📄 BioSEN: A Bio-Acoustic Signal Enhancement Network for Animal Vocalizations
#生物声学 #时频分析 #模型比较 #数据集
✅ 7.5/10 | 前25% | #生物声学 | #时频分析 | #模型比较 #数据集
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
基于当前提供的论文内容:
- 第一作者:Tianyu Song (九州大学 生物资源与生物环境科学研究生院)
- 通讯作者:Ton Viet Ta (九州大学 农学院)
- 作者列表:Tianyu Song (九州大学 生物资源与生物环境科学研究生院),Ton Viet Ta (九州大学 农学院),Ngamta Thamwattana (纽卡斯尔大学 信息与物理科学学院),Hisako Nomura (九州大学 农学院),Linh Thi Hoai Nguyen (九州大学 国际碳中和能源研究所)
💡 毒舌点评
本文精准地瞄准了生物声学信号增强这一“蓝海”问题,并通过三个针对性设计的模块(MSDA, BHME, EAGC)有效提升了性能,其计算效率优势显著,体现了扎实的工程优化能力。然而,论文中的消融实验结果存在明显的指标矛盾(如CSCConv-AE+MSDA的SNR为负),且核心贡献主要是在现有语音增强框架上的适配与组合创新,缺乏根本性的理论或架构突破,代码和模型权重的缺失也削弱了其即时影响力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及公开模型权重。
- 数据集:论文中引用的数据集(Xeno-canto, Earth Species Library, Biodenoising)为公开数据集,论文未提供新的自建数据集。如何获取已在[14]-[18]中说明。
- Demo:论文中未提及在线演示。
- 复现材料:提供了模型架构描述、损失函数、初始学习率、衰减系数和Batch Size。但缺少优化器、具体训练时长、各模块的详细超参数(如MSDA的头数、BHME的核尺寸)等,复现材料不完全充分。
- 论文中引用的开源项目:引用了FSPEN[19]、LiSenNet[20]、Demucs[21]、DCCRN[22]、FullSubNet[23]等作为对比基线,但未明确说明依赖的开源工具。
- 论文中未提及开源计划。
📌 核心摘要
本文旨在解决生物声学信号增强领域中,因动物叫声特性复杂(谐波结构、稀疏时序)和训练数据缺乏“干净”样本而带来的挑战。为此,作者提出了BioSEN模型,一个轻量级的专用去噪网络。其核心方法是在复杂卷积自编码器基线上,集成了三个关键模块:多尺度双轴注意力机制(MSDA)联合提取时频和通道特征;生物谐波多尺度增强模块(BHME)通过各向异性卷积捕捉谐波结构;以及能量自适应门控连接(EAGC)智能融合编解码器特征以抑制噪声传递。