📄 BiRQ: Bi-Level Self-Labeling Random Quantization for Self-Supervised Speech Recognition
#语音识别 #自监督学习 #低资源 #预训练
🔥 8.0/10 | 前25% | #语音识别 | #自监督学习 | #低资源 #预训练
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Liuyuan Jiang(罗切斯特大学 ⋆, 访问学生期间在IBM研究院 †)
- 通讯作者:未明确说明(论文未明确标注)
- 作者列表:
- Liuyuan Jiang(罗切斯特大学 ⋆, IBM研究院 †)
- Xiaodong Cui(IBM研究院 †)
- Brian Kingsbury(IBM研究院 †)
- Tianyi Chen(康奈尔大学 ‡)
- Lisha Chen(罗切斯特大学 ⋆)
💡 毒舌点评
亮点: 框架设计巧妙,将“自标签”与“锚定标签”结合成优雅的双层优化问题,在保持BEST-RQ式高效计算的同时,实现了HuBERT式的标签迭代优化。 短板: 双层优化部分的理论分析(Lemma 1及其条件)对非优化背景的读者不够友好,且论文未提供任何代码或预训练模型,大幅限制了其实际影响力和可复现性。
🔗 开源详情
- 代码: 论文中未提及代码链接。
- 模型权重: 未提及。
- 数据集: 论文使用了公开数据集LibriSpeech, YODAS, AMI,但未说明BiRQ专属数据集或预处理脚本。
- Demo: 未提及。
- 复现材料: 论文提供了详细的训练细节、超参数配置、模型架构描述(如Conformer配置C1/C2/C3),以及关键公式和算法伪代码(算法1),为复现提供了充足信息。
- 论文中引用的开源项目: 主要依赖标准框架:Conformer [7], BEST-RQ [2], Gumbel-Softmax [23],以及标准数据集处理工具。
- 开源计划总结: 论文中未提及开源计划。尽管提供了详实的论文内复现细节,但缺乏代码和权重分享将限制其快速应用和验证。
📌 核心摘要
- 问题: 语音自监督学习面临伪标签生成效率与质量的权衡。HuBERT等方法标签质量高但依赖外部编码器和多阶段流程,效率低;BEST-RQ方法高效但标签质量较弱。
- 方法核心: 提出BiRQ双层自监督学习框架。其核心是复用编码器(例如前k层)自身作为伪标签生成器,其输出经随机投影量化后生成“增强标签”(上层目标);同时,直接对原始语音输入进行随机投影量化,生成稳定的“锚定标签”(下层目标)。训练被建模为一个可微分的双层优化问题,并采用基于惩罚的单循环算法高效求解。
- 创新之处: 与HuBERT相比,BiRQ无需外部标签编码器,复用主编码器部分,实现了端到端训练且内存效率更高。与BEST-RQ相比,BiRQ引入了基于模型自身中间层表示的增强标签,实现了标签的迭代精炼,从而提升了伪标签质量。
- 实验结果: 在多个数据集(960h LibriSpeech, 5k YODAS)和多种Conformer配置(137M, 155M, 275M参数)上,BiRQ均一致优于BEST-RQ基线。例如,在137M模型、100 epoch设置下,BiRQ在LibriSpeech test-other集上的WER从BEST-RQ的20.5%降至19.1%,并在训练300 epoch后进一步降至17.2%,优于HuBERT式的多阶段离线重标记方法。消融实验证实了中间层选择k≈0.7K的有效性。
- 实际意义: 为语音自监督学习提供了一个简洁、高效且性能更强的端到端训练框架,降低了构建高性能语音表示模型的门槛。
