📄 Beyond Face Swapping: A Diffusion-Based Digital Human Benchmark for Multimodal Deepfake Detection
#音频深度伪造检测 #多模态模型 #基准测试 #扩散模型 #数据集
🔥 8.1/10 | 前25% | #音频深度伪造检测 | #多模态模型 | #基准测试 #扩散模型
学术质量 6.0/7 | 选题价值 1.8/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文标注Jiaxin Liu†和Jia Wang†贡献相等,未明确谁为第一)
- 通讯作者:Saihui Hou⋆, Zhaofeng He⋆
- 作者列表:Jiaxin Liu(北京邮电大学,BUPT)、Jia Wang(北京师范大学,BNU)、Saihui Hou(未说明具体机构,可能来自BUPT或BNU)、Min Ren(滴滴出行,Didi Chuxing)、Huijia Wu(滴滴出行,Didi Chuxing)、Long Ma(未说明)、Renwang Pei(未说明)、Zhaofeng He(未说明具体机构,可能来自BUPT或BNU)
💡 毒舌点评
亮点在于构建了第一个专门为评估“扩散模型驱动的数字人”伪造而设计的大规模多模态数据集(DigiFakeAV),数据生成流程严谨,有效暴露了现有检测器的脆弱性,为领域提供了急需的试金石。短板则是提出的检测方法DigiShield虽然有效,但更像一个验证多模态融合有效性的“基线”而非一个具有颠覆性的新架构,且其在DigiFakeAV上80.1%的AUC也说明“道高一尺,魔高一丈”,真正的安全挑战远未解决。
🔗 开源详情
- 代码:论文中提及项目主页
https://hubeiwuhanliu.github.io/DigiFakeAV.github.io/,但未明确是否提供代码仓库链接。 - 模型权重:未提及是否公开DigiShield或其他模型的权重。
- 数据集:通过项目主页
https://hubeiwuhanliu.github.io/DigiFakeAV.github.io/提供获取信息,表明将开源。 - Demo:未提及在线演示。
- 复现材料:给出了部分实现细节(如预处理、骨干网络ResNet-50、采样30帧、数据增强),但缺乏关键训练超参数(优化器、学习率等),复现材料不完整。
- 论文中引用的开源项目:引用了多个作为数据生成和对比的方法/模型,如Sonic [8], Hallo [5], EchoMimic [4], CosyVoice 2 [16], 以及基线检测器如Meso4 [19], Xception [2]等。
📌 核心摘要
要解决什么问题:现有深度伪造检测数据集和技术主要针对过时的面交换方法,无法有效评估和应对由扩散模型生成的、具有高度真实性和多模态一致性的新一代数字人伪造,导致现有检测器性能在现实威胁面前大幅下降。
方法核心是什么:本文提出两个核心贡献:a) 构建DigiFakeAV,一个包含6万视频的大规模多模态数据集,由5种前沿扩散模型生成,注重多样性、场景真实性和音视频同步质量。b) 提出DigiShield检测框架,采用双流网络分别提取视觉和音频的时空特征,并通过跨模态注意力和自注意力机制进行融合,以捕获微妙的跨模态不一致性。
与已有方法相比新在哪里:a) 数据集是第一个基于扩散模型、强调多模态一致性和场景多样性的伪造检测基准。b) 检测方法显式地建模了视频与音频在时空维度上的对齐关系,旨在应对扩散伪造的高一致性挑战。
主要实验结果如何:
- 现有9种检测器在DigiFakeAV上性能急剧下降,例如SFIConv从在DF-TIMIT上100%的AUC降至71.2%,SSVF从94.5%降至51.0%。
- DigiShield在DigiFakeAV上达到80.1% AUC,比此前最佳方法SFIConv(71.2%)高出8.9个百分点。
- 消融研究显示,引入音频模态和对比损失将AUC从73.6%提升至77.4%,再加入自监督自注意力进一步提升至80.1%。 关键实验结果表格如下:
表2:各种方法在现有数据集和DigiFakeAV上的AUC分数(%)
方法 DF-TIMIT FF-DF DFDC Celeb-DF FakeAVCeleb DigiFakeAV (ours) Meso4 87.8 68.4 84.7 75.3 54.8 60.9 MesoInception4 80.4 62.7 83.0 73.2 53.6 61.7 Xception-c23 95.9 94.4 99.7 72.2 65.3 72.5 Capsule 78.4 74.4 96.6 53.3 57.5 70.9 HeadPose 55.1 53.2 47.3 55.9 54.6 49.0 F3-Net 99.8 99.4 93.7 95.1 86.7 91.3 Cross Efficient ViT 50.4 55.8 99.1 95.1 86.7 80.5 SSVF - - - - - 94.5 SFIConv 100.0 100.0 95.9 96.7 95.8 93.0 注:该表展示了现有方法在多个数据集上的性能,凸显其在DigiFakeAV上性能的普遍大幅下滑。 表3:DigiShield与基线方法在DigiFakeAV和DF-TIMIT上的AUC分数对比
方法 DigiFakeAV DF-TIMIT-LQ DF-TIMIT-HQ MesoInception4 63.8 80.4 62.7 Capsule 65.3 78.4 74.4 Xception-c23 66.1 95.9 94.4 F3-Net 66.4 99.8 99.4 SFIConv 71.2 100.0 100.0 DigiShield (ours) 80.1 100.0 100.0 注:该表对比了本文提出的方法与之前最佳方法的性能,显示DigiShield在DigiFakeAV上的优势及在传统数据集上的强泛化性。 实际意义是什么:为学术界和工业界评估对抗最新AI生成威胁的能力提供了标准化的挑战平台(DigiFakeAV),并建立了新的检测基线(DigiShield),推动深度伪造检测技术向应对多模态、高真实性伪造的方向发展。
主要局限性是什么:a) 检测方法DigiShield虽为当前最佳,但80.1%的AUC表明在面对高质量扩散伪造时仍存在显著挑战。b) 数据集主要聚焦于语音驱动的数字人,可能未涵盖其他交互形式的扩散伪造。c) 论文未讨论检测方法在不同肤色、年龄群体上的公平性分析,尽管数据集已努力保证人口统计学平衡。
🏗️ 模型架构
DigiShield的架构如图2所示,是一个典型的双流多模态融合网络。
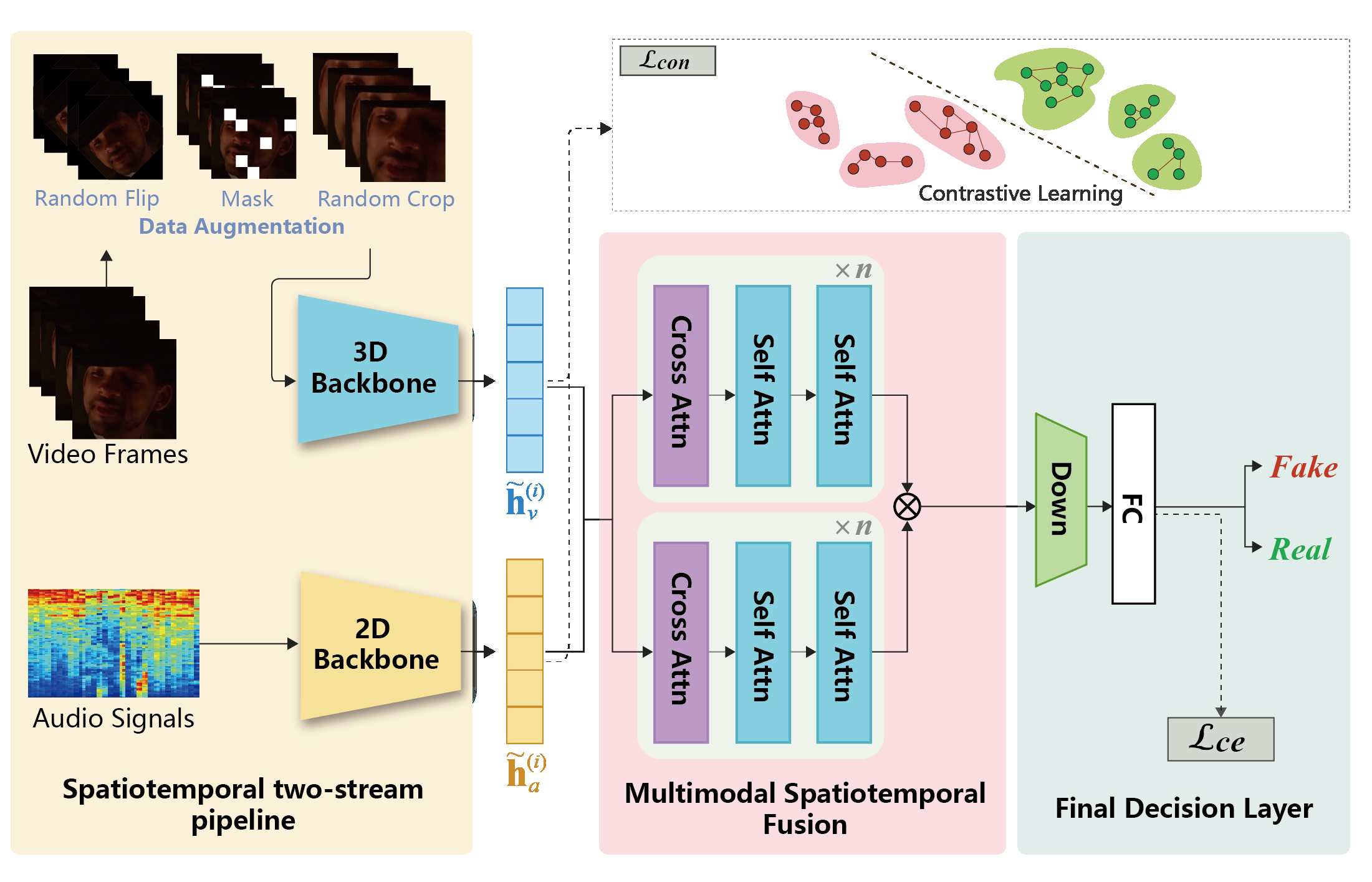 整体流程:输入为视频片段和对应的音频信号(转为梅尔频谱)。视频流和音频流分别通过各自的编码器提取特征,然后经过多模态时空融合模块,最后进行二分类判断真伪。
整体流程:输入为视频片段和对应的音频信号(转为梅尔频谱)。视频流和音频流分别通过各自的编码器提取特征,然后经过多模态时空融合模块,最后进行二分类判断真伪。
