📄 Attentive AV-Fusionnet: Audio-Visual Quality Prediction with Hybrid Attention
#音视频 #多模态模型 #注意力机制 #模型评估 #工业应用
✅ 7.0/10 | 前25% | #音视频 | #注意力机制 | #多模态模型 #模型评估
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Ina Salaj (Dolby Germany GmbH)
- 通讯作者:未说明(根据作者列表和常规署名,第一作者或第二作者可能为通讯作者,但论文中未明确标注)
- 作者列表:Ina Salaj (Dolby Germany GmbH), Arijit Biswas (Dolby Germany GmbH)
💡 毒舌点评
亮点:论文提出的混合注意力融合框架(结合GML学习特征和VMAF手工特征)设计精巧,实验结果在内部数据集上显著优于基线(Rp提升至0.97),且提供了可解释的模态重要性估计。短板:论文严重依赖于Dolby的“内部数据集”和“内部实现的GML/VMAF特征”,外部可复现性存疑,且在公开基准LIVE-SJTU上的提升(如RMSE从0.47降至0.44)相对有限,未能完全证明其“鲁棒性”声称。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了内部数据集,未公开。外部使用的LIVE-SJTU为公开数据集,但论文中未提供获取链接。
- Demo:未提及。
- 复现材料:提供了模型架构描述、损失函数、部分超参数搜索空间,但缺少训练细节(如epoch数、硬件、精确的训练时间)和最终配置。
- 论文中引用的开源项目/模型:引用了GML [14](未开源)和VMAF [11](VMAF本身开源,但论文使用其内部特征)。依赖的框架包括AdamW优化器,但未提及具体深度学习框架。
- 总结:论文中未提及开源计划,复现主要依赖论文描述,门槛较高。
📌 核心摘要
- 问题:现有音视频质量评估(AVQ)方法常采用简单的融合策略(如加权求和),无法有效建模内容相关的跨模态动态依赖关系(例如,高质量视频可补偿音频瑕疵),且依赖过时的单模态特征。
- 方法:提出Attentive AV-FusionNet。模型首先提取视频VMAF内部特征(6维)和音频GML深层特征(512维)。通过可学习投影将视频特征对齐到音频空间。核心融合阶段采用双向多头交叉注意力,使音频和视频特征相互关注,生成1024维联合表征;随后使用自注意力进一步精炼该表征,以捕捉模态内依赖。最终通过浅层全连接网络预测质量分数。
- 创新:1) 融合了深度学习(GML)和传统感知模型(VMAF)的异构特征;2) 利用混合注意力机制显式建模跨模态和模态内交互;3) 引入了模态相关性估计器,可量化每个模态对最终预测的贡献。
- 结果:在内部数据集(1500训练,125测试)上,该模型达到 Pearson (Rp) = 0.97, Spearman (Rs) = 0.96, RMSE = 0.22,显著优于加权乘积基线(Rp=0.84)和SVR方法(Rp=0.90)。在外部LIVE-SJTU数据集上,取得 Rp=0.92, Rs=0.92, RMSE=0.44,表现与SVR-8F(Rp=0.90)和Recursive AV-FusionNet(Rp=0.92)相当或略优。
- 意义:该模型为流媒体平台提供了更准确、可解释的音视频联合质量预测工具,其模态重要性估计为实现内容自适应的音视频比特率分配提供了可能。
