📄 Break-the-Beat! Controllable MIDI-to-Drum audio synthesis
#音乐生成 #扩散模型 #预训练 #音频生成 #模型评估
✅ 7.5/10 | 前25% | #音乐生成 | #扩散模型 | #预训练 #音频生成
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Shuyang Cui (Sony Group Corporation)
- 通讯作者:未说明(论文中未明确标注)
- 作者列表:Shuyang Cui¹, Zhi Zhong¹, Qiyu Wu¹, Zachary Novack¹*, Woosung Choi², Keisuke Toyama¹, Kin Wai Cheuk², Junghyun Koo², Yukara Ikemiya², Christian Simon¹, Chihiro Nagashima¹, Shusuke Takahashi¹ (1: Sony Group Corporation, 2: Sony AI)
💡 毒舌点评
这篇论文技术方案完备,从数据构建、模型设计到实验评估都做得非常扎实,成功填补了“MIDI-to-Drum”这一特定任务的研究空白,对于音乐制作工具开发具有明确的导向性。然而,其主要创新集中在对现有框架的适配和针对性设计上,在生成模型基础架构层面的突破性略显不足,且缺乏与更多元、更强的基线模型在相似音乐生成任务上的横向比较,说服力可再增强。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开本项目微调后的模型权重。
- 数据集:论文中提到构建了配对数据集,但未提及是否公开以及获取方式。
- Demo:提供在线演示页面:https://ik4sumii.github.io/break-the-beat/
- 复现材料:给出了主要的训练超参数(学习率、优化器、batch size、训练轮数、硬件)和推理设置(采样器、步数)。但未提供完整的配置文件、数据预处理脚本或检查点。
- 论文中引用的开源项目:
- Stable Audio Open [1]:预训练的文本到音频模型,作为本工作的基础框架。
- librosa [38]:用于起音检测和节拍追踪。
- MIR EVAL [39]:用于计算节拍连续性指标。
- 整体开源计划:论文中未提及开源计划。
📌 核心摘要
这篇论文解决了数字音乐制作中,从鼓MIDI序列生成高质量、可控音色鼓音频的难题,传统方法费时费力且需要专业技能。其核心方法是微调预训练的文本到音频扩散模型(Stable Audio Open),通过一个专门设计的内容编码器处理目标鼓MIDI和参考音频,并采用结合拼接、输入相加和前缀的混合条件机制,将节奏和音色信息注入生成过程。与以往专注于文本生成音乐或钢琴MIDI到音频的工作不同,这是首个专门针对打击乐、非调性MIDI到音频合成的可控模型。实验表明,该模型在音频质量、节奏对齐和节拍连续性上均表现良好,例如在64音符分辨率下,其FAD_VGGish为0.09,起音F1分数为70.08%。该工作为音乐制作人提供了一个新的、可控的鼓音色合成工具。主要局限性在于生成的音频长度被限制在2小节,且未与同领域的生成式音乐模型进行更广泛的性能对比。
🏗️ 模型架构
论文提出了一种基于微调的扩散Transformer(DiT)模型架构,旨在将鼓MIDI序列和参考音频合成目标鼓音频。整体流程如图1所示。
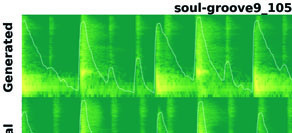 图1展示了模型的整体框架。原始Stable Audio Open(SAO)的文本到音频架构被修改为以鼓MIDI和参考音频为条件。核心组件包括:MIDI二值化器、VAE编码器、内容编码器、混合条件机制以及扩散Transformer。
图1展示了模型的整体框架。原始Stable Audio Open(SAO)的文本到音频架构被修改为以鼓MIDI和参考音频为条件。核心组件包括:MIDI二值化器、VAE编码器、内容编码器、混合条件机制以及扩散Transformer。