时空双流管道 (Spatiotemporal Two-Stream Pipeline):
- 视频流:输入视频片段 $x_v^{in} \in \mathbb{R}^{T \times C \times H_v \times W_v}$。使用ResNet-50作为视觉编码器 $F_v$,提取时空特征图 $f_v$。ResNet-50的卷积层和池化层将原始视频帧转换为高级视觉特征表示。
- 音频流:输入音频的梅尔频谱 $x_a^{in} \in \mathbb{R}^{C \times H_a \times W_a}$。使用一个基于卷积的音频编码器 $F_a$(论文未说明具体架构,可能为时频卷积网络)提取音频特征图 $f_a$。
- 动机:视频和音频的伪造痕迹可能出现在不同维度(如视频的时间连贯性、音频的频谱细节),双流结构允许模型分别学习各自模态的深层表示。
多模态时空融合 (Multimodal Spatiotemporal Fusion):
- 将提取的视觉特征图 $f_v$ 和音频特征图 $f_a$ 展平为序列形式:$ef_v \in \mathbb{R}^{N_v \times d}$, $ef_a \in \mathbb{R}^{N_a \times d}$,其中 $d$ 为特征维度。
- 跨模态注意力 (Cross-Attention):计算 $z_{va} = \text{CrossAtt}(Q=ef_v, K=ef_a, V=ef_a)$。这使得视觉特征能够主动查询音频特征中与之相关的信息,从而捕获音视频之间的一致性或不一致性。
- 自监督自注意力 (Self-Attention):对跨模态交互后的特征 $z_{va}$ 再进行自注意力计算:$z = \text{SelfAtt}(Q=z_{va}, K=z_{va}, V=z_{va})$。这有助于在序列内部建模更丰富的时空上下文依赖关系,增强时序建模能力。
- 设计选择:先跨模态对齐,再进行序列内建模,这种设计逻辑清晰地让模型先学习“什么该对齐”,再学习“序列内如何连贯”。
最终决策层 (Final Decision Layer):将融合后的特征表示与原始的音频/视频特征(或经过处理的版本)拼接,输入一个全连接层,输出二分类概率(真/假)。
💡 核心创新点
- 构建首个扩散模型数字人伪造基准 (DigiFakeAV):不同于以往基于GAN或面交换的数据集,这是第一个专门针对当前主流扩散模型(Sonic, Hallo等)生成的数字人伪造数据构建的大规模(6万视频)、多模态(音视频)基准。它更接近真实世界新兴威胁。
- 强调多模态一致性与场景多样性:数据集在生成时严格保证唇音同步、表情与语音韵律匹配,远超以往Wav2Lip驱动的数据集。同时,视频涵盖新闻、社交媒体等多种场景,并注重性别、肤色、国籍的平衡,减少了偏差。
- 提出针对性的多模态时空融合检测框架 (DigiShield):为了应对扩散伪造的高一致性挑战,DigiShield显式地设计了跨模态注意力机制来对齐音视频特征,并引入自注意力来增强时序建模。消融实验证明了这两个组件对性能提升的贡献。
🔬 细节详述
- 训练数据:
- 数据集:DigiFakeAV,包含10,000个真实视频(RV-RA),25,000个假视频-真音频(FV-RA),25,000个假视频-假音频(FV-FA),总计60,000个视频(840万帧)。
- 数据来源:原始视频来自HDTF和CelebV-HQ数据集。
- 合成工具:视频由Sonic, Hallo, Hallo2, EchoMimic, V-Express五种扩散模型生成;音频由CosyVoice 2合成(用于FV-FA部分)。
