📄 Bloodroot: When Watermarking Turns Poisonous for Stealthy Backdoor
#音频安全 #水印 #鲁棒性
✅ 7.5/10 | 前25% | #音频安全 | #水印 | #鲁棒性
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kuan-Yu Chen(Kuan-Yu Chen^{1,2},根据作者顺序判断)
- 通讯作者:Jeng-Lin Li^{2,⋆} 和 Jian-Jiun Ding^{1,⋆}(根据作者名后星号判断)
- 作者列表:Kuan-Yu Chen(台湾大学通讯工程研究所, Inventec公司AI研究中心)、Yi-Cheng Lin(台湾大学通讯工程研究所)、Jeng-Lin Li(Inventec公司AI研究中心)、Jian-Jiun Ding(台湾大学通讯工程研究所)
💡 毒舌点评
本文巧妙地将音频水印技术“黑化”为一种隐蔽后门,实现了“在眼皮子底下投毒”的效果,实验数据也显示其在感知质量和鲁棒性上确实优于传统土法炼钢的触发器。不过,这篇论文更像是把一个已知工具(水印)巧妙地应用到了一个已知场景(后门攻击),缺乏对水印本身可能被更复杂防御手段破解的深入探讨。
🔗 开源详情
- 代码:论文中提到“Code is available at GitHub”,但未提供具体的代码仓库URL链接。
- 模型权重:未提及是否公开微调后的Bloodroot-FT水印生成器权重。
- 数据集:使用的是公开的Speech Commands和VoxCeleb数据集,论文中未提供额外的数据集资源。
- Demo:未提及在线演示。
- 复现材料:提供了较为详细的训练细节,包括损失函数权重(λsup, λstft, λmel, λamp)、优化器(Adam)、学习率(1e-4)、Batch size(32)、水印强度(α=5)等关键超参数。硬件环境(NVIDIA A16, A40)也已说明。
- 论文中引用的开源项目:主要依赖了AudioSeal水印模型。还使用了开源数据集Speech Commands和VoxCeleb,以及torch-pruning库进行模型剪枝实验。
📌 核心摘要
- 要解决什么问题:现有音频后门攻击方法(如修改音高、插入超声波)在生成的有毒样本上会引入可被察觉的声音失真,且容易被常见的信号处理或模型剪枝防御手段所破坏。
- 方法核心是什么:提出Bloodroot框架,将原本用于版权保护的音频水印技术重新用作后门触发器。其核心是利用预训练的音频水印模型(AudioSeal)生成不可感知的扰动,并嵌入到少量(1%)训练数据中。进一步提出Bloodroot-FT,通过LoRA对水印生成器进行微调,以优化触发器的鲁棒性和隐蔽性之间的平衡。
- 与已有方法相比新在哪里:这是首个系统性地将音频水印作为后门触发器的研究。与传统的、针对性设计的声音模式(如超声波、环境音)相比,水印触发器天生具备更好的不可感知性和对常见信号处理的鲁棒性。
- 主要实验结果如何:在语音识别(SC-10/30)和说话人识别(VoxCeleb-125/全集)任务上,Bloodroot-FT相比现有最优基线,在感知质量(PESQ)上提升了约2分,STOI提升了约0.5。同时保持了超过95%的攻击成功率(ASR)和接近基线的模型准确率(BA)。关键抗防御实验结果如下表:
方法 ASR(无滤波) ASR(带低通滤波) PBSM 92.62% 9.52% Ultrasonic 97.26% 1.28% Bloodroot-FT 93.85% 53.49% 在模型剪枝防御下,Bloodroot系列也能保留约70%的ASR,而其他方法在剪枝率增加时ASR迅速下降。 - 实际意义是什么:一方面,它展示了如何利用水印技术实现更隐蔽、更鲁棒的数据所有权保护(正向应用)。另一方面,它警示了水印技术的“双刃剑”特性,可能被恶意利用进行更难检测的模型投毒攻击(反向风险),推动了AI安全领域对此类威胁的研究。
- 主要局限性是什么:研究主要集中在特定的语音任务和模型架构上;对于更复杂的防御(如对抗训练、水印检测算法)未做深入探讨;虽然声称是第一个系统性工作,但水印本身作为“触发器”的潜力挖掘可能还未到极致。
🏗️ 模型架构
论文没有提出一个全新的端到端网络架构,而是提出了一个攻击框架,核心是复用和微调一个现有的音频水印模型。
- 整体流程:攻击分为训练数据生成和模型训练/推理两个阶段(见图1)。攻击者使用一个水印生成器(G)为干净音频(x)生成水印扰动(w),将其加到原音频上得到有毒样本(˜x),并将标签篡改为目标标签(y_t)。受害者使用这个被污染的数据集训练自己的模型。
- 水印生成器(核心组件):
- 基础模型:采用预训练的AudioSeal模型作为水印生成器(G)。AudioSeal本身是一个基于神经网络(可能包含编码器和解码器)的音频水印系统,设计用于在音频中嵌入不可感知的、可检测的水印信号。
- 微调组件(Bloodroot-FT):在AudioSeal的解码器部分插入低秩自适应(LoRA)层,并只训练这些LoRA层,冻结原有模型参数。这允许以极小的参数开销,让水印生成器适应“后门触发”这一新任务。
- 数据流:
干净音频x->水印生成器G->水印扰动w->加法合成 (x + w)->有毒样本˜x。在微调(FT)版本中,G的内部结构被LoRA增强。 - 设计选择:
- Watermark-as-Trigger:核心思想是利用水印技术已优化的“不可感知性”和“鲁棒性”来解决后门攻击的痛点。
- LoRA微调:动机是轻量级、高效地让通用的水印生成器专注于生成对目标任务(SR/SID)更有效的触发模式,而非通用的水印。
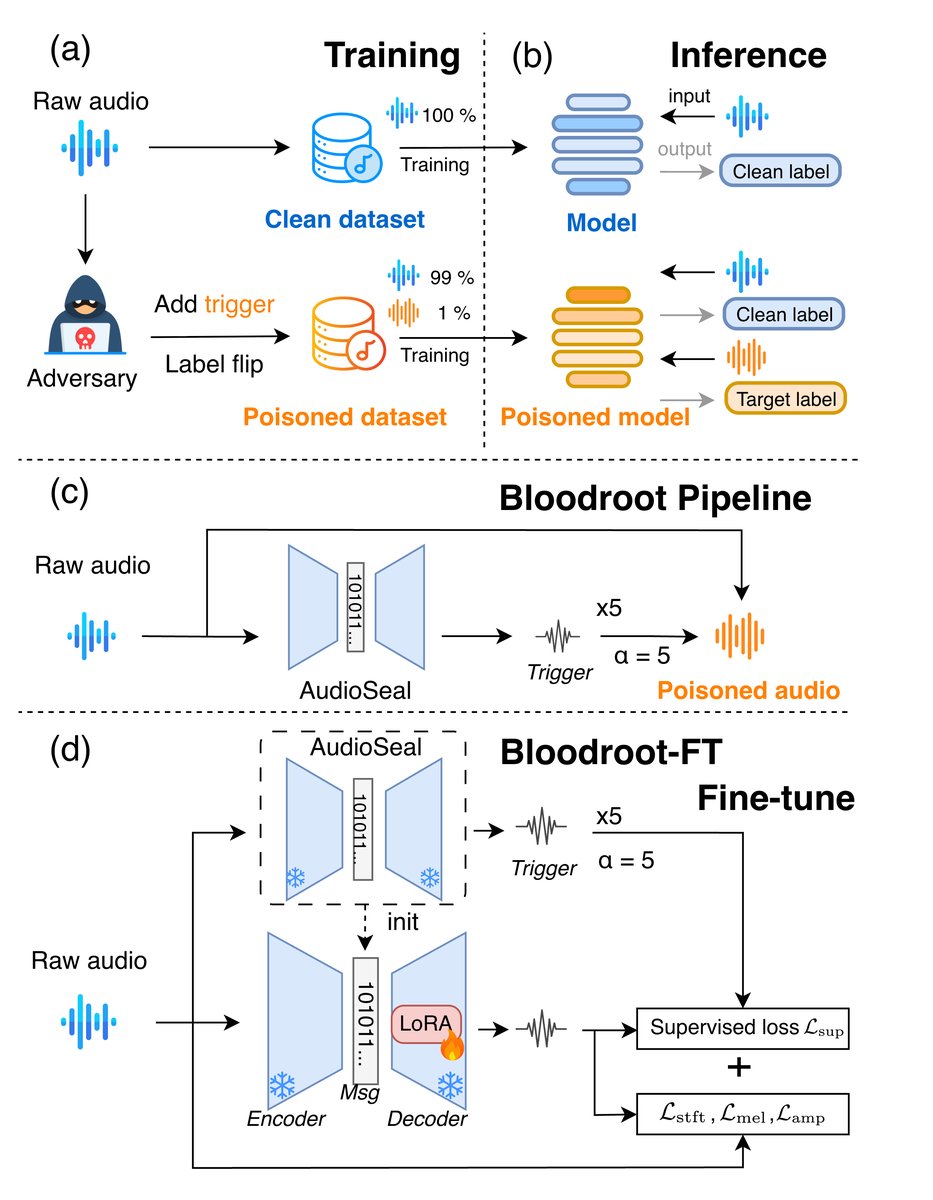 图1:Bloodroot框架概览。(a) 训练阶段:受害者模型在含有少量有毒样本的数据集上训练。(b) 推理阶段:带触发器的输入会激活后门(导致错误分类),干净输入则正常处理。(c) Bloodroot基础版:使用预训练的AudioSeal生成器,α=5控制扰动强度。(d) Bloodroot-FT:通过LoRA微调生成器,以优化鲁棒性和不可感知性之间的平衡。
图1:Bloodroot框架概览。(a) 训练阶段:受害者模型在含有少量有毒样本的数据集上训练。(b) 推理阶段:带触发器的输入会激活后门(导致错误分类),干净输入则正常处理。(c) Bloodroot基础版:使用预训练的AudioSeal生成器,α=5控制扰动强度。(d) Bloodroot-FT:通过LoRA微调生成器,以优化鲁棒性和不可感知性之间的平衡。
