能准确识别文本内容;声学表征的混淆矩阵(左)杂乱,表明对文本内容不敏感。这定量证实了语义分支编码语言信息,声学分支编码非语言声学信息。
⚖️ 评分理由
- 学术质量:6.5/7。论文提出了清晰的“语义鸿沟”问题,并设计了逻辑自洽的JASSQA模型进行解决。技术实现正确,实验设计全面(包含多数据集对比、跨域泛化测试、详细消融分析、表征可视化),数据可信。扣分点在于其核心架构(双分支+交叉注意力)是现有组件的组合应用,创新主要体现在应用和整合层面,而非提出全新的、具有理论突破的融合机制或模型范式。
- 选题价值:1.5/2。语音质量评估是语音处理领域一个基础且重要的任务,尤其在当前语音生成技术(TTS, VC)快速发展的背景下,客观、鲁棒的评估指标需求迫切。论文针对的“泛化性差”痛点是实际应用中的真实挑战,因此具有较高的前沿性和应用价值。
- 开源与复现加成:0.5/1。论文提供了开源代码仓库(https://github.com/kalenon/JASSQA),这对于社区复现和基于此工作进行改进是重要的。然而,论文未公开模型权重,且部分训练细节(如第二阶段极小的batch size=1)可能在实际复现中需要额外调整和解释,因此复现便利性未达到最佳状态。