📄 Bleed No More: Generative Interference Reduction for Musical Recordings
#音乐源分离 #生成模型 #对抗学习 #数据集
✅ 7.0/10 | 前25% | #音乐源分离 | #生成模型 | #对抗学习 #数据集
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Rajesh R (University of Illinois Chicago)
- 通讯作者:未说明
- 作者列表:Rajesh R (University of Illinois Chicago)、Rashen Fernando (University of Illinois Chicago)、Padmanabhan Rajan (Indian Institute of Technology Mandi)、Ryan M. Corey (University of Illinois Chicago)
💡 毒舌点评
本文精准地切入“干扰消除”而非“源分离”这一细分赛道,用条件生成对抗网络给出了一个干净利落的技术方案,在跨风格测试(印度古典音乐)上展现出不错的泛化能力,是“小题大做”的典范。然而,核心生成器工作在幅度谱上并复用输入相位,这几乎是音频增强领域的“经典妥协”,导致SAR指标普遍偏低,论文对此的讨论止于局限性陈述,未能提出更优的相位处理方案,略显保守。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开权重。
- 数据集:使用了公开数据集MUSDB18HQ和Sanidha,论文中未提供自行创建的MUSDB18HQ-R数据集。
- Demo:提供了在线音频示例页面:
listeningtech.github.io/cGANIR/。 - 复现材料:给出了部分训练细节(优化器、学习率、epoch数、batch size、损失权重α),但缺失硬件、训练时长、详细模型配置等关键信息。
- 引用的开源项目:使用了
pyroomacoustics进行房间模拟。
📌 核心摘要
本文针对多轨现场音乐录音中普遍存在的麦克风串音(bleed)问题,提出了一种基于条件生成对抗网络的干扰消除方法cWGAN-IR。该方法将问题重新定义为:从单通道受污染的观测信号中,条件生成出干净的、保留目标乐器音色和瞬态的目标信号。与传统的基于信号处理的方法(如KAMIR)或旨在输出所有音轨的通用源分离模型(如HTDemucs)不同,cWGAN-IR专注于单通道目标,使用U-Net生成器和Patch判别器在时频幅度谱上进行对抗训练。实验在模拟串音(MUSDB18HQ-S)和真实重录串音(MUSDB18HQ-R)条件下进行,结果表明,该方法在SI-SDR、SNR和SIR等指标上显著优于KAMIR、CAE等传统干扰消除基线,并与HTDemucs竞争力相当,尤其在真实重录条件下优势明显。消融实验表明对抗训练能有效提升性能。该模型在印度古典音乐数据集(Sanidha)上也显示出良好的跨领域迁移能力。论文的主要局限性在于使用混合相位重构波形,可能导致生成信号与真实目标之间存在相位差异,影响了SAR(信号与伪影比)指标。实际意义在于为音乐制作和现场录音提供了一个针对性强、易于部署(单通道)且能保持原始音质的串音消除工具。
关键实验结果表格(摘自论文表1):
| 方法 | MUSDB18HQ-S (模拟) | MUSDB18HQ-R (重录) | ||||||
|---|---|---|---|---|---|---|---|---|
| 指标 | SI-SDR (Vocal) | SIR (Vocal) | SI-SDR (Bass) | SIR (Bass) | SI-SDR (Vocal) | SIR (Vocal) | SI-SDR (Bass) | SIR (Bass) |
