📄 Audience-Aware Co-speech Gesture Generation in Public Speaking via Anticipation Tokens
#跨模态 #扩散模型 #多模态模型 #音频生成
🔥 8.0/10 | 前50% | #音频生成 | #扩散模型 | #跨模态 #多模态模型
学术质量 6.3/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Huan-Yu Chen (台湾新竹清华大学电机系)
- 通讯作者:Chi-Chun Lee (台湾新竹清华大学电机系)
- 作者列表:Huan-Yu Chen (台湾新竹清华大学电机系), Woan-Shiuan Chien (台湾新竹交通大学电机与计算机工程研究所), Chi-Chun Lee (台湾新竹清华大学电机系)
💡 毒舌点评
这篇论文的亮点在于其问题重构的视角——将公共演讲手势生成从“单向语音到手势”的映射,转变为包含观众预期的“互动式”生成,这为该领域注入了新的思考维度。然而,其短板也较为明显:一是性能提升主要体现在FGD和BC上,但牺牲了手势多样性(Diversity指标下降),且面部表情生成效果改善有限;二是作为一篇顶会论文,完全没有提供任何代码或模型资源,这在强调可复现性的今天,无疑削弱了其学术贡献的落地价值和社区影响力。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开权重。
- 数据集:论文描述了如何从公开来源(TED Talks, The Daily Show)构建数据集,但未提及是否会发布处理后的、带有笑声锚点标注和特征提取的专用数据集。
- Demo:未提供在线演示。
- 复现材料:论文提供了较为详细的训练细节,包括:数据集规模、视频帧率(15fps)、片段长度(5秒:1秒前缀+4秒预测)、笑声检测阈值(0.5)、优化步数(400k)、batch size(64)、学习率(1e-4)、硬件(单卡A100 80GB,训练2天)。这些信息对复现有较大帮助。
- 论文中引用的开源项目:主要依赖预训练模型WavLM(未指明具体版本或链接)、身体/面部姿态估计工具PyMAF-X和SmoothNet、以及笑声检测器(引用[9]但未具体说明)。
- 开源计划:论文中未提及任何开源计划。
📌 核心摘要
- 问题:现有的协同语音手势生成方法大多将公共演讲视为单说话人任务,忽略了观众的存在及其与演讲者之间的动态交互。这种简化视图无法捕捉公共演讲中演讲者主动预期并引发观众反应的关键特征。
- 方法核心:提出一个观众感知的协同语音手势生成框架。核心是引入“观众响应预期令牌”,该令牌编码了即将发生的观众反应(如笑声)的符号化信息。该令牌与语音特征在预训练的语音编码器中进行早期融合,融合后的条件嵌入通过跨注意力机制指导一个基于扩散的生成器合成手势。
- 新意:与已有方法相比,新在三个方面:(1) 理论上,将单说话人手势生成重新定义为演讲者与观众预期的联合建模问题;(2) 方法上,通过符号化的预期令牌和早期融合策略,显式地建模了演讲者的“预期”心理状态;(3) 实验上,构建了一个包含正负样本(反应前/非反应)的对比数据集用于训练预期令牌。
- 实验结果:在TED Talks和The Daily Show两个数据集上的实验表明,该方法在手势真实度(FGD)和语音-手势同步性(BC)指标上优于多数基线方法。消融实验表明,将预期令牌在语音表征阶段进行早期融合或作为控制信号的中期融合,效果优于在扩散生成阶段进行后期融合。具体数值见下表:
| 模型 | 数据集 | FGD ↓ | BC ↑ | Diversity ↑ | MSE ↓ | LVD ↓ |