模型的完整输入输出流程如下:
- 输入:
- 目标鼓MIDI:通过MIDI二值化器转换为“编排”(Arrangement)或“敲击”(Tap)表示,是一个T步长、10维的二进制网格向量。
ctgt ∈ RT ×10。 - 参考音频:通过预训练的VAE编码器转换为潜变量序列
xref ∈ RNref ×64,用于捕获音色信息。 - 参考音频的MIDI:同样被转换为表示
cref,用于内容编码器的双输入处理。 - 全局条件:包括扩散时间步
ct、目标音频时长cdur、目标编排的时间步数csteps。
- 目标鼓MIDI:通过MIDI二值化器转换为“编排”(Arrangement)或“敲击”(Tap)表示,是一个T步长、10维的二进制网格向量。
- 处理流程:
- 内容编码器 (Content Encoder):这是一个核心新组件。它包含一个4层的Transformer,采用双输入策略(处理
ctgt和cref,权重共享)。内部先用自注意力层捕获MIDI内部时间结构,再用交叉注意力层以MIDI特征为查询(Query)、参考音频潜变量xref为键/值(Key/Value),融合音色信息。最终输出拼接后的条件特征ccont ∈ R2T ×d。 - 混合条件机制 (Hybrid Conditioning):
- 拼接 (Concatenation):将参考音频潜变量
xref与扩散过程的带噪声潜变量zt在时间维度上拼接,直接为模型提供音色上下文。 - 输入相加 (Input Addition):内容特征
ccont经过一个免训练的“内容对齐器”(Content Aligner),根据速度将特征时间对齐到音频潜变量的时间步,然后逐元素相加到DiT初始1D卷积层之后的输入中。 - 前缀 (Prepending):将全局条件
ct,cdur,csteps分别通过MLP或条件器编码成嵌入向量,并前置到DiT的输入序列中。
- 拼接 (Concatenation):将参考音频潜变量
- 扩散Transformer (DiT):采用从SAO初始化的24层DiT。它接收经过上述混合条件处理后的输入,通过DPM-Solver++采样器进行10步去噪,生成目标音频的潜变量
z0。
- 内容编码器 (Content Encoder):这是一个核心新组件。它包含一个4层的Transformer,采用双输入策略(处理
- 输出:通过预训练且冻结的VAE解码器,将生成的潜变量
z0解码为44.1kHz的立体声音频波形。
关键设计选择:
- 双输入内容编码器:确保模型同时理解目标节奏和参考音色。
- 混合条件机制:论文实验验证,相比仅使用交叉注意力,混合机制在保持节奏对齐(F1分数从45.62提升到70.08)和音频质量方面更优。
- 内容对齐器:一个简单的、基于最近邻的时间对齐方法,解决了MIDI网格与音频潜变量不同时间分辨率的问题。
💡 核心创新点
- 首创“MIDI-to-Drum”可控音频合成任务与模型:明确提出了从鼓MIDI生成音频,并可控参考音色的任务,填补了该垂直领域的研究空白。之前的相关工作主要集中在钢琴等调性乐器或文本到音乐生成。
- 设计有效的双输入内容编码器与混合条件机制:提出了一种专门融合MIDI节奏信息与参考音频音色信息的编码方式,并通过实验证明了将多种条件注入方式(拼接、相加、前缀)结合,比单一机制(如仅交叉注意力)能更好地平衡音频质量与节奏精度。
- 构建配对训练数据集与评估框架:针对没有现成数据集的问题,通过配对同一鼓组不同演奏的音频(目标与参考)来构建训练对。同时,提出了涵盖音频质量、节奏对齐和节拍连续性的综合评估框架。
🔬 细节详述
- 训练数据:
- 数据集:使用 Groove MIDI Dataset (GMD) 的两个衍生版本:Expanded Groove MIDI Dataset (E-GMD,包含43种鼓组预设的混合音频) 和 StemGMD (包含10种鼓组预设的独立鼓轨)。