| Reference (参考) | -23.42 | 23.54 | -14.25 | 34.47 | -31.97 | 12.46 | -20.65 | 9.16 |
| KAMIR | 4.53 | 6.92 | 6.18 | 7.00 | 1.02 | 2.58 | -0.67 | 2.73 |
| t-UNet | -22.67 | 24.56 | -13.72 | 34.89 | -31.22 | 12.69 | -19.94 | 9.48 |
| HTDemucs | 16.36 | 37.93 | 16.87 | 40.92 | -8.46 | 21.89 | -6.29 | 20.67 |
| cWGAN-IR (Ours) | 13.09 | 38.64 | 17.38 | 42.44 | 2.30 | 22.79 | 2.02 | 22.74 |
表格结论:cWGAN-IR在模拟和真实条件下,SI-SDR和SIR均大幅超越传统基线,并与HTDemucs竞争,在真实条件下多数指标占优。
🏗️ 模型架构
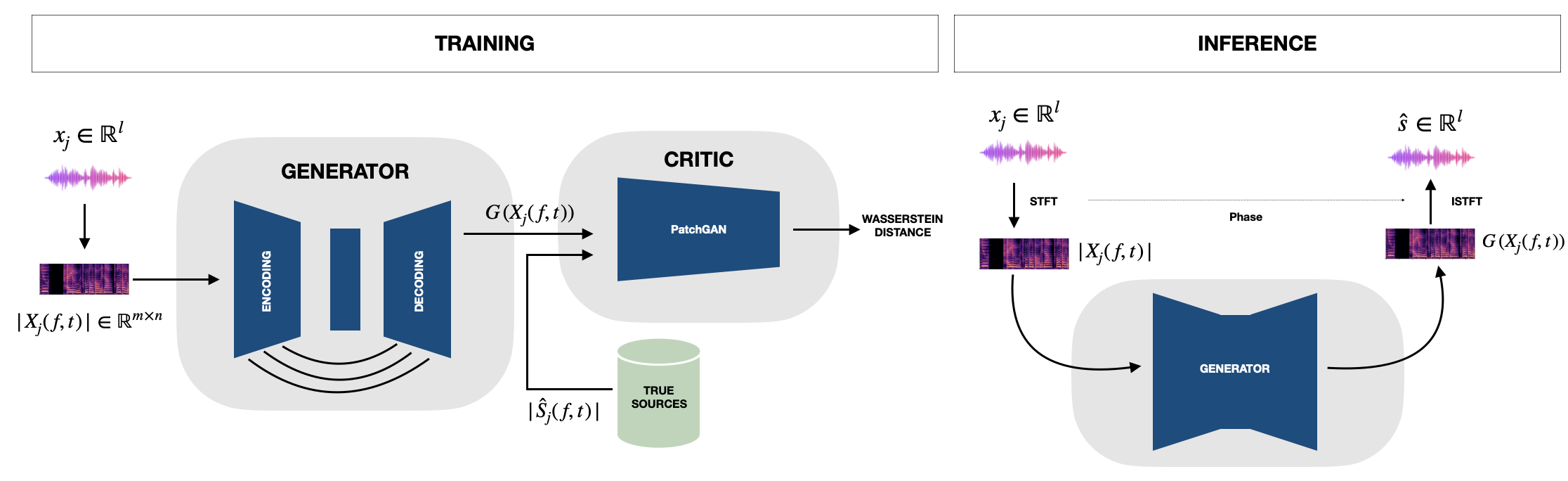 图2: cWGAN-IR干扰消除框架概览。左:训练流程(U-Net生成器、PatchGAN判别器(WGAN+GP)和L1损失)。右:推理流程(生成器输出、相位重用和ISTFT)。
图2: cWGAN-IR干扰消除框架概览。左:训练流程(U-Net生成器、PatchGAN判别器(WGAN+GP)和L1损失)。右:推理流程(生成器输出、相位重用和ISTFT)。
整体流程:
模型的目标是从受污染的幅度谱 |X_j| 中生成干净的幅度谱估计 G(|X_j|),其应近似于目标源 S_j 经过直达路径传输函数 H_jj 后的幅度谱 |S_j H_jj|。推理时,将生成的幅度谱与输入信号的相位 ∠X_j 结合,通过逆短时傅里叶变换(iSTFT)重构出时域波形。
主要组件:
生成器 (Generator, G):
- 架构:采用经典的U-Net结构。
- 编码器:包含三个下采样阶段,通道数逐级增加为64、128、256。每个编码块使用两个Conv-BN-ReLU层加步长卷积实现下采样。
- 瓶颈层:使用空洞卷积(膨胀率为2和4)以扩大感受野,捕捉长时依赖关系。
- 解码器:镜像编码器结构,通过转置卷积上采样,并通过跳跃连接将编码器对应层的特征图拼接到解码器中,以保留频谱细节信息。输出层为1×1卷积,直接进行幅度回归。
- 输入:受污染的单通道幅度谱
|X_j|。 - 输出:估计的干净目标幅度谱
G(|X_j|)。
判别器 (Critic, D):
- 架构:采用PatchGAN风格网络。
- 结构:由多个步长卷积-LeakyReLU-实例归一化(IN)层组成(首尾层除外),输出对输入频谱区域的局部分数,最终平均所有区域分数。
- 输入:将输入幅度谱
|X_j|与“目标”(训练时的干净幅度谱|S_j H_jj|或生成器的输出G(|X_j|))在通道维度上拼接。 - 训练目标:基于Wasserstein距离加梯度惩罚(WGAN-GP)。
关键设计选择:
- 条件生成范式:明确区别于多输出的源分离,专注于单通道目标的“精修”。
- 幅度谱操作:在幅度谱上进行生成和判别,计算效率高,但需要在推理时复用输入相位来重建波形。
- Patch判别器:能关注频谱的局部纹理细节,有助于生成更真实的高频结构。
💡 核心创新点
- 问题重新定义:从“分离”到“条件生成”:将多轨录音的串音消除问题,从传统的多通道信号处理或全能的音乐源分离框架中剥离出来,明确建模为“给定含干扰观测,生成干净目标”的条件生成任务。这简化了问题,更符合实际混音需求(往往只关心改善某一轨道)。
- 轻量级专用模型架构:提出cWGAN-IR,一个结构相对紧凑(U-Net + PatchGAN)的对抗模型,专门针对单通道干扰消除任务设计和训练,避免了为分离所有音轨而设计的复杂模型(如Transformer)带来的计算冗余和不必要信息干扰。