- 局限:模型依赖于未公开的内部数据集和特定特征提取器(GML、VMAF内部表示),外部验证数据集(LIVE-SJTU)规模有限,且未能提供代码或详细复现指南。
🏗️ 模型架构
Attentive AV-FusionNet 是一个端到端的全参考音视频质量预测模型,包含三个主要阶段:特征提取、注意力融合、质量预测。
- 特征提取与对齐
- 视频特征:从VMAF的内部表示中提取,包括4个VIF特征、1个运动特征(Motion2)和1个加性细节特征(ADM),共6维($d_v=6$)。这些特征在时间维度上进行池化,得到片段级特征 $X_v \in \mathbb{R}^{N \times 6}$,其中 $N=1$。
- 音频特征:从生成式机器听者(GML)的深层(最后一个全连接层之前)提取,维度为512($d_a=512$),得到 $X_a \in \mathbb{R}^{N \times 512}$。
- 模态对齐:通过一个可学习的线性投影层(带GELU激活)将6维视频特征映射到512维空间,使其与音频特征维度一致:$X’_v = \sigma(X_v W_v)$,其中 $W_v \in \mathbb{R}^{6 \times 512}$。此设计旨在保持模块轻量化,同时将两个模态置于同一表征空间。
- 基于注意力的融合
- 双向交叉注意力:采用标准Transformer多头注意力机制,但不使用位置编码和残差连接(作者认为池化特征已含时序信息)。
- 音频到视频:以投影后的视频特征 $X’v$ 为查询(Query),音频特征 $X_a$ 为键(Key)和值(Value),计算交叉注意力 $X{ca}^v$。
- 视频到音频:反之,以 $X_a$ 为查询,$X’v$ 为键和值,计算 $X{ca}^a$。
- 拼接:将两个方向的交叉注意力输出拼接,形成1024维(512+512)的联合表征 $J = [X_{ca}^a; X_{ca}^v]$。
- 自注意力:对联合表征 $J$ 应用自注意力,以进一步精炼模态内的上下文信息,得到 $J_{self}$。此步骤旨在增强模态内部的依赖关系建模。
- 预测
- 将 $J_{self}$ 输入一个浅层前馈网络(FFN),包含非线性激活(如GELU、Tanh)和Dropout,最终输出预测的音视频质量分数 $\hat{Q}_{av}$。浅层设计是为了避免过拟合,主要性能提升归功于注意力机制。
- 模态重要性估计(推理阶段附加)
- 提供两种互补指标:
- 消融敏感性:计算遮蔽某一模态后模型输出的变化,量化模型对该模态的依赖程度。
- 特征变化范数:比较交叉注意力前后模态嵌入的变化,较小的变化表明该模态在融合中更独立、稳定。
- 最终重要性得分为两者加权组合。
 图1:Attentive AV-FusionNet架构示意图。展示了从VMAF和GML提取特征,通过投影层对齐,经过双向交叉注意力和自注意力进行融合,最终通过FFN输出质量分数的过程。模型总参数量约为740万。
图1:Attentive AV-FusionNet架构示意图。展示了从VMAF和GML提取特征,通过投影层对齐,经过双向交叉注意力和自注意力进行融合,最终通过FFN输出质量分数的过程。模型总参数量约为740万。
💡 核心创新点
- 混合特征融合框架:创新性地将深度学习模型(GML)学习到的音频特征与传统感知视频质量模型(VMAF)的手工特征相结合。这利用了GML在现代音频编码上的优势和VMAF在视频质量评估上的成熟度与可解释性,弥补了单一特征来源的不足。
- 双向交叉-自注意力融合机制:不同于简单的加权融合或单向注意力,该模型采用双向交叉注意力让音频和视频特征相互“观察”和“解释”,显式建模动态的跨模态依赖。随后,自注意力模块进一步处理融合后的联合表征,以捕捉模态内部的全局关系。这种混合注意力设计能更全面地捕获音视频间的复杂交互。
