📄 Bone-Conduction Guided Multimodal Speech Enhancement with Conditional Diffusion Models
#语音增强 #扩散模型 #骨传导 #多模态模型
✅ 7.5/10 | 前25% | #语音增强 | #扩散模型 | #骨传导 #多模态模型
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Sina Khanagha(汉堡大学信号处理组)
- 通讯作者:未说明
- 作者列表:Sina Khanagha(汉堡大学信号处理组)、Bunlong Lay(汉堡大学信号处理组)、Timo Gerkmann(汉堡大学信号处理组)
💡 毒舌点评
本文的亮点在于将扩散模型这一强大的生成范式引入骨传导引导的多模态语音增强任务,并通过设计精巧的条件注入策略(IC/DC),在极低信噪比下实现了显著的性能飞跃(例如在-10dB SNR下POLQA提升超过1分)。然而,其核心短板在于扩散模型固有的多步迭代采样带来的推理速度瓶颈(论文仅简要提及需要数十步,未量化延迟),这使其在助听器、实时通信等需要低延迟的应用场景中面临严峻挑战,论文对此缺乏深入探讨和解决方案。
🔗 开源详情
- 代码:提供了GitHub代码仓库链接:https://github.com/sp-uhh/bcdm
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用了公开数据集ABCS(用于骨传导与空气传导语音)和CHiME3(用于噪声)。论文未说明其是否有独家数据。
- Demo:论文中未提及在线演示。
- 复现材料:提供了详尽的训练细节(数据集划分、预处理、优化器、学习率、Batch Size、EMA设置)、模型架构描述(包括IC/DC两种策略的细节)以及关键超参数(如σ范围、扩散步数)。未提供详细的训练脚本或配置文件。
- 论文中引用的开源项目:依赖NCSN++作为主干网络,并引用了其代码。条件编码器部分参考了BigGAN的残差块。
📌 核心摘要
问题:传统单通道语音增强模型在极端噪声环境(低信噪比)下性能严重下降。虽然骨传导信号(通过颅骨振动采集)对声学噪声免疫,但其带宽有限、清晰度差,如何有效融合这两种互补模态是一个挑战。
方法核心:提出了骨传导条件扩散模型(BCDM),一个基于复数域条件扩散模型的多模态语音增强框架。模型将干净语音作为生成目标,以带噪的空气传导语音为条件引导扩散过程,并创新性地引入骨传导信号作为额外条件。论文比较了两种将骨传导信号注入主网络的条件化策略:输入拼接(IC) 和 解码器条件化(DC)。
创新点:首次将条件扩散模型框架应用于骨传导引导的语音增强;提出了IC和DC两种有效的跨模态条件注入方法;在广泛的声学条件(SNR从-10dB到15dB)下进行了全面实验验证。
实验结果:在ABCS+CHiME3数据集上,所有BCDM变体在所有SNR条件下均优于基线模型(包括单模态扩散模型SGMSE+和多种多模态预测模型)。例如,在极具挑战性的-10dB SNR下,BCDM-DC-L的POLQA分数为2.37±0.45,而最强基线BiNet为2.35±0.40,SGMSE+仅为1.30±0.35。关键对比数据见下表。