与已有的语音增强方法相比,BioSEN的新颖之处在于其完全针对生物声学信号的独特属性进行模块设计,并利用伪干净数据进行训练。在三个多样化的生物声学测试集(鸟类声音、混合动物声音)上的实验表明,BioSEN在感知质量(SNR)和信号保真度(SI-SDR)上匹配或超越了多种先进的语音增强模型(如DCCRN, FullSubNet),同时计算开销大幅降低(例如在Bird Song数据集上仅需3.15 GFLOPs,远低于FullSubNet的93.82 GFLOPs)。这证明了其为生物多样性监测提供高效、鲁棒音频处理工具的潜力。主要局限性在于消融实验中部分模块组合出现指标矛盾,且模型依赖于预训练生成的伪干净数据,其在真实极端噪声下的泛化能力有待进一步验证。
🏗️ 模型架构
BioSEN的整体架构如图1所示,是一个编码器-解码器(Autoencoder)结构,其核心在于对编码器特征的增强和编解码器之间跳跃连接的智能过滤。
完整流程:输入复杂的时频特征 X ∈ R^{B×F×T×C×2},首先经过由MSDA模块构成的编码器进行特征提取。编码后的特征一方面传递给下一层编码器,另一方面通过EAGC模块有选择地传递给对应的解码层。解码器负责重建增强后的信号。整个网络以复杂卷积为基础操作。
主要组件:
编码器核心:多尺度双轴注意力(MSDA) (如图2所示)
- 功能:在编码阶段联合建模时间、频率和通道维度的依赖关系,以突出生物声学模式。
- 内部结构与数据流:
- 输入X首先被重塑为两种形态:(B×F, T, C) 用于时间注意力,捕获时序依赖;(B×T, F, C) 用于频率注意力,捕获频谱依赖。这是“双轴”的含义。
- 并行地,计算通道注意力:对输入X的幅度进行全局平均池化,通过全连接层和Sigmoid激活生成通道权重向量α。
- 融合:将双轴注意力的输出与经过通道权重缩放的原始输入(X ⊙ α)相加,最后通过一个1×1复数卷积融合这两个分支,再与原始输入残差连接,得到输出Xout。
- 设计动机:将时间和频率处理解耦,使模型能分别专注于动物叫声中不同的稀疏时序模式和窄带能量集中特性,同时通过通道注意力自适应地强调重要特征。
增强模块:生物谐波多尺度增强(BHME)
- 功能:专门捕捉和增强动物叫声中丰富的谐波结构。
- 内部结构:使用一组并行的、不同尺寸(k×1)的可学习各向异性卷积核。每个卷积核专注于捕获特定间距的谐波模式。所有卷积核的宽度固定为1,确保分析聚焦于频率轴。
- 数据流:输入先经过一个预处理卷积(Xconv),然后分别送入多个并行的(k×1)卷积分支,得到多尺度谐波特征Hk。这些特征被拼接后,通过一个1×1卷积融合为统一表示Hfused。最后,通过一个带可学习缩放因子α的残差连接与原始输入X相加,得到输出Y。
