📄 Bridging the Front-End and Back-End for Robust ASR via Cross-Attention-Based U-Net
#语音识别 #交叉注意力 #U-Net #鲁棒性
✅ 7.0/10 | 前25% | #语音识别 | #交叉注意力 | #U-Net #鲁棒性
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Tianqi Ning (新疆大学计算机科学与技术学院)
- 通讯作者:Hao Huang (新疆大学计算机科学与技术学院)
- 作者列表:Tianqi Ning (新疆大学计算机科学与技术学院, 新疆多语言信息技术重点实验室),Lili Yin (新疆大学计算机科学与技术学院, 新疆多语言信息技术重点实验室),Liting Jiang (新疆大学计算机科学与技术学院, 新疆多语言信息技术重点实验室),Yuye Hu (新疆大学计算机科学与技术学院, 新疆多语言信息技术重点实验室),Ziyuan Chen (新疆大学计算机科学与技术学院, 新疆多语言信息技术重点实验室),Hao Huang (新疆大学计算机科学与技术学院, 新疆多语言信息技术重点实验室, 丝绸之路多语言认知计算联合国际研究实验室)
💡 毒舌点评
本文的核心亮点在于其“桥梁”模块的设计哲学:不改变预训练的SE和ASR模型,而是通过一个轻量的交叉注意力U-Net在冻结设置下进行特征融合,这为即插即用地提升现有系统鲁棒性提供了一个优雅的解决方案。然而,论文在证明该方法的普适性上稍显薄弱,其所有实验均在一个跨域测试集(AMI)上进行,虽然这恰恰是其宣称的优势场景,但缺乏在标准训练/测试同分布基准(如CHiME-4测试集)上的验证,使得结论的全面性打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。作者未提供开源代码仓库。
- 模型权重:未提及是否公开模型权重。
- 数据集:使用了公开数据集CHiME-4(训练)和AMI sdm1(测试),但未提供数据预处理脚本或具体配置文件。
- Demo:未提供在线演示。
- 复现材料:论文给出了较详细的训练配置(学习率、批量大小、梯度累积、裁剪范数、通道数等),但部分关键细节(如优化器、warm-up步数、损失函数、具体硬件环境)未说明,不足以完全复现。
- 引用的开源项目:SE前端使用了FRCRN [29] 和 MossformerGAN [30],ASR后端使用了Whisper [31]。这些模型本身是公开的,但论文未提供集成这些模型的具体代码。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:语音增强(SE)作为语音识别(ASR)的前端,会引入与ASR目标不匹配的失真或伪影。现有观察添加(OA)方法通过线性融合增强语音和带噪语音来缓解此问题,但在复杂声学环境中效果有限且依赖于固定的融合系数。
- 方法核心:提出一种基于交叉注意力的U-Net模块(CA-UNet),用于交互式地融合增强语音和带噪语音的Fbank特征。该模块采用双分支编码器-解码器架构,利用交叉注意力机制让两个输入分支相互提取互补信息,并通过门控融合模块自适应整合输出,最终生成更鲁棒的声学特征。
