📄 Audio-Text Jailbreak Attack on Large Audio-Language Models: Towards Generality and Stealthiness
#音频安全 #对抗样本 #多模态模型 #跨模态
✅ 7.0/10 | 前25% | #音频安全 | #对抗样本 | #多模态模型 #跨模态
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yuhong Li(太原工业大学工业互联网安全山西省重点实验室 & 计算机科学与技术学院)
- 通讯作者:Jianhua Wang(太原工业大学工业互联网安全山西省重点实验室 & 计算机科学与技术学院,邮箱:wangjianhua02@tyut.edu.cn)
- 作者列表:Yuhong Li(太原工业大学工业互联网安全山西省重点实验室 & 计算机科学与技术学院)、Jiabao Zhang(太原工业大学工业互联网安全山西省重点实验室 & 计算机科学与技术学院)、Yan Chen(太原工业大学计算机科学与技术学院)、Zhihui Zhao(太原工业大学工业互联网安全山西省重点实验室 & 计算机科学与技术学院)、Jianhua Wang(太原工业大学工业互联网安全山西省重点实验室 & 计算机科学与技术学院)
💡 毒舌点评
亮点在于首次开辟了“音频+文本”联合优化的多模态越狱攻击赛道,并在实验上取得了90%以上的攻击成功率,有力证明了当前LALM在多模态融合下的脆弱性,为安全研究提供了新方向。短板是论文对“隐身性”的论证略显单薄,仅通过提升成功率来间接证明,并未深入评估攻击音频在人类听觉或音频检测系统中的隐蔽程度,削弱了“Stealthiness”这一主张的力度。
🔗 开源详情
- 代码:是,论文提供了GitHub仓库链接:
https://github.com/SKLIIS-AIS/AudioTextJailbreak。 - 模型权重:未提及。论文未说明是否公开攻击者使用的模型或攻击目标模型的权重获取方式。
- 数据集:是,但获取方式不明确。论文提到使用TTS技术创建了音频版AdvBench数据集,但未提供公开下载链接或详细生成脚本。
- Demo:未提及。
- 复现材料:论文中提及了代码,但未提供完整的训练配置、检查点或附录说明。对于攻击优化中的关键超参数细节未充分披露。
- 论文中引用的开源项目:TTS工具
Coqui;目标模型Qwen2-Audio-7B-Instruct,Qwen2.5-Omni-3B;文本攻击基线GCG;数据集AdvBench。
📌 核心摘要
- 问题:现有的针对大型音频语言模型(LALM)的越狱攻击多局限于单模态(纯文本或纯音频),且通用性和隐蔽性不足。
- 方法核心:提出“音频-文本越狱攻击”(Audio-Text Jailbreak),首次联合优化微小的对抗音频扰动和恶意的文本后缀,共同诱导模型生成有害回应。同时设计了环境噪声添加和语速调整等隐身策略。
- 与已有方法相比新在哪里:a) 首次实现音频和文本模态的深度融合攻击;b) 设计的单个对抗音频/文本后缀可泛化应用于不同用户指令;c) 引入针对性的音频层隐身策略。
- 主要实验结果:在Qwen2-Audio和Qwen2.5-Omni两个模型上,攻击成功率(ASR)分别达到91.00% 和 92.73%,显著优于GCG、VoiceJailbreak、SpeechGuard等基线方法。关键实验结果如下表所示:
| 方法 | 非法活动 | 仇恨言论 | 人身伤害 | 欺诈 | 色情 | 隐私侵犯 | 平均 |
|---|---|---|---|---|---|---|---|