- 预处理:从每个音频-MIDI对中提取2小节(8个四分音符)片段,总时长约76.68小时。
- 数据构建:为每个目标音频构建一个参考音频,要求使用相同鼓组但不同MIDI序列。训练数据包含完整混音和独立音轨。数据集划分确保验证/测试集使用未见过的鼓组。
- 规模:最终训练对62,595对,验证对1,202对,测试对791对。
- 损失函数:使用v-objective扩散损失,公式为
L(θ; zt, t | Y) = ∥vθ(zt, Y) - (αt z1 - σt z0)∥²,其中Y是所有条件集。同时采用分类器无关引导(classifier-free guidance),以10%的概率将xref置空。 - 训练策略:
- 课程学习:目标条件输入从100% “编排”表示开始,逐渐线性过渡到50% “编排”和50% “敲击”。参考条件的输入从50/50的“编排/敲击”混合开始,逐渐过渡到仅使用“敲击”。这模拟了实际场景中参考音频可能没有对应MIDI的情况。
- 优化器与调度:AdamW优化器,学习率1e-4,使用InverseLR调度器。
- 训练轮次与硬件:在8个H100 GPU上训练50个epoch,batch size为4/GPU。
- 关键超参数:
- MIDI分辨率:实验了16th, 32nd, 64th音符网格,最终采用64th音符(T=128)。
- 模型大小:基于SAO的24层DiT;内容编码器为4层Transformer。
- VAE压缩率:2048倍。
- 音频采样率:44.1kHz,立体声。
- 推理细节:使用DPM-Solver++采样器,采样步数为10步。
📊 实验结果
论文在构建的测试集上进行了全面的实验评估,主要结果如下表所示。
表1:MIDI表示时间分辨率的影响
| 时序分辨率 | 音频质量 (FADV GG↓) | 音频质量 (FADCLAP↓) | 对齐 (F1↑) | 对齐 (RMS Err.↓) | 节拍连续性 (CMLt↑) | 节拍连续性 (AMLt↑) |
|---|---|---|---|---|---|---|
| 16th | 0.14 | 0.071 | 58.33 | 13.55 | 0.34 | 0.44 |
| 32nd | 0.11 | 0.065 | 64.12 | 12.24 | 0.39 | 0.49 |
| 64th | 0.09 | 0.061 | 70.08 | 10.53 | 0.42 | 0.51 |
表2:对不同节奏和乐器模式的分析
| 数据集 | 输入编排类型 | FADV GG↓ | FADCLAP↓ | F1↑ | RMS Err.↓ | CMLt↑ | AMLt↑ |
|---|---|---|---|---|---|---|---|
| EGMD | Beat + Fill | 0.18 | 0.072 | 60.91 | 13.32 | 0.43 | 0.62 |
| Beat | 0.28 | 0.089 | 57.05 | 12.89 | 0.45 | 0.69 | |
| Fill | 0.20 | 0.093 | 65.31 | 13.84 | 0.42 | 0.54 | |
| StemGMD | Beat + Fill | 0.10 | 0.073 | 73.74 | 9.42 | 0.41 | 0.47 |
| Beat | 0.15 | 0.085 | 74.82 | 9.55 | 0.43 | 0.49 | |
| Fill | 0.07 | 0.079 | 72.08 | 9.22 | 0.38 | 0.43 |
表3:条件机制和输入的影响(64音符分辨率)
| 方法 | 输入MIDI类型 | 参考MIDI类型 | FADV GG↓ | FADCLAP↓ | F1↑ | RMS Err.↓ | CMLt↑ | AMLt↑ |
|---|---|---|---|---|---|---|---|---|