- 主要局限: 论文未公开代码和模型,限制了可复现性。双层优化的理论保证依赖于一定的条件假设。超参数如损失权重w1, w2的选择依赖经验。
🏗️ 模型架构
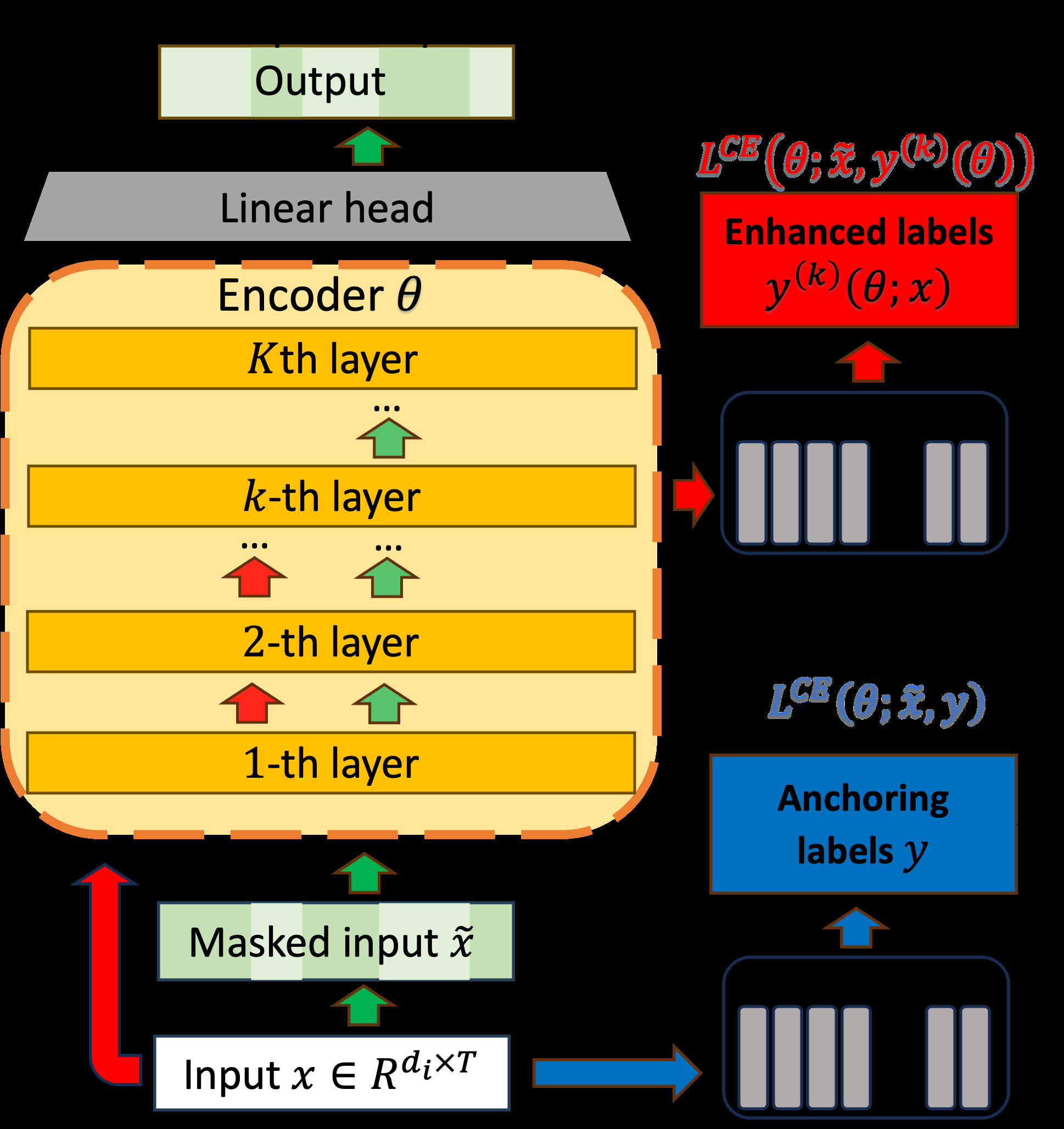 BiRQ的整体架构基于一个K层的通用声学编码器(如Conformer),其架构图(图1)展示了核心数据流:
BiRQ的整体架构基于一个K层的通用声学编码器(如Conformer),其架构图(图1)展示了核心数据流:
- 输入与预处理: 未掩码的归一化语音输入
x通过编码器。 - 锚定标签生成(蓝色箭头):
x直接通过一个固定的随机投影矩阵P_anchor(维度:输入特征维度d_i× 码本维度d_c)投影到码本空间u(x),然后通过最近邻匹配到一个固定的随机码本C(N个条目),得到独热编码的锚定标签y(x)。该标签独立于模型参数θ,用于稳定训练。 - 增强标签生成(红色箭头):
x通过编码器的前k层(作为“标签编码器”),得到中间层归一化表示z(k)(θ; x)。该表示通过另一个固定的随机投影矩阵P_enhance(维度:隐藏维度d_h×d_c)投影到码本空间u(k)(θ; x)。为了使其可微分,应用Gumbel-Softmax技巧(公式4),生成软化的分类分布y(k)(θ; x)作为增强标签。该标签依赖于模型参数θ,允许梯度回传以进行迭代优化。 - 掩码预测训练(绿色箭头): 输入
x被随机掩码得到˜x。˜x通过整个K层编码器θ,输出经过一个线性层映射到码本维度,得到logitso(θ; ˜x)。损失函数LCE计算在被掩码位置M上,logits与锚定标签y(x)和增强标签y(k)(θ; x)的交叉熵。 - 双层优化框架(BLO): 上层(UL)目标
F(θ)最小化使用增强标签的交叉熵损失,鼓励模型利用自身精炼的特征学习。下层(LL)目标G(θ)最小化使用锚定标签的交叉熵损失,提供稳定的监督。优化问题(公式8)被重构为惩罚形式(公式9),联合优化w1F(θ) + w2G(θ),其中w2/w1控制对下层目标接近最优的惩罚强度。
关键设计选择:
- 复用编码器: 将主编码器前k层作为标签生成器,避免了引入额外编码器,实现了内存高效和端到端训练。
- 随机投影量化器: 继承自BEST-RQ,相比k-means等方法,计算开销极低。
- 锚定与增强的双层设计: 锚定标签(来自原始输入)提供稳定的基准,防止训练崩溃;增强标签(来自中间层表示)提供更高质量、随训练演化的监督信号。
- Gumbel-Softmax: 使离散的最近邻匹配操作可微,允许通过标准梯度下降进行端到端优化。
💡 核心创新点
- 基于模型自身的双层自标签框架: 核心创新是设计了一个双层优化问题,其中编码器既是学习者(预测被掩码部分),也是标签生成者(其自身的中间层输出经量化后作为监督信号)。这统一了标签精炼和表示学习,且无需外部组件。
- 锚定标签与增强标签的协同设计: 明确区分并利用了两种标签:来自原始输入的、固定的锚定标签用于稳定训练;来自模型中间层的、可演化的增强标签用于提升监督质量。这种组合在效率与性能间取得了良好平衡。
- 高效的单循环可微分求解算法: 将双层优化问题通过惩罚方法转化为单目标问题,使得可以在单个循环中同时计算
∇F(θ)和∇G(θ)并更新参数,实现了与普通反向传播相似的计算效率(见算法1)。 - 可扩展的高效实现: 相比需要额外标签编码器的HuBERT方法(内存开销O(Td + 2P)),BiRQ仅增加了轻量的投影操作,保持O(Td + P)的复杂度,与基础的BEST-RQ相同,在实际中表现为更低的显存占用。
🔬 细节详述
- 训练数据:
- 预训练: 960小时LibriSpeech无标签数据;5000小时YODAS(YouTube对话音频)无标签子集。
