📄 Brainprint-Modulated Target Speaker Extraction
#语音分离 #语音增强 #多任务学习 #多模态模型 #鲁棒性
🔥 8.0/10 | 前25% | #语音分离 | #多任务学习 | #语音增强 #多模态模型
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Qiushi Han(南京邮电大学电子与光学工程学院 & 柔性电子(未来技术)学院)
- 通讯作者:Liya Huang(南京邮电大学电子与光学工程学院 & 柔性电子(未来技术)学院)
- 作者列表:
- Qiushi Han(南京邮电大学电子与光学工程学院 & 柔性电子(未来技术)学院)(†共同第一作者)
- Yuan Liao(香港中文大学(深圳)人工智能与数据科学学院 & 研究生院)(†共同第一作者)
- Youhao Si(南京邮电大学电子与光学工程学院 & 柔性电子(未来技术)学院)
- Liya Huang(南京邮电大学电子与光学工程学院 & 柔性电子(未来技术)学院)(⋆通讯作者)
💡 毒舌点评
本文最大的亮点在于“脑印调制”这一概念的提出,巧妙地将通常被视为噪声的个体EEG差异转化为可用的生物特征信号来指导音频分离,思路新颖且实验验证充分。不过,论文的短板在于对“个性化”的论证稍显单一,主要依赖于SID和AAD任务的监督,缺乏对脑印嵌入空间本身可解释性、跨会话稳定性以及在真实助听器设备上实时性、功耗等方面的深入讨论,使得这项工作的工程化前景存在不确定性。
🔗 开源详情
- 代码:论文中提供了GitHub代码仓库链接:https://github.com/rosshan-orz/BM-TSE。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:评估使用的是公开的KUL和Cocktail Party数据集,论文中提供了数据集的引用。
- Demo:论文中未提及在线演示。
- 复现材料:论文在“实现细节”部分提供了较为详细的训练配置(优化器、学习率、调度器、Batch Size、轮数、硬件),并建议参考GitHub仓库获取更多细节。
- 论文中引用的开源项目:论文在方法部分引用了TasNet [15]和Sandglasset [16]作为其音频编码和分离网络的基础组件。
📌 核心摘要
- 要解决的问题:当前基于脑电图(EEG)的目标说话人提取(TSE)系统面临两个核心挑战:EEG信号的非平稳性导致跨会话性能不稳定,以及显著的个体间差异限制了通用模型的泛化能力。
- 方法核心:本文提出了脑印调制目标说话人提取(BM-TSE)框架。该框架首先使用一个带有自适应频谱增益(ASG)模块的时空EEG编码器,从非平稳信号中提取稳定特征。其核心是一个“个性化脑印调制”机制:通过联合优化说话人识别(SID)和听觉注意解码(AAD)任务,学习一个统一的“脑图”嵌入(brainmap embedding),该嵌入同时编码用户的静态身份和动态注意状态,并用它主动调制和优化音频分离过程,实现个性化输出。
- 与已有方法相比新在哪里:传统TSE方法通常将EEG中的身份特异性信息视为需要抑制的统计噪声。BM-TSE则创新地利用这些“脑印”信息,将其作为个性化的调制信号,直接作用于语音分离网络,从“被动解码注意力”转向“主动利用身份特征进行定制化增强”。