- 设计动机:不同于语音处理对基频和其谐波的区分不明显,动物叫声(如鸟鸣)的谐波结构是其“清脆”听感的关键。BHME通过多尺度、各向异性的卷积,自然地学习不同密度的谐波间距。
连接模块:能量自适应门控连接(EAGC)
- 功能:作为跳跃连接,智能地选择从编码器传递到解码器的特征,抑制噪声传播。
- 内部结构与数据流:
- 频率加权门控:对编码器特征E,先通过一个可学习的门控机制G和频率能量权重Wfreq(源自频谱能量分布)进行过滤,得到Ef。公式为:Ef = Eo ⊙ (σ(Conv(Eo)) · Wfreq)。
- 交叉注意力:解码器状态D作为查询(Query),从Ef中选择最相关的特征Es,生成细化后的表示。
- 分辨率匹配:由于编码器和解码器层可能存在分辨率差异,EAGC使用双线性插值将Ef调整到与解码器层D相同的尺寸(Fd, Td),然后再进行后续操作。
- 设计动机:传统的跳跃连接会无差别地传递所有特征,包括噪声。EAGC通过频率感知的门控和查询-选择机制,确保只传递与目标动物叫声最相关、能量集中的频带特征。
💡 核心创新点
- 面向生物声学的专用模型设计:首次明确并系统性地为生物声学信号增强设计网络模块(MSDA, BHME, EAGC),而不是直接套用语音增强模型。每个模块都针对动物叫声的特性(谐波丰富、时序稀疏、频带窄)进行优化,这是其核心创新所在。
- 生物谐波多尺度增强(BHME)模块:这是对传统语音增强中特征提取的显著改进。之前的方法(如Gammatone滤波器)是固定的,而BHME通过可学习的、不同尺寸的各向异性卷积核,自适应地学习和增强不同物种叫声的特定谐波模式,更符合生物声学信号的物理特性。
- 能量自适应门控连接(EAGC)模块:改进了U-Net类架构中的跳跃连接。通过结合频率能量加权和交叉注意力,实现了从“无条件传递”到“基于查询的、频率感知的智能传递”的升级,有效解决了跳跃连接传递噪声的问题,提升了重构质量。
🔬 细节详述
- 训练数据:
- 训练集:使用Xeno-canto鸟类数据集[14]。关键点是利用伪干净目标方法[12]:用一个预训练的语音增强模型生成“伪干净”的参考音频,将原始的噪声录音转化为配对的“噪声输入-伪干净参考”样本,用于监督训练。
- 测试集:使用三个小但多样化的测试集(见表1):Bird Song[15](鸟类,平均SNR -10~-5 dB)、Biodenoising[12](鸡、狮子等,平均SNR -10~-5 dB)、Mixed data[16,17,18](果蝠、水獭等,平均SNR -5~10 dB)。
- 预处理:论文中未详细说明。
- 数据增强:论文中未提及。
- 损失函数:
- 名称:负SI-SDR (Scale-Invariant Signal-to-Distortion Ratio)。
- 作用:衡量增强信号与参考信号之间的相似度,值越大表示相似度越高。最小化负SI-SDR等价于最大化SI-SDR。
- 权重:论文中未提及使用不同损失的组合或权重。
