📄 Auxiliary Multi-Label Training For Improving the Robustness of Audio Deepfake Detection on AI-Processed Data
#音频深度伪造检测 #数据增强 #多任务学习 #自监督学习 #鲁棒性
✅ 6.5/10 | 前50% | #音频深度伪造检测 | #数据增强 | #多任务学习 #自监督学习
学术质量 4.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Inho Kim(松石大学)
- 通讯作者:Souhwan Jung*(松石大学)
- 作者列表:Inho Kim(松石大学),Jiwon Seo(松石大学),Seoyoung Park(松石大学),Thien-Phuc Doan(松石大学),Souhwan Jung*(松石大学)
💡 毒舌点评
亮点在于问题定义非常清晰——将“AI处理”从传统伪造中剥离,并提出一个简单易懂的训练框架(AMLT)来提升模型对此类数据的鲁棒性,思路直接有效。短板则是实验对比略显单薄,仅用了两个AP模块进行训练和评估,且未深入探讨不同AP组合或更复杂场景下的泛化能力,对方法为何有效的理论解释也主要停留在t-SNE可视化,机制剖析不够深。
🔗 开源详情
- 代码:论文中未提及自己方法(AMLT)的代码仓库链接。
- 模型权重:未提及公开的模型权重。
- 数据集:评估所用数据集(VCTK, LibriSpeech, VoxCeleb, ASVspoof 2021, DSD-Corpus, In-The-Wild)为公开数据集,论文提供了引用。训练基线使用ASVspoof 2019公开数据。
- Demo:未提供在线演示。
- 复现材料:给出了基线模型、AP模块的来源链接(开源工具),以及部分训练设置描述(如保持基线配置、调整输出层),但关键超参数(损失权重、学习率等)未说明。
- 论文中引用的开源项目:
- 神经编解码器:BigCodec, EnCodec, SpeechTokenizer, FunCodec
- 语音增强:ClearerVoice, VoiceFixer, Resemble-Enhance, Denoiser
- 基线模型/特征:wav2vec 2.0 (Hugging Face)
📌 核心摘要
- 要解决什么问题:音频深度伪造检测模型(如SSL-Conformer, SSL-AASIST)在面对经过神经编解码器(NC)或AI语音增强(SE)等AI处理(AP)的音频时,性能会严重下降,因为这些处理会引入网络伪影,导致模型误判。
- 方法核心是什么:提出辅助多标签训练(AMLT)。在训练阶段,为AP处理后的音频分配额外的辅助标签(如AP bona, AP sp),将原本的二分类(真实/伪造)扩展为多分类进行训练,使模型能显式学习区分AP数据。在评估阶段,则忽略辅助标签,回归原始的二分类进行性能评估。
- 与已有方法相比新在哪里:打破了音频深度伪造检测领域长期遵循的“二分类训练”范式。与简单的数据增强(Aug)方法相比,AMLT通过引入辅助标签,在训练时为AP数据提供了更细粒度的监督信号,理论上能学到更具区分性的特征表示。
