📄 ATOM: Adaptive Token-Level Optimal Transport Mixup for Speech Translation
#语音翻译 #对比学习 #多任务学习 #数据增强 #低资源
🔥 8.0/10 | 前25% | #语音翻译 | #对比学习 | #多任务学习 #数据增强
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.2 | 置信度 高
👥 作者与机构
- 第一作者:Jialing Wang(1. 教育部民族语言智能分析与安全治理重点实验室,中央民族大学;2. 香港中文大学(深圳))
- 通讯作者:Yue Zhao(教育部民族语言智能分析与安全治理重点实验室,中央民族大学)
- 作者列表:Jialing Wang(教育部民族语言智能分析与安全治理重点实验室,中央民族大学;香港中文大学(深圳))、Yue Zhao(教育部民族语言智能分析与安全治理重点实验室,中央民族大学)、Yuhao Zhang(香港中文大学(深圳))、Haizhou Li(香港中文大学(深圳))
💡 毒舌点评
亮点:ATOM框架巧妙地将最优传输的“硬”对齐、对比学习的“精”对齐以及语义相似度引导的自适应“软”混合结合成一个闭环,在低资源藏汉翻译任务上实现了显著的BLEU提升(+2.43),证明了其在弥合模态鸿沟方面的实际效力。
短板:论文对于关键的自适应混合公式(3)解释不够清晰(p、σ、γ未明确定义),且消融实验设计较为简单,未能深入剖析各组件协同工作的具体机制和边界条件,使得方法的“自适应”智能性略显黑盒。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:所使用的MuST-C和TIBMD@MUC是公开或部分公开的学术数据集,论文中说明了其来源。
- Demo:未提供在线演示。
- 复现材料:论文给出了详细的实验设置、超参数配置(学习率、批大小、优化器、模型维度等)、评估指标和数据集统计,为复现提供了基础信息,但未提供完整的训练代码或配置文件。
- 论文中引用的开源项目:明确基于 FAIRSEQ 工具包进行实现;使用了 HuBERT 作为语音编码器;使用了 SentencePiece 进行分词;使用了 sacreBLEU 进行评估。
📌 核心摘要
- 要解决的问题:端到端语音翻译(ST)面临训练数据稀缺和源语言语音与目标语言文本之间存在巨大模态鸿沟的双重挑战。
- 方法核心:提出ATOM框架,结合最优传输(OT)进行初始跨模态对齐,利用基于InfoNCE的对比学习迭代优化对齐质量,并设计一种基于语义相似度的自适应模态混合策略,将对齐后的语音和文本token在特征层面进行融合。
- 与已有方法相比新在哪里:相比于之前使用固定概率进行模态混合或仅使用单一对齐机制的方法,ATOM实现了“对齐(OT)-精化(对比学习)-融合(自适应混合)”的闭环,且融合权重由token间的语义相似度动态决定,更具灵活性和语义感知能力。
- 主要实验结果:在MuST-C英德(En-De)和TIBMD藏汉(Ti-Zh)数据集上进行评估。
- 主实验结果对比表
模型 En-De BLEU Ti-Zh BLEU XSTNET 20.61 11.56 STEMM 20.82 13.61 ConST 20.77 14.66 CMOT 20.84 14.87 OTST 20.88 13.90 ATOM 22.48 17.30 - 消融实验(En-De):移除对比学习(-LCTR)导致BLEU下降0.34;同时移除对比学习和自适应混合(-CTR -Adaptive Mixup)导致BLEU下降1.64,回落至CMOT的水平(20.84)。
- 不同对齐损失对比(En-De):CTR损失(21.18)优于OT损失(20.75)和CAR损失(20.09)。