- 训练策略:
- 初始学习率:1 × 10^{-3}。
- 衰减系数:0.7(可能指每隔一定步数或当指标停止提升时,学习率乘以0.7)。
- Batch Size:16。
- 优化器:论文中未提及具体优化器名称(如Adam, SGD)。
- 训练步数/轮数:论文中未提及。
- Warmup:论文中未提及。
- 关键超参数:
- 模型大小:论文未给出具体参数量。
- MSDA中的注意力头数:论文未提及。
- BHME中并行卷积核的数量及具体尺寸(k值):论文未提及。
- EAGC中的门控网络结构:论文未提及。
- 训练硬件:NVIDIA A100 GPU, 40GB RAM。
- 推理细节:论文未提及解码策略、温度、beam size等。
- 正则化或稳定训练技巧:论文未提及Dropout、权重衰减等具体技巧。
📊 实验结果
论文在三个数据集上进行了消融实验和与多种语音增强模型的对比,结果如下表所示。
表2:Bird Song数据集上的消融实验与模型对比
| 模型 | SI-SDR (dB) | SI-SDRi (dB) | SNR (dB) | SNRi (dB) | FLOPs (G) |
|---|---|---|---|---|---|
| Noisy (输入) | -7.80 | - | -7.81 | - | - |
| FSPEN[19] | -0.64 | 7.16 | 2.43 | 10.24 | 6.61 |
| LiSenNet[20] | -5.14 | 2.86 | 0.48 | 8.49 | 0.11 |
| Demucs[21] | 3.16 | 10.96 | 5.31 | 13.12 | 23.78 |
| DCCRN[22] | 3.15 | 10.95 | 5.29 | 13.10 | 27.69 |
| FullSubNet[23] | 2.76 | 10.56 | 5.20 | 13.02 | 93.82 |
| CSCConv-AE (基线) | -0.06 | 7.74 | 3.23 | 11.04 | - |
| CSCConv-AE+MSDA | 4.02 | 11.82 | -4.26 | 3.56 | - |
| CSCConv-AE+BHME | 2.38 | 10.18 | 4.81 | 12.63 | - |
| CSCConv-AE+EAGC | 2.89 | 10.69 | 5.20 | 13.01 | - |
| BioSEN (完整模型) | 3.47 | 11.27 | 5.73 | 13.54 | 3.15 |
关键结论:
- 消融实验:添加每个模块(MSDA, BHME, EAGC)都带来性能提升。完整BioSEN在SNR和SNRi上达到最佳。值得注意的是,CSCConv-AE+MSDA组合在SI-SDR上最高(4.02 dB),但SNR极差(-4.26 dB),可能过拟合了失真度量而忽略了噪声抑制,这表明单一指标的局限性。