|---|---|---|---|---|---|---|
| DiP (最强基线) | TED Talks | 0.646 | 0.613 | 62.35 | 11.58 | 10.77 |
| 本文方法 | TED Talks | 0.633 | 0.617 | 61.29 | 11.85 | 10.55 |
| DiffSHEG (最强基线) | The Daily Show | 0.726 | 0.633 | 60.24 | 10.25 | 9.256 |
| 本文方法 | The Daily Show | 0.721 | 0.662 | 60.12 | 10.56 | 9.741 |
- 实际意义:为公共演讲、在线教育、虚拟主播等场景下的手势生成提供了更符合社交互动本质的建模思路,有望提升虚拟人或机器人的表现力和自然度。
- 主要局限:模型在提升真实度和同步性的同时,可能限制了生成手势的多样性;对更细微的面部表情生成效果提升有限;实验仅基于观众笑声这一种预期信号,且依赖预先检测,未在闭环或更动态的交互中验证。
🏗️ 模型架构
模型整体架构(如图1所示)是一个基于扩散的、条件生成的框架,主要包含三个部分:语音与预期编码器、条件融合模块、扩散手势生成器。
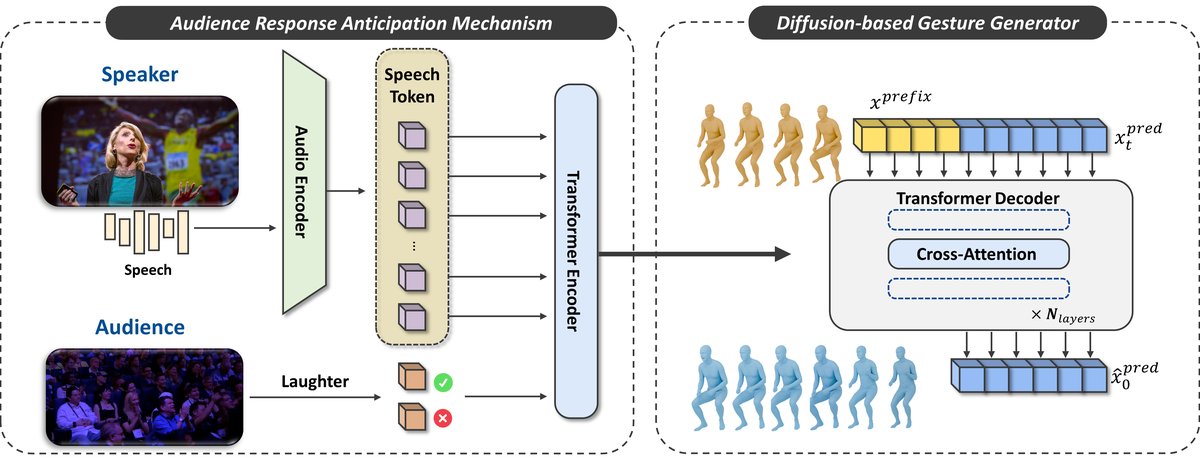 图1:整体框架概览。语音令牌和一个预期令牌被输入到语音基础模型中,其输出通过交叉注意力指导一个扩散生成器,该生成器以手势前缀和噪声序列作为条件。
图1:整体框架概览。语音令牌和一个预期令牌被输入到语音基础模型中,其输出通过交叉注意力指导一个扩散生成器,该生成器以手势前缀和噪声序列作为条件。
- 输入:语音信号(波形)、已观测的短时手势/面部表情前缀(
x_prefix,1秒)、以及一个二元标签(指示当前段是否即将引发观众反应)。 - 语音与预期编码器:
- 语音编码器:使用预训练的WavLM模型。其CNN编码器首先将语音波形转换为一系列语音嵌入序列(
[x_s1, ..., x_st])。 - 预期令牌生成:基于二元标签,生成一个可学习的离散向量
token_aa(维度与语音嵌入相同)。 - 融合与编码:将
token_aa直接插入到语音嵌入序列的开头(即[token_aa, x_s1, ..., x_st]),形成一个增强序列。该序列被送入WavLM的Transformer编码器,得到融合了演讲者语音内容和观众预期信息的条件嵌入C ∈ R^(T+1)×768。此过程即早期融合策略,让预期信息从一开始就影响语音表征。
- 语音编码器:使用预训练的WavLM模型。其CNN编码器首先将语音波形转换为一系列语音嵌入序列(
- 扩散手势生成器:
- 输入:以手势前缀
x_prefix(已观测的709维手势与表情序列)和随机高斯噪声x_T作为起始。 - 条件:上述条件嵌入
C。 - 去噪过程:通过交叉注意力机制,条件
C在每个去噪步骤中指导噪声序列x_t向目标手势序列x_pred进行去噪(如公式2所示)。网络学习的是直接回归目标动作序列(如公式3的损失函数所示)。
- 输入:以手势前缀
- 输出:生成的完整手势与面部表情序列。
关键设计选择:
- 早期融合:将预期令牌与语音令牌在编码器最前端结合,使得预期信息能够深度调制语音表征,而非仅仅作为后处理信号。消融实验证明这比后期融合更有效。
- 扩散生成器:利用扩散模型在复杂分布建模上的优势,生成多样且逼真的连续动作序列。
- 条件嵌入:通过跨注意力将丰富的语义条件(语音+预期)注入到动作生成过程中,实现了灵活可控的合成。
💡 核心创新点
问题重构:从单向映射到预期交互
- 局限:先前工作将公共演讲手势生成视为语音到手势的单向映射,忽略了演讲者对观众反应的主动预期这一关键社交动态。
