📄 Attentive Masked Self-Distillation for Respiratory Sound Classification
#音频分类 #知识蒸馏 #数据增强 #医学音频
✅ 7.5/10 | 前25% | #音频分类 | #知识蒸馏 | #数据增强 #医学音频
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Nuo Chen(浙江大学集成电路学院)
- 通讯作者:Mingsheng Xu(浙江大学集成电路学院)
- 作者列表:Nuo Chen(浙江大学集成电路学院)、Mingsheng Xu(浙江大学集成电路学院)
💡 毒舌点评
亮点:论文针对呼吸声分类中数据预处理(循环填充)引入的捷径学习问题,设计了一个巧妙的“注意力掩码”机制,能动态地屏蔽模型容易过度依赖的声谱图区域,这比随机掩码更具针对性,且可视化结果令人信服。短板:尽管在ICBHI上取得了SOTA级别的性能,但实验仅在一个中等规模的数据集上进行,且模型骨架(AST)的参数量巨大(~90M),对于实际的医疗边缘部署可能并不友好,论文对此的讨论不足。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:https://github.com/CcnNnn/AMS-D。
- 模型权重:论文中未提及是否公开预训练或训练好的模型权重。
- 数据集:使用公开的ICBHI 2017数据集,但未在论文中说明具体获取方式(通常需自行申请)。
- Demo:论文中未提及在线演示。
- 复现材料:论文给出了主要训练细节:优化器(Adam)、学习率(5e-5及衰减策略)、Batch size(24)、训练轮数(50)、损失函数权重(α=1.0, β=0.03, γ=0.3)、掩码比例(39%)。但未提供完整的配置文件、检查点或环境依赖说明。
- 论文中引用的开源项目:
- 核心骨干模型:Audio Spectrogram Transformer (AST) [3]。
- 数据集:ICBHI 2017呼吸声数据库 [17]。
- 对比方法:Patch-Mix [4], LungAdapter [18], MVST [20], Gap-Aug [6] 等。
- 训练工具:Adam优化器 [19]。
📌 核心摘要
这篇论文旨在解决基于Transformer的呼吸声分类模型因参数量大、训练数据少而导致的过拟合,以及因音频预处理(循环填充)引入的冗余信息导致的捷径学习问题。方法核心是提出一个名为“注意力掩码自蒸馏”的框架,它结合了渐进式自蒸馏(将前一epoch模型作为教师,用KL散度对齐logits)和一种创新的注意力掩码策略:利用教师模型的特征通过Token权重模块计算每个token的重要性,并在当前epoch的学生模型中掩蔽掉最显著(即最可能成为捷径特征)的token。此外,模型还引入了一个重建任务,以掩蔽的token为目标进行重建,作为正则化项增强表示的鲁棒性。与已有方法相比,其新意在于将知识蒸馏、针对捷径特征的主动掩蔽以及重建正则化三者有机结合。