- 内容感知的模态重要性估计:提出了一个新颖的模块,通过消融敏感性和特征变化范数两种指标,为每个输入内容片段量化音频和视频模态的相对贡献。这不仅提供了可解释性,还为实际应用(如根据内容动态分配音视频码率)提供了直接的技术路径。
🔬 细节详述
- 训练数据:
- 内部数据集:65个源片段,编码为25种音视频组合(5种视频码率:0.5-25 Mb/s H.264;5种音频码率:16-256 kb/s,使用HE-AACv2/v1和AAC编码),共1625个刺激。主观评分由10位参与者在ITU合规条件下完成,采用5分MOS,共16,250个评分。训练集1500个刺激,测试集125个刺激(5个源片段)。
- 外部数据集(LIVE-SJTU):14个源视频,使用H.265和AAC编码。评估时排除了8 kb/s的音频码率,使用32-128 kb/s。MOS评分缩放到[0, 100]。
- 数据预处理:对不同数据集的MOS尺度使用IBM变换进行了对齐。
- 损失函数:结合了一致性相关系数(CCC) 和 均方根误差(RMSE) 的损失:$L = \lambda (1 - CCC) + (1 - \lambda) RMSE$。实验中设定 $\lambda = 0.6$,旨在平衡预测的排序一致性(与主观评分相关性)和绝对误差。
- 训练策略:
- 优化器:AdamW。
- 学习率与权重衰减:搜索范围分别为 $10^{-4}$ 到 $10^{-2}$ 和 $10^{-3}$ 到 $10^{-1}$。
- 批大小:32。
- 训练轮数/步数:未明确说明。
- 交叉验证:使用5折交叉验证进行超参数调优。
- 激活函数:主要使用GELU。
- Dropout:在FFN中使用,比率搜索范围为0.1-0.6。
- 关键超参数:
- 注意力层维度:交叉注意力 $d_k = 512/H$,自注意力 $d_k^{(j)} = 1024/H_j$。
- 头数(H):{2, 4, 8}。
- 前馈网络维度:{256, 512, 1024}。
- 交叉注意力层数:音频到视频和视频到音频方向均可为1-5层。
- 模型总参数量:约7.4M(如图1所述)。
- 训练硬件:未说明。
- 推理细节:未提及特殊解码策略或温度、beam size等,因为任务是回归预测,而非生成。
- 正则化技巧:使用了Dropout,并在FFN中采用浅层设计以防止过拟合。
📊 实验结果
主要对比实验(表1): 论文在内部数据集和外部LIVE-SJTU数据集上对比了基线、SVR方法和多种深度学习模型。
| 类别 | 模型 | 内部数据集 | LIVE-SJTU |
|---|---|---|---|
| Rp ↑ | Rs ↑ | ||
| 基线 | Q-Random (wa=0.3, wv=0.7) | 0.84 | 0.86 |
| Q-Internal (wa=0.33, wv=0.67) | 0.83 | 0.86 | |
| Q-External (wa=0.23, wv=0.76) | 0.83 | 0.87 | |
| SVR | SVR-2F (Qa, Qv) | 0.86 | 0.84 |
| SVR-3F (+音频码率) | 0.89 | 0.88 | |
| SVR-7F (Qa + 6个VMAF特征) | 0.86 | 0.86 | |
| SVR-8F (+音频码率) | 0.90 | 0.89 | |
| 深度学习 | Simple AV-Fusion (无注意力) | 0.84 | 0.83 |
