📄 AUV: Teaching Audio Universal Vector Quantization with Single Nested Codebook
#音频生成 #统一音频模型 #知识蒸馏 #自监督学习
🔥 8.0/10 | 前25% | #音频生成 | #知识蒸馏 | #统一音频模型 #自监督学习
学术质量 5.5/7 | 选题价值 1.8/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yushen Chen (上海交通大学X-LANCE实验室, MoE人工智能重点实验室, 江苏省语言计算重点实验室, SCS;上海创新研究院)
- 通讯作者:Xie Chen (上海交通大学X-LANCE实验室, MoE人工智能重点实验室, 江苏省语言计算重点实验室, SCS;上海创新研究院)
- 作者列表:Yushen Chen(上海交通大学X-LANCE实验室, MoE人工智能重点实验室, 江苏省语言计算重点实验室, SCS;上海创新研究院)、Kai Hu(腾讯混元)、Long Zhou(腾讯混元)、Shulin Feng(腾讯混元)、Xusheng Yang(北京大学,深圳)、Hangting Chen(腾讯混元)、Xie Chen(上海交通大学X-LANCE实验室, MoE人工智能重点实验室, 江苏省语言计算重点实验室, SCS;上海创新研究院)
💡 毒舌点评
亮点是嵌套码本(Matryoshka Codebook)设计巧妙,将领域先验以一种灵活、可学习的方式注入单一码本,避免了复杂多阶段训练和域切换难题。短板在于“统一”模型在语音重建的关键指标(如PESQ)上仍稍逊于领域专用模型(如BigCodec),且论文未公开完整的训练数据与硬件配置,对工业级复现构成挑战。
🔗 开源详情
- 代码:论文中提供了项目主页链接(https://swivid.github.io/AUV/),并称“The pre-trained model and demo samples are available”,但未明确提供完整代码仓库的GitHub链接。
- 模型权重:论文提及预训练模型可用,但未说明具体下载地址或平台。
- 数据集:论文使用了Emilia, LibriTTS, AudioSet等公开数据集及内部数据集。公开数据集部分未说明具体获取或预处理方式。内部数据集未公开。
- Demo:论文提供在线演示样本(通过项目主页)。
- 复现材料:论文提供了非常详细的训练配置(优化器、学习率、调度、模型尺寸等),并在消融实验部分给出了不同设置下的结果,有助于复现。未提及提供预训练检查点、配置文件或复现脚本。
- 论文中引用的开源项目:VQ-GAN、HiFi-GAN(用于判别器)、EnCodec、DAC、Vocos、Conformer、BigCodec、Stable-Codec(用于MS-STFT判别器设置)、WavLM、MuQ、BEATs(作为教师模型)、EmoVoice(用于TTS评估)、F5-TTS(用于评估数据)。
- 总结:论文承诺提供模型和演示,但未提供完整的代码和数据获取链路,因此开源信息部分充分,部分未说明。
📌 核心摘要
