📄 Beamforming Using Virtual Microphones for Hearing Aid Applications
#语音增强 #波束成形 #麦克风阵列 #助听器 #低复杂度
✅ 7.5/10 | 前50% | #语音增强 | #波束成形 | #麦克风阵列 #助听器
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Mojtaba Farmani(Eriksholm Research Centre, Snekkersten, Denmark; Department of Electronic Systems, Aalborg University, Aalborg, Denmark)
- 通讯作者:未说明
- 作者列表:Mojtaba Farmani(Eriksholm Research Centre & Aalborg University)、Svend Feldt(Eriksholm Research Centre)、Jesper Jensen(Eriksholm Research Centre)
💡 毒舌点评
论文的核心亮点在于将虚拟麦克风的生成从复杂的相位-幅度分离插值(如GAI)或依赖几何信息的建模,简化为一个基于WDO假设的幂函数模型(式4),理论推导优雅且计算成本极低,非常适合助听器芯片。短板在于,作为一篇声称“ superior performance ”的论文,其对比基线(GAI和扩展GAI)略显保守,未与近年来性能更强的基于神经网络的虚拟麦克风方法进行直接对比,削弱了“SOTA”宣称的说服力。
🔗 开源详情
论文中未提及代码、模型权重、数据集的任何公开信息,也未提及Demo或复现材料。论文中引用了多个开源项目或方法(如GAI [2],扩展GAI [1],MVDR [15]),但未说明是否基于它们的开源实现。
📌 核心摘要
该论文旨在解决助听器因物理麦克风数量受限而影响波束成形性能的问题。其核心方法是利用W-disjoint正交性(WDO)假设,提出一种低复杂度的虚拟麦克风信号生成算法。该算法将虚拟麦克风与参考麦克风之间的相对传输函数(RTF)建模为两物理麦克风间RTF的幂函数(式4),通过一个参数λ即可控制虚拟麦克风位置,实现插值与外推。