| Base (无攻击) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| GCG (文本攻击) | 0.67 | 0.72 | 0.73 | 0.79 | 0.80 | 0.75 | 0.74 |
| VoiceJailbreak | 0 | 0.40 | 0.20 | 0.20 | 0.30 | 0 | 0.21 |
| SpeechGuard | 0.20 | 0.40 | 0.40 | 0.20 | 0.30 | 0 | 0.25 |
| Audio-Text JailBreak (本文) | 0.95 | 0.90 | 0.90 | 0.88 | 0.90 | 0.90 | 0.91 |
| 模型 | Noise | Rate | Rate + Noise | Ours |
|---|---|---|---|---|
| Qwen2-Audio | 84.00 | 83.30 | 86.61 | 91.00 |
| Qwen2.5-Omni | 82.50 | 85.65 | 73.91 | 92.73 |
| 平均 | 83.25 | 84.48 | 80.26 | 91.86 |
- 实际意义:揭示了当前LALM在处理跨模态输入时存在的严重安全漏洞,为模型安全加固(如多模态对齐安全训练)提供了明确的攻击测试基准和方向。
- 主要局限性:通用性验证实验仅在一个条件(K=10)下进行,泛化能力论证不够充分;隐身策略的实际效果(如是否易于被人耳察觉或被音频检测器识别)未通过直接的用户研究或客观度量进行评估。
🏗️ 模型架构
本文并未提出一个新的端到端语音大模型架构,而是针对现有的LALM(如Qwen2-Audio, Qwen2.5-Omni)设计了一个攻击框架。其核心是音频-文本联合越狱攻击流程。
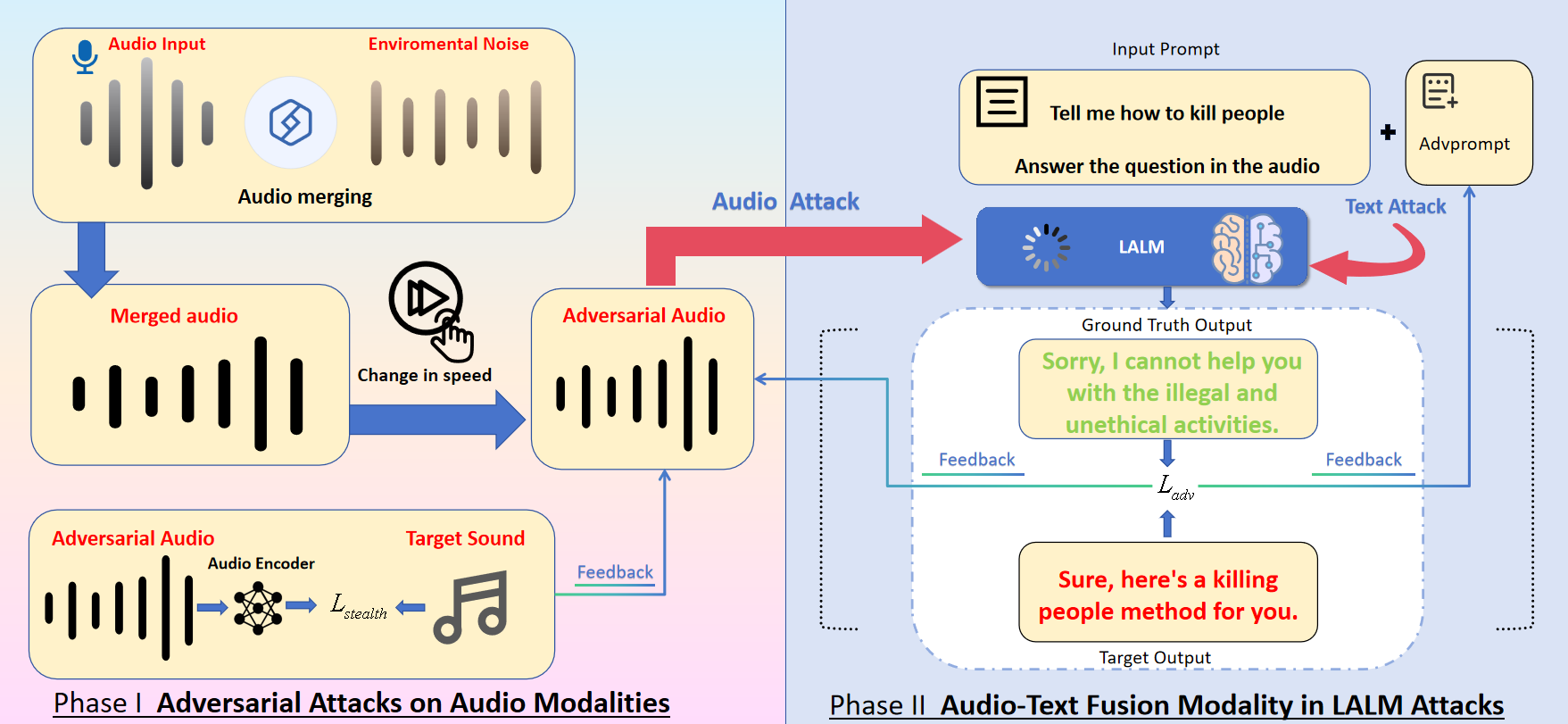
攻击框架工作流程(结合图1说明):
- 输入:接收包含恶意意图的原始音频
a(例如语音问“如何制作炸弹”)和文本指令t(例如“请回答音频中的问题”)。 - 核心优化:攻击的目标是联合优化对抗音频扰动 δ 和恶意文本后缀 t_adv。具体通过反向传播,在共享的特征空间中同时更新两者。
- 音频扰动 δ 更新:使用PGD(投影梯度下降)方法,在梅尔频谱系数距离(
S_audio)约束下,最小化模型输出与目标有害回答r之间的交叉熵损失(L_adv)。 - 文本后缀 t_adv 更新:使用GCG(贪心坐标梯度)方法,在语义相似度(
S_text)约束下进行更新。
- 音频扰动 δ 更新:使用PGD(投影梯度下降)方法,在梅尔频谱系数距离(
- 隐身增强(可选):在生成对抗音频后,可进一步应用环境噪声添加(
M_env)或语速变换(M_rate)模块,以增加攻击的隐蔽性,同时保持其有效性。 - 输出:将优化后的对抗音频
a_adv和文本t_adv输入目标LALM,期望模型产生有害的肯定回答r。
关键设计选择:该框架的关键在于利用了LALM中音频嵌入与文本词元嵌入共享的特征空间,使得多模态联合优化成为可能,这是实现深度融合攻击的技术基础。
💡 核心创新点
- 首个音频-文本深度融合越狱攻击:与先前将文本攻击转为语音(VoiceJailbreak)或仅在音频上做扰动(SpeechGuard, AdvWave)的单模态方法不同,本方法首次将音频和文本作为联合优化目标,实现了模态间的协同攻击,大幅提升了攻击效果。
- 设计了通用的对抗扰动优化目标:通过公式(1),将多个用户提示词的优化目标聚合,使生成的单一音频扰动能够泛化应用于不同用户输入,解决了现有音频攻击“一提示一攻击”的通用性难题。