- 如何起作用:该框架将观众反应(如笑声发生前的段落)作为“预期信号”,并将生成目标从“根据当前语音生成手势”转变为“根据当前语音和即将到来的观众反应生成手势”。
- 收益:使生成的手势更能体现演讲者的沟通意图和对观众的引导,提升了手势的上下文合理性和社交适切性。
方法创新:离散预期令牌与早期融合
- 局限:之前的方法或完全忽略观众信号,或将其作为连续的后处理输入,未能高效地将这种高层的、符号化的意图信息与底层的连续语音信号对齐。
- 如何起作用:引入一个可学习的、离散的
token_aa来代表“即将发生观众反应”这一抽象概念。通过将其与语音令牌序列在WavLM编码器中进行早期融合,迫使模型在语音理解阶段就共同编码语言内容和预期情境。 - 收益:消融研究证实,早期融合(或中期融合)在FGD和BC指标上显著优于后期融合,证明了这种将预期信息“提前”整合到语音表征中的策略是更优的。
数据构建:基于反应锚点的对比学习
- 局限:缺乏包含明确观众反应时序信息的公共演讲手势数据集。
- 如何起作用:创新性地使用观众笑声作为“时间锚点”。构建正样本(笑声发生前的段落)和负样本(同一演讲中无笑声的段落)形成对比对。笑声仅用于定义时间窗口,不作为模型输入。
- 收益:创建了一个可用于训练和评估预期建模能力的专用数据集(1764个视频,超过450小时),并通过对比设计使模型能更清晰地区分“有预期”和“无预期”的演讲状态。
🔬 细节详述
- 训练数据:
- 来源与规模:TED Talks(1764个视频,371.15小时,7542次笑声)和《The Daily Show》(10集,6.37小时,1000次笑声)。
- 预处理:使用PyMAF-X提取SMPL-X身体参数,SmoothNet平滑抖动。身体运动
g为659维(含骨盆相对速度、关节位置/速度、6D旋转、脚接触标签),面部表情f为50维SMPL-X表情系数。组合成709维向量。 - 数据构建:使用置信度阈值0.5的笑声检测器。正样本为笑声前固定长度的片段,负样本为同一演讲中至少距笑声1秒以上、且无观众信号的片段。
- 损失函数:
- 采用与扩散模型等效的动作序列回归损失(公式3)。即在训练时,对带噪的目标动作序列进行去噪,目标是直接预测干净的动作序列
x0,而非预测添加的噪声。损失为预测序列与真实序列的L2距离的期望。
- 采用与扩散模型等效的动作序列回归损失(公式3)。即在训练时,对带噪的目标动作序列进行去噪,目标是直接预测干净的动作序列
- 训练策略:
- 优化器:论文未明确说明,但通常使用AdamW。
- 学习率:1e-4。
- Batch Size:64。
- 训练步数:400k步。
- 调度策略:论文未提及。
- 关键超参数:
- 视频帧率:15 fps。
- 序列长度:总长5秒(75帧)。其中前缀
x_prefix为1秒(15帧),预测窗口x_pred为4秒(60帧)。 - 模型基础:基于WavLM(隐藏维度768)的语音编码器,以及基于扩散模型的生成器(具体架构细节未详细说明)。
- 训练硬件:
- 单块NVIDIA A100 80GB GPU。
- 训练时长:约2天。
- 推理细节:
- 论文未详细描述推理时的采样步数、温度等参数。
- 正则化或稳定训练技巧:
- 使用SmoothNet对提取的关节进行平滑,可视为一种数据预处理正则化。
- 非负样本的构建有严格标准,避免了数据污染。
📊 实验结果
主要对比实验(表1): 论文在TED Talks和The Daily Show两个数据集上,与多个单说话人(CaMN, TalkSHOW, DiffSHEG, EMAGE)和文本到动作(MDM, DiP)基线模型进行了比较。指标包括手势真实度(FGD↓)、同步性(BC↑)、多样性(Diversity↑)以及面部动作误差(MSE↓, LVD↓)。