与已有的广义幅度插值(GAI)等方法相比,新方法无需分离处理相位和幅度,计算更简单,且能外推至物理阵列连线之外。论文在420个基于真实助听器录音的声学场景(含消声室、演播室、会议室;食堂、火车、办公室、街道等噪声;-5dB至15dB SNR)上进行评估。实验表明,将生成的虚拟麦克风信号(例如取λ=-4)整合到MVDR波束成形器中,相比仅用双物理麦克风的基线,在分段信噪比(ISNR)和客观语音可懂度(ESTOI)上均有显著提升,最高ISNR改善可达3 dB(图4a)。通过调整λ优化虚拟麦克风位置(如置于用户前方)可获得额外性能增益(图2)。该方法的实际意义在于能在不增加助听器硬件成本和功耗的前提下,有效提升降噪与语音清晰度。主要局限性在于其性能依赖于WDO假设的近似性,在强混响或多说话人干扰下可能减弱,且目前的虚拟麦克风位置优化是一维的(沿两麦克风连线),可能非全局最优。
🏗️ 模型架构
该论文的核心并非传统意义上的神经网络架构,而是一个基于信号处理理论的虚拟麦克风生成框架,其目的是为后端的波束成形器生成额外的输入通道。完整流程如下:
- 输入:来自两个物理麦克风的带噪语音信号 Y₁(k, l) 和 Y₂(k, l)。
- RTF估计:在WDO假设下,利用式(5)实时估计物理麦克风间的相对传输函数 D₂(k, l)。该估计基于信号的统计特性,使用指数移动平均实现。
- 虚拟麦克风信号合成:
- 核心创新模块:基于式(4),通过将估计的 RTF D₂(k, l) 取 λ 次幂来生成虚拟麦克风位置处的 RTF D₃(k, l)。
- 生成虚拟信号:利用式(3),将参考麦克风信号 Y₁(k, l) 乘以估算出的 D₃(k, l),得到虚拟麦克风信号 Y₃(k, l)。通过选择不同的λ值(如图1所示),可以在两物理麦克风之间(插值,0<λ<1)或其外侧(外推,λ>1或λ<0)合成功信号。
- 波束成形:将两个物理麦克风信号和一个或多个虚拟麦克风信号合并成向量 Y(k, l),输入MVDR波束成形器(式6)。该波束成形器使用语音和噪声帧估计的协方差矩阵(式7,8)来计算权重 w(k, l),最终输出增强后的语音。 关键设计选择及其动机:
- 幂函数模型(式4):这是最重要的设计。在远场自由场假设下,RTF的相位部分与距离成线性关系,幅度部分与距离成反平方关系。将RTF进行λ次幂运算,能够同时、且近似线性地缩放相位延迟和衰减幅度,从而在数学上简洁地模拟了位置缩放,避免了GAI方法中分别插值相位和幅度的复杂性和潜在不一致性。
- WDO假设:简化了信号模型,使得RTF可以通过简单的统计平均(式5)来估计,这是整个方法低复杂度的基础。
- 可扩展的虚拟麦克风数量:通过选择多个不同的λ值,可以合成本文实验中的“2mic + 2vm”配置,展示了方法的可扩展性。
💡 核心创新点
- 基于幂函数的统一RTF缩放模型:将虚拟麦克风RTF建模为物理麦克风RTF的幂(D₃ = (D₂)^λ)。这是与之前GAI类方法最根本的区别,实现了对相位和幅度的联合、简洁建模,大幅降低了计算复杂度。
- 低复杂度且灵活的虚拟位置外推:该模型仅通过调整一个标量参数λ,就能在两物理麦克风连线(甚至连线外)的任意位置生成虚拟麦克风信号,突破了传统插值方法仅能工作于阵列内部的限制,增强了波束成形器的空间滤波自由度。
- 针对助听器场景的端到端优化与验证:论文没有停留在信号合成层面,而是将虚拟麦克风生成完整集成到助听器常用的MVDR波束成形流水线中,并在涵盖助听器典型使用场景的大规模、多样化真实录音数据集上进行了系统评估,验证了其在实际应用中的有效性和鲁棒性。
🔬 细节详述
- 训练数据:论文未使用“训练”一词,因为是传统信号处理方法。数据为“评估用”:使用了佩戴助听器外壳和头躯模拟器(HATS)在三种环境(消声室、低混响录音棚、混响会议室)录制的语音,以及四种真实环境(食堂、火车、办公室、街道)录制的噪声。所有信号在20kHz采样。总计生成420个独立的双耳声学场景(840单声道场景),SNR范围-5dB至15dB。论文未提供数据集名称或公开下载链接。
- 损失函数:不适用(非机器学习方法)。
- 训练策略:不适用。参数估计(如式5的期望)使用指数移动平均,时间常数为20ms。波束成形器的协方差矩阵估计也使用指数移动平均,时间常数为159ms。
- 关键超参数:
- STFT参数:帧长128采样点(6.4ms),重叠108采样点,128点FFT。这确保了低延迟,适合助听器。
- 窗函数:平方根汉宁窗(分析与合成)。