- 问题:现有的神经音频编解码器要么是领域专用的(语音、音乐等分开训练),要么在使用单一码本实现统一音频表示时,面临重建质量不佳、训练流程复杂、处理混合域音频能力弱等问题。
- 方法核心:提出AUV,一个采用单一嵌套码本的统一神经音频编解码器。其核心是设计一个“俄罗斯套娃”式(Matryoshka)的嵌套码本,为语音、人声、音乐、声音等不同领域分配重叠的索引区间作为弱先验。同时,利用多个领域的预训练教师模型(如WavLM、MuQ、BEATs)对学生编解码器进行知识蒸馏,以注入丰富的语义信息,所有训练在单阶段完成。
- 新意:AUV是首个将嵌套码本设计和多领域教师蒸馏相结合,用于实现统一单码本音频表示的方法。与之前工作(如UniCodec的刚性分割码本和多阶段训练)相比,它更灵活、更高效,且能自然处理混合域音频。
- 主要实验结果:在语音重建(LibriSpeech test-clean)上,AUV(WER 3.64, SPK-SIM 0.81)与BigCodec(WER 3.63, SPK-SIM 0.84)等专用模型表现相当,并显著优于UniCodec(WER 3.78)。在音乐和声音重建上,AUV的Audiobox Aesthetics各项得分全面超越UniCodec(例如,音乐CE: 5.90 vs 5.06)。消融实验证实了嵌套码本和多领域蒸馏对重建和生成质量的提升。
- 实际意义:AUV为语音、音乐、声音等多领域提供了一个统一的离散表示基础,有望简化下游音频大模型(如TTS、音频生成)的训练,并能高效处理现实世界中的混合音频内容。
- 局限性:在极低比特率下的重建保真度仍有提升空间;统一模型在个别语音指标上与最强专用模型仍有微小差距;训练数据的具体细节和获取方式未完全公开。
🏗️ 模型架构
AUV的整体架构为编码器-量化器-解码器(Encoder-Quantizer-Decoder)。
- 输入输出流程:输入为16kHz的音频波形。首先通过一个STFT头转换为时频谱图(STFT特征)。编码器(Encoder)将STFT特征映射为潜在表示。接着,单一码本的向量量化器(VQ)将连续潜在表示离散化为离散token(50Hz)。解码器(Decoder)接收这些离散token,并通过一个iSTFT头将其转换回时域波形。
- 主要组件:
- 编码器与解码器:均采用Conformer块作为主干网络,这是一种卷积增强的Transformer,能有效建模局部与全局依赖。与之前发现一致,论文发现放大解码器比放大编码器对重建质量提升更显著,因此解码器使用了更多层(12层 vs 编码器8层)。
- 音频表示:使用STFT频谱作为建模目标,而非直接建模波形。这借鉴了Vocos的成功经验。
- 嵌套码本(Nested Codebook):这是关键设计。总码本大小为16384(或扩展至20480)。不同领域的索引区间相互嵌套:例如,0-4095为语音专用,0-8191为人声(歌声,包含语音)专用,0-16383为音乐专用,8192-16383为非人声声音专用。这种设计为模型提供了领域先验,但允许在共享区间内灵活学习。
- 蒸馏头:在解码器的第6层输出上附加一个“蒸馏学习器头”(distillation learner head),用于接收来自教师模型的连续表示监督信号。
