📄 Audio Deepfake Detection at the First Greeting: “Hi!”
#音频深度伪造检测 #时频分析 #端到端 #鲁棒性 #实时处理
✅ 7.5/10 | 前25% | #音频深度伪造检测 | #时频分析 | #端到端 #鲁棒性
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Haohan Shi(拉夫堡大学伦敦分校数字技术研究所)
- 通讯作者:Yunxiao Zhang(埃克塞特大学计算机科学系)
- 作者列表:Haohan Shi(拉夫堡大学伦敦分校数字技术研究所)、Xiyu Shi(拉夫堡大学伦敦分校数字技术研究所)、Safak Dogan(拉夫堡大学伦敦分校数字技术研究所)、Tianjin Huang(埃克塞特大学计算机科学系)、Yunxiao Zhang(埃克塞特大学计算机科学系)
💡 毒舌点评
这篇论文精准地切入了音频伪造检测中一个极具现实意义的细分场景——“第一句话”检测,并为此设计了针对性的轻量化框架,实验对比充分且结果显著,工程化考量(效率、部署)也值得肯定。不过,其核心模块(PCEM, FCEM)的命名虽显“豪华”,但内部算子(如卷积、池化、GELU)的组合更像是一个精心调优的“乐高”拼装,原创的理论洞察稍显薄弱,更像是一个扎实的工程优化案例。
🔗 开源详情
- 代码:论文在结论部分声明“Codes are available.”,表明代码已公开,但未在文中提供具体的仓库链接(如GitHub URL)。
- 模型权重:未提及是否公开预训练模型权重。
- 数据集:训练数据集Dcom由多个公开数据集构建,论文未提供独立的下载链接,但指明了来源语料库。评测数据集ADD-C也已公开使用。
- Demo:未提供在线演示。
- 复现材料:提供了较为详细的训练配置信息(损失函数、优化器、调度策略、Batch Size、早停设置等),以及模型架构的主要组件和关键超参数。未提及是否提供配置文件、环境依赖或更详细的附录。
- 论文中引用的开源项目:提到了依赖的基线模型实现(LCNN, RawNet2, AASIST等)和数据集(Fake-or-Real, Wavefake, ASVspoof等)。
- 论文中未提及开源计划:除了声明代码可用外,未提及是否在特定平台维护、是否持续更新或提供issue支持等详细开源计划。
📌 核心摘要
本文旨在解决在真实世界通信降质(如编解码、丢包)条件下,对超短音频(0.5-2秒)进行深度伪造检测的挑战,典型场景是通话开头的“Hi”。作者提出了S-MGAA框架,这是对MGAA的轻量化扩展。其核心方法包括两个新模块:像素-通道增强模块(PCEM)和频率补偿增强模块(FCEM),前者从时频像素和通道维度增强伪造线索的显著性,后者通过多尺度频率分析来补偿时间信息的不足。