- 主要实验结果:在KUL和Cocktail Party两个公开数据集上的实验表明,BM-TSE在语音质量(SI-SDR)和可懂度(STOI, ESTOI)上均达到了当前最优(SOTA)。例如,在Cocktail Party数据集上,BM-TSE的SI-SDR为14.02 dB,优于之前的SOTA方法MSFNet(12.89 dB)。消融研究证实了LS-TConv、ASG、SConv模块以及LSID损失的关键作用。
- 实际意义:该研究为开发新一代真正个性化、高保真的神经调制助听设备提供了有力的技术路径,证明了将用户独特的神经特征融入核心音频处理管线的巨大潜力。
- 主要局限性:论文未深入探讨该框架在真实实时助听器设备上的计算复杂度、功耗及延迟;对于脑印嵌入在更长时间跨度(如数月或数年)下的稳定性验证不足;此外,实验数据集均为健康被试在实验室环境下录制,模型在听力损失患者及真实嘈杂场景中的泛化能力有待进一步验证。
🏗️ 模型架构
BM-TSE是一个端到端的多模态(EEG+音频)系统,整体架构如图1所示。
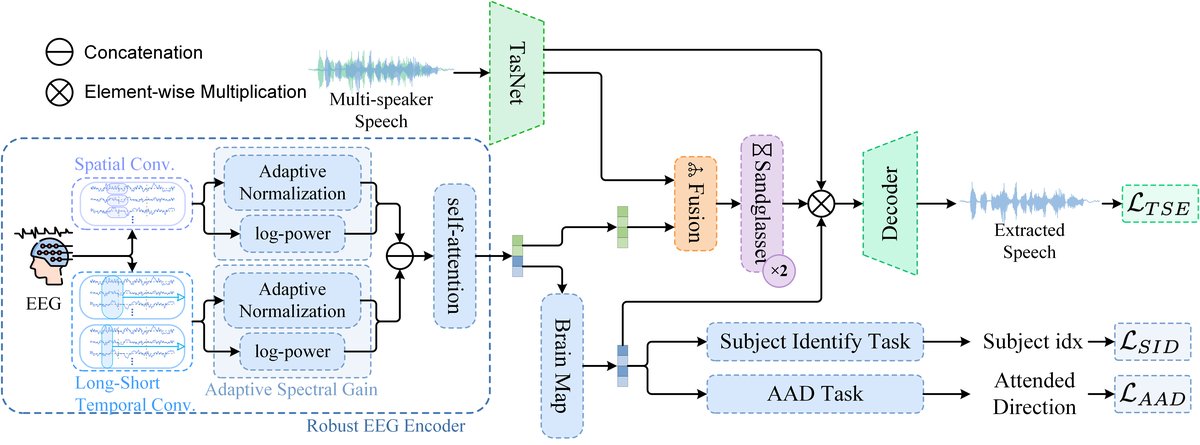
完整输入输出流程:
- 输入:原始EEG信号(B×C×T)和混合多人语音波形。
- 处理:
- EEG信号经过“鲁棒EEG编码器”处理,输出一个统一的特征嵌入E。
- 语音波形经过TasNet音频编码器,输出音频特征。
- 音频特征与对齐后的EEG特征E在“Sandglasset”分离网络中进行多粒度自注意力处理,得到中间分离特征A。
- 同时,EEG特征E经过一个“个性化脑印模块”处理,生成“脑图”嵌入(brainmap)。
- 核心创新步骤:利用“脑图”嵌入对中间特征A进行个性化调制,得到优化后的特征A_refined(公式5:
A_refined = (T(E) + P(brainmap)) ⊙ A)。 - A_refined经过“重建器”重建为目标说话人的时域波形。
- 输出:提取出的目标说话人语音波形。
主要组件详解:
- 鲁棒EEG编码器:核心是解决EEG非平稳性。
- 双分支时空特征提取:
- 长短期时间卷积(LS-TConv)分支:捕捉EEG的时间动态,输出特征E_temp。
- 空��卷积(SConv)分支:捕捉EEG的地形(通道间)拓扑特征,输出特征E_spat。
- 自适应频谱增益(ASG)模块:分别增强上述两种特征。ASG模块内部包含:
L(·): 对数功率块,通过log(Pool(E²+ϵ))捕捉非线性能量模式,放大稳定的个体间差异。A(·): 自适应归一化块,基于可学习门控的Group Normalization,稳定特征分布。公式为A(E_in) = E_in ⊙ σ(Ws ⊙ GN(E_in) + bs)。- 最终ASG输出为两者拼接:
ASG(E_in) = Concat(A(E_in), L(E_in))。
- 跨域融合:为增强后的E_temp和E_spat添加可学习的位置编码,沿序列维度拼接后,通过一个自注意力层学习跨时/空域的依赖关系,生成最终EEG嵌入E。
- 双分支时空特征提取:
- 脑印调制机制:
- 个性化脑印模块:一个由残差卷积块组成的轻量网络,以EEG嵌入E为输入,生成“脑图”嵌入。该模块受到SID(识别用户)和AAD(识别注意力)两个辅助分类任务的联合监督。
- 调制层:将脑图嵌入与EEG特征E(经投影层T(·)对齐)相加后,与中间语音特征A进行逐元素乘法(⊙),完成个性化的、动态的特征精炼。
- 分离网络:采用Sandglasset架构,其“沙漏形”多粒度自注意力结构,能够建模从音素到单词等不同时间尺度的上下文,对语音分离至关重要。