在ICBHI数据集上的实验表明,该方法取得了具有竞争力的结果,敏感性达到60.92%,ICBHI综合得分为67.54%,优于Gap-Aug等强基线。消融实验和可视化分析证实了各组件的有效性以及模型关注临床相关声学区域的能力。该工作的实际意义在于为医疗音频分析提供了一种更鲁棒、泛化能力更强的建模思路,但其局限性在于主要验证集中在一个公开数据集,且使用了参数量庞大的预训练模型,计算效率未做深入探讨。
| 方法 | 架构 | 敏感性(%) | 特异性(%) | ICBHI得分(%) |
|---|---|---|---|---|
| Co-tunning [21] | ResNet50 | 37.24 | 79.34 | 58.29 |
| Patch-Mix CL [4] | AST | 43.07 | 81.66 | 62.37 |
| SG-SCL [22] | AST | 43.55 | 79.87 | 61.71 |
| BST [23] | CLAP | 45.67 | 81.40 | 63.54 |
| LungAdapter [18] | AST | 44.37 | 80.43 | 62.40 |
| MVST [20] | AST | 51.10 | 81.99 | 66.55 |
| Gap-aug [6] | CNN14 | 58.20 | 77.07 | 67.64 |
| LoRA [24] | AST | 36.11 | 85.31 | 60.71 |
| AMS-D (ours) | AST | 60.92 | 74.16 | 67.54 |
表1: ICBHI数据集性能对比(引自论文)
| 掩码策略 | 敏感性(%) | 特异性(%) | ICBHI得分(%) |
|---|---|---|---|
| 无掩码 | 44.28 | 82.79 | 66.11 |
| 随机掩码 | 63.14 | 70.68 | 66.91 |
| 时间区间掩码 | 63.05 | 67.64 | 65.35 |
| 频率区间掩码 | 89.42 | 16.09 | 52.75 |
| 注意力掩码(ours) | 60.92 | 74.16 | 67.54 |
表2: 不同掩码策略性能对比(引自论文)
| 模型配置 | 敏感性(%) | 特异性(%) | ICBHI得分(%) |
|---|---|---|---|
| 基线(AST) | 64.47 | 67.15 | 65.81 |
| + 自蒸馏 | 44.28 | 82.79 | 66.11 |
| + 自蒸馏 + 掩码 | 49.49 | 74.35 | 61.92 |
| AMS-D (完整) | 60.92 | 74.16 | 67.54 |
表3: 消融实验(引自论文)
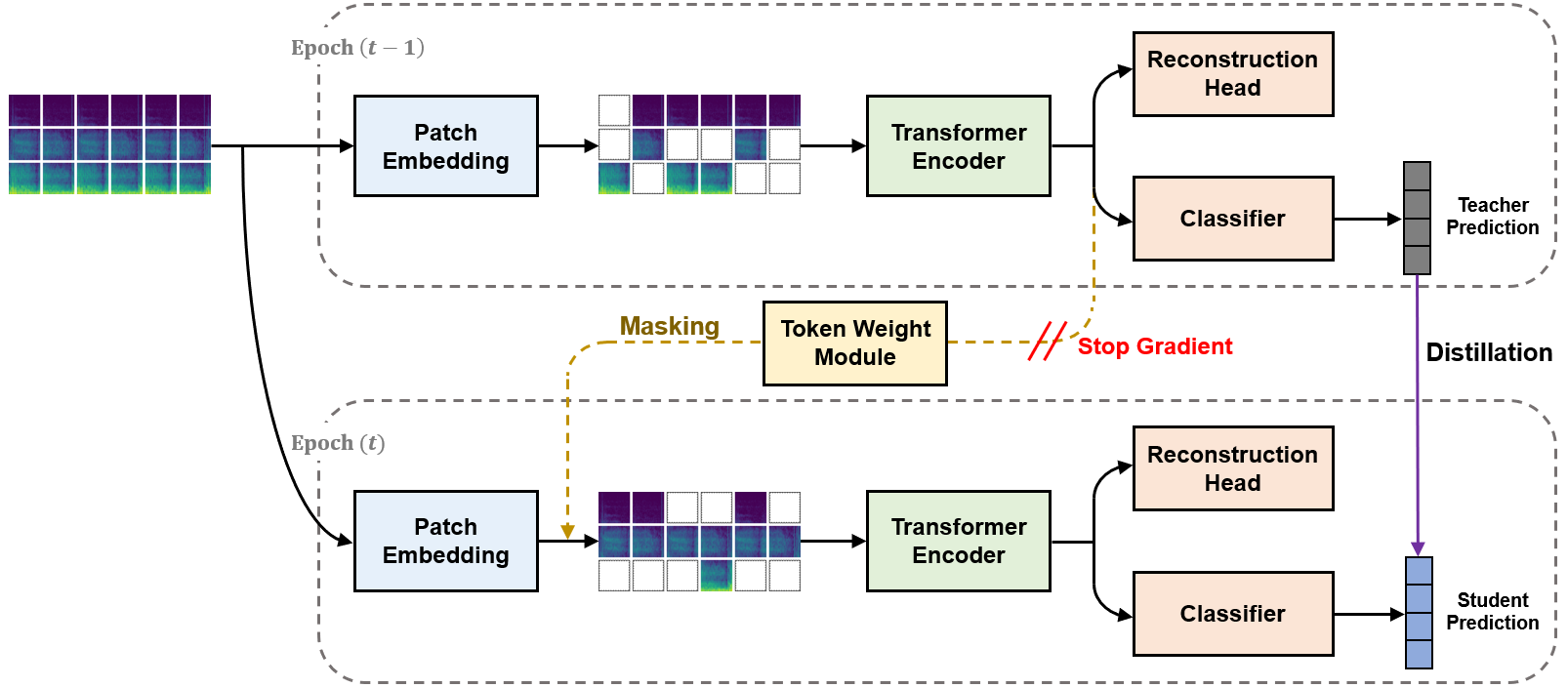 图1展示了AMS-D的整体框架:左侧为渐进式自蒸馏,t-1 epoch的教师模型提供logits用于计算蒸馏损失;右侧为注意力掩码策略,教师模型的最终层特征经Token权重模块生成掩码,应用于t epoch学生的输入,并加入了重建任务。