与已有方法相比,本文首次联合关注了超短输入和通信降质鲁棒性两个方面,并设计了轻量高效的模型。主要实验结果表明:在ADD-C测试集上,S-MGAA-MFCC在0.5秒输入下的平均等错误率(EER)为3.44%,相比次优基线(RawGAT-ST)的4.52%降低了23.89%;在所有时长和降质条件下均取得最优或次优性能;同时,模型在实时因子(RTF)、浮点运算量(GFLOPs)和训练时间上展现出显著优势。该研究为实时部署在资源受限设备(如智能手机)上的早期语音欺骗检测提供了可行方案。主要局限性在于,实验评估均在合成降质数据集上进行,未在真实部署的实时通信系统中验证其端到端性能。
实验结果表格(Table 1):
| 模型 | 0.5s Avg. EER (%) | 1.0s Avg. EER (%) | 1.5s Avg. EER (%) | 2.0s Avg. EER (%) |
|---|---|---|---|---|
| MGAA-MFCC | 5.44 | 2.88 | 1.70 | 0.99 |
| RawGAT-ST | 4.52 | 2.74 | 1.75 | 1.02 |
| S-MGAA-MFCC | 3.44 | 1.50 | 0.75 | 0.36 |
实验结果表格(Table 2):
| 输入特征 | 平均EER相对改善率 |
|---|---|
| LFCC | +51.60% |
| CQCC | +42.85% |
| MFCC | +51.55% |
实验图表:
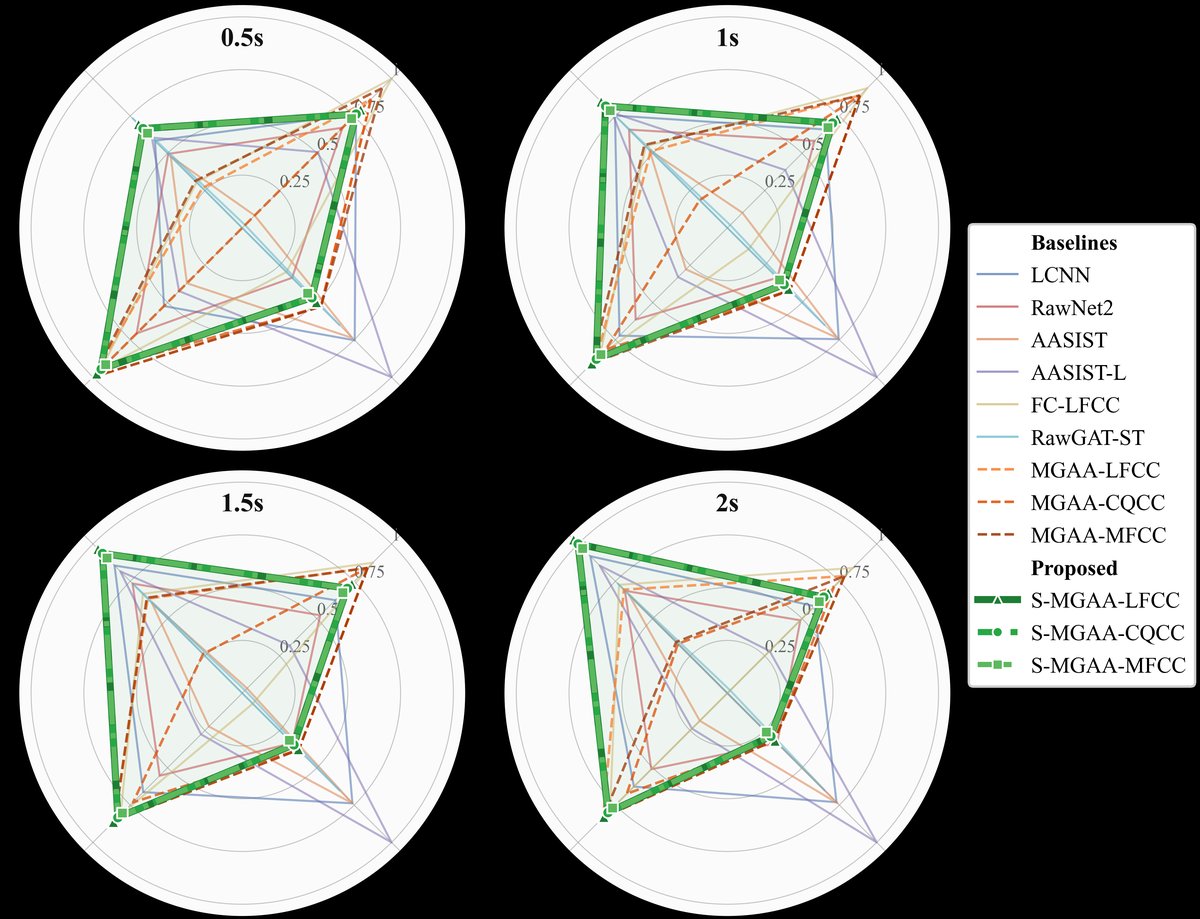 图2展示了所有基线模型在输入时长从4秒缩短至0.5秒时,平均EER普遍出现显著上升,凸显了现有方法在超短音频上的性能脆弱性,为本文工作的必要性提供了佐证。
图2展示了所有基线模型在输入时长从4秒缩短至0.5秒时,平均EER普遍出现显著上升,凸显了现有方法在超短音频上的性能脆弱性,为本文工作的必要性提供了佐证。
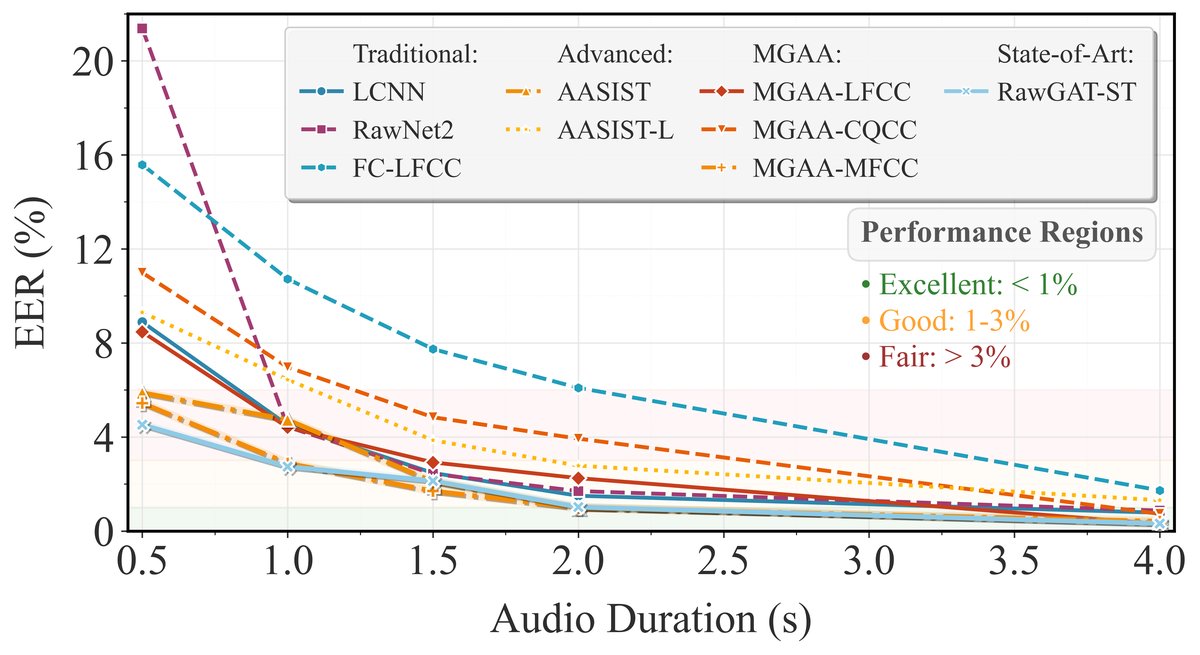 图3通过雷达图对比了S-MGAA(绿色区域)与主要基线模型在参数量、计算量、实时因子和训练时间等效率指标上的表现,直观表明S-MGAA在保持高性能的同时,具有更优的计算效率和部署友好性。
图3通过雷达图对比了S-MGAA(绿色区域)与主要基线模型在参数量、计算量、实时因子和训练时间等效率指标上的表现,直观表明S-MGAA在保持高性能的同时,具有更优的计算效率和部署友好性。
🏗️ 模型架构
S-MGAA的整体架构(图1)是一个端到端的处理流水线,旨在从超短时频特征中提取并增强判别性线索。
- 输入与预处理:输入为一段超短音频(0.5-2s),先提取时频特征(如LFCC, CQCC, MFCC),得到表示张量ζ ∈R^{B×C×F×T}(B:批大小, C:通道数, F:频率维度60, T:时间维度16/32/47/63)。
