📄 BridgeCode: A Dual Speech Representation Paradigm for Autoregressive Zero-Shot Text-to-Speech Synthesis
#语音合成 #自回归模型 #零样本 #模型评估
🔥 8.0/10 | 前25% | #语音合成 | #自回归模型 | #零样本 #模型评估
学术质量 5.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Jingyuan Xing(华南理工大学)、Mingru Yang(华南理工大学) (论文注明两者共同第一作者)
- 通讯作者:Xiaofen Xing(华南理工大学)、Xiangmin Xu(佛山大学) (论文标注†)
- 作者列表:Jingyuan Xing(华南理工大学)、Mingru Yang(华南理工大学)、Zhipeng Li(华南理工大学)、Xiaofen Xing(华南理工大学)、Xiangmin Xu(佛山大学,华南理工大学)
💡 毒舌点评
亮点在于其提出的“双表示”范式巧妙地将离散token的生成效率与连续特征的高质量重建相结合,有效缓解了自回归TTS中经典的“速度-质量”矛盾,并在实验中取得了目前最低的token生成率。短板是所有实验仅在英语LibriTTS一个数据集上进行,虽然方法具有通用性,但缺乏多语言或跨领域(如情感、唱歌)的验证,其真实泛化能力尚待证明。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:实验使用公开的LibriTTS数据集,但未提供经过处理的特定数据或脚本。
- Demo:提供了在线语音合成演示页面链接:https://test1562.github.io/demo/.
- 复现材料:给出了部分训练细节(如优化器、学习率、batch size、训练步数、硬件),但未提供完整的训练配置文件、模型架构详细参数或检查点。
- 论文中引用的开源项目:wav2vec 2.0 Base(特征编码器)、HiFi-GAN(vocoder)。
📌 核心摘要
- 要解决什么问题:针对基于自回归(AR)的零样本文本到语音合成(TTS)中存在的两个关键问题:(i) 生成速率与合成质量之间固有的权衡矛盾;(ii) 直接沿用文本模型训练范式导致的语音监督信号失配。
- 方法核心是什么:提出BridgeTTS框架,其核心是BridgeCode双语音表示范式。该范式包含稀疏的离散token和稠密的连续特征两种表示,并设计了SparseBridge和DenseBridge两个对称的桥接模块进行双向转换。AR模型在生成时只需预测低帧率的稀疏token,再通过DenseBridge恢复出高信息量的连续特征用于高质量合成。同时,训练中引入特征损失(Feature Loss)与token损失联合优化,提供更细粒度的监督。