模型 SNR=-10dB POLQA SNR=-10dB PESQ SNR=-10dB ESTOI SNR=5dB POLQA SNR=15dB POLQA Noisy Mixture 1.09 1.08 0.21 1.55 2.42 SGMSE+ 1.30 1.15 0.36 2.83 3.55 BiNet 2.35 1.80 0.63 2.62 2.78 BCDM-IC-S 2.36 1.86 0.75 3.00 3.53 BCDM-DC-L 2.44 2.02 0.76 3.20 3.70 实际意义:为助听器、可穿戴通信设备等在极端嘈杂环境下(如工厂、战场)保持清晰语音通信提供了新的技术路径,证明了多模态生成模型的潜力。
主要局限性:(1)扩散模型推理需要多步采样(论文实验中N=60),计算成本高,延迟大,与预测模型的单次前向传播相比在实时性上处于劣势。(2)依赖额外的骨传导传感器,增加了硬件成本和佩戴负担,论文未讨论传感器噪声、校准等实际部署问题。
🏗️ 模型架构
模型整体流程:BCDM是一个条件扩散模型,其核心是一个评分网络(Score Network) \( s_\theta(x_t, y, y_c, t) \)。在训练时,网络学习估计扩散过程在时间步\( t \)的状态\( x_t \)的梯度(分数),条件是干净语音\( x_0 \)(通过前向过程加噪得到\( x_t \))、带噪空气传导语音\( y \)和骨传导语音\( y_c \)。在推理时,从纯噪声或带噪语音出发,利用训练好的网络估计分数,通过求解反向随机微分方程(SDE)逐步去噪,生成干净语音。
主干网络:采用基于NCSN++的多分辨率U-Net架构。论文测试了两种大小配置:大型(-L)和小型(-S),主要区别在于特征图数量和残差块深度。
条件化策略(核心创新):论文提出了两种将骨传导信号\( y_c \)融入评分网络的方法,如图1所示。
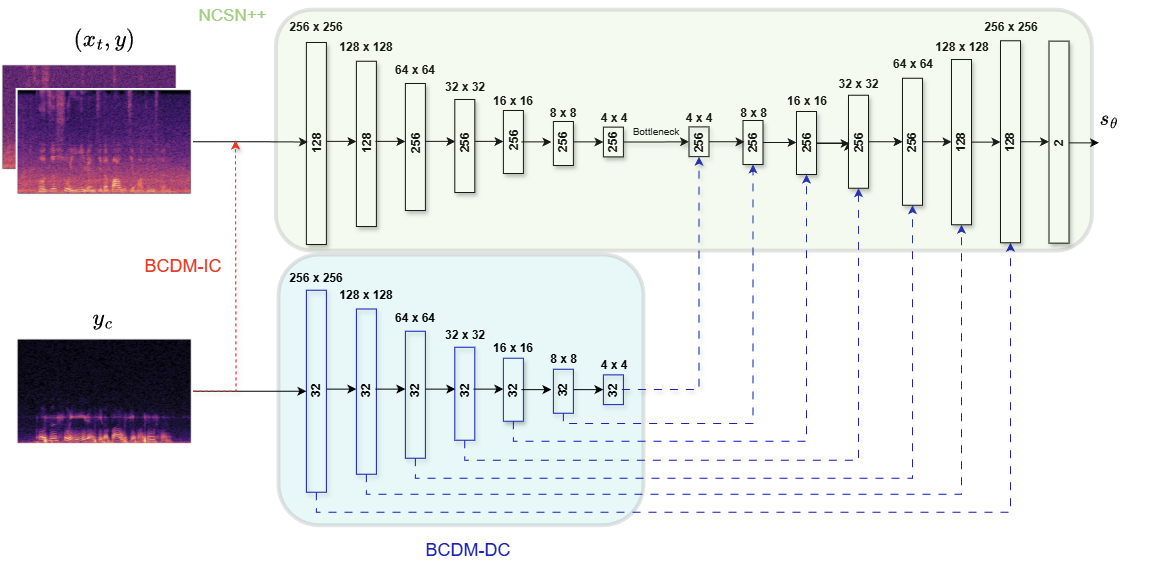
- 输入拼接(IC, BCDM-IC):最直接的方法。将时间对齐的骨传导语音频谱图、带噪空气传导语音频谱图以及当前扩散状态频谱图在通道维度进行拼接,然后一同输入到共享的U-Net编码器中。优点是结构简单,参数增量少。
- 解码器条件化(DC, BCDM-DC):更精细的方法。为骨传导信号设计一个独立的条件编码器。��编码器由基于BigGAN的残差块构成,并受扩散时间步条件调制。其输出的特征图在U-Net解码器的各个上采样层,通过跳跃连接注入到主干网络中。注入后,会与主干特征和跳跃连接特征拼接,再通过1x1卷积降维以匹配原网络通道数。这种方法能更独立地提取骨传导特征,并实现多尺度条件注入。
输入输出:输入为复数STFT表示(256频率 bin × 256帧)。输出是估计的分数向量,维度与输入一致。最终生成的是复数域干净语音频谱图。
💡 核心创新点
- 首次将条件扩散模型框架应用于骨传导引导的语音增强。将此任务重新定义为以带噪语音和骨传导语音为条件的生成问题,利用了扩散模型在复杂条件生成上的强大能力。
- 提出并比较了两种针对异构传感器数据的条件注入策略(IC与DC)。IC策略验证了简单融合的可行性;DC策略通过独立编码器和多尺度注入,为模型提供了更灵活的跨模态特征交互方式,实验表明其在指标上略有优势。
- 在极低信噪比条件下取得了显著且一致的性能提升。实验证明,BCDM在所有测试SNR下均优于强基线,尤其在-10dB等极端噪声环境下,优势明显(如POLQA比最强多模态基线BiNet高0.09-0.81),验证了该框架的有效性。
- 系统分析了扩散步数(N)对性能的影响。通过图2展示了BCDM性能随采样步数增加而提升,并指出DC策略需要更多步数达到峰值,而IC策略收敛更快。这为实际部署中性能与速度的权衡提供了参考。