- S-MGAA核心模块:这是框架的主体,由三个顺序模块组成:
- 像素-通道增强模块(PCEM):其核心思想是联合建模像素级显著性、通道重要性和时频耦合性。公式为
PCEM(ζ) = Vc(ζ ⊙P(ζ) ⊙C(ζ) + T(ζ))。其中:P(ζ)(像素级检测器)通过一个深度卷积(HDW)和批归一化、GELU、Sigmoid激活,生成像素级掩码,突出伪造线索。C(ζ)(通道放大器)通过全局平均池化后接两个卷积(压缩和扩展),生成通道注意力权重,强调关键特征通道。T(ζ)(时频耦合)通过两个分解卷积(先(1,3)后(3,1))建模频率和时间的依赖关系。- 三者通过逐元素乘法和加法交互,再经逐点卷积
Vc混合通道信息。
- MGAA块:这是论文已有的核心注意力框架,用于对经过PCEM增强的特征进行自适应加权。
- 频率补偿增强模块(FCEM):其设计目的是弥补超短音频时间信息的不足,利用频率特征进行补偿。公式为
FCEM(δ) = F(Bi(δ), Gj(δ)) ⊙ A(δ)。它包含:- 多尺度频率分析(MFA):三个并行分支
Bi(δ)使用不同尺寸的卷积核(ki∈{20,15,10})在频率轴上操作,同时使用三个自适应池化Gj(δ)(两个最大池化,一个平均池化)获取全局频率模式。这些输出被拼接后通过卷积F(·)融合。 - 自适应时频交互(AFI):通过一个沿频率维度的(7,1)深度卷积
HDWf生成频率维度注意力图,再用Sigmoid激活,用以选择跨时间的最重要频率特征。
- 多尺度频率分析(MFA):三个并行分支
- 像素-通道增强模块(PCEM):其核心思想是联合建模像素级显著性、通道重要性和时频耦合性。公式为
- 后续处理与分类:S-MGAA处理后的特征
ψ经过两个卷积特征嵌入块(CFEB-64, CFEB-128)提升表示层次,得到ζ’。然后再次通过一个S-MGAA模块,得到最终特征ψ’。ψ’被展平后送入分类器(包含全连接层、批归一化、GELU激活和dropout),输出二元分类结果(真/假)。 - 关键设计选择:整个架构采用浅层和深层分布式S-MGAA模块的设计(即在浅层特征和深层特征上分别应用S-MGAA),消融实验证明这比仅在单一层使用更有效,能平衡低级和高级特征的学习。
💡 核心创新点
- 问题场景的首次聚焦:首次系统性地研究在真实通信降质条件下,对极短音频(0.5-2秒)进行深度伪造检测的问题。这直接回应了实时通信安全中“第一时间”防御的迫切需求,填补了现有工作在时长和降质条件交叉领域的空白。
- 针对性增强模块设计:提出了PCEM和FCEM两个轻量级模块,分别针对超短音频伪造线索稀疏和时频信息不平衡的痛点。PCEM从像素和通道维度“放大”线索,FCEM则从频率维度“补偿”时间信息的缺失,二者协同工作,提升了模型对受限信息的利用效率。