- 数据流与交互:在训练时,输入音频的领域标签被提供给系统,用于引导码本的初始化和蒸馏信号的选择。在推理时,模型是领域无关的,仅依赖编码器和量化器从整个码本中选择token。
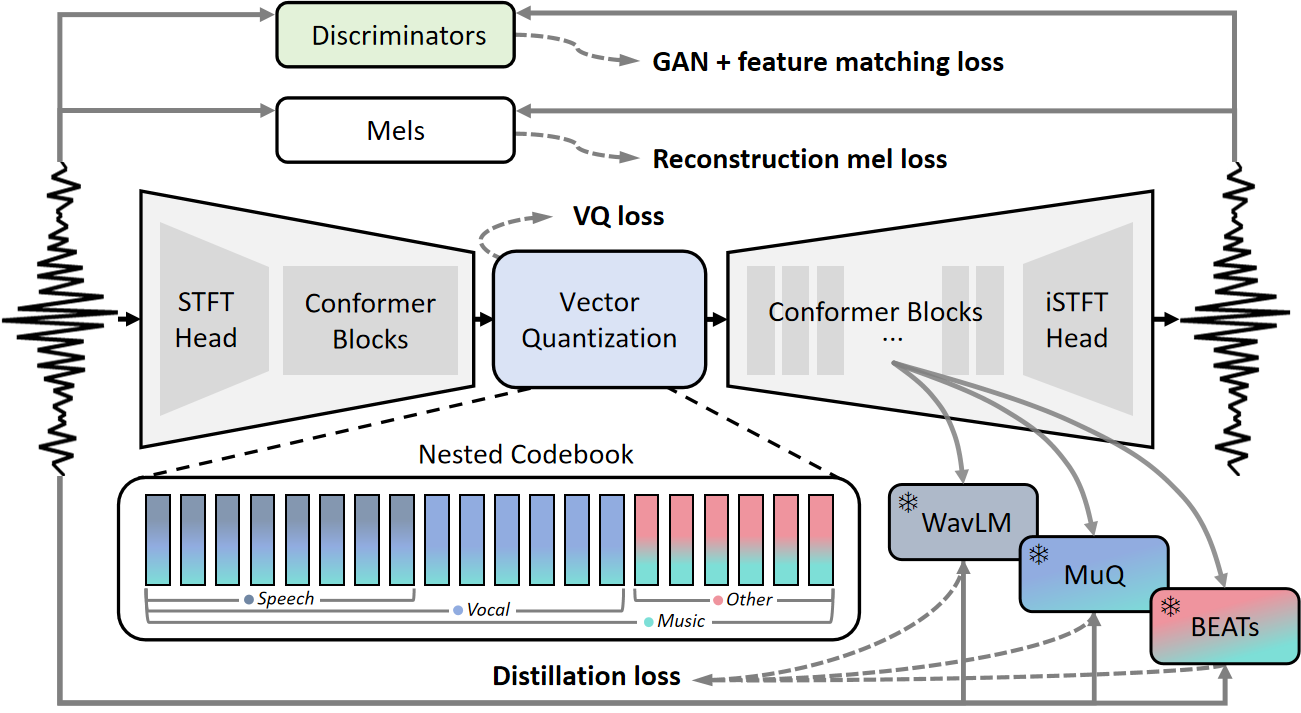 图1展示了AUV的整体框架。训练时,音频领域信息被输入模型,用于指导码本划分和选择对应的教师模型进行蒸馏。推理时,模型无需领域信息,直接处理任意音频。
图1展示了AUV的整体框架。训练时,音频领域信息被输入模型,用于指导码本划分和选择对应的教师模型进行蒸馏。推理时,模型无需领域信息,直接处理任意音频。
💡 核心创新点
- 嵌套码本(Matryoshka Codebook)设计:为统一单码本音频编解码提供了灵活的领域先验。不同于UniCodec的刚性分割,嵌套设计允许不同领域的码本区间重叠(如语音区间是人声区间的子集),更符合音频内容(如人声包含语音)的自然关系,提升了码本利用率和对混合域音频的适应性。
- 多领域语义蒸馏(Multi-domain Semantic Distillation):突破以往仅使用语音教师模型(如WavLM)的局限,首次系统性地利用音乐(MuQ)和通用音频(BEATs)的自监督预训练模型作为教师,为不同领域的音频注入相应的语义信息,丰富了统一编解码器的语义表达能力。
- 高效的Conformer + STFT架构选择:通过实验验证,采用以Conformer为骨干、以STFT为建模目标的架构,在单阶段训练中比基于波形的Transformer架构更有效,避免了性能损失和多阶段训练的复杂性。同时,通过增强判别器(采用Stable-Codec的FFT尺寸设置)显著提升了感知质量,尤其是说话人相似性。
- 单阶段统一训练:整个AUV模型(声学编解码+语义蒸馏)在单阶段完成训练,简化了流程。相比UniCodec复杂的三阶段训练,这提升了训练效率和模型的一体化程度。
🔬 细节详述
- 训练数据:总规模约12万小时。语音:95K小时Emilia和LibriTTS。人声与音乐:约20K小时内部数据。音频:从AudioSet筛选的4K小时音乐集和800小时非人声声音集。消融实验使用3K小时混合数据集。论文中未提供具体数据集获取方式或详细预处理步骤。
- 损失函数:包括量化器损失、Mel损失、对抗损失(使用MPD和MS-STFT判别器)和特征匹配损失,具体实现参考BigCodec。蒸馏损失为L1距离与余弦相似度的组合(公式见论文3.3节)。
- 训练策略:
- 优化器:AdamW,峰值学习率1e-4。
- 调度:线性warmup 5K步,余弦衰减500K步,之后保持恒定。
- 批量大小:全局128。
- 训练步数:根据消融表,主要实验为1M步。
- 推理使用EMA权重。
- 关键超参数:
- 采样率:16kHz。
- STFT跳跃长度:320,对应50Hz token率。
- Conformer隐藏维度:512,FFN乘数:4。
- 编码器层数:8,解码器层数:12。
- 码本大小:16384(基础),20480(扩展)。
- 码本量化维度:8(因式分解后)。
