📄 B-GRPO: Unsupervised Speech Emotion Recognition Based on Batched-Group Relative Policy Optimization
#语音情感识别 #强化学习 #自监督学习 #多语言
✅ 6.5/10 | 前50% | #语音情感识别 | #强化学习 | #自监督学习 #多语言
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Yingying Gao(中国移动研究院;北京大学多媒体信息处理国家重点实验室)
- 通讯作者:未说明
- 作者列表:Yingying Gao(中国移动研究院;北京大学多媒体信息处理国家重点实验室)、Shilei Zhang(中国移动研究院;北京大学多媒体信息处理国家重点实验室)、Runyan Yang(中国移动研究院;北京大学多媒体信息处理国家重点实验室)、Zihao Cui(中国移动研究院;北京大学多媒体信息处理国家重点实验室)、Junlan Feng(中国移动研究院;北京大学多媒体信息处理国家重点实验室)
💡 毒舌点评
这篇论文巧妙地将强化学习中的“组相对优势”思想从生成任务迁移到了分类任务的样本选择上,为无监督语音情感识别提供了一个新颖且有一定效果的框架。然而,其核心的“自奖励”函数高度依赖模型自身的置信度,缺乏外部验证,容易陷入“自信地犯错”的循环;此外,论文声称“无监督”,但实际需要一半的标注数据进行预训练,这削弱了其在“零标注”场景下的说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开数据集(IEMOCAP, CASIA, CAFE, MELD, M3ED),但论文未说明具体获取方式或预处理脚本。
- Demo:未提供。
- 复现材料:部分复现细节已给出(模型结构、学习率、批量大小、训练轮数),但关键奖励函数参数、优化器、数据划分细节、训练硬件等信息缺失。
- 论文中引用的开源项目:引用了Emobox[17]工具包(用于实验实现)和多个预训练模型:SenseVoice[18]、Emotion2vec[10]、Whisper[19]。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
本文针对无监督语音情感识别中数据稀疏和标注偏差问题,提出了一种基于批量组相对策略优化(B-GRPO)的强化学习方法。方法核心是将训练过程视为长期决策,将是否使用一个样本作为动作,将一个批次内的样本作为一组,通过计算组内相对优势来优化策略。与标准GRPO不同,B-GRPO无需为同一个输入生成多个候选输出。论文提出了自奖励函数(基于模型预测的最大似然概率)和教师奖励函数(引入外部模型验证)来评估样本质量,以替代依赖真实标签的可验证奖励。实验在五个多语言数据集上表明,B-GRPO相比无RL的基线方法平均提升了19.8%的宏F1分数,相比DINO等自监督方法也平均提升了10.3%。研究发现,自奖励函数在整体表现上优于教师奖励函数。该方法的实际意义在于提供了一种利用大量未标注数据提升情感识别性能的有效途径。主要局限性在于奖励函数的设计较为启发式,且模型的初始训练仍需依赖部分标注数据。
🏗️ 模型架构
B-GRPO是一个用于训练语音情感识别(SER)分类器的强化学习框架。其整体架构可概括为:
- 策略模型(Policy Model):这是一个标准的分类器。输入为由预训练语音编码器(如SenseVoice)提取的语音特征(取最后一层Transformer输出的帧级特征平均)。策略模型内部结构为两个线性隐藏层(隐藏维度128),中间由ReLU激活函数连接,输出层为Softmax,产生对N个情绪类别的概率分布。
- 优势计算(Advantage Calculation):核心改造点。将一个批次(Batch)的所有样本视为一个“组”。对于批次内的第i个样本,计算其奖励
r_i,然后计算该批次奖励的均值¯r_i和标准误差ˆr_i。其优势函数Â_i定义为:若原始优势A_i = (r_i - ¯r_i) / ˆr_i大于0,则Â_i = A_i;否则为0。 - 奖励函数(Reward Functions):
- 自奖励函数:完全基于策略模型自身的输出。
r1是一个阈值奖励:若最大类别概率max(p(n|q_i))超过阈值δ,则给予常数奖励C,否则为0。r2则直接将最大概率值作为奖励分数。 - 教师奖励函数:引入一个不参与训练的外部教师模型(如Emotion2vec)。
r3在策略模型与教师模型预测类别一致时给予奖励C。r4要求同时满足r1和r3的条件。r5基于策略模型与教师模型输出概率分布的KL散度。
- 自奖励函数:完全基于策略模型自身的输出。