- 跨声学条件和跨音乐风格的泛化性验证:不仅在标准模拟数据上验证,更通过重录数据(MUSDB18HQ-R) 模拟真实录音室的声学串扰,并引入印度古典音乐数据集(Sanidha) 测试跨文化、跨乐器风格的迁移能力,实验设计更贴近现实世界的复杂性和多样性。
- 明确的目标导向评估:评估指标聚焦于SI-SDR和SIR(衡量干扰抑制程度),而非SAR(衡量伪影),这与其“保留目标音质,消除干扰”的设计目标高度一致,即使SAR有所牺牲,也能从其核心目标出发进行合理解释。
🔬 细节详述
- 训练数据:
- MUSDB18HQ-S:使用MUSDB18HQ中的vocal, bass, drums三轨。通过
pyroomacoustics库模拟混响房间(参数随机:尺寸、RT60 0.2-0.6s)并按照公式(1)合成串音。麦克风布局模拟:目标近麦(0.2-0.5m),干扰源远置(1-3m)。生成7560个10秒片段(50%重叠)。 - Sanidha:使用其中的vocal, mridangam, violin, ghatam四轨,采用与MUSDB18HQ-S相同的合成协议,生成2300对用于训练/评估。
- MUSDB18HQ-R:将MUSDB18HQ子集在录音室用扬声器播放并用真实分离的麦克风重新录制,模拟真实空间串音。此数据集仅用于评估。
- Saraga:无参考的现场录音,仅用于定性听感评估。
- MUSDB18HQ-S:使用MUSDB18HQ中的vocal, bass, drums三轨。通过
- 预处理:所有音频重采样为22.05kHz,混合为单声道。STFT参数:Hann窗,窗长2047,帧移512。使用幅度谱作为输入。
- 损失函数:
- 判别器损失 (L_D):公式(5)。为Wasserstein距离估计加梯度惩罚(
λ_gp = 10),旨在让判别器更好地区分真实和生成的频谱对。 - 生成器损失 (L_G):公式(6)。包含两部分:1)对抗损失
-E[D(G(|X_j|), |X_j|)],鼓励生成器欺骗判别器;2)L1保真度损失α|||S_j H_jj| - G(|X_j|)||_1,直接约束生成幅度谱与目标幅度谱的相似度。权重α = 10。
- 判别器损失 (L_D):公式(5)。为Wasserstein距离估计加梯度惩罚(
- 训练策略:
- 优化器:Adam,学习率
lr = 2e-4,β1 = 0.5,β2 = 0.999。 - 训练轮数:600 epochs。
- 批大小:8。
- 其他:论文未明确说明训练硬件(GPU型号、数量)、训练时长、warmup或学习率调度策略。
- 优化器:Adam,学习率
- 关键超参数:
- 模型大小:U-Net通道数序列64-128-256,具体层数未详细说明。
- STFT参数:窗长2047,帧移512。
- 推理细节:生成器输出幅度谱
G(|X_j|)后,直接使用输入信号X_j的相位∠X_j进行iSTFT重建波形~s_j。论文未提及任何解码策略(如温度、beam size)的调整,属于固定推理流程。
📊 实验结果
- 主要对比实验结果(表格已包含在上文“核心摘要”部分,此处补充完整版并解读):
表1:在MUSDB18HQ模拟(S)和真实(R)条件下的结果(均值,越高越好)
| 方法 | Vocal | Bass | Drums | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 数据集 | SI-SDR | SNR | SIR | SAR | SI-SDR | SNR | SIR | SAR | SI-SDR | SNR | SIR | SAR |
| MUSDB18HQ-S | ||||||||||||
| Reference | -23.42 | -2.69 | 23.54 | 24.58 | -14.25 | -1.59 | 34.47 | 19.79 | -19.07 | -0.48 | 27.00 | 17.07 |