- 微调: 100小时LibriSpeech带标签子集(用于137M/155M模型);150小时AMI会议带标签数据(用于275M模型)。
- 预处理: 16kHz采样率。使用80维log-Mel滤波器组(25ms窗,10ms移位)。输入特征通过堆叠连续两帧进行降采样。
- 掩码策略: 继承自BEST-RQ。随机选择2%的总帧长进行掩码,每个掩码跨度为20帧(因堆叠实际为40帧)。掩码区域填充高斯噪声(均值0,方差0.1)。
- 损失函数: 交叉熵损失
LCE(公式5),定义在被掩码的位置M上。总目标为w1F(θ) + w2G(θ),其中F(θ)对应增强标签损失,G(θ)对应锚定标签损失。 - 训练策略:
- 优化器: AdamW(预训练),Adam(微调)。
- 学习率: 137M模型预训练:2e-4;155M模型预训练:1e-4;275M模型预训练:1e-4。微调:峰值0.001,10 epoch线性warmup,保持10 epoch,10 epoch余弦退火。
- Batch Size: 137M模型:100;155M模型:64;275M模型:128。
- 训练轮数: 主要比较中使用100 epoch,也测试了200和300 epoch。
- 关键超参数:
- 中间层选择k: 遵循经验法则
k ≈ 0.7K(K为总层数)。5层模型选k=3,10层模型选k=7。 - 码本: N-entry固定随机码本
C。消融实验中测试了4个码本(4CB)。 - Gumbel-Softmax温度τ: 设为0.5。
- 双层损失权重:
w1 = 0.1,w2 = 2.4,对应的惩罚系数γ = w2/w1 = 24。 - 模型配置: C1 (5层, 1024宽, 8头, 窗200, 137M);C2 (10层, 768宽, 6头, 全注意力, 155M);C3 (10层, 1024宽, 8头, 窗200, 275M)。
- 中间层选择k: 遵循经验法则
- 训练硬件: 未明确说明具体GPU型号和数量,仅在内存分析中提及“4×H100 GPUs”。
- 推理细节: 微调使用CTC损失。解码使用4-gram语言模型(LibriSpeech使用官方提供,AMI使用内部模型)。未提及流式设置。
- 正则化/稳定训练技巧: 锚定标签的下层目标本身就起到正则化和稳定训练的作用。Gumbel-Softmax的温度参数
τ和双层惩罚系数γ也是稳定训练的关键超参数。
📊 实验结果
主要对比实验: 论文在表1、2、3中展示了BiRQ在不同模型规模、数据集和设置下与监督基线和BEST-RQ的对比。关键结果如下表:
| 模型配置 | 数据集 | 方法 | 指标 (WER) | 结果 |
|---|---|---|---|---|
| C1 (5层, 137M) | LibriSpeech (960h预训练, 100h微调) | 监督基线 (100ep) | test-clean / test-other | 8.4% / 24.4% |
| BEST-RQ (100ep) | 7.1% / 20.5% | |||
| + 迭代重标记 (100ep) | 6.3% / 18.6% | |||
| BiRQ (k=3, 100ep) | 6.6% / 19.1% | |||
| BiRQ (200ep) | 6.1% / 17.4% | |||
| BiRQ (300ep) | 5.9% / 17.2% | |||
| C2 (10层, 155M) | LibriSpeech (960h预训练, 100h微调) | 监督基线 (100ep) | test-clean / test-other | 7.4% / 20.5% |