- 模型对比:BioSEN在SNR和SNRi上超越所有对比模型(包括强大的DCCRN和FullSubNet)。在SI-SDR上略低于CSCConv-AE+MSDA,但综合表现均衡。
- 效率:BioSEN仅需3.15 GFLOPs,远低于Demucs (23.78G), DCCRN (27.69G) 和 FullSubNet (93.82G),是高效模型的典范。
表3:在Biodenoising和Mixed data数据集上的性能对比
| 模型 | Biodenoising [12] | Mixed data [16, 17, 18] | ||||||
|---|---|---|---|---|---|---|---|---|
| SI-SDR | SI-SDRi | SNR | SNRi | SI-SDR | SI-SDRi | SNR | SNRi | |
| Noisy | -7.49 | - | -3.71 | - | 2.89 | - | 3.20 | - |
| FSPEN | 6.89 | 14.38 | 5.20 | 8.91 | 12.15 | 9.26 | 10.27 | 7.07 |
| LiSenNet | -1.42 | 8.49 | 2.53 | 8.63 | 2.87 | -0.02 | 4.62 | 1.42 |
| Demucs | 7.97 | 15.47 | 6.38 | 10.10 | 12.83 | 9.94 | 12.55 | 9.35 |
| DCCRN | 7.14 | 14.63 | 6.19 | 9.90 | 15.97 | 13.08 | 13.09 | 9.40 |
| FullSubNet | 9.17 | 16.66 | 6.43 | 10.14 | 13.89 | 11.00 | 13.82 | 10.62 |
| BioSEN | 9.44 | 16.93 | 6.52 | 10.23 | 16.16 | 13.27 | 16.10 | 12.90 |
关键结论:BioSEN在所有四个指标上均优于其他模型,尤其在Mixed data(涵盖多种动物)上优势明显,表明其良好的泛化能力和鲁棒性。
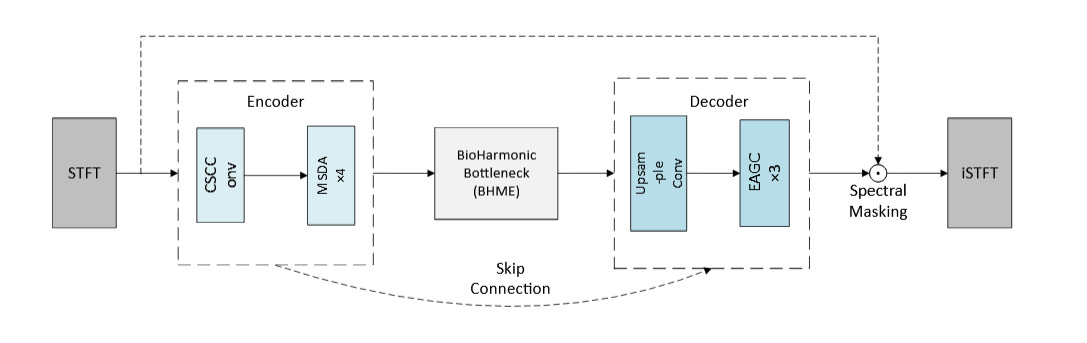 图1展示了BioSEN的整体架构,清晰地呈现了编码器(内含MSDA)、解码器以及连接两者的EAGC模块。数据流从左至右,EAGC模块位于中间,对编码器到解码器的特征传递进行过滤。
图1展示了BioSEN的整体架构,清晰地呈现了编码器(内含MSDA)、解码器以及连接两者的EAGC模块。数据流从左至右,EAGC模块位于中间,对编码器到解码器的特征传递进行过滤。