- 策略优化:使用修改后的GRPO损失函数(公式7)更新策略模型参数。该损失是策略梯度损失和KL散度正则化项(约束策略模型与参考模型π_ref的分布,π_ref为训练开始前的初始模型)的加权和,并使用了PPO中的裁剪技巧以稳定训练。
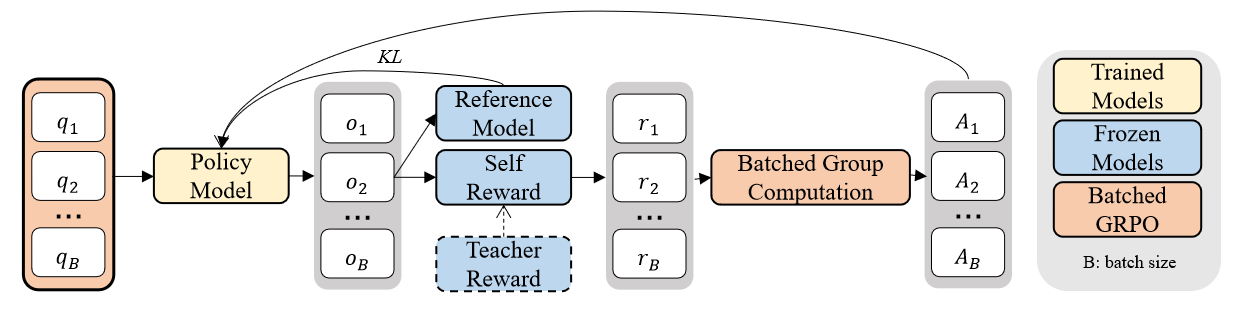 图1:B-GRPO框架。图中橙色框展示了B-GRPO的核心:将一个批次(Batch)的样本作为一组(Group),通过计算组内奖励的均值来归一化每个样本的优势(Advantage)。策略模型(Policy Model)输出情绪概率,并根据自奖励或教师奖励函数获得奖励。最终通过策略梯度更新模型。
图1:B-GRPO框架。图中橙色框展示了B-GRPO的核心:将一个批次(Batch)的样本作为一组(Group),通过计算组内奖励的均值来归一化每个样本的优势(Advantage)。策略模型(Policy Model)输出情绪概率,并根据自奖励或教师奖励函数获得奖励。最终通过策略梯度更新模型。
💡 核心创新点
- 将GRPO从生成任务适配到分类任务:标准GRPO用于语言模型生成,通过一个查询的多个生成结果计算优势。B-GRPO的核心创新在于将“组”的概念从“同一个查询的多个响应”转变为“同一个批次的多个样本”,从而使其适用于预测结果固定的分类任务。
- 无标签的样本质量评估机制(自奖励函数):提出基于模型自身预测置信度(最大概率)的奖励函数(r1, r2),无需任何人工标注或外部真实标签,即可在强化学习框架内筛选“高质量”样本进行训练。
- 引入教师模型提供额外监督信号(教师奖励函数):构建了一个独立的、使用不同特征提取器的教师模型,通过预测一致性(r3, r4)或分布相似性(r5)为学生策略模型提供奖励,作为一种自监督信号。
- 优势函数的正向筛选(Positive Advantage):在计算优势时,将负的优势值强制归零,只利用那些奖励高于批次平均水平的样本进行更新,旨在更直接地学习“好样本”的模式。
🔬 细节详述
- 训练数据:
- 预训练阶段:使用IEMOCAP、CASIA、CAFE、MELD、M3ED五个数据集中每个数据集一半的标注数据,对策略模型进行100个epoch的监督学习预训练。
- B-GRPO训练阶段:使用同一数据集的另一半未标注数据,进行100个epoch的B-GRPO训练。
- 数据集信息:五个数据集,涵盖英语(IEMOCAP, MELD)、法语(CAFE)、普通话(CASIA, M3ED)。所有标注映射到6类情绪:中性、愤怒、惊讶、悲伤、快乐、恐惧。使用Emobox工具包进行预处理。
- 损失函数:核心是公式(7)定义的B-GRPO损失,包含策略梯度损失(带裁剪)和KL散度正则化项。其中KL散度项计算方式为公式(8),是参考模型概率除以策略模型概率再减去其对数再减1。奖励函数为上述的r1-r5。
- 训练策略:
- 优化器:未说明。
- 学习率:1e-4。
- 批量大小(Batch Size):32或64(作者测试认为平衡性最佳)。
- 训练轮数:监督预训练100 epochs,B-GRPO训练100 epochs,共200 epochs。
- 关键超参数:
- 策略模型/教师模型结构:两个线性隐藏层,隐藏维度128,中间ReLU激活。
- 奖励函数相关:常数奖励C的值未明确(消融实验表明2和-1差异不大,但最终实验取C=1)。阈值δ(自奖励r1)在消融实验中为0.5。阈值θ(教师奖励r5)未说明。
- 训练硬件:未说明。
- 推理细节:推理时使用训练好的策略模型对语音特征进行一次前向传播,取最大概率对应的情绪类别作为预测结果,无需解码策略。
- 正则化/稳定技巧:使用了PPO中的裁剪技巧(
clip(..., 1-ε, 1+ε))来限制策略更新的幅度,ε未说明。在优势函数中排除了负优势,也是一种隐式的样本筛选正则化。
📊 实验结果
论文在五个数据集上进行了宏F1分数的评估。
表1. 与基线方法对比(F1%)
| 方法 | IEMOCAP | CASIA | CAFE | MELD | M3ED |
|---|---|---|---|---|---|
| Baseline (无RL) | 67.7 | 25.0 | 44.7 | 25.3 | 28.8 |
| DINO | 69.2 | 28.5 | 51.0 | 26.6 | 30.8 |
| Same epochs (无B-GRPO) | 68.6 | 29.5 | 48.7 | 27.3 | 29.7 |
| Full labeled | 69.2 | 57.2 | 50.3 | 28.3 | 31.5 |
| B-GRPO | 69.2 | 37.0 | 52.0 | 30.7 | 32.1 |
| 结论:B-GRPO在所有数据集上均优于无RL基线和DINO。在CASIA上提升尤为显著(+12%)。相比仅增加训练轮数(Same epochs),B-GRPO仍有优势。部分结果已接近或超过全标注数据训练(Full labeled)。 |