- 创新性:与OA的线性加法机制相比,本方法引入了非线性、可学习的交互式特征融合;在保持前端SE和后端ASR模型参数冻结的严格条件下运行,具有即插即用的实用性;将U-Net的多尺度特征提取能力与交叉注意力的动态信息整合能力相结合。
- 主要实验结果:在AMI sdm1数据集(复杂会议场景)上,使用冻结的FRCRN(SE)和Whisper-medium(ASR)时,所提方法相比最佳OA基线(wOA=0.2)实现了28.71%的相对词错误率(WER)降低,相比仅使用增强语音(SE-ASR)实现了26.76%的相对降低。消融实验表明,交叉注意力和自注意力模块对性能提升均有贡献。关键实验结果表格如下:
ASR后端 SE前端 仅ASR (WER) SE+ASR (WER) SE+OA+ASR (WER) 提出方法 (WER) whisper-small FRCRN 99.18% 72.49% 77.94% 54.06% whisper-small MossformerGAN 99.18% 56.35% 64.44% 52.91% whisper-medium FRCRN 62.67% 54.25% 55.73% 39.73% whisper-medium MossformerGAN 62.67% 46.58% 49.74% 41.39% whisper-large FRCRN 53.98% 44.62% 47.39% 38.93% whisper-large MossformerGAN 53.98% 40.49% 43.53% 40.81% 表I 摘录。可以看出,提出方法在所有配置中均取得最佳或次佳性能,尤其在使用较小ASR模型时优势更明显。 - 实际意义:为在不重新训练已有预训练SE和ASR模型的前提下,提升复杂环境下的ASR鲁棒性提供了一种有效的后处理方案,降低了系统集成与升级的成本。
- 主要局限性:实验验证集中在单一的跨域测试集(AMI),缺乏在标准同分布基准上的对比;模块虽轻量但仍引入额外延迟(约15.83ms/句),对实时性要求极高的场景可能有影响;论文未公开代码和模型,限制了复现与应用。
🏗️ 模型架构
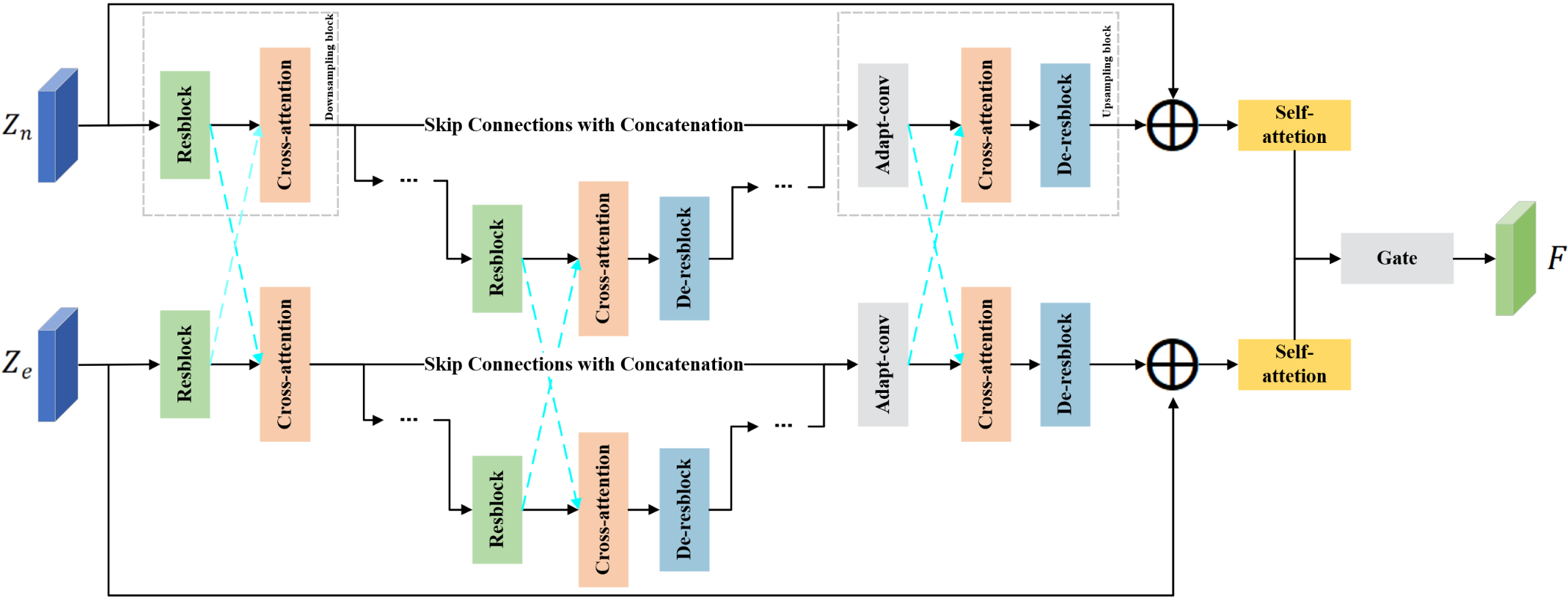 整体架构: 如图1所示,所提模块接收两路输入:增强语音的Fbank特征(Ze) 和 带噪语音的Fbank特征(Zn)。每路输入通过一个独立的分支进行处理,两个分支结构对称,均包含一个编码器、一个解码器以及一个门控融合模块。最终,融合后的特征被送入下游ASR后端(如Whisper)。
整体架构: 如图1所示,所提模块接收两路输入:增强语音的Fbank特征(Ze) 和 带噪语音的Fbank特征(Zn)。每路输入通过一个独立的分支进行处理,两个分支结构对称,均包含一个编码器、一个解码器以及一个门控融合模块。最终,融合后的特征被送入下游ASR后端(如Whisper)。
组件详解:
- 双分支编码器-解码器 (U-Net结构):
- 编码器:每个分支的编码器包含三个下采样阶段。每个阶段由卷积残差块(Convolutional Residual Block) 和 多头交叉注意力块(Multi-head Cross-attention Block) 组成。卷积残差块通过两个卷积层、LeakyReLU激活和跳跃连接提取层级化的声学特征。池化层逐步下采样以扩大感受野。