- 与已有方法相比新在哪里:不同于以往AR-TTS要么降低token率牺牲质量,要么增加token信息量牺牲效率的单一思路,BridgeCode首次提出利用“稀疏token生成+连续特征重建”的混合范式,在提升效率的同时保证质量。此外,通过联合token级和特征级的损失函数,解决了AR模型训练中的监督信号失配问题。
- 主要实验结果如何:在LibriTTS数据集上,BridgeTTS取得了最低的Token Rate(10Hz),相较于基线CosyVoice(25Hz)和GPT-Talker(50Hz)大幅降低。同时,其词错误率(WER)在测试集上为4.9%,显著低于VALL-E(18.5%)、UniAudio(12.9%)和GPT-Talker(16.4%),仅略高于CosyVoice(8.0%)。在语音质量(QMOS)和说话人相似度(SMOS)上,BridgeTTS与最优的CosyVoice表现相当或略低,但均优于大多数基线。消融实验证明,DenseBridge和特征损失对性能有关键贡献。合成速度(RTF)相比基线AR模型提升了约63%(0.37x)。
| 模型 | Token Rate (↓) | WER (↓) | SMOS (↑) | QMOS (↑) | UTMOS (↑) |
|---|---|---|---|---|---|
| LibriTTS Development Set | |||||
| GT | / | 2.3% | 4.41 ± 0.11 | 4.41 ± 0.13 | 4.258 |
| CosyVoice | 25Hz | 6.8% | 4.13 ± 0.12 | 4.36 ± 0.12 | 4.253 |
| BridgeTTS (Ours) | 10Hz | 3.4% | 4.07 ± 0.11 | 4.15 ± 0.09 | 4.050 |
| LibriTTS Test Set | |||||
| VALL-E | 50Hz | 18.5% | 3.64 ± 0.12 | 3.49 ± 0.11 | 2.728 |
| CosyVoice | 25Hz | 8.0% | 4.12 ± 0.08 | 4.29 ± 0.11 | 4.148 |
| BridgeTTS (Ours) | 10Hz | 4.9% | 4.01 ± 0.12 | 4.11 ± 0.13 | 3.894 |