- 主要结论:ATOM在两个任务上均取得最优结果,相比最强基线CMOT分别提升1.64(En-De)和2.43(Ti-Zh)个BLEU点,在资源更稀缺的Ti-Zh任务上提升尤为显著。
- 主实验结果对比表
- 实际意义:为低资源语音翻译提供了一种有效的技术方案,通过挖掘多任务学习中平行文本数据的潜力来提升语音模型性能,对促进欠发达语言的跨语言交流有实用价值。
- 主要局限性:1)实验对比的基线均为2022-2024年的经典方法,未与更新的、可能基于大规模预训练语音-语言模型的SOTA进行对比;2)自适应混合策略的参数设置(p, τ, γ)依赖经验,缺乏更深入的分析或自动化调参机制;3)论文未公开代码,限制了可复现性和直接应用。
🏗️ 模型架构
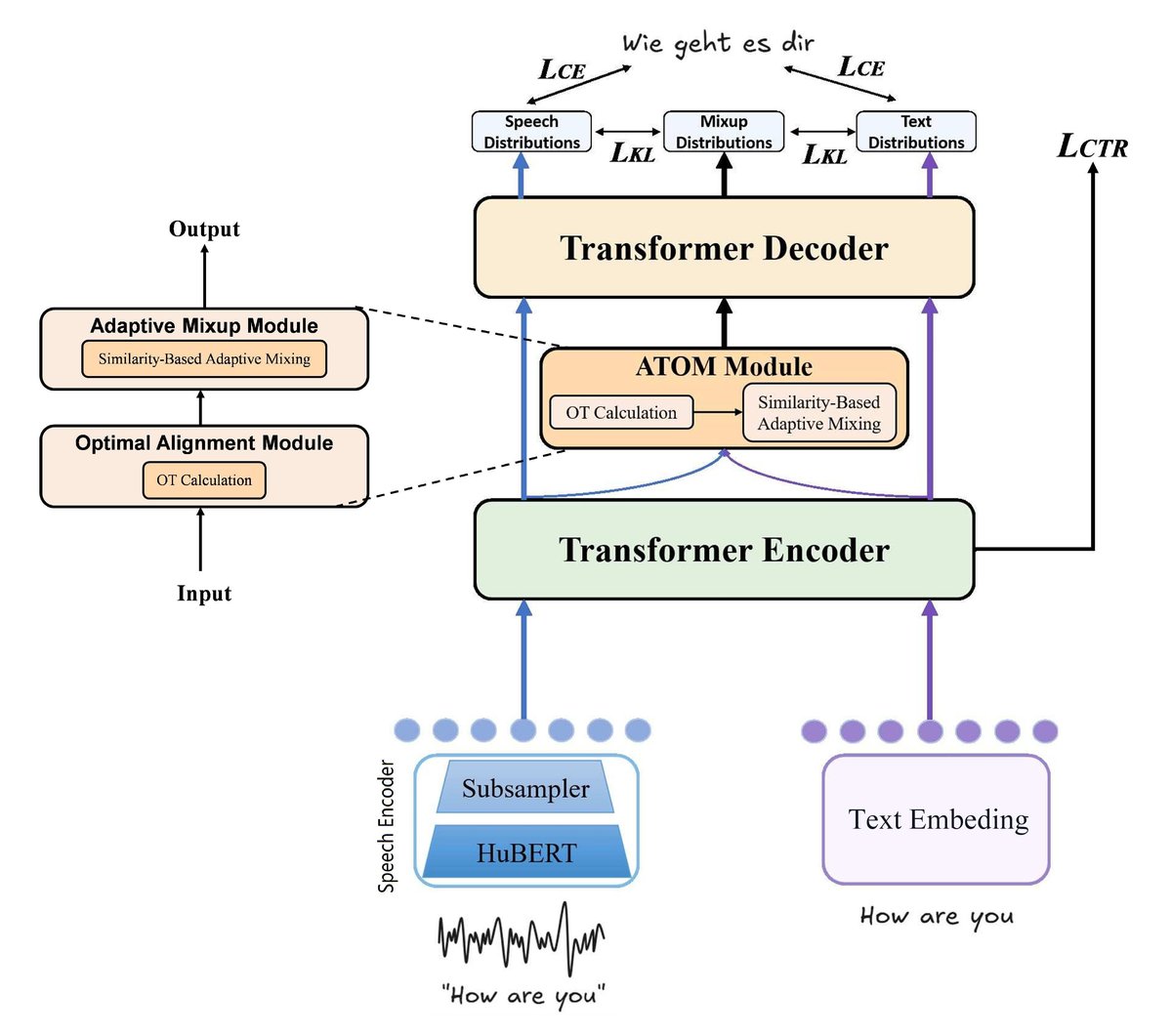
ATOM是一个端到端的语音翻译模型,其整体架构如上图所示,主要由五个协同工作的组件构成:
- Speech Encoder(语音编码器):使用预训练的HuBERT模型作为特征提取器。其后接一个由两层卷积层构成的下采样器(Sub-sampler),作用是降低语音特征的时间维度,以提高后续Transformer处理的效率并减少计算量。
- Text Embedding(文本嵌入层):将输入的源语言文本(在训练时使用)转换为连续向量表示。它与语音编码器并行工作,使得模型能够在训练时学习语音和文本之间的跨模态对齐。
- Translation Encoder(翻译编码器):由多层Transformer编码器构成。它接收来自语音编码器或文本嵌入层的特征,并通过多头自注意力机制捕捉更深层次的语义表示,同时保留模态特有的信息。
- ATOM模块:这是本文的核心创新模块,嵌入在编码器和解码器之间。它执行两个关键操作:
- 跨模态对齐与精化:首先使用最优传输(OT)算法初步对齐语音token和文本token序列。然后,基于OT得到的对齐关系,利用对比学习(InfoNCE损失)来“拉近”配对token的表示,“推远”非配对token的表示,从而精化对齐质量。
- 自适应模态混合:在获得精化的token对齐关系后,对于每一对语音token
h_s_i和文本tokenh_x_ai,计算它们的余弦相似度。该相似度被用于生成一个混合权重α_i,最终的混合表示h'_i是语音和文本特征的加权和。权重由相似度动态决定,实现了基于语义的、平滑的跨模态特征融合。
- Translation Decoder(翻译解码器):由多层Transformer解码器构成。它通过交叉注意力机制关注编码器的输出(可以是原始语音、文本或经ATOM混合后的表示),并自回归地生成目标语言的文本序列。
数据流:训练时,语音和文本数据并行输入。经过各自的编码器后,在ATOM模块中,基于OT和对比学习找到的对应关系被用于计算混合特征。解码器同时被要求基于纯语音、纯文本和混合特征进行预测,并通过多任务损失进行优化。推理时,仅使用语音输入,经过编码器和ATOM模块处理后,由解码器生成翻译结果。
💡 核心创新点
最优传输与对比学习的迭代式对齐框架:
- 是什么:将OT用于发现语义上的初始软对齐,再用对比学习作为判别器,通过最大化对齐对相似度、最小化非对齐对相似度来优化表示空间。
- 之前局限:CMOT等方法直接使用OT得到的对应关系进行特征替换,是“一次性”的,未对表示本身进行优化以强化对齐信号。
- 如何起作用与收益:形成了一个“发现对齐-强化表示-再发现更好对齐”的闭环。对比学习使得模型学习到更具判别性的跨模态特征表示,从而提升了对齐的准确性和鲁棒性。
基于语义相似度的自适应模态混合策略:
- 是什么:在确定模态融合权重时,不使用固定的混合比例(如CMOT),而是根据每个对齐的语音-文本token对的实际余弦相似度动态计算权重。
- 之前局限:固定概率混合忽略了token间语义对齐质量的差异,可能将不匹配的特征强行混合,引入噪声。