- 主要实验结果如何:在SSL-Conformer和SSL-AASIST两个基线上,AMLT(4L-2L设置)相比基线和简单数据增强方法,在包含AP数据的评估集上均取得了最高的准确率。具体而言,4L-2L使SSL-AASIST准确率从65.89%提升至72.28%,SSL-Conformer从71.21%提升至76.63%,优于简单数据增强的69.58%和72.94%。混淆矩阵和t-SNE可视化显示,AMLT能更好地区分真实样本和经过AP处理的真实样本。
- 实际意义是什么:提供了一种提升音频深度伪造检测模型在真实世界(音频可能经过各种AI预处理)场景下鲁棒性的有效策略,有助于增强现有检测系统的实用性和安全性。
- 主要局限性是什么:方法有效性对训练时所选AP模块的代表性有依赖;论文未深入分析AMLT提升性能的深层原因(如为何多标签训练优于二分类训练);实验仅验证了特定基线和有限AP组合下的效果,未在更广泛场景(如未知AP、混合AP)下验证泛化性。
🏗️ 模型架构
论文中未提供专用的模型架构图(AMLT本身是一种训练策略,而非新模型结构)。AMLT应用于两个现有的基线模型:
- SSL-Conformer:前端为wav2vec 2.0自监督学习(SSL)预训练特征提取器,后端为Conformer分类器(结合了Transformer和CNN)。
- SSL-AASIST:前端同样为wav2vec 2.0,后端为AASIST,一种基于图神经网络(GNN)的检测器。
AMLT的训练流程(以4L-2L为例):
- 输入:音频样本(可能为原始或AP处理后)。
- 模型前向传播:通过SSL前端提取特征,再通过后端分类器输出预测分布。
- 损失计算:关键修改点。对于原始样本,使用“Bonafide”或“Spoof”标签计算交叉熵损失;对于AP样本,使用“AP bona”或“AP sp”辅助标签计算损失。所有损失加权求和。
- 训练目标:最小化多分类交叉熵损失。
- 评估阶段:将模型输出的多类别预测映射回原始的二分类(“Bonafide”包含“Bonafide”和“AP bona”;“Spoof”包含“Spoof”和“AP sp”),计算准确率。
💡 核心创新点
- 问题重新定义与标签体系:明确区分了“AI处理(AP)”音频与“伪造(Spoof)”音频。AP不改变语音内容,但改变声学特征。据此引入了辅助标签(AP bona, AP sp),为后续方法奠定了基础。
- 辅助多标签训练(AMLT)框架:提出了一种在训练阶段使用多标签分类来增强模型对AP数据判别力的通用训练范式。其核心思想是,在训练时为模型提供更细粒度的监督信号(区分原始数据与不同类型的AP数据),而在评估时回归任务本身要求的二分类。
- 训练与评估标签解耦:AMLT允许训练时使用更复杂的标签空间来学习更丰富的特征表示,但在评估时保持与标准任务一致的标签空间,从而直接兼容现有评估标准并提升性能。
🔬 细节详述
- 训练数据:
- 基线训练集:ASVspoof 2019训练数据。
- AP处理:使用4种神经编解码器(BigCodec, EnCodec, SpeechTokenizer, FunCodec)和4种语音增强工具(ClearerVoice, VoiceFixer, Resemble-Enhance, Denoiser)。