| 模型 | Token Rate (↓) | WER (↓) | SMOS (↑) | QMOS (↑) | UTMOS (↑) |
|---|---|---|---|---|---|
| BridgeTTS | 10Hz | 4.9% | 4.01 ± 0.12 | 4.11 ± 0.13 | 3.894 |
| -w/o DenseBridge | 10Hz | 13.8% | 3.74 ± 0.11 | 3.74 ± 0.12 | 3.443 |
| -w/o Lfeatures | 10Hz | 7.1% | 3.92 ± 0.13 | 3.96 ± 0.12 | 3.471 |
| 系统 | RTF (↓) | Token Rate (↓) | WER (↓) | SMOS (↑) | QMOS (↑) | UTMOS (↑) |
|---|---|---|---|---|---|---|
| Baseline AR | 1× | 50Hz | 9.8% | - | - | - |
| BridgeTTS | 0.37× | 10Hz | 4.9% | +0.12 | +0.09 | +0.43 |
- 实际意义是什么:该方法为构建更高效、高质量的零样本TTS系统提供了新思路。通过降低自回归生成的计算需求,有助于在资源受限的设备或需要实时响应的场景中部署先进的语音合成技术。
- 主要局限性是什么:目前所有实验仅在英文LibriTTS数据集上进行,对于多语言、跨领域的泛化能力未做探讨。此外,虽然对比了多种基线,但未与最新(如2025-2026)的一些代表性工作进行直接比较。
🏗️ 模型架构
BridgeTTS的整体架构分为两大部分:BridgeCode表示学习框架和BridgeTTS自回归生成框架。
BridgeCode: 这是一个用于学习和转换双语音表示的框架,包含三个核心组件:
- 冻结的特征编码器:使用预训练的wav2vec 2.0 Base模型,从原始语音中提取稠密连续特征(F0 ∈ RT×768)。
- SparseBridge:将稠密特征压缩为稀疏离散token。其内部流程为:输入特征先经过多尺度卷积(核大小1,3,5)提取上下文特征(F1),然后进行时间维度下采样(5倍降帧率,得到F2),最后通过分层残差向量量化(RVQ)将F2压缩为离散码。关键设计:仅保留RVQ的第一层码本索引作为最终稀疏token,大幅压缩了信息量。
- DenseBridge:将稀疏token重建为稠密连续特征。其内部流程为:先用码本预测器从稀疏token预测出完整的RVQ码,再通过分层RVQ解码器恢复量化特征,然后上采样恢复原始时间分辨率,最后通过多尺度卷积逆网络细化,输出重建的连续特征。