💡 核心创新点
- 提出Watermark-as-Trigger概念框架:这是第一个系统性地将音频水印技术重新用途化为后门触发器的研究。之前局限:后门攻击的触发器都是手工设计或用其他模型生成的特定声音模式(如超声波、环境噪音),与水印技术割裂。如何起作用:直接利用预训练水印模型生成扰动。收益:触发器自动继承了水印的不可感知性和鲁棒性,实验显示其在PESQ/STOI和抗防御性能上远超传统方法。
- 基于对抗微调的触发器优化(Bloodroot-FT):之前局限:直接使用预训练水印模型(Bloodroot基础版)虽然不错,但其生成的水印并非为“后门攻击”这个特定目标优化,攻击成功率(ASR)仍有提升空间。如何起作用:通过设计一个复合损失函数(包含监督损失、多尺度STFT损失、感知损失和幅度正则化),用LoRA对水印生成器进行微调,使其生成的扰动能更有效地欺骗受害者模型,同时保持低感知失真。收益:在保持高感知质量的同时,进一步提升了攻击成功率和鲁棒性(见图2的PESQ-ASR权衡曲线)。
- 全面的鲁棒性与实用性验证:之前局限:许多后门攻击研究仅报告攻击成功率,对常见防御(如滤波、剪枝)下的性能退化评估不足。如何起作用:系统测试了Bloodroot在低通滤波和模型剪枝两种防御下的表现。收益:定量证明了水印触发器相比传统触发器具有显著更强的抗防御能力(表3和图3),强调了其在实际场景中的威胁性。
🔬 细节详述
- 训练数据:
- 数据集:语音识别使用Speech Commands的SC-10(10个关键词)和SC-30(30个关键词)子集。说话人识别使用VoxCeleb-125(125位说话人)和完整的VoxCeleb数据集。
- 来源与规模:均为公开的学术数据集。论文未提供具体规模数字。
- 预处理/增强:未说明。攻击仅修改1%的数据标签和内容。
- 损失函数:用于微调Bloodroot-FT的总损失函数为加权和(公式5):
Lsup(监督损失,权重λsup=20000):使生成的扰动逼近一个目标扰动。Lstft(多尺度STFT损失,权重λstft=10):保持频谱相似性。Lmel(对数梅尔感知损失,权重λmel=10):约束梅尔频谱的偏差。Lamp(幅度正则化损失,权重λamp=0.1):防止扰动能量过大,其公式为Lamp = (1/(BT)) ||w||_2^2。
- 训练策略:
- 优化器:Adam。
- 学习率:1e-4。
- Batch size:32。
- 训练步数/轮数:未说明。
- 调度策略:未说明。
- 关键超参数:
- 水印强度α:Bloodroot基础版使用α=5。这是控制水印扰动幅度的关键参数。
- 中毒率ρ:默认为1%,消融实验测试了0.1%-2%。
- LoRA适配器:具体秩(rank)未说明,但强调了其轻量级。
- 训练硬件:受害者模型训练使用NVIDIA A16 GPU,Bloodroot微调使用NVIDIA A40 GPU。训练时长未说明。
- 推理细节:未说明具体解码策略等,对于SR和SID任务,应是标准的前向传播。
- 正则化技巧:在损失函数中引入
Lamp(幅度正则化)是关键的正则化技巧,用于约束扰动能量,提升隐蔽性。
📊 实验结果