- 评估数据:从VCTK, LibriSpeech, VoxCeleb提取真实样本;从ASVspoof 2021 DF eval, DSD-Corpus, In-The-Wild提取伪造样本。每个数据集提取5,000样本,并对所有样本应用8种AP,总评估集约270,000样本。
- AMLT训练数据:在基线训练集(ASVspoof 2019)上应用选定的AP模块(SpeechTokenizer和VoiceFixer用于4L训练;SpeechTokenizer用于3L训练)生成AP样本,并与原始训练样本混合进行多标签训练。数据增强(Aug)基线则仅添加AP样本进行传统二分类训练。
- 损失函数:论文未说明具体损失函数公式,但明确使用了交叉熵损失。在AMLT中,为不同类别的样本(Bonafide, AP bona, Spoof, AP sp)分配了损失权重,但未提供具体权重数值。
- 训练策略:
- 模型配置:保持基线模型的优化器、学习率等设置不变,仅调整输出层维度以适应多分类。
- 具体超参数(如学习率值、batch size、训练轮数):未说明。
- AMLT训练:4L训练使用四个类别,3L训练使用三个类别(将AP sp并入Spoof)。
- 关键超参数:未说明。
- 训练硬件:未说明。
- 推理细节:未说明。
- 正则化技巧:未说明。
📊 实验结果
主要评估指标为准确率(ACC)。关键结果如下:
表1:不同AP类别下的平均准确率(%)
| AP类型 | 模型 | 真实样本(原始) | 真实样本(AP后) | 伪造样本(原始) | 伪造样本(AP后) |
|---|---|---|---|---|---|
| 神经编解码器 | SSL-Conformer | 77.11 | 5.75~65.73 | 93.76 | 89.67~99.61 |
| SSL-AASIST | 65.84 | 0.37~53.23 | 95.33 | 93.15~99.81 | |
| 语音增强 | SSL-Conformer | 77.11 | 23.79~73.57 | 93.76 | 93.89~98.15 |
| SSL-AASIST | 65.84 | 5.91~60.73 | 95.33 | 95.18~99.54 |
表2:不同数据集上的平均准确率(%)
| 数据集 | SSL-Conformer (原始/AP) | SSL-AASIST (原始/AP) |
|---|---|---|
| VCTK (真实) | 99.86 / 76.43 | 97.98 / 58.12 |
| LibriSpeech (真实) | 90.44 / 44.96 | 78.10 / 30.62 |
| VoxCeleb (真实) | 41.02 / 12.39 | 21.44 / 3.94 |
| DF21 (伪造) | 99.90 / 99.22 | 99.98 / 99.61 |
| DSD (伪造) | 81.78 / 88.20 | 86.14 / 92.26 |
| ITW (伪造) | 99.60 / 99.51 | 99.86 / 99.69 |
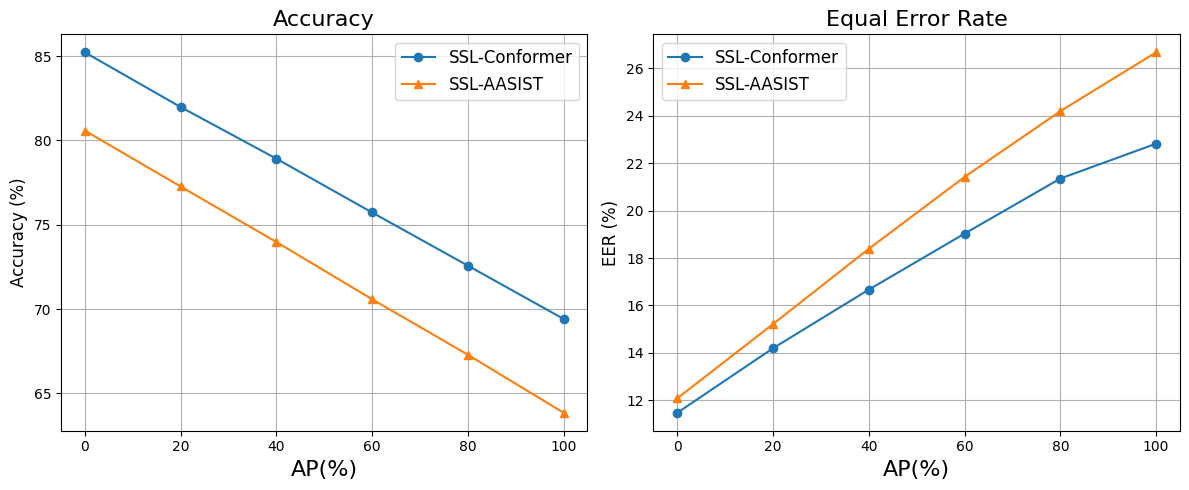 图1说明:随着训练/评估数据中AP样本比例的增加,模型的准确率和等错误率(EER)持续恶化,直接证明了AP数据对检测性能的负面影响。