两个Bridge网络通过对称设计和层间对齐约束(Layer-wise alignment)实现精确的双向转换,整体训练由代码预测损失(Lcode)、特征重建损失(Lfeat)和语音对抗损失(Ladv)联合优化。
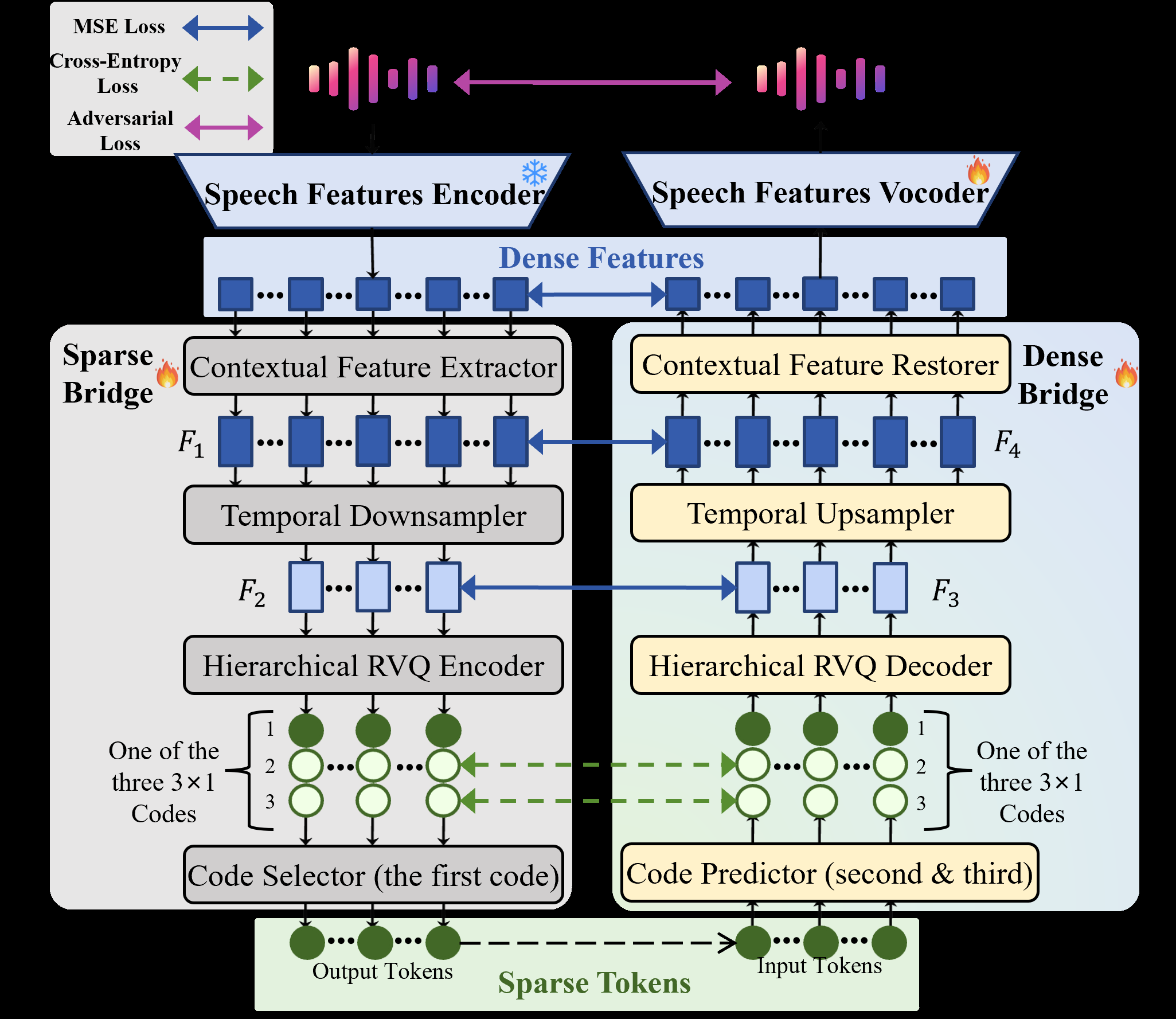 图2: BridgeCode的架构与桥接模块细节。展示了SparseBridge的压缩过程和DenseBridge的重建过程,以及训练时的层间对齐约束。
图2: BridgeCode的架构与桥接模块细节。展示了SparseBridge的压缩过程和DenseBridge的重建过程,以及训练时的层间对齐约束。
BridgeTTS: 基于BridgeCode构建的自回归TTS框架,其AR生成器基于GPT-2模型重训练。其独特之处在于AR的推理范式:
- 输入:每个预测步,AR模型输入的不是上一个token,而是之前5个连续的语音特征帧(由DenseBridge从已生成的token重建而来)。这提供了更丰富的上下文。
- 输出:预测下一个稀疏离散token。
- 迭代:将新预测的token送入冻结的DenseBridge,重建为5帧稠密特征,追加到特征序列中,作为下一步的输入。如此迭代,直到生成EOS或达到目标长度。
训练时,损失函数为token预测损失(Ltoken)与特征重建损失(Lfeatures)之和。
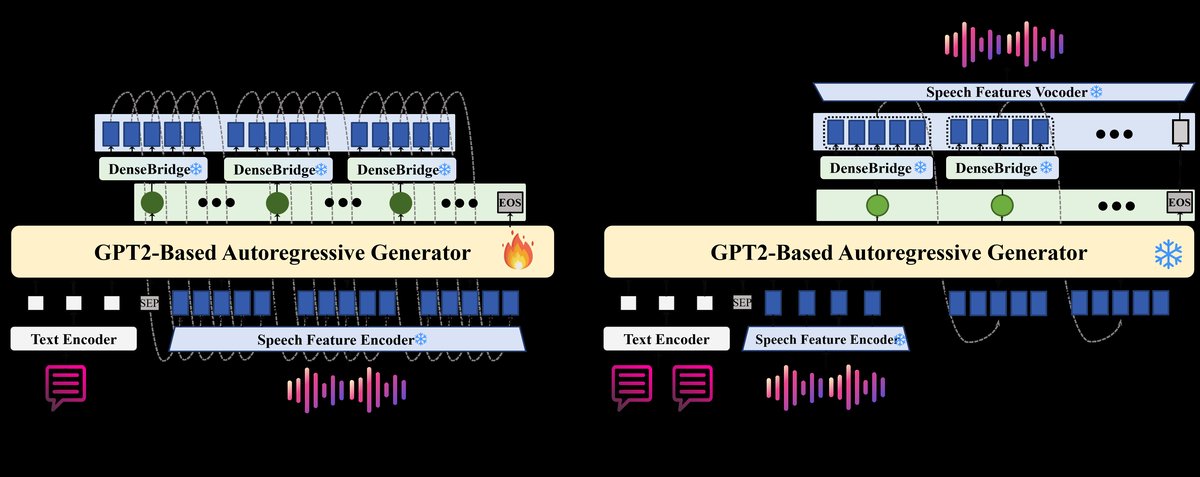 图3: BridgeTTS的训练和推理流程。(A)训练过程:AR模型在token损失和特征损失下优化。(B)推理过程:AR生成token,通过DenseBridge转换为特征,再输入模型进行下一轮预测。
图3: BridgeTTS的训练和推理流程。(A)训练过程:AR模型在token损失和特征损失下优化。(B)推理过程:AR生成token,通过DenseBridge转换为特征,再输入模型进行下一轮预测。
💡 核心创新点
- 双语音表示范式(BridgeCode):首次提出将语音同时表示为“稀疏离散token”和“稠密连续特征”两种形式,并设计了可学习的双向转换桥接模块。这解决了AR模型中token生成率与信息密度不可兼得的根本矛盾。
- 联合监督优化:针对文本自回归模型训练范式在语音任务上的不适配问题,提出在token级交叉熵损失之外,增加基于连续特征的特征损失(MSE),为语音token预测提供了更符合声学特性、更细粒度的梯度监督信号。
- 高效AR生成范式:通过让AR模型基于低帧率的稀疏token进行预测,并利用DenseBridge从稀疏token恢复出高信息量的连续特征作为AR的上下文输入,实现了“少预测、多信息”的高效生成模式,显著减少了AR迭代步数。