图1展示了AMS-D的整体框架:左侧为渐进式自蒸馏,t-1 epoch的教师模型提供logits用于计算蒸馏损失;右侧为注意力掩码策略,教师模型的最终层特征经Token权重模块生成掩码,应用于t epoch学生的输入,并加入了重建任务。
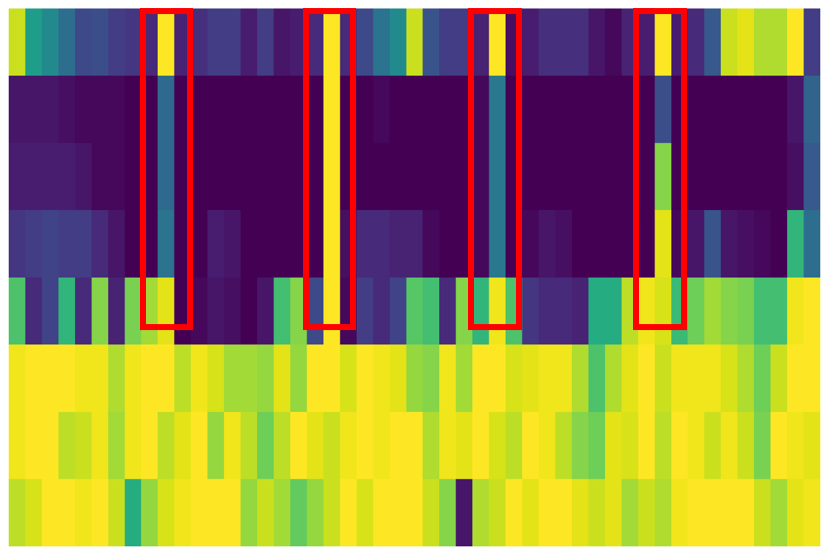 图2展示了在喘鸣音(crackle)声谱图上不同掩码策略的对比(上排),以及注意力掩码在不同训练阶段的选择频率热图(下排)。它表明,注意力掩码策略能动态地、结构性地屏蔽与病理特征相关的区域(如红框所示的高频区域),而非随机分散。
图2展示了在喘鸣音(crackle)声谱图上不同掩码策略的对比(上排),以及注意力掩码在不同训练阶段的选择频率热图(下排)。它表明,注意力掩码策略能动态地、结构性地屏蔽与病理特征相关的区域(如红框所示的高频区域),而非随机分散。
🏗️ 模型架构
本文提出的AMS-D框架旨在增强Audio Spectrogram Transformer (AST) 在呼吸声分类任务上的鲁棒性。其整体架构围绕一个核心思想:利用模型自身的历史知识(上一训练轮次)来指导当前轮次的学习,具体通过两条路径实现:知识蒸馏和注意力掩蔽。
- 骨干网络:采用在ImageNet和AudioSet上预训练的Audio Spectrogram Transformer (AST),并进行全参数微调。输入为呼吸声音频预处理后得到的梅尔频谱图。
- 渐进式自蒸馏模块:
- 功能:将前一个训练轮次(epoch t-1)的模型作为“教师”,当前轮次(epoch t)的模型作为“学生”,通过KL散度损失使两者的输出logits对齐。
- 数据流:前一轮次模型的分类输出
qt-1与当前轮次模型的输出qt共同计算蒸馏损失Ldistill = KL(qt || qt-1)。 - 设计动机:相比传统的双模型蒸馏,此方法更高效。论文发现直接对齐logits比PS-KD中提出的动态软标签更稳定。
- 注意力掩码策略模块:
- 功能:动态识别并遮蔽输入声谱图中最显著的token(可能对应捷径特征),迫使模型从上下文中学习。
- 内部结构与数据流:
- 输入:取自教师模型(epoch t-1)最后一层的token序列
zi,并应用了stop-gradient操作以稳定训练。 - Token权重模块 (TWM):由1D卷积层、层归一化、全连接层和Softmax层组成。它输出每个token的重要性权重
ai。 - 掩码生成:根据权重
ai,选择重要性最高的部分token(论文中掩码比例为39%)作为待掩蔽集合M。 - 应用掩码:在当前轮次(epoch t)学生的Transformer编码器输入前,将对应位置的token值置零或进行掩蔽处理。
- 辅助损失:TWM内部还通过加权求和生成一个汇总token
zcls,送入一个辅助分类器,其交叉熵损失Lmask用于优化TWM,确保其学习到的权重与分类目标相关。
- 输入:取自教师模型(epoch t-1)最后一层的token序列