表2. 不同奖励函数对比(F1%)
| 奖励类型 | 特征提取器 | r1 | r2 | r3 | r4 | r5 |
|---|---|---|---|---|---|---|
| 自奖励 | SenseVoice | 69.2, 37.0, 52.0, 30.7, 32.1 | 69.3, 36.3, 51.9, 31.0, 31.7 | - | - | - |
| 教师奖励 | Emotion2vec-plus-large | - | - | 69.1, 33.7, 51.5, 30.4, 32.0 | 69.3, 36.3, 52.6, 30.3, 31.8 | 69.8, 29.8, 50.7, 30.5, 31.4 |
| Emotion2vec-base | - | - | 70.0, 34.4, 50.1, 30.0, 31.0 | 69.6, 37.5, 51.6, 30.3, 31.8 | - | |
| Whisper-large-v3 | - | - | 24.5, 13.4, 8.8, 10.7, 9.2 | 69.2, 35.8, 51.1, 30.6, 31.9 | - | |
| 结论:整体上,自奖励(r1)性能最稳定且在多数据集上表现优异。教师奖励中,使用Whisper的r3效果极差,但与其他奖励组合的r4尚可。 |
表3. 优势函数变体对比(F1%)
| 变体 | IEMOCAP | CASIA | CAFE | MELD | M3ED |
|---|---|---|---|---|---|
| 仅正优势 (Â_i > 0) | 69.2 | 37.0 | 52.0 | 30.7 | 32.1 |
| 无正向筛选 (w/o Â_i > 0) | 69.2 | 35.4 | 51.8 | 30.8 | 32.1 |
| 无优势函数 (w/o Â_i) | 69.7 | 36.2 | 51.8 | 29.7 | 31.3 |
| 结论:移除正向筛选或整个优势函数计算均会导致性能下降,尤其是在CASIA和MELD上,验证了优势函数设计的有效性。 |
表4. 不同特征提取器下的策略模型性能(F1%)
| 特征提取器 | 基线 | + B-GRPO | 基线 | + B-GRPO | … (其他数据集) |
|---|---|---|---|---|---|
| Sensevoice | 69.4 | 70.1 | 53.5 | 59.2 | … |
| Emotion2vec | 70.4 | 69.9 | 68.3 | 70.2 | … |
| Whisper | 70.6 | 72.0 | 47.9 | 55.2 | … |
| 结论:B-GRPO对不同特征提取器均有提升,其中对Whisper的提升最大(在MELD上从31.7%到36.7%)。 |
表5. 数据来源对B-GRPO性能的影响(F1%)
| 数据使用方式 (训练B-GRPO的数据 → 基线训练的数据) | 基线 | 相同语料 | 外部语料 |
|---|---|---|---|
| SAVEE → MELD | 27.7 | 31.8 | 29.5 |
| JL → IEMOCAP | 69.4 | 70.1 | 69.6 |
| M3ED → CASIA | 53.5 | 59.2 | 47.0 |
| CASIA → M3ED | 31.1 | 33.9 | 32.3 |
| CASIA → CAFE | 47.6 | 53.3 | 51.5 |
| CAFE → CASIA | 53.5 | 59.2 | 58.2 |
| Librispeech → MELD | 27.7 | 31.8 | 29.9 |
| 结论:B-GRPO能从相同或外部语料中筛选有效样本,但使用相同语料效果更优。这表明B-GRPO具备一定的数据选择能力。 |
⚖️ 评分理由
- 学术质量(5.5/7):创新性方面,将GRPO从生成任务改造为分类任务的样本选择问题是一个有价值的思路迁移,但技术壁垒不高。奖励函数设计(尤其是自奖励)逻辑合理但略显直观。实验部分比较扎实,对比了多种基线、进行了充分的消融实验(奖励函数、优势函数、模型架构、数据来源),并在五个不同语言的数据集上验证,结果具有说服力。主要不足是部分关键超参数和实验细节缺失,且预训练需要标注数据的设定降低了其“无监督”的纯度。
- 选题价值(1.5/2):无监督语音情感识别是解决领域数据瓶颈的关键,选题具有明确的研究意义和应用价值。将强化学习引入该任务是一个新颖的尝试,对相关领域的研究者有启发作用。
- 开源与复现加成(-0.5/1):论文未提供任何开源代码、预训练模型或详细复现指南。虽然给出了一些超参数,但奖励函数阈值、裁剪参数ε、优化器、具体数据预处理步骤等关键信息均未说明,使得独立复现较为困难。