🔬 细节详述
- 训练数据:使用LibriTTS数据集,包括train-clean-100, train-clean-360, train-other-500子集(共585小时),采样率16kHz。未提及具体数据预处理或增强策略。
- 损失函数:
- Lcode:在DenseBridge训练中,用于预测的第二、三RVQ码与真实码之间的交叉熵损失。
- Lfeat:在BridgeCode训练中,重建特征与压缩特征之间的均方误差(MSE)。
- Ladv:使用HiFi-GAN判别器计算的对抗损失。
- Ltoken:在BridgeTTS训练中,AR模型预测token与真实token的交叉熵损失。
- Lfeatures:在BridgeTTS训练中,AR模型预测token经DenseBridge重建的特征与真实特征的MSE损失。
- Ltotal = Lcode + Lfeat + Ladv。
- LAR = Ltoken + Lfeatures。
- 训练策略:
- 优化器:AdamW,初始学习率1.0×10⁻⁴,按每epoch衰减因子0.9991/8衰减。
- Batch Size:16。
- 训练步数:BridgeCode训练700k步,BridgeTTS的AR生成器训练600k步。
- 训练顺序:先训练BridgeCode(两个桥接模块),冻结后,再训练AR生成器。
- 关键超参数:
- 稠密连续特征维度:768(来自wav2vec 2.0 Base)。
- SparseBridge下采样因子:5(即稀疏token帧率为原始特征帧率的1/5)。
- Hierarchical RVQ:将2304维特征拆分为3个768维向量,每个用3层RVQ量化,形成3×3的码矩阵。最终只使用第一层码。
- AR模型:基于GPT-2,但具体规模(层数、隐藏维度)论文中未提及。
- 训练硬件:NVIDIA A800 GPU,训练步数如上,但总训练时长论文中未提及。
- 推理细节:
- AR生成器每步输入5个连续特征帧。
- 每步预测一个token。
- 迭代终止条件:生成EOS token或达到目标序列长度。
- 最终语音合成:使用训练时微调的HiFi-GAN vocoder。
- 未提及温度、beam size等具体解码参数。
📊 实验结果
主要对比实验在LibriTTS开发集和测试集上进行,基线包括VALL-E, UniAudio, GPT-Talker和CosyVoice。评估指标包括客观指标(Token Rate, WER, UTMOS)和主观指标(SMOS, QMOS)。