- 解码器:解码器遵循对称的上采样路径。它通过自适应卷积模块(adapt-conv) 处理来自对应编码器层的跳跃连接(skip connections)与前一个块输出拼接后的张量,再通过反残差块(de-resblock) 逐步恢复空间分辨率。
- 交叉注意力机制(Cross-Attention):这是模型实现“交互”的核心。在编码器的每个阶段,两个分支(增强语音流与带噪语音流)通过交叉注意力进行信息交互。以增强语音分支为例(如图2所示),它将自身的特征作为查询(Query),而从带噪语音分支提取的特征作为键(Key)和值(Value)。通过计算注意力权重,增强语音分支能够动态地从带噪语音中选择性地聚合互补信息,从而丰富其表示。
- 残差连接与自注意力:在每个分支的U-Net结构末端,输入特征与输出特征通过一个残差连接相加,以稳定训练并保留原始信息。随后,融合表示通过一个自注意力(Self-attention) 块,以捕捉特征内部的长程依赖关系。
- 门控融合模块(Gated Fusion Module):在两个分支的处理完成后,一个门控融合模块接收来自增强语音分支和带噪语音分支的最终输出。该模块自适应地学习一个融合权重,将两个分支的表示组合成一个单一的、更鲁棒的特征表示,作为最终输出。
数据流: 原始音频 -> STFT -> Fbank提取 -> 送入增强语音分支和带噪语音分支。在编码阶段,两个分支的对应层级通过交叉注意力交换信息。解码后,两个分支的输出经自注意力处理,最后由门控融合模块合并,生成最终增强的Fbank特征,输入ASR解码器。
💡 核心创新点
- 交互式特征融合机制:提出使用交叉注意力替代OA的线性加法。局限:线性OA在复杂环境下系数选择困难且性能有限。创新:交叉注意力允许模型根据当前输入动态学习如何从两种语音(增强/带噪)中提取最互补的信息,实现了非线性的、数据驱动的融合。收益:在复杂声学环境(AMI数据集)下取得了显著的WER降低(相对OA降低28.71%)。
- 冻结模型下的即插即用设计:该模块设计为在预训练的SE前端和ASR后端参数完全冻结的情况下工作。局限:联合微调(joint fine-tuning)成本高且依赖训练域数据。创新:提出一个独立的中间融合模块,无需修改或重训已部署的庞大模型。收益:提供了灵活的部署方式,可快速集成到现有语音识别管线中以提升鲁棒性,降低了升级成本。
- 双分支U-Net与多尺度特征融合:采用U-Net架构作为特征提取和重建的骨干。局限:简单的特征拼接或加法可能丢失多尺度信息。创新:U-Net的编码器-解码器结构和跳跃连接能够同时利用浅层细节和深层语义特征;双分支设计确保了两种输入源的特征在多尺度上都能进行独立的提取与交互。收益:增强了模块对复杂声学特征(如噪声、混响、伪影)的建模和修复能力。
🔬 细节详述
- 训练数据:在CHiME-4数据集(单通道channel 5)上训练,包含1,600个真实和7,138个模拟的带噪语音语句。预处理:STFT(FFT长度400,窗长400,帧移160,汉明窗),然后提取Fbank特征。
- 损失函数:论文中未明确说明损失函数的名称和具体形式。
- 训练策略:
- 学习率:0.001,并采用warm-up策略(具体步数未说明)。
- 批量大小:batch size为1,梯度累积步数为32(等效批量大小32)。