| BEST-RQ (100ep) | 6.8% / 19.6% | |||
| BiRQ (k=7, 100ep) | 5.0% / 12.6% | |||
| C3 (10层, 275M) | YODAS (5k小时预训练) -> AMI (150h微调) | 监督基线 (100ep) | ami-ihm / ami-sdm | 25.7% / 47.0% |
| BEST-RQ (100ep) | 18.4% / 37.2% | |||
| BiRQ (k=7, 100ep) | 16.3% / 34.0% |
关键结论:
- 持续提升: 在所有配置中,BiRQ均显著优于其基线BEST-RQ和监督学习。例如,在C2模型上,BiRQ将test-other WER从19.6%大幅降至12.6%。
- 等效迭代精炼: BiRQ通过双层优化实现了等效于多阶段离线重标记的效果。在C1模型上,100 epoch的BiRQ性能已接近甚至超过相同累计epoch数的迭代重标记方法,而300 epoch的BiRQ达到了最佳性能(5.9%/17.2%),表明其标签质量在训练中持续提升。
- 规模扩展性: 方法在更薄更深(155M)、更大(275M)的模型上同样有效,并在不同的预训练-微调数据组合(LibriSpeech -> LibriSpeech, YODAS -> AMI)上表现出良好的泛化性。
消融实验:
表1中的消融实验研究了中间层选择k的影响(使用C1模型,100 epochs):
| k值 | test-clean WER | test-other WER |
|---|---|---|
| k=2 | 7.4% | 21.1% |
| k=3 | 6.6% | 19.1% |
| k=4 | 6.4% | 17.9% |
结论:选择k=3(≈0.7*5层)取得了最佳的test-clean WER,而k=4在test-other上略优,验证了k≈0.7K的经验法则。选择过浅的k(如k=2)性能下降明显。 |
扩展设置: 使用多码本(4CB)的BiRQ变体(表1最后一行)取得了test-clean 6.2%和test-other 16.3%的显著更好结果,证明增加码本多样性能进一步提升性能。
内存效率分析: 论文指出,BiRQ的峰值内存占用(23.0GB)低于HuBERT式迭代重标记方法(26.0GB),体现了其内存高效性。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性 (2.0/2.5): 创新点明确,将双层优化应用于语音SSL以结合锚定与增强标签,思路新颖且工程实现巧妙。
- 技术正确性 (2.0/2.5): 方法设计合理,实验结果一致且具有说服力,双层优化的单循环求解有理论依据(Lemma 1)。
- 实验充分性 (1.5/1.5): 实验非常充分,覆盖了多种模型规模、数据集、配置,并进行了关键的消融实验(k选择、多码本),提供了详实的对比数据。
- 证据可信度 (0.5/0.5): 结果可复现(基于公开数据集和标准设置),但未提供代码,部分降低了可信度和可及性。
- 选题价值:1.5/2
- 前沿性 (0.8/1.0): 语音自监督学习是当前研究热点,提升其效率和性能是重要方向。
- 潜在影响与应用 (0.7/1.0): BiRQ提供了一种更优的预训练范式,有望���用于构建更强大的语音基础模型,具有明确的应用价值。
- 开源与复现加成:0.5/1
- 复现信息充分性 (0.5/0.5): 论文提供了非常详细的训练配置、超参数(损失权重、温度、层选择法则等)、模型规格和预处理步骤,复现门槛较低。
- 开源完整性 (0.0/0.5): 论文未提及任何代码、模型权重或复现材料的开源计划,这是一个重大缺失。