🔬 细节详述
- 训练数据:
- 数据集:ABCS数据集(42小时,100位中文说话人,包含时间对齐的空气传导与骨传导语音)。
- 噪声数据:CHiME3数据集,用于生成带噪空气传导语音。
- 训练SNR:从-5dB到20dB均匀采样。
- 预处理:复数STFT,窗口长度510,帧移128,得到256个频率bin。截取256帧,形成256x256的输入。
- 损失函数:论文中未明确写出具体损失函数名称,但指出训练目标是分数匹配目标(公式6):\( \mathbb{E}[\|s_\theta(x_t, y, y_c, t) - \nabla_{x_t} \log p_{0t}(x_t | x_0, y)\|^2_2] \)。即训练网络去预测理论分数值。
- 训练策略:
- 优化器:Adam。
- 学习率:\( 10^{-4} \)。
- Batch Size:8。
- 训练细节:使用指数移动平均(EMA),衰减率为0.999。
- 关键超参数:
- 扩散步数(推理时):N=60。
- 噪声调度参数:\( \sigma_{\min} = 0.05 \),\( \sigma_{\max} = 0.5 \)。
- 模型大小:表格中给出了参数量,例如BCDM-DC-L为67.4M。
- 训练硬件:未说明。
- 推理细节:
- 解码策略:使用预测-校正(PC)采样策略求解反向SDE。
- 每个时间步包含2次分数函数调用(一次预测,一次校正)。
- 正则化技巧:未明确提及除EMA外的其他技巧。
📊 实验结果
主要Benchmark与指标:
- 数据集:ABCS + CHiME3构建的测试集。
- 指标:POLQA(客观感知语音质量评估,分值越高越好)、PESQ(感知语音质量评估)、ESTOI(扩展短时客观可懂度)。
主要对比结果: 下表完整列出了论文Table 1的核心对比数据,展示了不同模型在不同信噪比下的性能。BCDM(尤其是DC-L变体)在所有条件下均取得最佳结果。
| 模型 (参数量) | SNR (dB) | POLQA | PESQ | ESTOI |
|---|---|---|---|---|
| Noisy Mixture | -10 | 1.09 ± 0.07 | 1.08 ± 0.21 | 0.21 ± 0.11 |
| SGMSE+* (65.6M) | -10 | 1.30 ± 0.35 | 1.15 ± 0.17 | 0.36 ± 0.19 |
| FCN-LF (0.26M) | -10 | 1.33 ± 0.25 | 1.08 ± 0.06 | 0.38 ± 0.12 |
| DCCRN (13.8M) | -10 | 1.93 ± 0.38 | 1.40 ± 0.20 | 0.63 ± 0.09 |
| BiNet (27.3M) | -10 | 2.35 ± 0.40 | 1.80 ± 0.26 | 0.70 ± 0.08 |
| BCDM-IC-S (11.7M) | -10 | 2.36 ± 0.45 | 1.86 ± 0.39 | 0.75 ± 0.08 |
| BCDM-DC-S (12.3M) | -10 | 2.31 ± 0.48 | 1.92 ± 0.38 | 0.74 ± 0.08 |
| BCDM-IC-L (65.6M) | -10 | 2.37 ± 0.45 | 1.95 ± 0.36 | 0.76 ± 0.08 |