表1:在TED Talks和The Daily Show数据集上的定量评估。改进的FGD分数表明本文模型生成的手势与真实值保真度更高,验证了观众线索在手势合成中的效用。
关键结论:
- 手势真实度与同步性:本文方法在核心的手势生成指标上取得了领先或极具竞争力的结果。在TED Talks上,取得了最低的FGD(0.633)和最高的BC(0.617),超越了次优的DiP(0.646, 0.613)。在The Daily Show上,取得了最低的FGD(0.721)和最高的BC(0.662),超越了DiffSHEG(0.726)和DiP(0.644)。
- 多样性权衡:本文模型在多样性指标上表现一般。在TED Talks上(61.29)低于MDM(68.24)和TalkSHOW(66.29);在The Daily Show上(60.12)低于TalkSHOW(65.29)和MDM(64.57)。表明观众预期建模可能在提高保真度的同时约束了生成动作的方差。
- 面部表情:改进有限且不一致。在TED Talks上,LVD(10.55)优于多数基线但次于EMAGE(10.23);在The Daily Show上,LVD(9.741)有竞争力但次于DiffSHEG(9.256)。这可能由于15fps的设置更利于捕捉身体运动,以及多模态联合优化中身体动作占主导。
消融实验(表2): 针对预期令牌的融合策略进行了消融研究,测试了早期(Early)、中期(Mid)、晚期(Late)及其组合。
表2:在TED Talks和The Daily Show数据集上,对预期令牌融合策略的消融研究。早期融合调制语音特征,中期融合充当控制信号,晚期融合调整手势生成。
关键结论:
- 早期与中期融合占优:早期融合在同步性(BC)上最优(TED: 0.617, Daily: 0.662),中期融合在真实度(FGD)上最优(TED: 0.631, Daily: 0.720)。这两种策略都显著优于晚期融合。
- 晚期融合效果差:单独使用晚期融合(-,-,✓)在两个数据集上都导致了最差或次差的结果(如TED FGD: 0.655, BC: 0.605)。即使与其他策略组合,晚期融合的加入也往往带来性能下降(对比✓,-,-与✓,-,✓)。
- 启示:预期信息最有效的整合时机是在语音表征阶段,即在它和语音信号深度交互之前。将其作为生成阶段的后处理信号效果不佳。
⚖️ 评分理由
- 学术质量:6.3/7
- 创新性(1.8/2):将观众预期引入手势生成框架是一个新颖且合理的视角,问题重构和预期令牌的设计有独到之处。
- 技术正确性(1.5/2):技术路线清晰、完整,基于成熟的预训练模型和扩散模型,方法论上没有明显错误。
- 实验充分性(1.5/2):在两个大规模数据集上与众多基线对比,并进行了关键的消融研究,实验设计较为全面。但未测试更多样化的场景或更长期的序列。
- 证据可信度(1.5/2):指标选择和结果报告规范,消融结果有力支持了核心设计点(融合策略)。但所有评估基于离线生成,未进行主观用户研究(如MOS)来评估感知自然度。
- 选题价值:1.5/2
- 前沿性(0.8/1):属于多模态生成与人机交互的交叉前沿,关注点从内容生成转向社交交互建模,符合趋势。
- 影响与应用(0.7/1):对提升虚拟人、数字人、机器人在公共演讲场景下的表现力有明确价值,应用潜力具体。
- 开源与复现加成:0.0/1
- 论文仅提供了详尽的文本描述(如数据处理流程、超参数),但未提供代码、模型、数据集或Demo。对于一篇需要复现复杂多阶段流程的论文而言,这大大增加了复现门槛,因此复现加分为0。