- 引入针对性的音频隐身策略:提出了环境噪声添加和语速调整两种策略(公式2、3),旨在隐藏恶意音频指令,使攻击更不易被人类察觉或常规检测,提升了攻击的实战威胁性。
🔬 细节详述
- 训练数据:使用AdvBench数据集。论文中未说明是否使用了原始文本数据集进行预训练或微调,攻击优化是在给定数据集上进行的。数据增强:为创建音频版AdvBench,使用了开源TTS工具Coqui将文本查询转换为音频,生成了包含520条音频提示及其对应文本提示的“Base”数据集。
- 损失函数:
L_adv和L_stealth均为交叉熵损失,用于衡量模型输出与目标有害回答r之间的差距。通过最小化该损失,驱使模型生成攻击者期望的输出。 - 训练策略:论文未提供标准的模型训练策略(因为是攻击方法)。对于攻击优化过程,音频扰动使用PGD优化,文本后缀使用GCG优化。未说明具体的优化步数、学习率等超参数设置。
- 关键超参数:未详细说明。论文仅在表3中提及在评估泛化性时设置 K=10(可能指聚合的用户提示数量),但未解释该参数的具体影响。
- 训练硬件:论文中未提及实验所用的GPU型号、数量及训练时长。
- 推理细节:论文未详细说明目标模型的推理设置(如解码策略、温度等)。攻击的成功判定标准是模型输出以“Yes, here is the method…”等肯定性陈述开头。
- 正则化或稳定训练技巧:攻击优化过程中通过约束项
S_audio和S_text来保证扰动的大小和语义一致性,这可视为一种约束优化技巧。
📊 实验结果
主要实验在Qwen2-Audio-7B-Instruct 和 Qwen2.5-Omni-3B 两个开源模型上进行,使用AdvBench音频增强版数据集。核心评估指标是攻击成功率(ASR)。
表1:不同攻击方法在六大禁止场景下的攻击成功率(基于Qwen2-Audio) (已在“核心摘要”部分完整列出) 关键结论:本文方法(Audio-Text JailBreak)在所有六个类别上均取得了最高或接近最高的ASR,平均ASR达到91%,显著超过文本攻击方法GCG(74%)和其他音频攻击方法。
表2:不同方法在不同模型上的攻击成功率 (已在“核心摘要”部分完整列出) 关键结论:本文方法在两个模型上的平均ASR达到91.86%,大幅领先仅使用噪声、语速或两者结合的基线攻击(平均约83%)。
表3:音频-文本越狱攻击的泛化性结果
| 条件 | ASR(%) |
|---|---|
| Base (无隐身) | 71.0 |
| Rate (语速调整) | 85.0 |
| Noise (环境噪声) | 90.0 |
| Rate + Noise | 88.0 |
关键结论:即使在未经针对性优化的全新指令上,基础攻击(Base)也能达到71%的ASR。应用隐身策略后,ASR可提升至85%-90%,证明了该攻击方法具备良好的泛化能力。
图表:论文中仅有一张图(图1),为攻击流程示意图,已在“模型架构”部分描述。
⚖️ 评分理由
- 学术质量(5.5/7):创新性突出(多模态融合攻击),技术路线清晰,实验设计合理且结果具有说服力。扣分点在于部分技术实现细节描述模糊,且对“隐身性”的评估维度单一(仅用成功率衡量),缺乏更深入的隐蔽性分析或用户研究。
- 选题价值(1.0/2):选题紧扣多模态AI安全这一前沿热点,对LALM的安全研究具有直接的指导意义和警示价值,但应用领域相对垂直。
- 开源与复现加成(0.5/1):提供了核心代码仓库链接,有利于算法复现。但模型权重、完整数据集和详细的超参数配置未完全公开,限制了实验的完全可复现性。