- 虚拟麦克风位置参数λ:实验测试了λ = -0.5(前),0.5(中),1.5(后),-3,-4等值。最终性能对比中使用λ=-4(单虚拟麦克风)和λ=-3与-4(双虚拟麦克风)。
- VAD:使用了“理想VAD”,以瞬时SNR是否大于0为准则。
- 训练硬件:未说明。论文为算法验证,未涉及深度学习训练。
- 推理细节:整个流程在STFT域逐帧处理,为流式处理架构。RTF估计、波束成形器权重计算均为在线自适应过程。
- 正则化或稳定技巧:在式(4)中,为避免计算负指数幂,当虚拟麦克风位于前麦克风前方时,建议将后麦克风(Mic.2)选为参考麦克风,以确保数值稳定。
📊 实验结果
论文评估了MVDR波束成形器在配置虚拟麦克风前后的性能,主要指标为分段信噪比改善(ISNR)和扩展短时客观可懂度(ESTOI)。
主要性能对比(来自图4描述):
| 配置 | 输入SNR (图4a) | 噪声类型 (图4b) | 混响等级 (图4c) | 关键结论 |
|---|---|---|---|---|
| 2mic (基线) | 性能最差 | 性能最差 | 性能最差 | 基线性能 |
| GAI (2mic+vm) | 优于基线 | 优于基线 | 优于基线 | 有一定提升 |
| Ext. GAI (2mic+vm) | 优于基线,与GAI相当 | 优于基线 | 优于基线 | 提升有限 |
| Proposed (2mic+vm, λ=-4) | 显著优于所有基线 | 显著优于所有基线 | 显著优于所有基线 | ISNR改善最高达3 dB |
| Proposed (2mic+2vm, λ=-3,-4) | 性能最优 | 性能最优 | 性能最优 | 添加第二个虚拟麦克风带来进一步提升 |
关键图表与结论:
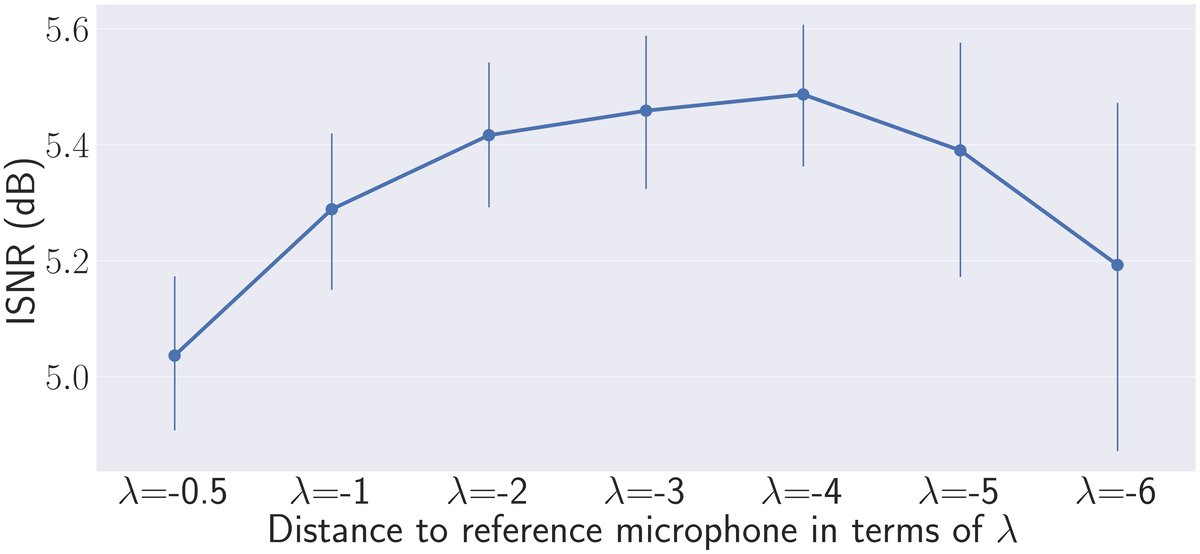 图2结论:虚拟麦克风位置对不同方位角的目标效果不同。将VM放在用户前方(λ=-0.5)对正前方(0°)目标ISNR提升最大;放在后方(λ=1.5)对后方(180°)目标效果最佳。这符合SNR在VM最接近目标时最高的直觉。对于助听器,推荐将VM置于前方。
图2结论:虚拟麦克风位置对不同方位角的目标效果不同。将VM放在用户前方(λ=-0.5)对正前方(0°)目标ISNR提升最大;放在后方(λ=1.5)对后方(180°)目标效果最佳。这符合SNR在VM最接近目标时最高的直觉。对于助听器,推荐将VM置于前方。