- 设计动机:解决因循环填充等预处理引入的冗余信息导致的捷径学习。选择性掩蔽高权重token,能更有效地打破模型对局部伪特征的依赖。
- 重建模块:
- 功能:作为正则化器,防止模型在掩蔽后从无意义的token中学习平凡表示。
- 数据流:在编码器之后,添加一个重建头(论文未详细说明其结构),以被掩蔽的原始token
zi为监督信号,输出重构值ri。 - 损失函数:计算重构误差
Lrecon = MSE(ri, zi)。
- 整体学习目标:总损失
L = Ltask + αLdistill + βLmask + γLrecon,其中Ltask是主任务的交叉熵损失,α, β, γ是平衡权重(实验设为1.0, 0.03, 0.3)。
💡 核心创新点
- 针对性注意力掩码以对抗捷径学习:不同于音频领域常用的随机掩码(如MAE),本文提出的TWM能利用教师模型的知识,动态计算并掩蔽那些最可能成为“捷径特征”的声谱图区域。这是对预处理冗余问题(循环填充)的直接、主动的干预。
- 渐进式自蒸馏的改进应用:在PS-KD框架基础上,简化了蒸馏目标(直接对齐logits),并将其与掩码策略结合。自蒸馏本身提供了时间维度上的知识传递与正则化。
- 掩码与重建的协同设计:掩码策略负责“破坏”捷径路径,而重建任务负责在破坏后引导模型学习更鲁棒的上下文表征。消融实验表明,二者单独使用效果不佳,结合后才能达到最佳性能,体现了设计的完备性。
- 针对医疗音频的轻量级优化思想:虽然使用了大模型(AST),但AMS-D框架本身旨在通过更智能的训练策略(而非增大模型)来提升小数据集上的性能,具有一定的实用价值。
🔬 细节详述
- 训练数据:
- 数据集:ICBHI 2017呼吸声数据库。
- 规模:920个录音,126名受试者,共6898个呼吸周期(含1864个crackles, 886个wheezes, 506个both)。
- 预处理:重采样至16kHz,循环填充至8秒统一长度,生成128维梅尔频谱图(25ms Hanning窗,10ms步长)。
- 数据增强:对原始音频进行时间域增强以解决类别不平衡;在训练10个epoch后,对频谱图应用随机噪声和随机时间滚动。
- 损失函数:
Ltask:分类任务的交叉熵损失。Ldistill:KL散度损失,用于对齐师生logits,权重α=1.0。Lmask:辅助分类器的交叉熵损失,用于优化Token权重模块,权重β=0.03。Lrecon:掩蔽token的重建均方误差损失,权重γ=0.3。
- 训练策略:
- 优化器:Adam。
- 学习率:初始5e-5,训练15个epoch后,每5个epoch衰减0.2。
- Batch Size:24。
- 训练轮数:50个epoch。
- 关键超参数:
- 掩码比例:39%(通过验证集扫描确定)。
- 模型大小:AST骨干,总可训练参数89.66M。
- 训练硬件:论文未说明。
- 推理细节:论文未说明解码策略等具体细节,分类任务通常直接取最后一层[CLS] token的输出进行softmax得到类别概率。
- 正则化技巧:
- Token权重模块输入前的stop-gradient操作,用于稳定跨epoch的依赖训练。
- 渐进式自蒸馏和重建任务本身作为重要的正则化手段,防止过拟合。
📊 实验结果
- 主实验(表1):在ICBHI数据集上,与多种SOTA方法对比。AMS-D的ICBHI综合得分为67.54%,与当前最佳Gap-Aug (67.64%)相当。值得注意的是,AMS-D的敏感性(60.92%)显著高于Gap-Aug (58.20%)和MVST (51.10%),表明其在识别异常呼吸声样本方面更具优势,但其特异性(74.16%)低于多个基线方法。
- 掩码策略对比实验(表2):在39%掩码率下,注意力掩码策略的ICBHI得分(67.54%)最高。其敏感性(60.92%)低于随机掩码(63.14%),但特异性(74.16%)远高于随机掩码(70.68%)和无掩码(82.79%)。随机掩码在敏感性上表现最强,但特异性下降,说明其正则化效果强但可能过于均匀。频率区间掩码性能最差,因其破坏了频谱结构。
- 消融实验(表3):
- 基线AST得分65.81%。
- 单独加入自蒸馏:敏感性大幅下降(64.47% -> 44.28%),特异性大幅提升(67.15% -> 82.79%),得分微升至66.11%。这表明自蒸馏主要影响了模型的判定倾向。
- 自蒸馏+掩码(无重建):性能显著下降至61.92%,验证了仅破坏而不重建会导致性能损失。
- 完整AMS-D:性能恢复并超越基线,达到67.54%,证明了掩码与重建结合的必要性。
- 可视化分析(图2):
- 上排:在crackle样本上,随机掩码均匀覆盖频谱,而注意力掩码呈现出结构化模式,集中屏蔽了信息丰富的低频区域,并特别地屏蔽了红框标出的、可能与crackle相关的高频薄区域。
- 下排(热图):显示了在50个训练周期内,被注意力掩码选中的token的频率热图。可以看出,模型在训练过程中收敛到一种稳定的掩码模式,持续地高概率屏蔽特定区域(尤其是与crackle相关的高频区),证实了TWM能学习到有临床意义的、上下文感知的掩码策略。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个设计合理、组件互补的框架来解决呼吸声分类中的具体问题。创新点(注意力掩码)有清晰的动机和有效的验证。实验设计规范,包含了关键的消融研究和可视化分析,证据可信。扣分点在于:1)核心创新是现有模块(自蒸馏、掩码、重建)的组合与适配,原创性未达到里程碑级别;2)模型基于大型预训练AST,在资源受限的医疗场景下的适用性讨论不足。
- 选题价值:1.5/2:医疗音频分析是重要的应用方向,呼吸声分类具有明确的临床需求。论文关注的“捷径学习”问题是深度学习在该领域的一个真实挑战。成果对相关音频/语音任务(如使用相似预处理的分类任务)有参考价值。
- 开源与复现加成:0.5/1:提供了代码仓库链接,给出了关键的训练超参数、损失函数设置和数据集使用描述,这对于复现论文的核心方法是充分的。但模型权重、完整的数据预处理脚本、详细的硬件配置等未提及,因此加成分有限。