关键结论:
- 效率:BridgeTTS取得了所有模型中最低的Token Rate(10Hz),相比CosyVoice(25Hz)和GPT-Talker(50Hz)降低了60%-80%的生成帧率。实时因子(RTF)相比基线AR模型提升了63%(从1×降至0.37×)。
- 质量:在合成质量(QMOS)和说话人相似度(SMOS)上,BridgeTTS与当前表现最好的CosyVoice差距很小(测试集QMOS差0.18, SMOS差0.11),但显著优于VALL-E, UniAudio等。其UTMOS得分也处于第一梯队。
- 准确性:在测试集上,BridgeTTS的WER(4.9%)显著低于VALL-E(18.5%)、UniAudio(12.9%)和GPT-Talker(16.4%),接近CosyVoice(8.0%),表明其生成的语音可懂度很高。
- 消融研究:
- 移除DenseBridge(即直接用稀疏token生成)导致WER飙升至13.8%,各项主观分数大幅下降,证明DenseBridge对于恢复高质量语音至关重要。
- 移除特征损失(Lfeatures)后,WER从4.9%上升至7.1%,SMOS、QMOS、UTMOS均有明显下降,证明联合优化特征损失对提升自然度和可懂度有直接贡献。
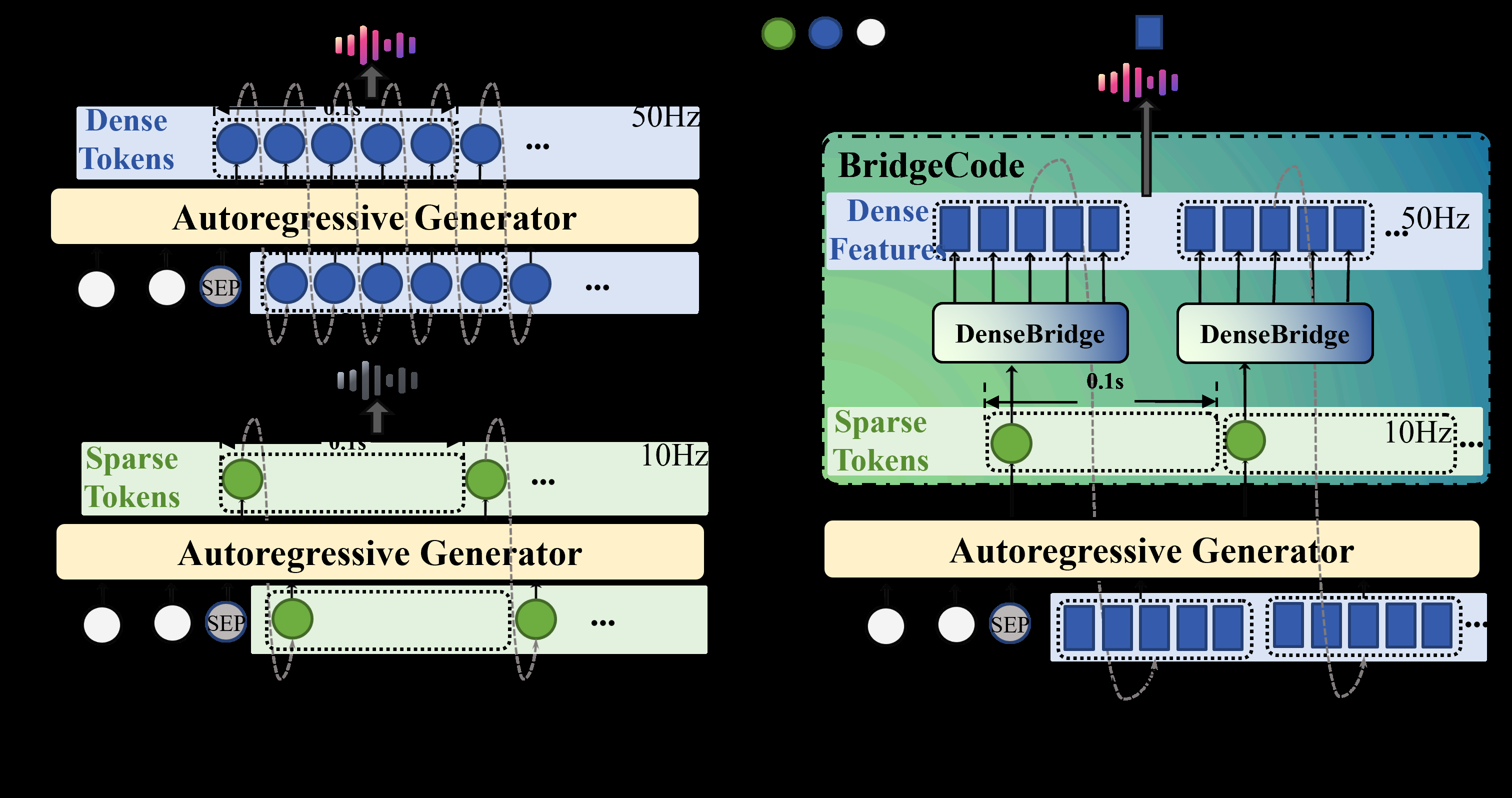 图1: 现有AR-TTS框架(A)与提出的BridgeTTS(B)在token生成率与质量权衡上的对比示意图。
图1: 现有AR-TTS框架(A)与提出的BridgeTTS(B)在token生成率与质量权衡上的对比示意图。
图3: BridgeTTS的架构与流程,同时也展示了通过桥接模块实现高效生成的机制,这与表3中的RTF提升直接对应。
⚖️ 评分理由
- 学术质量:5.5/7:创新性较强,提出了新颖的双表示范式和联合优化目标,有效解决了领域内的具体痛点。技术实现完整,实验设计合理,进行了充分的对比和消融研究,数据支撑了主要论点。扣分点在于实验仅限于单一英文数据集,模型细节(如AR生成器具体参数)未完全公开,限制了结论的普适性和可复现性评估。
- 选题价值:2.0/2:选题非常前沿且重要,直接针对当前主流AR-TTS系统的核心瓶颈进行优化。研究成果对提升TTS系统效率、降低部署门槛具有明确的推动作用,与语音合成领域的研究者和工程师高度相关。
- 开源与复现加成:0.5/1:论文提供了Demo页面链接,展示了合成效果。训练细节(优化器、学习率、步数、数据集)提供了部分信息。但核心代码、模型权重、完整的训练配置均未公开,严重限制了其他研究者的复现和后续开发。