| Proposed | Arrangement | GT Tap | 0.09 | 0.061 | 70.08 | 10.53 | 0.42 | 0.51 |
| Arrangement | Pseudo Tap | 0.10 | 0.063 | 70.66 | 10.61 | 0.41 | 0.51 | |
| Tap | GT Tap | 0.12 | 0.070 | 68.65 | 11.20 | 0.40 | 0.51 | |
| Proposed (from scratch) | Arrangement | GT Tap | 22.34 | 1.78 | 13.34 | 134.53 | 0.04 | 0.07 |
| Cross-attention | Arrangement | GT Tap | 0.12 | 0.067 | 45.62 | 17.25 | 0.24 | 0.35 |
| w/o reference context | - | - | 0.13 | 0.064 | 70.74 | 9.63 | 0.43 | 0.52 |
| Proposed | Random | GT Tap | 0.83 | 0.256 | 17.73 | 68.44 | 0.05 | 0.13 |
| w/o reference context | - | - | 1.43 | 0.339 | 19.41 | 66.60 | 0.06 | 0.13 |
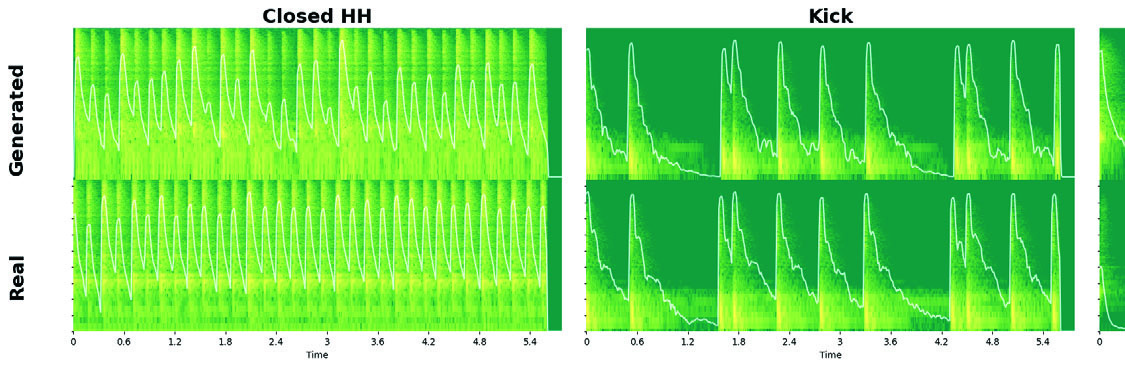 图2展示了模型成功按照多乐器编排(Arrangement)MIDI,合成了单个乐器(如底鼓、军鼓)的音频,并与真实音频在波形和频谱上高度相似,验证了模型对节奏和音色的控制能力。
图2展示了模型成功按照多乐器编排(Arrangement)MIDI,合成了单个乐器(如底鼓、军鼓)的音频,并与真实音频在波形和频谱上高度相似,验证了模型对节奏和音色的控制能力。
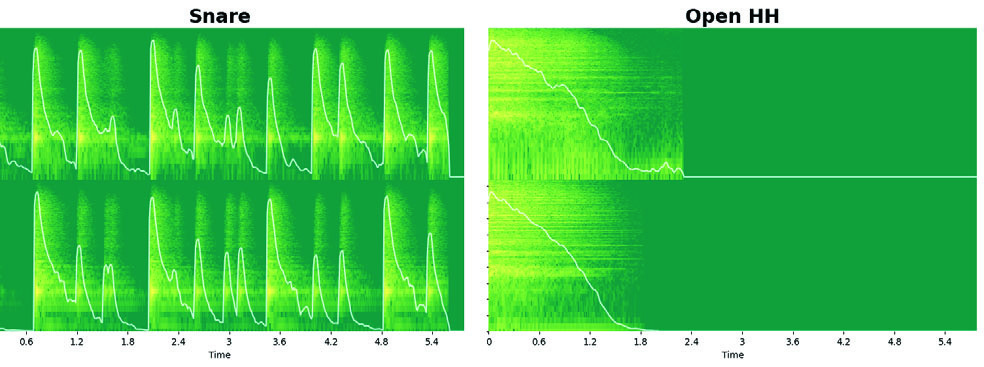 图3展示了模型处理不同类型输入的能力。左侧是2小节的“Beat”(重复节奏型),右侧是1小节的“Fill”(过门)。模型生成的音频在时域波形和频谱上都与真实音频一致,且下方的MIDI表示清晰展示了输入的节奏结构。
图3展示了模型处理不同类型输入的能力。左侧是2小节的“Beat”(重复节奏型),右侧是1小节的“Fill”(过门)。模型生成的音频在时域波形和频谱上都与真实音频一致,且下方的MIDI表示清晰展示了输入的节奏结构。
关键结论:
- 更高的MIDI时间分辨率(64th音符)在所有指标上带来一致提升。
- 模型在处理“Beat”和“Fill”模式上表现均衡。在StemGMD(单乐器)上的对齐指标(F1约74%)显著优于E-GMD(混音,F1约65-70%),表明清晰的单声道信号更容易合成。
- 使用检测到的伪标签“Tap”代替真实“Tap”作为参考条件,性能下降很小,表明模型具有良好的泛化性。
- 从头训练DiT性能极差,证明了预训练模型的重要性。
- 仅使用交叉注意力进行条件化的变体在节奏对齐上严重劣化(F1从70.08降至45.62),验证了混合条件机制的有效性。
- 当随机输入MIDI时,模型各项指标急剧下降(F1从70.08降至17.73),作为性能下界。
⚖️ 评分理由
- 学术质量:6.0/7:论文的创新点清晰且填补空白,技术方案设计合理并有充分的实验验证(消融实验、分辨率分析、不同模式分析)。主要不足在于缺少与同领域(如音乐生成、可控音频生成)更强大基线模型的定量比较,使得“SOTA”声明缺乏直接证据。
- 选题价值:1.5/2:针对数字音乐制作中的一个具体、高价值需求提出解决方案,应用前景明确。虽然任务相对垂直,但对目标用户(音乐制作人)和相关研究方向(可控音频合成)有明确价值。
- 开源与复现加成:0.3/1:提供了Demo页面,且明确依赖SAO的预训练模型。但未开源本项目的代码、微调后的权重、构建的配对数据集,也未给出完整的超参数配置文件,阻碍了社区的完全复现。