📄 Auditory-Inspired Transformer for Binaural Speech Enhancement and Spatial Cue Preservation
#语音增强 #端到端 #空间音频 #多通道
✅ 7.0/10 | 前25% | #语音增强 | #端到端 | #空间音频 #多通道
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Sirawitch Laichatkul(朱拉隆功大学计算机工程系)
- 通讯作者:未说明
- 作者列表:Sirawitch Laichatkul(朱拉隆功大学计算机工程系)、Waradon Phokhinanan(巴黎高等师范学校感知系统实验室)、Thanapat Trachu(朱拉隆功大学计算机工程系)、Ekapol Chuangsuwanich(朱拉隆功大学计算机工程系)
💡 毒舌点评
这篇论文最大的亮点在于将听觉皮层的频率选择性(tonotopy)和自上而下注意力这一神经科学概念,成功地转化为了一个有效的计算模块(修改的ViT编码器和频率受限注意力掩码),为解决双耳增强中的空间线索失真问题提供了一个新颖且合理的切入点。但短板同样明显:模型对最具挑战性的相位线索(IPD)保持效果提升有限(∆IPD仅从1.12/1.13微降至1.09),实验仅基于合成数据,其在真实复杂声学环境下的表现和泛化能力有待验证,且缺乏开源代码,让这份“灵感”稍显难以触摸。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及是否公开预训练模型权重。
- 数据集:训练和评估所用的数据(CSTR, QUT-NOISE-TIMIT, MS-SNSD)均为公开数据集,但论文中未说明具体的下载方式或处理脚本。
- Demo:未提供在线演示。
- 复现材料:论文中提供了较为详细的训练设置(优化器、学习率、批次大小、训练轮数)、模型超参数(层数、维度、patch大小)以及数据预处理流程,这些构成了复现的基本要素。
- 论文中引用的开源项目:论文引用了HRTF测量数据[17],但未明确表示其代码或数据的可获取性。其他引用多为方法论文或数据集。
- 总结:论文中未提及开源计划。虽然复现所需的关键技术细节已在文中阐述,但缺乏直接可用的代码和权重,使得完全复现存在一定门槛。
📌 核心摘要
- 问题:双耳语音增强不仅要在频谱上抑制噪声,更关键的是要保持双耳线索(如耳间时间差ITD和耳间强度差ILD),否则会破坏空间听觉,影响助听器和增强现实等应用效果。现有方法在这一挑战上表现不足。
- 方法:提出了BinauralViT,一个受听觉神经科学启发的Transformer架构。其核心是引入两个听觉启发层:一个能实现“自上而下”注意力的频率选择性表示层(通过修改ViT编码器和添加频率注意力掩码实现),以及一个用于捕捉时序连贯性的语音处理层。
- 创新:与已有方法相比,新在:1)受皮层频率拓扑组织启发,设计了允许同一时间帧内频率间注意力但限制跨帧注意力的机制;2)提出了一种双层Transformer结构,第一层进行特征选择与融合,第二层建模时序依赖以保持空间线索。
- 结果:在合成的非平稳噪声数据集上,BinauralViT在PESQ(2.78 vs 2.54/2.30)、SI-SNR(17.43 vs 16.92/15.30)上优于BiTasNet和BCCTN基线,并在ILD保持(∆ILD 4.20 vs 6.03/5.85)上显著提升,IPD保持(∆IPD 1.09 vs 1.13/1.12)略有改善。MBSTOI(~0.98)在所有模型中已接近饱和。消融实验验证了修改ViT编码器、第二层编码器及IPD/ILD特征的必要性。
- 意义:为双耳语音处理提供了一种新的、受生物启发的模型设计思路,证明了模拟听觉机制对提升空间线索保持能力的有效性,对助听技术发展有积极参考价值。
- 局限:实验在模拟数据上进行,可能无法完全反映真实场景的复杂性;对IPD的提升幅度有限;模型计算复杂度和实时性未作讨论。
🏗️ 模型架构