| BCDM-DC-L (67.4M) | -10 | 2.44 ± 0.46 | 2.02 ± 0.40 | 0.76 ± 0.08 |
| Noisy Mixture | 5 | 1.55 ± 0.40 | 1.17 ± 0.12 | 0.65 ± 0.12 |
| SGMSE+* (65.6M) | 5 | 2.83 ± 0.50 | 2.30 ± 0.47 | 0.85 ± 0.07 |
| BiNet (27.3M) | 5 | 2.62 ± 0.43 | 2.14 ± 0.35 | 0.80 ± 0.06 |
| BCDM-DC-L (67.4M) | 5 | 3.20 ± 0.50 | 2.74 ± 0.49 | 0.87 ± 0.06 |
| Noisy Mixture | 15 | 2.42 ± 0.53 | 1.74 ± 0.33 | 0.87 ± 0.07 |
| SGMSE+* (65.6M) | 15 | 3.55 ± 0.44 | 3.08 ± 0.41 | 0.94 ± 0.04 |
| BiNet (27.3M) | 15 | 2.78 ± 0.46 | 2.30 ± 0.38 | 0.84 ± 0.05 |
| BCDM-IC-S (11.7M) | 15 | 3.53 ± 0.49 | 3.08 ± 0.47 | 0.93 ± 0.04 |
| BCDM-DC-L (67.4M) | 15 | 3.70 ± 0.45 | 3.25 ± 0.43 | 0.94 ± 0.04 |
关键发现:
- BCDM在所有SNR下全面超越基线。在极低SNR(-10dB)下,BCDM-DC-L的PESQ比BiNet高0.22,比SGMSE+高0.87。
- 在较高SNR(15dB)下,BCDM仍能保持优势,而BiNet等多模态基线优势减弱甚至不如单模态SGMSE+。
- BCDM的小模型(
-S,~12M参数)性能与参数量相近的BiNet(27.3M)相当甚至更优,而BCDM的大模型(-L,~66M参数)与参数量相近的单模态SGMSE+(65.6M)相比,在POLQA和PESQ上仍有明显优势。 - DC策略在绝对指标上略优于IC策略,但IC策略的收敛速度更快(见图2)。
图表分析: 图2(论文中Fig. 2)展示了在-5dB SNR下,BCDM的小模型(IC-S和DC-S)的PESQ分数随扩散步数N变化的曲线。图中同时绘制了基线模型BiNet和DCCRN的固定性能线(因为它们是预测模型,无需采样步数)。结论是:BCDM-IC-S约在N=10步时超越DCCRN,N=20步时超越BiNet并接近其峰值性能;BCDM-DC-S需要更多步数达到相似性能。
⚖️ 评分理由
- 学术质量:6.5/7:论文工作扎实,创新点明确(首次应用扩散模型于此任务、两种条件策略),理论推导清晰(SDE框架),实验对比全面且结果显著。主要扣分在于对扩散模型推理延迟这一关键缺陷讨论不足,且未在更广泛的任务(如带噪语音识别)上验证增强后语音的实用性。
- 选题价值:1.0/2:选题位于语音增强的前沿交叉领域,具有明确的技术价值(利用物理传感免疫噪声)。但骨传导传感器的普及度和佩戴便利性限制了其应用广度,且实时性问题可能阻碍其在消费级产品中的快速落地。
- 开源与复现加成:0.5/1:提供了明确的代码仓库链接(
github.com/sp-uhh/bcdm),训练数据集(ABCS)和噪声数据集(CHiME3)均为公开数据集,关键训练超参数和模型配置描述清晰,可复现性强。未提供预训练模型权重,因此给予中等加分。