- 兼顾性能与效率的轻量化框架:在扩展MGAA框架以处理超短输入时,注重了模型的轻量化设计。实验显示,S-MGAA在实现最佳检测性能的同时,保持了极低的浮点运算量、紧凑的参数量、稳定的实时因子和较低的训练成本,使其具备在资源受限边缘设备上实时部署的潜力。
🔬 细节详述
- 训练数据:使用Dcom数据集,由6个公开语料库(Fake-or-Real, Wavefake, LJSpeech, MLAAD-EN, M-AILABS, ASVspoof2021 LA)构建,包含640,205个真实语音和1,191,865个伪造语音。数据预处理和增强严格遵循[6]的协议,包含了30种真实世界通信降质类型。
- 损失函数:使用交叉熵损失函数(Cross-Entropy Loss)。
- 训练策略:数据集按80:20划分训练集和验证集。批量大小为256,训练最多5个epoch,使用早停法(patience=3)防止过拟合。优化器为AdamW,学习率调度使用余弦退火(cosine annealing scheduler)。
- 关键超参数:输入频率维度固定为60。时间维度根据音频时长变化(0.5s对应T=16, 2.0s对应T=63)。模型的核心组件如PCEM和FCEM中的卷积核大小、压缩比率(κ=8, κ2=2)在论文中有具体说明。
- 训练硬件:在Intel Core i7-12700K CPU和NVIDIA RTX 3090 GPU(24GB)上进行训练和评估。
- 推理细节:论文未提供关于推理阶段解码策略、温度、beam size等细节,因为这是一个分类任务,通常直接输出预测概率。
- 正则化技巧:除了早停法,模型在分类器部分使用了dropout(具体值未说明)。
- 评测数据集:主要评测在ADD-C测试集上进行,该数据集包含C0(干净)到C5(不同程度编解码和丢包)六种条件。
📊 实验结果
论文在ADD-C测试集上对多种基线和所提模型进行了全面评估,结果如下:
主要性能对比(平均EER %, 越低越好)
| 模型 | 0.5s | 1.0s | 1.5s | 2.0s |
|---|---|---|---|---|
| LCNN | 8.89 | 4.51 | 2.47 | 1.50 |
| RawNet2 | 21.38 | 4.43 | 2.43 | 1.70 |
| AASIST | 5.88 | 4.73 | 2.10 | 0.99 |
| AASIST-L | 9.30 | 6.44 | 3.86 | 2.78 |
| RawGAT-ST | 4.52 | 2.74 | 1.75 | 1.02 |
| FC-LFCC | 15.58 | 10.72 | 7.74 | 6.09 |
| MGAA-LFCC | 8.47 | 4.41 | 2.92 | 2.25 |
| MGAA-CQCC | 10.99 | 6.97 | 4.84 | 3.93 |