BinauralViT的完整架构如图1所示,是一个端到端的双耳语音增强模型,其目标是从带噪的双耳语音信号中估计出相位敏感掩码(PSM),进而重构出干净语音。整体流程可分为四个主要阶段:
双耳特征提取:输入为左右耳的带噪语音信号y_l(t), y_r(t),首先通过短时傅里叶变换(STFT)转换为时频表示Y_l(k,n), Y_r(k,n)。然后提取四种特征:耳间相位差(IPD)、耳间强度差(ILD)、左耳幅度谱(SPl)和右耳幅度谱(SPr)。IPD和ILD编码了空间信息,SPl和SPr编码了频谱内容。
修改的视觉Transformer(mViT)编码:这是模型的核心创新组件。每种特征(IPD, ILD, SPl, SPr)分别输入一个独立的mViT编码器(图1a中绿色框)。如图2所示,该编码器对标准ViT进行了两项关键修改:去除了线性投影层,注意力层直接作用于输入特征以减少参数;添加了频率受限注意力掩码。具体来说,对于一个大小为(16,16)的patch P(i,j),它只能关注同一时间帧j内的所有频率位置q的patch P(q,j),而不能跨越不同时间帧。这模拟了听觉皮层中神经元按频率组织并受注意力调制的特性。每个mViT编码器输出对应的表征R_Pfeat(如图1b中的R_PILD, R_PIPD等)。
表示集成:此阶段模拟听觉皮层对多个频谱流的整合。如图1b所示,首先进行交叉注意力(CA):以ILD表征(R_PILD)为查询(Query),以IPD表征(R_PIPD)为键(Key)和值(Value),通过交叉注意力机制融合空间线索,输出为融合后的左右表征R_PL和R_PR。然后,将R_PL、R_PR与对应的谱表征R_PSPL、R_PSPR相加。最后,将左右通道的表征拼接,通过自注意力(SA)层建模双耳间的相互关系,得到最终的整合表征R_PSP。
相位敏感掩码(PSM)估计与重建:整合表征R_PSP分别送入左右通道的自注意力层和线性层,经sigmoid激活后得到估计的PSM。将估计的PSM与输入的幅度谱逐元素相乘,即可得到增强后的干净语音幅度谱。结合原始相位信息,通过逆STFT重建时域语音信号。
图1:BinauralViT模型架构总览
 此图展示了模型的端到端流程:从左右耳信号输入,经过特征提取、多个修改的ViT编码器处理,通过表示集成块融合,最后经线性解码器输出增强的语音。图1b详细展示了表示集成块的内部结构,包括交叉注意力和自注意力层。
此图展示了模型的端到端流程:从左右耳信号输入,经过特征提取、多个修改的ViT编码器处理,通过表示集成块融合,最后经线性解码器输出增强的语音。图1b详细展示了表示集成块的内部结构,包括交叉注意力和自注意力层。
图2:修改的视觉Transformer编码器
 此图详细说明了如何修改标准ViT:去除了线性投影,并添加了蓝色的注意力掩码。掩码确保了在自注意力计算中,每个patch(代表一个时间-频率位置)只能与同一时间帧(即同一列)内的其他patch进行交互。
此图详细说明了如何修改标准ViT:去除了线性投影,并添加了蓝色的注意力掩码。掩码确保了在自注意力计算中,每个patch(代表一个时间-频率位置)只能与同一时间帧(即同一列)内的其他patch进行交互。
💡 核心创新点
受听觉皮层启发的频率选择性注意力机制:
- 是什么:在Transformer编码器中引入频率受限注意力掩码,强制模型在每一帧内独立地进行频率间的注意力计算。
- 之前局限:先前沿频率轴的注意力模型(如AST)处理的是整个频谱序列,而非在单一时间帧内进行选择性注意,这不符合生物听觉系统并行处理不同频率的组织方式。
- 如何起作用:该机制迫使模型像听觉皮层一样,在每个时刻专注于分析不同频率成分的相互关系,实现了“自上而下”的注意力调制,更有效地从混合信号中分离目标语音的频谱特征。
- 收益:消融实验(表2)表明,使用标准ViT替代此修改后,PESQ从2.78降至2.25,ILD误差(∆ILD)从4.20升至5.94,证明了该机制对提升整体语音质量和空间线索保持的关键作用。
用于双耳增强的双层Transformer架构:
- 是什么:第一层(mViT编码器)负责从各特征中提取和选择性融合空间-频谱表征;第二层(集成后的注意力编码器)负责对这些表征进行时序建模,以保持跨帧的双耳线索连贯性。