| KAMIR | 4.53 | 3.88 | 6.92 | 5.47 | 6.18 | 5.42 | 7.00 | 6.27 | 3.15 | 2.94 | 4.21 | 3.56 |
| CAE | 9.12 | 8.66 | 9.77 | 8.90 | 7.91 | 7.36 | 9.82 | 7.64 | 6.88 | 6.12 | 9.03 | 7.45 |
| t-UNet | -22.67 | -2.15 | 24.56 | 24.91 | -13.72 | -1.18 | 34.89 | 20.16 | -18.49 | -0.33 | 27.26 | 17.42 |
| HTDemucs | 16.36 | 16.45 | 37.93 | 24.23 | 16.87 | 5.61 | 40.92 | 24.69 | 13.09 | 3.13 | 25.36 | 20.77 |
| cWGAN-IR | 13.09 | 9.96 | 38.64 | 17.48 | 17.38 | 10.64 | 42.44 | 16.59 | 13.87 | 10.29 | 29.72 | 15.60 |
| MUSDB18HQ-R | ||||||||||||
| Reference | -31.97 | -2.65 | 12.46 | -1.81 | -20.65 | -1.96 | 9.16 | -4.80 | -32.11 | -0.67 | 7.71 | -2.04 |
| KAMIR | 1.02 | -0.43 | 2.58 | 0.84 | -0.67 | 1.21 | 2.73 | 1.12 | -2.76 | 0.35 | 1.97 | -0.28 |
| CAE | 0.94 | 1.15 | 3.78 | 2.26 | 1.48 | 0.33 | 3.67 | 1.57 | -2.92 | 0.06 | 3.29 | 0.73 |
| t-UNet | -31.22 | -2.31 | 12.69 | -1.42 | -19.94 | -1.62 | 9.48 | -4.39 | -31.53 | -0.49 | 7.88 | -5.63 |
| HTDemucs | -8.46 | 0.64 | 21.89 | 11.27 | -6.29 | 0.67 | 20.67 | 3.36 | -8.58 | 0.94 | 18.39 | 5.06 |
| cWGAN-IR | 2.30 | 3.52 | 22.79 | 3.62 | 2.02 | 2.10 | 22.74 | 3.24 | -2.58 | 1.66 | 18.79 | -0.90 |
结果分析:
- vs. 传统基线:cWGAN-IR在所有指标(尤其是SI-SDR, SNR, SIR)上大幅超越KAMIR、CAE和t-UNet,证明了生成式方法的有效性。
- vs. HTDemucs:在模拟数据(-S)上,HTDemucs在SAR上表现更好(例如vocal SAR: 24.23 vs 17.48),这与其直接输出波形和可能更保守的生成策略有关。但cWGAN-IR在SIR上更高,说明其抑制干扰更彻底。在更贴近现实的重录数据(-R)上,cWGAN-IR在关键指标SI-SDR和SIR上全面超越HTDemucs,显示了更强的鲁棒性。
- 核心权衡:cWGAN-IR的SAR相对较低,这与其“使用混合相位重构”和“更激进的幅度生成(更锐利的频谱对比)”直接相关,是论文明确指出的trade-off。
- 跨域迁移实验结果:
表2:在Sanidha(卡纳提克音乐)数据集上的结果(均值,越高越好)