💡 核心创新点
- 提出“脑印调制”范式:首次提出将EEG信号中编码的个人身份特征(脑印)和动态注意状态,从传统方法中需要抑制的“变异”,转变为主动利用的“个性化调制信号”,用于直接指导和优化音频分离过程。这是概念上的重大创新。
- 设计统一的脑图嵌入(Brainmap Embedding):通过设计一个同时受到SID(静态身份)和AAD(动态注意)任务监督的轻量级神经网络,学习一个能够统一编码这两种关键信息的紧凑表示。这种多任务监督确保了脑图嵌入的丰富性和区分性。
- 提出鲁棒的时空EEG编码器与ASG模块:针对EEG的非平稳性,明确设计了包含LS-TConv、SConv的双分支结构来分别捕获时间与空间特征,并创新性地引入ASG模块。ASG通过结合对数功率(非线性能量)和自适应归一化(分布稳定化),有效提升了特征的跨会话稳定性和辨别力。
🔬 细节详述
- 训练数据:
- 数据集:KUL数据集(16名被试,64导EEG,8196Hz)和Cocktail Party数据集(33名被试)。
- 预处理:带通滤波(0.1-45 Hz),去工频干扰(KUL),下采样至128 Hz(KUL),异常通道校正(Cocktail Party),重参考,独立成分分析(ICA)去除眼动/肌电伪迹。
- 数据划分:将两个数据集混合后,按75:12.5:12.5的比例随机划分为训练、验证和测试集。
- 损失函数:采用多任务复合损失
L_total = L_TSE + αL_SID + βL_AAD。- 高保真TSE损失(L_TSE):加权求和三个分量:
L_TSE = w₁L_MSE + w₂L_STFT + w₃*L_SI-SDR。分别对应时域均方误差、频域STFT幅度损失和尺度不变信噪比损失。 - 脑印监督损失(L_SID, L_AAD):均为标准的交叉熵(CE)损失,用于分类任务。
- 高保真TSE损失(L_TSE):加权求和三个分量:
- 训练策略:
- 优化器:Adam,初始学习率1e-4。
- 调度器:StepLR,每轮衰减0.9。
- 训练轮数:100轮。
- 批量大小:8。
- 模型选择:在验证集上基于SI-SDRi指标保存最佳模型。
- 关键超参数:超参数α、β(任务损失权重)和w₁, w₂, w₃(TSE损失分量权重)的具体数值未在论文正文中说明。
- 训练硬件:NVIDIA 4090 GPU。
- 推理细节:论文中未提及特定的推理优化策略(如流式处理、量化等),应为标准的前向传播。
- 正则化技巧:模型架构中使用了残差连接(脑印模块)。其他如Dropout等未明确提及。
📊 实验结果
主要基准测试结果:
表1: 在Cocktail Party数据集上的性能对比
| 模型 | SI-SDR (dB) | STOI | ESTOI | PESQ |
|---|---|---|---|---|
| Mixture (基线) | 0.45 | 0.71 | 0.55 | 1.61 |
| UBESD [8] | 8.54 | 0.83 | – | 1.97 |
| BASEN [9] | 11.56 | 0.86 | 0.72 | 2.21 |
| MSFNet [11] | 12.89 | 0.88 | 0.77 | 2.51 |
| BM-TSE (Ours) | 14.02 | 0.90 | 0.77 | 2.47 |
表2: 在KUL数据集上的性能对比
| 模型 | SI-SDR (dB) | STOI | ESTOI | PESQ |