- 之前局限:现有的频率选择性模型(如文献[13])主要用于声源定位,缺乏建模时序依赖的能力,因此难以有效保留语音增强所需的序列信息和空间线索。
- 如何起作用:第一层专注于“听什么”(频率选择性特征提取),第二层专注于“如何听”(时序上的连贯性建模),分工明确,更符合语音处理的层次化特点。
- 收益:消融实验中,去掉第二层编码器,PESQ从2.78降至2.70,ILD误差从4.20升至4.92,表明该层对于巩固跨帧空间信息、提升语音质量有贡献。
以相位敏感掩码(PSM)为目标的掩码估计:
- 是什么:模型最终预测的目标是PSM,而非传统的理想二值掩码(IBM)或理想比率掩码(IRM)。PSM考虑了带噪信号与干净信号之间的相位差。
- 之前局限:传统掩码方法在增强过程中容易扭曲双耳间的相位关系(IPD),因为其优化目标往往不直接约束相位保真度。
- 如何起作用:PSM本身包含了相位差信息,将其作为监督目标,使得模型在估计掩码时需要隐式地学习和保持正确的相位关系,从而有助于在重建时维持空间线索。
- 收益:虽然所有基线方法也使用了掩码,但结合上述的架构创新,BinauralViT在ILD保持上取得了显著更好的结果(∆ILD 4.20 vs 5.85/6.03),表明其整体框架(包括PSM目标和新架构)对空间线索更友好。
🔬 细节详述
训练数据:
- 语音数据:使用CSTR数据集[16],包含58名说话人的单声道语音。
- 噪声数据:训练和验证阶段使用QUT-NOISE-TIMIT数据库[18]中的四种噪声(咖啡馆、车窗、家庭厨房、城市街道)。测试阶段使用MS-SNSD数据集[19]中的四种噪声(机场广播、复印机、邻居、打字)。
- 数据生成:通过卷积头部相关脉冲响应(HRIR)[17]将单声道语音合成不同方位角(-90°到90°,间隔10°)的双耳干净语音。噪声通过叠加多个不同方位角的HRIR处理过的噪声成分生成,以模拟空间分布的、无一致双耳线索的噪声。混合信噪比(SNR)在训练/验证时为0, 5, 10, 15 dB;测试时为2.5, 7.5, 12.5, 17.5 dB。
- 预处理:所有信号采样率为16kHz。STFT参数:FFT长度512,窗长400,汉宁窗,帧移100。
损失函数:
- 名称:均方误差(MSE)损失。
- 作用:最小化估计的相位敏感掩码(PSM)与真实PSM之间的差异。
- 公式:真实PSM定义为 $PSM(k, n) = \frac{|X(k, n)|}{|Y(k, n)|} \cos(\Theta)$,其中$\Theta$是带噪信号与干净信号在每个时频点的相位差。模型优化目标是估计PSM与真实PSM的MSE。
训练策略:
- 优化器:AdamW。
- 学习率:初始学习率为0.0001。
- 批大小(Batch Size):32。
- 训练轮数(Epochs):100。
- 调度策略:论文中未说明学习率调度策略。
- Warmup:论文中未提及。
关键超参数:
- 模型深度:每个mViT编码器有N=8层Transformer层;第二阶段编码器同样有8层Transformer层。
- 表征维度:256。
- Patch大小:(16, 16),在时间和频率维度上都有50%的重叠。
- 解码:重叠的PSM预测通过加权平均(使用汉明窗)进行合并。
训练硬件:论文中未说明训练所用的GPU/TPU型号、数量及训练时长。
推理细节:未提及特殊解码策略。输入为合成的带噪双耳信号,输出为估计的PSM,经掩码作用后通过逆STFT重建语音。
正则化或稳定训练技巧:论文中未明确提及使用了Dropout、权重衰减等额外正则化技巧。优化器使用AdamW本身内置了权重衰减。
📊 实验结果
论文在合成的、未见过的噪声类型上进行了对比实验和消融研究。
主要性能对比(表1)
| 方法 | PESQ ↑ | MBSTOI ↑ | SI-SNR ↑ | ∆IPD ↓ | ∆ILD ↓ |
|---|---|---|---|---|---|
| BiTasNet [9] | 2.54 | 0.97 | 16.92 | 1.13 | 6.03 |
| BCCTN [10] | 2.30 | 0.98 | 15.30 | 1.12 | 5.85 |