| 方法 | Vocal | Mridangam | Violin | Ghatam | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 指标 | SI-SDR | SNR | SIR | SAR | SI-SDR | SNR | SIR | SAR | SI-SDR | SNR | SIR | SAR | SI-SDR | SNR | SIR | SAR |
| True vs Bleed | 0.29 | 0.27 | 0.84 | 15.71 | 9.05 | 9.03 | 19.38 | 25.51 | 5.65 | 5.60 | 6.25 | 19.50 | -3.32 | -3.56 | -1.90 | 13.54 |
| KAMIR | 1.12 | 0.86 | 6.42 | 5.37 | 2.84 | 1.71 | 10.35 | 9.58 | 4.89 | 4.72 | 7.48 | 8.96 | 0.52 | 1.33 | 4.56 | 4.02 |
| HTDemucs | -26.13 | -2.59 | -17.50 | 9.63 | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| cWGAN-IR | 3.46 | 3.21 | 13.51 | 5.87 | 9.49 | 9.93 | 26.28 | 21.08 | 7.71 | 7.83 | 16.88 | 10.31 | 1.18 | 1.60 | 9.81 | 4.70 |
结果分析:
- HTDemucs在vocal上性能急剧下降(SI-SDR为负值),表明其泛化能力不足。论文指出这是因为其固定输出音轨与印度乐器不匹配。
- cWGAN-IR在所有乐器上均取得了正的SI-SDR和最高的SIR,尤其在mridangam上表现突出(SIR 26.28),证明了其作为“干扰消除器”而非“全分离器”的跨风格泛化优势。
- 消融实验结果:
表3:对抗训练效果消融(MUSDB18HQ上均值)
| 方法 | MUSDB18HQ-S | MUSDB18HQ-R | ||
|---|---|---|---|---|
| 指标 | SI-SDR | SIR | SI-SDR | SIR |
| ℓ1 only | 12.05 | 30.51 | 0.18 | 20.65 |
| ℓ1+adv (cWGAN-IR) | 14.78 | 36.93 | 0.58 | 21.44 |
结果分析:加入对抗训练后,在模拟和真实条件下,SI-SDR和SIR均有提升,尤其在模拟数据上SIR提升显著(+6.42 dB),验证了对抗训练对于改善干扰抑制和信号逼真度的重要性。
⚖️ 评分理由
学术质量:5.5/7
- 创新性(2.0/2.5):将“干扰消除”重新定义为“条件生成”是一个清晰有力的思路创新,模型架构和训练方法组合得当。但非底层原理的突破,更多是对现有技术的有效整合与应用。
- 技术正确性(1.5/1.5):数学建模清晰,模型设计合理,实验方法严谨(尤其是重录数据的引入)。
- 实验充分性(1.5/2.0):实验设计全面,覆盖多种条件,有消融实验。但部分训练硬件、超参数细节缺失,模型未开源,影响了完全复现的确定性。
- 证据可信度(0.5/1.0):结果数据支持结论,讨论了局限性。
选题价值:1.0/2
- 前沿性与影响(0.7/1.0):生成式音频处理是前沿,解决音乐制作中的实际痛点问题,具有明确应用价值。
- 读者相关性(0.3/1.0):对音频处理、音乐信息检索领域的研究者和工程师有较高参考价值,但受众相对专精。
开源与复现加成:0.5/1
- 代码/模型/数据:提供了示例音频网页链接(部分结果可公开感知),训练数据集公开。但未提供模型代码、权重和完整的训练配置,复现门槛较高。
- 复现细节:给出了损失函数公式、主要训练超参数(lr, epochs, batch size, α),但硬件和训练时长等信息缺失。因此加成有限。