|---|---|---|---|---|
| Mixture (基线) | 0.25 | 0.69 | 0.52 | 1.17 |
| UBESD [8] | 6.1 | 0.73 | 0.75 | 1.09 |
| BASEN [9] | 11.5 | 0.82 | 0.76 | 1.76 |
| MSFNet [11] | 14.6 | 0.83 | 0.76 | 2.12 |
| BM-TSE (Ours) | 15.92 | 0.85 | 0.77 | 2.10 |
关键结论:BM-TSE在两个数据集上的SI-SDR、STOI和ESTOI指标上均达到最优。在Cocktail Party数据集上,SI-SDR比次优的MSFNet高出1.13 dB;在KUL数据集上,SI-SDR高出1.32 dB。PESQ指标上MSFNet略高,但论文指出BM-TSE在整体语音质量和可懂度上占优。
消融实验结果:
表3: 关键模块消融实验分析(在Cocktail Party数据集上)
| 模型变体 | SI-SDRi (dB) | STOI | ESTOI | PESQ |
|---|---|---|---|---|
| BM-TSE (Full) | 14.50 | 0.90 | 0.77 | 2.47 |
| w/o LS-TConv | 2.88 | 0.72 | 0.54 | 1.70 |
| w/o SConv | 13.61 | 0.88 | 0.74 | 2.37 |
| w/o ASG | 13.13 | 0.88 | 0.74 | 2.39 |
| w/o L_SID | 12.29 | 0.87 | 0.72 | 2.26 |
关键结论:移除LS-TConv导致性能崩溃(SI-SDRi下降超过11 dB),证明其不可或缺。移除SConv、ASG或L_SID均导致显著但相对较小的性能下降,验证了各组件的重要性。
可视化分析:图2通过梅尔频谱图对比,直观展示了不同消融变体生成的音频质量差异。
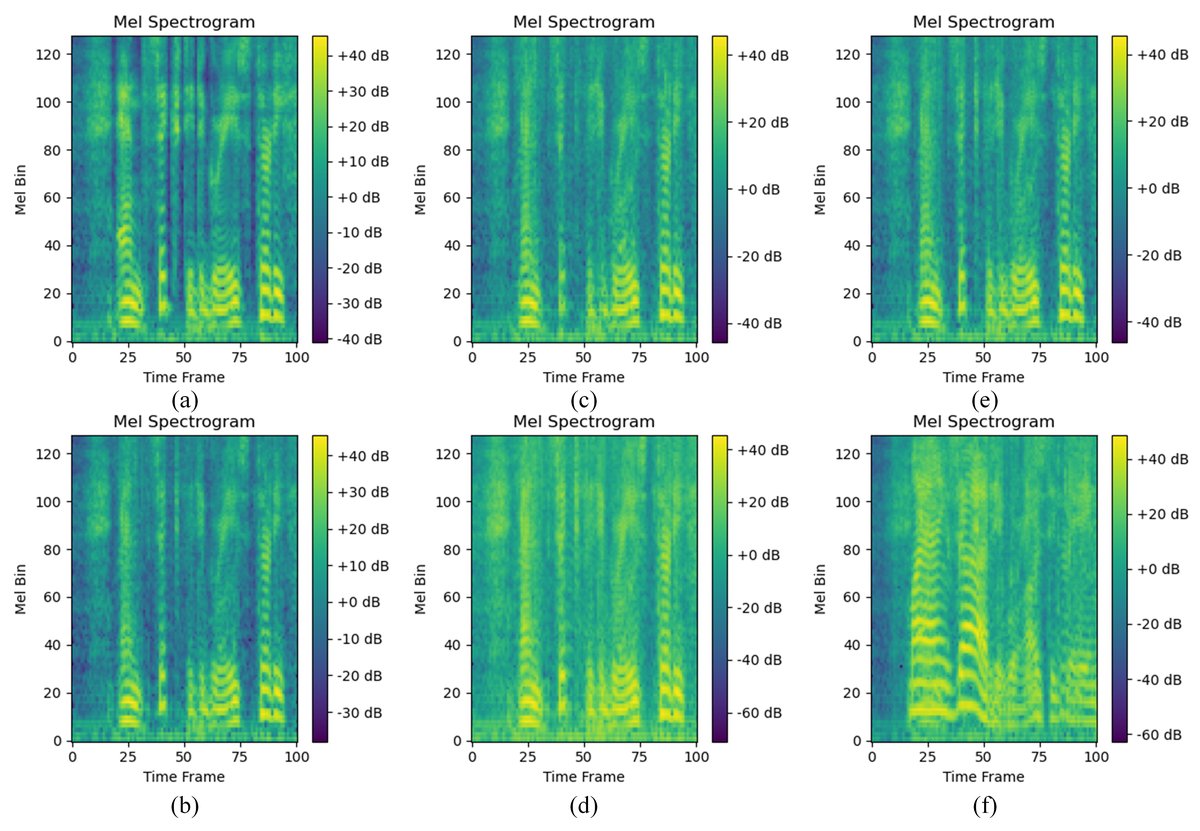 关键结论:(a)干净语音为基准;(b)完整模型重建质量高;(c)移除ASG导致高频细节丢失;(d)移除L_SID引入频谱失真;(e)移除SConv导致斑块状伪影;(f)移除LS-TConv模糊了时间动态。这从听觉感知层面佐证了各模块的必要性。
关键结论:(a)干净语音为基准;(b)完整模型重建质量高;(c)移除ASG导致高频细节丢失;(d)移除L_SID引入频谱失真;(e)移除SConv导致斑块状伪影;(f)移除LS-TConv模糊了时间动态。这从听觉感知层面佐证了各模块的必要性。
⚖️ 评分理由
- 学术质量:6.0/7:创新性很强,“脑印调制”是一个新颖且有潜力的概念。技术实现路径完整,从EEG编码到多任务学习框架设计合理。实验部分非常充分,包括与SOTA的对比和细致的消融研究,结果可信度高。扣分点在于缺乏对模型在更复杂、更现实场景下的验证,以及对脑印嵌入更深的分析。
- 选题价值:1.5/2:研究聚焦于个性化神经语音提取,对于助听器、脑机接口等应用有明确的前沿性和潜在价值。选题较为垂直,受众面相对有限,但解决的问题重要且具体。
- 开源与复现加成:0.5/1:论文提供了公开的GitHub代码仓库链接,并在实现细节部分给出了超参数、优化器、调度器、硬件等关键复现信息,透明度较高,降低了复现门槛。扣分点在于未明确说明是否提供预训练模型权重,这在一定程度上影响了“开箱即用”的复现体验。