| BinauralViT | 2.78 | 0.98 | 17.43 | 1.09 | 4.20 |
- 关键结论:BinauralViT在感知语音质量(PESQ)和信噪比(SI-SNR)上显著优于两个基线。在空间线索保持方面,ILD误差(∆ILD)降低幅度尤为明显(从5.85/6.03降至4.20),而IPD误差(∆IPD)的改善幅度较小(从1.12/1.13降至1.09)。可懂度指标(MBSTOI)在所有模型上都接近饱和(~0.98),论文认为这可能与中等至高信噪比条件下的天花板效应有关。
消融研究(表2)
| 方法 | PESQ ↑ | MBSTOI ↑ | ∆IPD ↓ | ∆ILD ↓ |
|---|---|---|---|---|
| BinauralViT | 2.78 | 0.98 | 1.09 | 4.20 |
| w/o second encoder layer | 2.70 | 0.98 | 1.09 | 4.92 |
| Using standard ViT encoder | 2.25 | 0.98 | 1.09 | 5.94 |
| w/o IPD features | 2.74 | 0.98 | 1.08 | 4.39 |
| w/o ILD features | 2.75 | 0.98 | 1.07 | 4.76 |
| w/o IPD & ILD features | 2.35 | 0.97 | 1.10 | 5.09 |
- 关键结论:
- 修改ViT编码器至关重要:使用标准ViT替代修改版,导致PESQ大幅下降(2.25),ILD误差显著上升(5.94)。这归因于标准ViT的线性投影和缺乏频率限制注意力,引入了跨时间帧的噪声干扰和失真。
- 第二层编码器有贡献:移除第二层编码器,PESQ轻微下降(2.70),ILD误差上升(4.92),表明其在巩固时序信息、维持空间连贯性方面发挥作用。
- 双耳线索互补:同时移除IPD和ILD特征导致性能全面下降(PESQ 2.35, ∆ILD 5.09)。单独移除任一特征会导致该特征相关的误差略微降低(如移除IPD特征后,∆IPD略降至1.08),但另一特征的误差会上升(如移除IPD后,∆ILD升至4.39),这印证了双耳定位理论中的双线索(duplex theory)互补性。
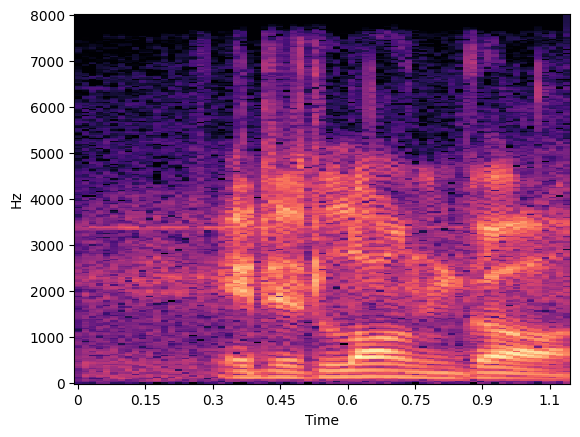
图3:频谱图比较
 此图定性展示了带噪信号、干净信号和经不同方法增强后的信号频谱。从视觉上看,BCCTN(中间右)残留了较多噪声,BiTasNet(中间左)虽然保留了谐波结构但引入了干扰,而BinauralViT(右)的增强结果最接近干净参考(上),背景更干净。这与表1中的客观指标趋势一致。
此图定性展示了带噪信号、干净信号和经不同方法增强后的信号频谱。从视觉上看,BCCTN(中间右)残留了较多噪声,BiTasNet(中间左)虽然保留了谐波结构但引入了干扰,而BinauralViT(右)的增强结果最接近干净参考(上),背景更干净。这与表1中的客观指标趋势一致。
⚖️ 评分理由
- 学术质量:5.5/7:论文的核心创新点——将听觉皮层的频率选择性转化为Transformer的注意力掩码机制——具有生物学动机和新颖性。技术实现逻辑清晰,架构设计合理。实验设置了合理的对比基线,并进行了有效的消融研究,数据支持其主要论点。主要扣分点在于:1)实验仅在合成数据集上进行,未报告在真实场景或更复杂条件下的泛化能力;2)对最具挑战性的IPD保持效果提升有限,削弱了其“有效保留空间线索”的强主张;3)未与更多最新的端到端双耳增强方法进行对比。
- 选题价值:1.5/2:研究双耳语音增强并聚焦于空间线索保持,直接针对助听器、AR/VR等应用的痛点,是音频处理领域一个明确且有价值的前沿方向。选题相关性高,潜在应用价值明确。
- 开源与复现加成:0.0/1:论文详细描述了模型架构、数据生成方式、超参数和评估协议,为复现提供了清晰的技术路线。然而,论文中未提供任何代码、预训练模型或数据集生成脚本的链接,这限制了其立即可复现性,因此不给予加分或扣分。