| CA AV-Fusion (仅交叉注意力) | 0.90 | 0.87 | |
| Recursive AV-FusionNet | 0.90 | 0.89 | |
| Attentive AV-FusionNet (本文) | 0.97 | 0.96 |
关键结论:
- 内部数据集:Attentive AV-FusionNet取得了最佳性能(Rp=0.97, RMSE=0.22),显著优于所有基线(包括最优的SVR-8F:Rp=0.90)和其他深度学习变体(如CA AV-Fusion:Rp=0.90)。这证明了其混合注意力融合的有效性。
- 外部数据集(LIVE-SJTU):该模型在相关性指标(Rp=0.92, Rs=0.92)上达到了与最强基线(Recursive AV-FusionNet: Rp=0.92)持平的水平,但在RMSE上(0.44)略差于Recursive AV-FusionNet(0.39)和SVR-8F(0.86)。这表明模型具有较好的泛化能力,但在不同数据分布上优势不明显。
- 消融分析:
- 去掉所有注意力(Simple AV-Fusion)后性能大幅下降,证实注意力机制是关键。
- 仅加入交叉注意力(CA AV-Fusion)后性能已接近Recursive AV-FusionNet,再加入自注意力(完整模型)在内部数据集上带来巨大提升,但在外部数据集上收益有限。
- 表2(超参数搜索空间)显示,模型在层数、头数、学习率等多个维度进行了系统调优。
模态重要性估计结果:
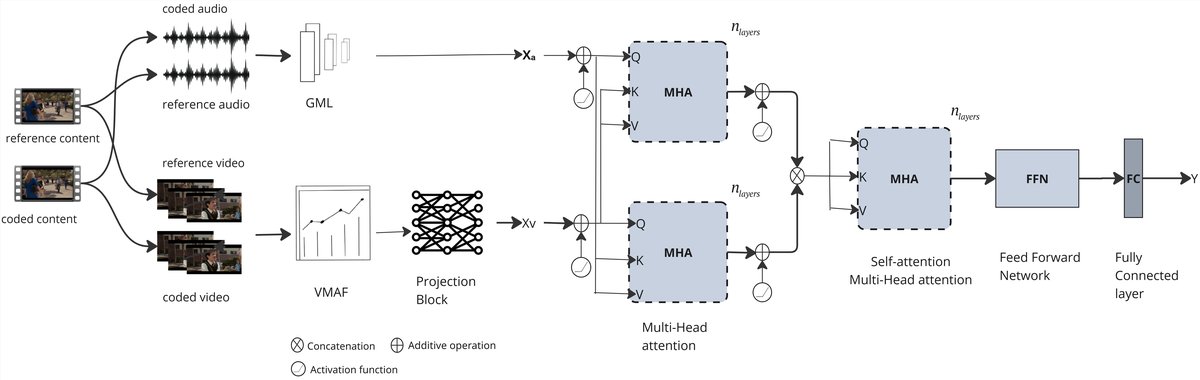 图2:模型对不同内容类型预测的模态重要性。(a)音频主导型内容(包含密集瞬态的音频挑战性场景),模型分配更高权重给音频。(b)视频主导型内容(视觉动态、音乐简单),模型分配更高权重给视频。这直观展示了模型“内容感知”的特性。
图2:模型对不同内容类型预测的模态重要性。(a)音频主导型内容(包含密集瞬态的音频挑战性场景),模型分配更高权重给音频。(b)视频主导型内容(视觉动态、音乐简单),模型分配更高权重给视频。这直观展示了模型“内容感知”的特性。
⚖️ 评分理由
- 学术质量(6.0/7):
- 创新性(2.0/2.5):提出混合特征与混合注意力融合的框架,特别是双向交叉注意力与自注意力的组合应用在音视频质量评估中较为新颖。模态重要性估计器也是一个有价值的贡献。
- 技术正确性(2.0/2.5):方法基于成熟的Transformer注意力机制,特征对齐、融合逻辑清晰,损失函数设计合理。
- 实验充分性(1.5/2.0):进行了充分的对比实验(基线、SVR、消融),并利用两个数据集验证。但外部数据集上的提升不够突出,且缺少对“内部数据集”数据多样性的深入分析。
- 证据可信度(0.5/0.5):实验设置明确,指标(Rp, Rs, RMSE)标准,表格数据完整。主要弱点是依赖私有数据和特征,限制了外部验证。
- 选题价值(1.5/2):
- 前沿性(0.7/1):音视频联合质量评估是多媒体和流媒体领域的持续热点,使用注意力机制进行多模态融合是当前主流技术方向。
- 潜在影响与应用空间(0.8/1):模型直接服务于流媒体优化(如Netflix、YouTube等),具有明确的工业应用价值。其可解释���模态重要性估计为自适应码率分配提供了新思路。
- 开源与复现加成(-0.5/1):
- 论文未提供代码、预训练模型或内部数据集。
- 训练和测试的许多细节(如GML和VMAF特征提取的具体代码、数据增强、硬件环境)未公开。
- 虽然给出了超参数搜索空间,但最终最佳配置的完整清单(包括所有层数)未明确列出,给完全复现带来困难。