- 预处理:使用RetinaFace进行人脸检测和裁剪;音频重采样至16kHz;添加现实噪声和压缩。
- 数据增强:训练时采用随机裁剪等增强策略。
- 划分:训练集、验证集、测试集按8:1:1划分,且无身份重叠。
- 损失函数:
- 对比损失 (Lcon):$L_{con} = \frac{1}{N} \sum_{i=1}^{N} [y_i D(eh_v^{(i)}, eh_a^{(i)})^2 + (1 - y_i) \max(0, m - D(eh_v^{(i)}, eh_a^{(i)}))^2]$。其中 $y_i$ 是标签,$D$ 是欧氏距离,$m$ 是间隔参数。该损失旨在拉近真实样本的音视频特征,推远伪造样本的特征。
- 交叉熵损失 (Lce):标准的二分类交叉熵损失。
- 总损失:$L_{total} = L_{con} + L_{ce}$。
- 训练策略:
- 优化器:论文未说明。
- 学习率、warmup、batch size:论文未说明。
- 训练步数/轮数:论文未说明。
- 调度策略:论文未说明。
- 关键超参数:
- 视觉编码器:ResNet-50。
- 每个视频采样帧数:30帧。
- 注意力机制:使用了跨模态注意力和自监督自注意力。
- 训练硬件:论文未说明。
- 推理细节:论文未说明解码策略等细节,仅提到使用测试集进行评估。
- 正则化技巧:论文未提及Dropout等具体正则化技术。
📊 实验结果
论文在DigiFakeAV和DF-TIMIT数据集上进行了全面的实验,主要结论如下:
现有检测器在新数据集上失效:如表2所示,所有9种被评估的先进检测器在DigiFakeAV上的AUC均大幅低于其在旧数据集上的表现。例如,混合域方法SFIConv从DF-TIMIT-HQ的100%降至71.2%;多模态方法SSVF在FakeAVCeleb上的94.5%暴跌至51.0%,几乎等同于随机猜测。这直接证明了DigiFakeAV的挑战性和现有技术的不足。
DigiShield性能领先:如表3所示,DigiShield在DigiFakeAV上达到80.1% AUC,显著优于此前最佳方法SFIConv(71.2%)。同时,DigiShield在传统数据集DF-TIMIT上保持了100% AUC,展示了其强大的泛化能力。
消融研究验证设计:表4的消融研究清晰地展示了模型各组件的贡献:
- 仅视觉流+Lce:AUC 73.6%。
- 加入音频流和Lcon:AUC提升至77.4%,证明了音频信息和对比学习对捕获跨模态不一致性的价值。
- 再加入跨模态注意力 (CrossAtt) 和自注意力 (SelfAtt):AUC达到80.1%,表明对齐建模和时序建模的进一步提升。
表4:DigiShield在DigiFakeAV上的消融研究
Lce Lcon CrossAtt SelfAtt AUC ✓ 73.6 ✓ ✓ ✓ 77.4 ✓ ✓ ✓ ✓ 80.1
⚖️ 评分理由
- 学术质量:6.0/7:工作扎实,系统性强。数据集构建是主要贡献,方法合理但创新性中等。实验设计充分(跨数据集、消融研究),结果可信。扣分点在于检测方法架构的独创性有限,且最终性能指标(80.1%)表明问题远未解决。
- 选题价值:1.8/2:选题紧扣深度伪造技术发展的最前沿,直面扩散模型带来的新威胁。构建的基准数据集对整个社区具有重要的指导和推动作用,实际应用意义重大。
- 开源与复现加成:0.3/1:提供了数据集项目主页,这是一个重要贡献。但论文本身未提供代码、模型权重、完整的训练���置和超参数,严重影响了独立复现的可能性。