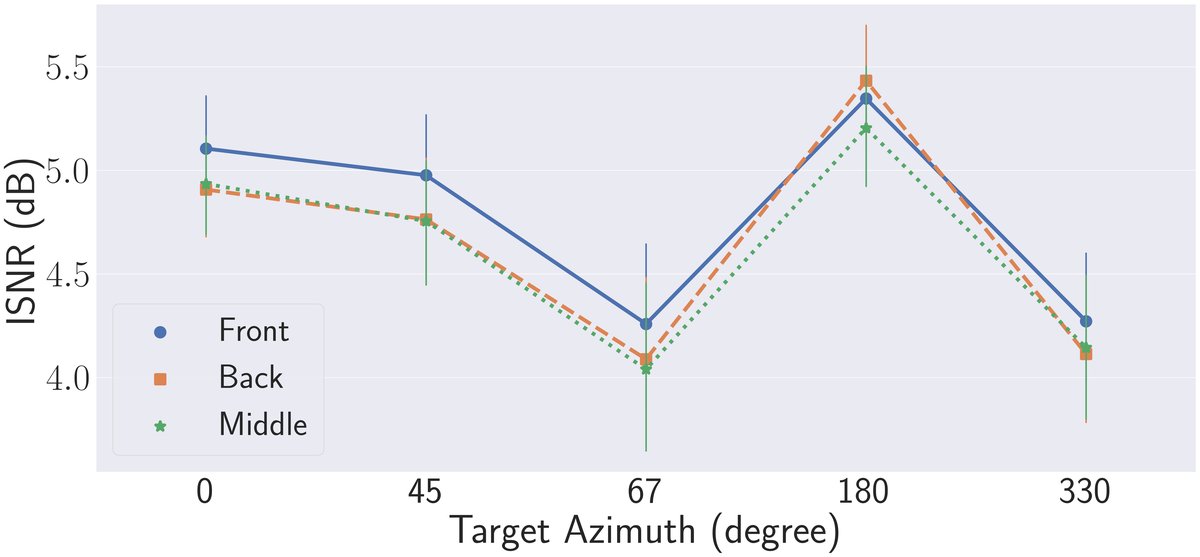 图3结论:随着|λ|增大(VM远离参考麦克风),ISNR先提升后下降。性能在λ=-4左右达到峰值。这表明增大虚拟阵列孔径有助于提升空间分辨率,但距离过大会导致空间混叠,性能下降。最优λ可能随频率变化。
图3结论:随着|λ|增大(VM远离参考麦克风),ISNR先提升后下降。性能在λ=-4左右达到峰值。这表明增大虚拟阵列孔径有助于提升空间分辨率,但距离过大会导致空间混叠,性能下降。最优λ可能随频率变化。
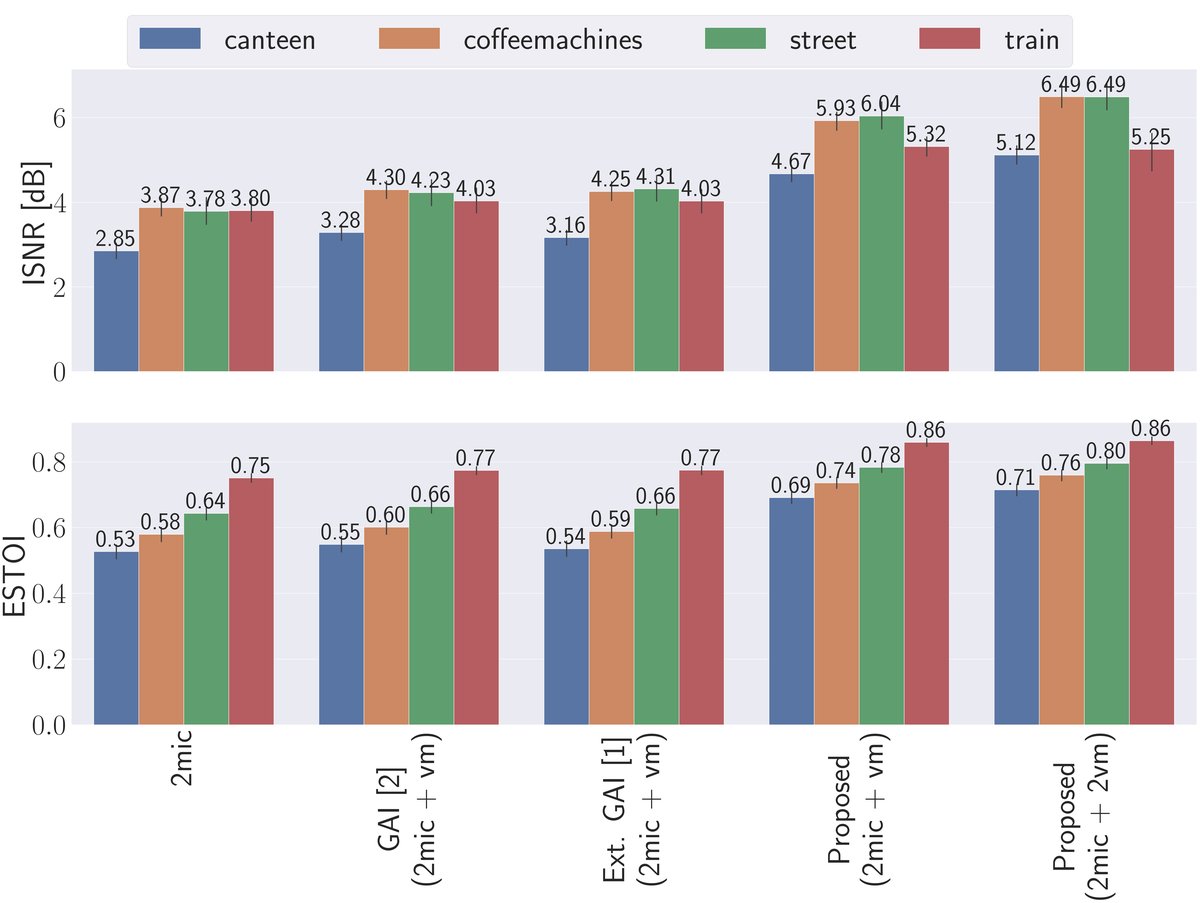 图4结论:在所有测试维度上,所提方法(尤其是使用两个虚拟麦克风时)都显著优于基线和GAI方法。其性能在各种输入SNR、不同噪声类型(包括可能削弱WDO假设的多说话人噪声)以及不同混响水平下都保持鲁棒。
图4结论:在所有测试维度上,所提方法(尤其是使用两个虚拟麦克风时)都显著优于基线和GAI方法。其性能在各种输入SNR、不同噪声类型(包括可能削弱WDO假设的多说话人噪声)以及不同混响水平下都保持鲁棒。
⚖️ 评分理由
- 学术质量:6.0/7。论文理论基础扎实(WDO假设、RTF幂函数模型),推导清晰。实验设计周到,使用了大规模、多样化的真实场景录音数据进行评估,对比了合理的基线,并进行了位置和距离的消融分析(图2,图3),证据充分且可信。主要扣分点在于方法本身是对现有信号处理思想的巧妙应用与简化,创新幅度属于渐进式而非突破性;同时,如前所述,与性能可能更强的神经网络基线缺失对比,使得其声称的“ superior performance ”范围受限。
- 选题价值:1.5/2。选题直接针对助听器这一重要且需求明确的应用,解决硬件受限的核心痛点。虚拟麦克风技术具有明确的实用价值和产业化前景。扣分点在于该技术领域相对垂直,对更广泛的音频处理社区(如通用语音增强、智能设备等)的辐射影响可能有限。
- 开源与复现加成:0/1。论文完全未提及代码、模型、数据集公开或任何复现支持计划。尽管文中提供了部分算法参数,但缺乏完整的数据集描述和评估代码,使得完全复现其全部实验结果存在较大困难。