- 训练硬件:论文中未提及GPU/TPU型号、数量或训练时长。
- 推理细节:使用EMA权重进行解码。未提及温度或beam size等参数,因为AUV是编解码器,下游生成任务(如TTS)会使用自回归模型处理其输出的token。
- 正则化技巧:未特别提及除对抗训练和EMA外的其他技巧。
📊 实验结果
语音重建评估(LibriSpeech test-clean)
| 模型 | 码本大小 | TPS (token/秒) | WER↓ | STOI↑ | PESQ-WB↑ | SPK-SIM↑ | UTMOS↑ |
|---|---|---|---|---|---|---|---|
| Ground Truth | - | - | 2.50 | 1.00 | 4.64 | 1.00 | 4.09 |
| DAC | 1024 | 50×12 | 2.61 | 0.97 | 4.01 | 0.95 | 4.00 |
| BigCodec | 8192 | 80 | 3.63 | 0.94 | 2.68 | 0.84 | 4.11 |
| X-codec2 | 65536 | 50 | 3.20 | 0.92 | 2.43 | 0.82 | 4.12 |
| MagiCodec | 131072 | 50 | 4.25 | 0.92 | 2.54 | 0.77 | 4.17 |
| UniCodec | 16384 | 75 | 3.78 | 0.93 | 2.65 | 0.81 | 4.05 |
| AUV (C2) | 20480 | 50 | 3.64 | 0.91 | 2.40 | 0.81 | 4.09 |
其他领域重建评估(Audiobox Aesthetics分数)
| 模型 | 人声测试集 CE↑ | CU↑ | PC↑ | PQ↑ | Audio Set eval CE↑ | CU↑ | PC↑ | PQ↑ |
|---|---|---|---|---|---|---|---|---|
| Ground Truth | 5.69 | 6.04 | 3.44 | 6.81 | 4.52 | 5.73 | 4.10 | 6.33 |
| UniCodec | 5.06 | 5.44 | 2.66 | 6.44 | 4.09 | 5.21 | 4.03 | 5.88 |
| AUV (C2) | 5.90 | 6.16 | 3.33 | 6.85 | 4.27 | 5.40 | 4.08 | 6.02 |
关键结论:AUV在语音重建上与BigCodec等专用模型竞争力相当(WER接近),且显著优于统一基线UniCodec。在音乐/声音重建上,AUV全面超越UniCodec,且得分接近或超过GT。其码本更小(20K vs 131K),token率更低(50 vs 80),更具实用性。
消融实验关键结果(LibriSpeech test-clean)
| ID | 码本类型 | 码本大小 | 蒸馏 | WER↓ | SPK-SIM↑ | 语音索引比例 |
|---|---|---|---|---|---|---|
| (B0) | 无分割 | 16384 | ✗ | 4.30 | 0.78 | 25.9% |