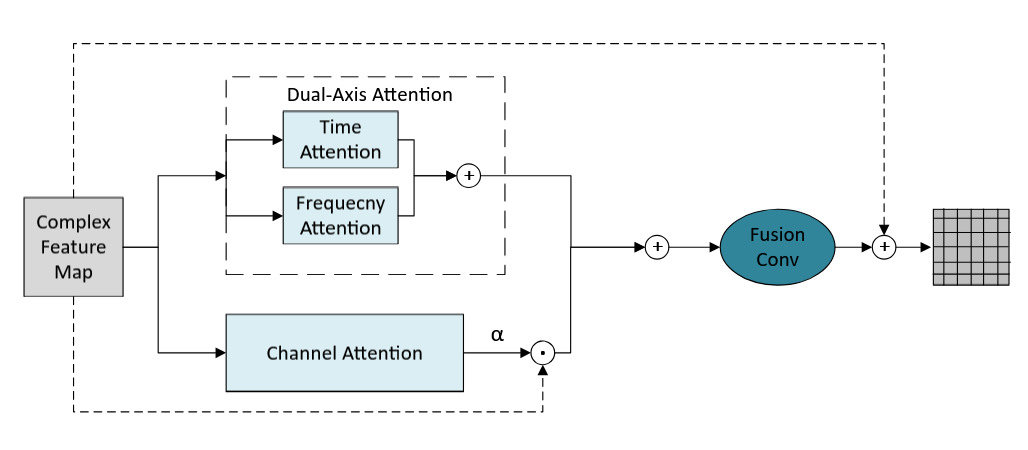 图2详细展示了MSDA模块的内部结构,可以看到双轴注意力(时间与频率)的并行处理路径,以及通道注意力的生成和融合过程,最后通过1x1卷积和残差连接输出。
图2详细展示了MSDA模块的内部结构,可以看到双轴注意力(时间与频率)的并行处理路径,以及通道注意力的生成和融合过程,最后通过1x1卷积和残差连接输出。
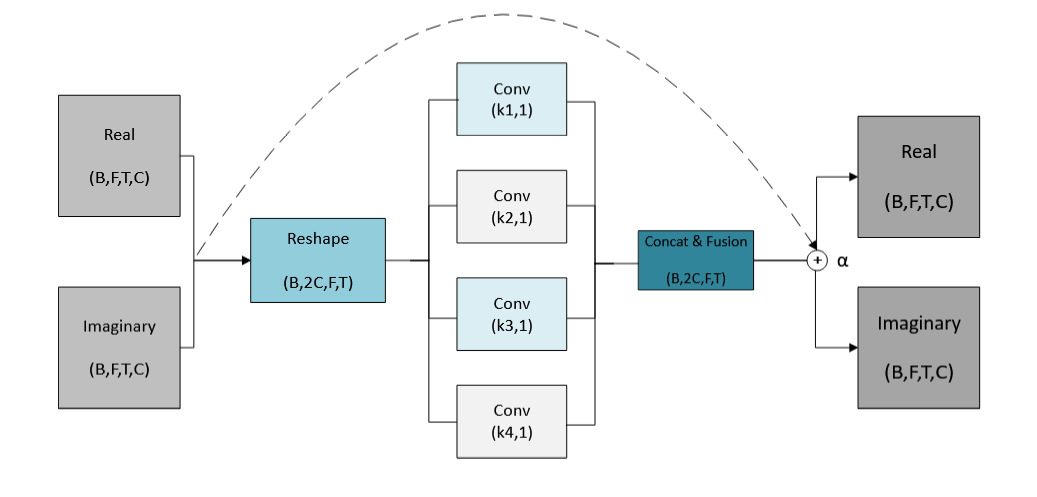 图3展示了BHME模块,其核心是多个并行的、不同尺寸(kx1)的各向异性卷积分支,用于捕获不同尺度的谐波结构,最终融合并与输入进行残差连接。
图3展示了BHME模块,其核心是多个并行的、不同尺寸(kx1)的各向异性卷积分支,用于捕获不同尺度的谐波结构,最终融合并与输入进行残差连接。
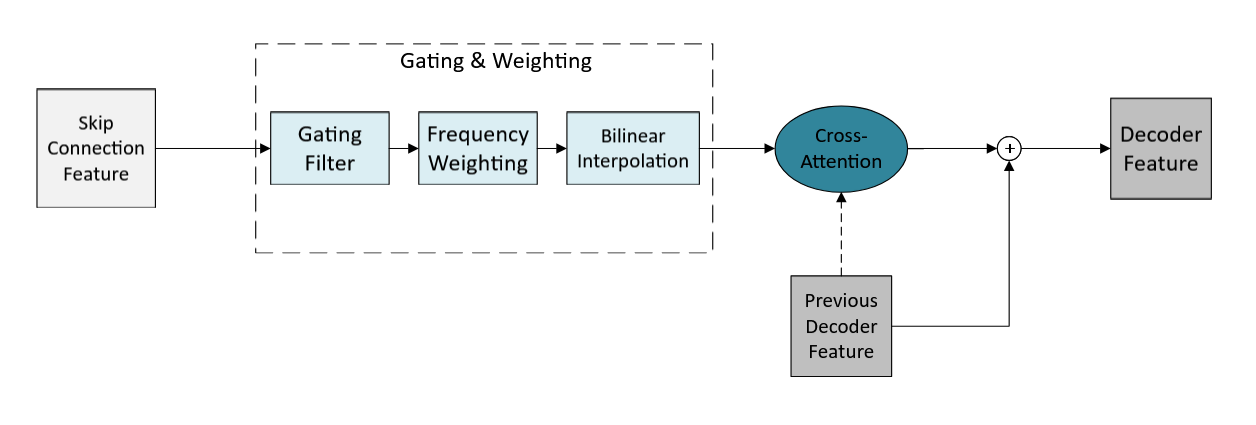 图4展示了EAGC模块,包括频率加权门控、交叉注意力(以解码器状态D为查询)以及处理分辨率差异的双线性插值步骤,说明了其如何智能地选择和传递编码器特征。
图4展示了EAGC模块,包括频率加权门控、交叉注意力(以解码器状态D为查询)以及处理分辨率差异的双线性插值步骤,说明了其如何智能地选择和传递编码器特征。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:提出专用于生物声学的信号增强网络,三个核心模块(MSDA, BHME, EAGC)设计有针对性,BHME和EAGC具有一定新颖性。但整体架构仍基于成熟的编码器-解码器和注意力框架,创新性在于“领域适应性设计”而非“基础理论突破”。
- 技术正确性:各模块设计逻辑清晰,公式和实验指标定义准确。
- 实验充分性:在三个不同动物类别的测试集上进行了充分的对比实验和消融实验,使用了多个标准评价指标,并报告了计算复杂度(FLOPs),实验设计较为全面。消融实验中“CSCConv-AE+MSDA”结果的矛盾(SNR为负)是一个小瑕疵,但可能源于过拟合或指标特性。
- 证据可信度:实验设置(硬件、损失函数、学习率)有说明,对比模型均为公认的相关工作,结果可复现。但未提供训练步数等更多细节。
- 选题价值:1.5/2
- 前沿性与潜在影响:生物声学信号增强是生态监测、生物多样性保护中的关键技术瓶颈,该研究直接针对这一有实际需求的垂直领域,填补了专用模型的空白,具有明确的应用前景和积极影响。
- 与音频/语音读者相关性:为音频/语音处理领域的研究者提供了如何将现有技术迁移、适配到新领域(动物声音)的范例,其中的模块设计(如谐波增强、智能门控)对处理其他非语音音频(如机械故障声、鸟类监测)也有启发意义。
- 开源与复现加成:0/1
- 论文未提供代码仓库、预训练模型权重或具体的训练配置文件。虽然描述了模型架构和训练参数,但缺乏关键超参数(如卷积核具体尺寸、注意力头数)和训练细节(如优化器、确切的epoch数),这给完全复现带来了一定难度。因此不给加成。