| MGAA-MFCC | 5.44 | 2.88 | 1.70 | 0.99 |
| S-MGAA-LFCC | 5.33 | 2.46 | 1.33 | 0.66 |
| S-MGAA-CQCC | 7.87 | 4.48 | 2.59 | 1.54 |
| S-MGAA-MFCC | 3.44 | 1.50 | 0.75 | 0.36 |
关键结论:在0.5秒极端条件下,S-MGAA-MFCC(3.44%)相比最强基线RawGAT-ST(4.52%)绝对EER降低了1.08个百分点,相对降低约24%。在所有时长下,S-MGAA-MFCC均取得最优性能。
S-MGAA相对MGAA的平均EER改善率
| 输入特征 | 0.5s | 1.0s | 1.5s | 2.0s | 平均 |
|---|---|---|---|---|---|
| LFCC | +37.07% | +44.22% | +54.45% | +70.67% | +51.60% |
| CQCC | +28.39% | +35.72% | +46.49% | +60.81% | +42.85% |
| MFCC | +36.76% | +47.92% | +55.88% | +63.64% | +51.55% |
关键结论:S-MGAA在三种特征上均对原始MGAA带来了显著提升,平均改善率超过40%,证明了其设计的有效性和泛化性。
消融实验(部分数据)
- 移除PCEM或FCEM会导致所有特征和所有时长下的性能一致下降。
- 仅在深层或浅层使用S-MGAA的性能均不如在两层都使用(混合设计),验证了多层次特征精炼的重要性。
效率对比(0.5s - 2.0s输入)
- S-MGAA参数量:0.99M → 2.14M
- GFLOPs:0.02G → 0.08G
- 实时因子(RTF):0.38 → 0.10
- 训练时间:0.25h → 0.49h
- 对比基线如RawGAT-ST(GFLOPs:36.12G, 训练时间:15.78h),S-MGAA在效率上具有压倒性优势。
⚖️ 评分理由
- 学术质量:5.5/7。论文问题定义清晰、工程动机明确,提出的方法模块设计合理且有效,实验设计全面(包括不同特征、不同时长、不同降质条件下的对比、消融研究、效率分析),数据翔实,论证严谨。主要扣分点在于核心创新(PCEM, FCEM)在技术原创性上偏向于模块集成与适配,缺乏更底层的理论突破或全新视角。
- 选题价值:1.5/2。选题直接针对实时语音通信安全的痛点,聚焦“第一句话”检测这一具有挑战性且应用价值高的细分场景,符合当前AI安全领域的前沿需求,对学术界和工业界都有较强吸引力。
- 开源与复现加成:0.5/1。论文明确提供了代码(尽管未给出具体链接),并提供了包括数据划分、超参数、优化器、损失函数在内的关键训练细节,为复现提供了良好基础。但若能提供预训练模型或完整配置文件,复现性将更佳。