- 优化器:未提供具体名称(如Adam, SGD)。
- 训练轮数:最多10个epoch。
- 梯度裁剪:最大范数5.0。
- 关键超参数:
- 模型参数量:2.77M(额外引入的参数)。
- U-Net通道数:编码器通道序列 [16, 32, 64, 128],解码器对称为 [128, 64, 32, 16]。
- 交叉注意力头数(H):未具体说明,但公式(3)中提及。
- 训练硬件:未说明。
- 推理细节:
- 平均额外延迟:每句15.83毫秒。
- SE前端:FRCRN 或 MossformerGAN。
- ASR后端:Whisper-small/medium/large。
- 所有SE和ASR模型参数在训练和推理时均冻结。
- 正则化/稳定技巧:梯度裁剪(max norm 5.0)。
📊 实验结果
主要评估:在AMI sdm1测试集(复杂会议场景,包含噪声、混响和说话人重叠)上评估WER。基线系统包括:仅ASR(only-ASR)、SE+ASR、SE+OA+ASR(OA系数在{0.0, 0.1, …, 1.0}中选择最优值)。 关键对比结果(完整表格见核心摘要部分):
- 提出方法在多数配置中显著优于所有基线。例如,使用FRCRN+whisper-medium时,提出方法的WER为39.73%,而最优基线(SE-ASR)为54.25%,相对改进达26.76%。
- OA方法(SE-OA-ASR)在该复杂数据集上表现通常差于SE-ASR,证实了线性融合的局限性。表II显示,在FRCRN+whisper-medium配置下,OA系数从0增至1.0时,WER从54.25%持续恶化至62.67%,最优系数为0(即等同于SE-ASR)。 消融研究(表III):在FRCRN+whisper-medium上验证各组件贡献。
- 基础U-Net+门控融合:WER 41.72%
- 加上交叉注意力:WER 40.56% (-1.16%)
- 再加自注意力(完整模型):WER 39.73% (-0.83%) 结果表明所有模块都有正向贡献。
图表引用:
- 图1 (
):展示了所提模块的整体双分支U-Net架构、交叉注意力交互和门控融合的完整流程。 - 图2 (
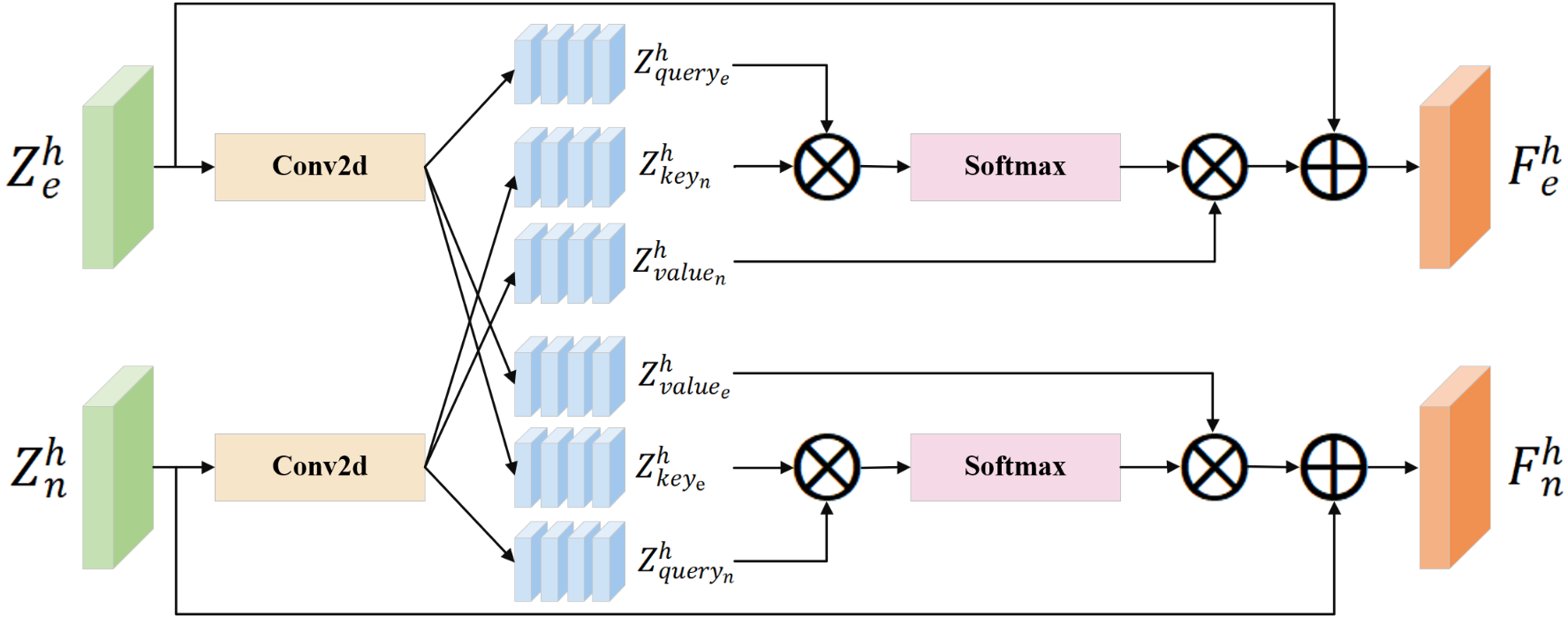):详细示意了交叉注意力模块如何工作,即增强语音特征如何作为查询去从带噪语音特征(键和值)中提取信息。
⚖️ 评分理由
- 学术质量:6.5/7。论文动机清晰,技术方案合理(交叉注意力+U-Net+门控融合),实验设计严谨(冻结模型设置、充分基线对比、消融研究),并在目标场景(复杂跨域)下取得了实质性改进。主要不足是实验验证范围较窄,仅在一个跨域测试集上进行,缺乏在标准训练-测试同分布基准(如CHiME-4测试集)上的表现,这在一定程度上削弱了结论的普适性。
- 选题价值:2.0/2。鲁棒语音识别是工业界和学术界的持续热点。提出一种“即插即用”、无需重训现有大模型的融合模块来提升鲁棒性,具有明确的实用价值和工程吸引力。
- 开源与复现加成:-0.5/1。论文提供了详细的架构描述和超参数配置(如通道数、训练轮数、学习率、梯度裁剪),这对于理解方法至关重要。然而,未提供代码仓库链接、预训练模型权重或完整的训练脚本,这显著增加了完全复现的难度,因此给予扣分。