图1说明:随着训练/评估数据中AP样本比例的增加,模型的准确率和等错误率(EER)持续恶化,直接证明了AP数据对检测性能的负面影响。
表3:不同训练方法的准确率(%)对比
| 训练方法 | SSL-AASIST | SSL-Conformer |
|---|---|---|
| 基线 | 65.89 | 71.21 |
| 数据增强(Aug) | 69.58 | 72.94 |
| AMLT (3L-2L) | 70.13 | 73.03 |
| AMLT (4L-2L) | 72.28 | 76.63 |
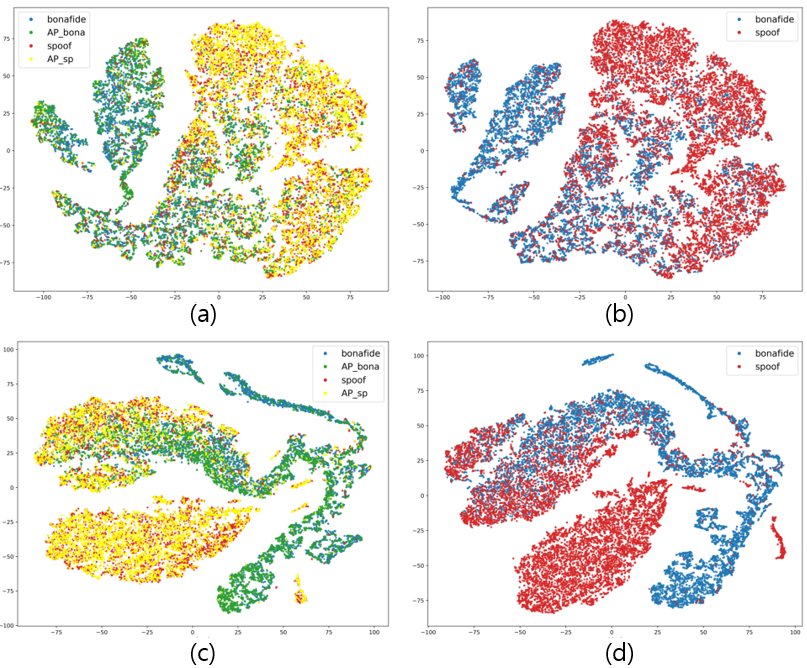 图2说明:对比了SSL-AASIST和SSL-Conformer在数据增强(Aug)和4L-2L训练下的混淆矩阵。4L-2L方法在真实(Bonafide)和伪造(Spoof)两类上的分类性能均优于简单数据增强,特别是在减少将AP处理的真实样本误判为伪造(假阴性)方面效果显著。
图2说明:对比了SSL-AASIST和SSL-Conformer在数据增强(Aug)和4L-2L训练下的混淆矩阵。4L-2L方法在真实(Bonafide)和伪造(Spoof)两类上的分类性能均优于简单数据增强,特别是在减少将AP处理的真实样本误判为伪造(假阴性)方面效果显著。
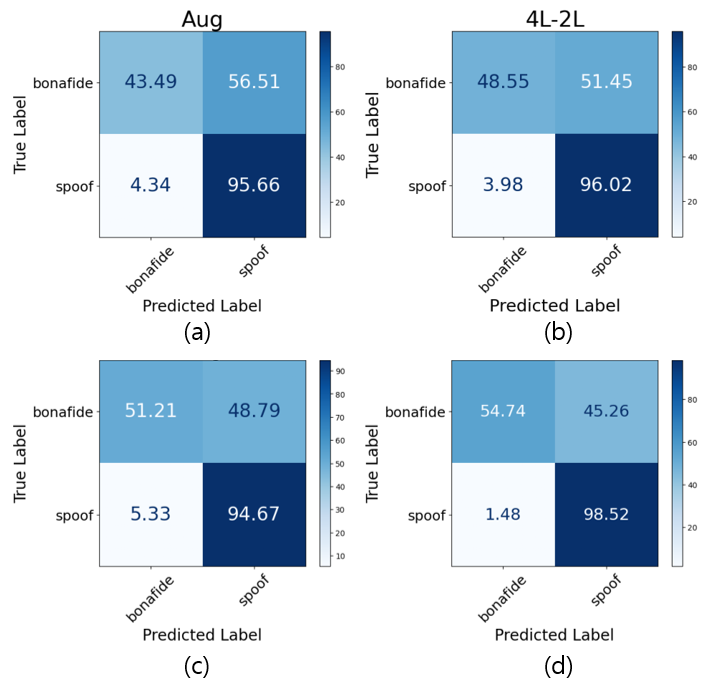 图3说明:t-SNE可视化显示,4L-2L方法(c, d)比数据增强方法(a, b)能在嵌入空间中更清晰地分离原始标签(Bonafide vs Spoof),特别是能更好地区分原始真实样本与AP处理后的真实样本(Bonafide vs AP bona),直观验证了AMLT能学习到更具判别性的特征。
图3说明:t-SNE可视化显示,4L-2L方法(c, d)比数据增强方法(a, b)能在嵌入空间中更清晰地分离原始标签(Bonafide vs Spoof),特别是能更好地区分原始真实样本与AP处理后的真实样本(Bonafide vs AP bona),直观验证了AMLT能学习到更具判别性的特征。
主要结论:AMLT,尤其是使用所有辅助标签的4L-2L设置,在两个先进的基线模型上均实现了比基线和简单数据增强方法更好的检测性能,平均准确率提升超过7%(如SSL-Conformer从71.21%提升至76.63%)。消融实验显示,使用所有辅助标签(4L)优于只使用部分辅助标签(3L)。
⚖️ 评分理由
- 学术质量:4.5/7:创新点在于提出了清晰的训练框架(AMLT),技术路线正确,实验验证了其有效性。但创新属于训练策略层面,技术深度有限。实验设计合理,但对比基线(如是否与更强的数据增强或领域自适应方法对比)可以更充分,对方法有效性的理论解释不够深入。
- 选题价值:1.5/2:直击音频深度伪造检测在实际部署中面临的一个重要痛点(AI预处理带来的干扰),问题实际且重要,对相关领域研究者和工程师有明确参考价值。
- 开源与复现加成:0.5/1:论文引用了大量所用工具的开源代码,便于他人复现实验环境。但作者未公开自己方法的代码、模型权重或完整的训练脚本(如损失权重配置),复现其方法需要一定额外工作。