主要基准与数据集:SC-10, SC-30 (关键词识别); VoxCeleb-125, VoxCeleb (说话人识别)。 主要指标:BA (良性准确率), ASR (攻击成功率), PESQ (感知语音质量评估), STOI (短时客观可懂度)。
与最强基线的对比(关键数值提取自表1、表2、表3):
- 感知质量 (PESQ/STOI):Bloodroot系列在所有任务上都取得最佳。例如在SC-30数据集(ResNet-18模型)上,Bloodroot-FT的PESQ为3.382,STOI为0.928,相比最强基线(Ultrasonic)的2.892和0.845,PESQ提升了0.49分(约17%相对提升),STOI提升了0.083。
- 攻击成功率 (ASR):Bloodroot系列在多数设置下达到或超过最强基线。在VoxCeleb(ResNet-18)上,Bloodroot-FT的ASR达到99.36%,超过了所有基线。
- 良性准确率 (BA):Bloodroot系列保持了与基线相当或略高的BA,表明对正常任务影响小。
- 抗防御能力:
- 低通滤波:见下表。Bloodroot-FT在滤波后仍保持53.49%的ASR,而基线方法(如超声波)几乎失效(1.28%)。
方法 ASR (无滤波) ASR (带低通滤波) PBSM 92.62% 9.52% JingleBack 90.52% 5.14% Ultrasonic 97.26% 1.28% Bloodroot 95.09% 44.58% Bloodroot-FT 93.85% 53.49% - 模型剪枝:见图3。随着剪枝率增加,基线方法的ASR迅速下降,而Bloodroot方法下降缓慢,在剪枝率高达90%时仍能维持约70%的ASR。
- 低通滤波:见下表。Bloodroot-FT在滤波后仍保持53.49%的ASR,而基线方法(如超声波)几乎失效(1.28%)。
关键消融实验(图2):
- 中毒率影响:在SC-10上,当中毒率从0.1%增加到2%时,BA保持稳定(约92-93%),而ASR从约0%稳步上升至近100%。仅0.5%的中毒率就能达到约50%的ASR,证明了触发器的高效性。
- PESQ-ASR权衡:在LSTM和ResNet-18模型上,Bloodroot-FT的PESQ-ASR权衡曲线均位于Bloodroot基础版之上,说明LoRA微调成功地在相同感知质量下获得了更高的攻击成功率,或在相同攻击成功率下实现了更好的感知质量。
⚖️ 评分理由
- 学术质量:6.5/7:创新性明确(框架新颖),技术路线清晰(复用+微调),实验设计全面(跨任务、跨数据集、跨模型、抗防御测试),数据详实。扣分点在于:1) 对微调过程的超参数敏感性和选择依据讨论较少;2) 未能探讨更前沿或更具挑战性的防御(如对抗样本训练、基于特征的水印检测);3) 论文声称是“第一篇”,但缺乏对相关领域(如音频指纹)更广泛的文献对比。
- 选题价值:2.0/2:选题非常契合当前AI安全与可信AI的前沿热点,揭示了水印技术的潜在风险,具有较高的学术价值和警示意义。应用空间直接关联模型供应链安全和数据所有权保护。
- 开源与复现加成:0.5/1:论文明确承诺提供代码(
Code is available at GitHub),并给出了详尽的实现细节(损失函数、超参数等),这为复现提供了良好基础。扣分是因为:1) 未提供具体的代码仓库链接;2) 模型权重、详细的训练脚本/配置文件未提及。