| (B1) | 刚性分割 | 16384 | ✗ | 4.21 | 0.79 | 32.2% |
| (B2) | 嵌套分割 | 16384 | ✗ | 3.99 | 0.80 | 37.1% |
| (C2) | 嵌套分割 | 20480 | ✓ | 3.64 | 0.81 | 59.1% |
关键结论:
- 嵌套码本(B2)在WER和说话人相似度上优于无分割(B0)和刚性分割(B1)。
- 多领域蒸馏(C2)进一步降低了WER,提升了说话人相似度。
- 索引分布分析显示,模型能自发地将更多token分配到对应领域的专用区间(如语音输入时,59.1%的token落入语音区间,远高于随机概率)。
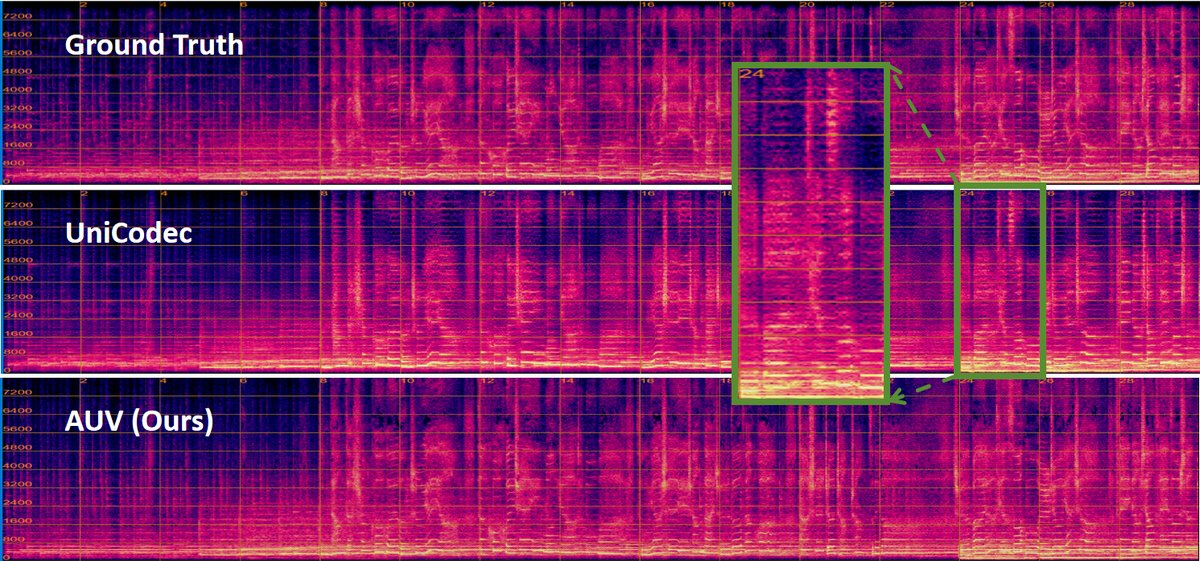 图2展示了一段音乐的频谱图对比。UniCodec的重建结果存在明显的混叠伪影,而AUV的重建结果更干净,更接近原始频谱。这直观证明了AUV在处理非语音音频时的优势。
图2展示了一段音乐的频谱图对比。UniCodec的重建结果存在明显的混叠伪影,而AUV的重建结果更干净,更接近原始频谱。这直观证明了AUV在处理非语音音频时的优势。
零样本TTS评估结果
| 使用编解码器 | 多领域蒸馏 | 码本类型 | 码本大小 | WER↓ | SPK-SIM↑ | UTMOS↑ |
|---|---|---|---|---|---|---|
| (B0) | ✗ | 无分割 | 16384 | 5.45 | 0.43 | 4.15 |
| (B1) | ✗ | 刚性分割 | 16384 | 6.26 | 0.43 | 4.20 |
| (B2) | ✗ | 嵌套分割 | 16384 | 4.99 | 0.44 | 4.27 |
| (C0) | ✓ | 嵌套分割 | 16384 | 4.51 | 0.44 | 4.26 |
| (C2) | ✓ | 嵌套分割 | 20480 | 4.89 | 0.43 | 4.29 |
关键结论:使用AUV的token训练的TTS模型(尤其是经多领域蒸馏和嵌套码本设计的)在WER上显著低于使用BigCodec、X-codec2或UniCodec token训练的模型,表明AUV产生的离散表示对下游生成任务更友好。
⚖️ 评分理由
- 学术质量(5.5/7):创新性体现在嵌套码本和多领域蒸馏的结合,有效解决了统一音频表示的多个痛点。技术正确性高,实验设计合理,包含充分的消融实验和多领域评估。主要扣分点在于部分关键基线(如MagiCodec)并非最新SOTA,且论文未公开训练数据和硬件等关键复现信息,证据的完全可信度稍受影响。
- 选题价值(1.8/2):统一音频表示是构建通用音频基础模型的关键环节,AUV提供了一种高效、灵活的解决方案,对语音合成、音频生成、多模态理解等下游任务有广泛的应用潜力,与前沿方向高度相关。
- 开源与复现加成(0.5/1):论文提供了详细的架构描述、训练超参数和预训练模型/演示样本的链接(https://swivid.github.io/AUV/),具有较好的可复现基础。但未提及完整代码仓库和训练数据的具体下载方式,因此加成有限。