- 如何起作用与收益:对于语义匹配度高的token对,赋予文本特征更高的权重,因为此时文本特征是高质量的监督信号;对于匹配度低的,则保留更多原始语音特征。这使得特征融合更智能、更精细,提升了表示的语义一致性。
多任务学习与KL散度正则化的协同训练:
- 是什么:在总损失中,除了标准的ST和MT交叉熵损失外,还引入了对称的KL散度散度项,约束模型在混合输入、纯语音输入和纯文本输入下产生的目标词预测分布保持一致。
- 之前局限:标准的多任务学习可能只优化各自的损失,不同输入模态下的预测可能不一致。
- 如何起作用与收益:KL正则化强制模型对不同来源但语义等价的信息产生一致的理解,增强了跨模态表征的对齐和泛化能力,是一种有效的隐式正则化手段。
🔬 细节详述
- 训练数据:
- ST数据:MuST-C En-De(47.06小时)和TIBMD@MUC Ti-Zh(57.52小时)。
- MT数据(用于预训练):En-De使用WMT数据;Ti-Zh使用TIBMD@MUC中的平行句对。
- 预处理:使用SentencePiece进行分词,词汇量10k,源语言和目标语言共享。过滤了长度比大于1.5的句对。音频为16kHz单声道,16-bit。
- 损失函数:
总损失
L_total:λ_ST L_ST + λ_MT L_MT + λ_KL (L_KL(M,S) + L_KL(M,T)) + λ_CTRL * L_CTRL。L_ST和L_MT:标准的自回归交叉熵损失。L_CTRL:对比学习损失(InfoNCE),公式见论文(2)。L_KL:对称KL散度散度,用于正则化三种输入条件(混合M,语音S,文本T)下的输出分布。- 权重:
λ_ST和λ_MT在论文中未明确给出数值,可能默认为1。λ_CTRL= 0.9,λ_KL= 2.0。
- 训练策略:
- 两阶段训练:第一阶段,用MT数据预训练文本嵌入层和联合Transformer编码器;第二阶段,用ST数据微调整个模型。
- 优化器:Adam。
- 学习率:MT预训练阶段
2e-3;ST微调阶段1e-4,其中HuBERT编码器使用1e-5,且其CNN层被冻结。 - Batch Size:1600万音频帧。
- 训练步数:60,000步。
- 关键超参数:模型有6层Transformer编码器和6层解码器,隐藏维度512,注意力头数8。ATOM模块超参数:
p=0.2,τ=0.6,γ=10,T=0.05(对比学习温度)。 - 训练硬件:Nvidia GeForce RTX 4090 GPUs(数量未说明)。
- 推理细节:使用束搜索(Beam Search),
beam_size = 8。评估指标为sacreBLEU。 - 正则化技巧:冻结预训练HuBERT的CNN层;在损失中加入KL散度正则化项。
📊 实验结果
主要实验对比:论文在表2中详细对比了ATOM与多个基线模型在两个数据集上的性能。
- 主要结果表(同核心摘要)
模型 En-De BLEU Ti-Zh BLEU XSTNET 20.61 11.56 STEMM 20.82 13.61 ConST 20.77 14.66 CMOT 20.84 14.87 OTST 20.88 13.90 Adaptive-OTST 20.91 14.00 ATOM 22.48 17.30 - 分析:ATOM在所有基线中取得最佳成绩。与同属OT家族的CMOT相比,在En-De上提升1.64,在Ti-Zh上提升2.43,优势显著。
- 主要结果表(同核心摘要)
消融实验(表3):
实验配置 En-De BLEU 与完整ATOM的差值(∆) I. ATOM (完整) 22.48 - II. 去掉对比学习 (-LCTR) 22.14 -0.34 III. 同时去掉对比学习和自适应混合 (-CTR -Adaptive Mixup) 20.84 -1.64 - 分析:移除对比学习导致性能小幅下降,说明其对表示精化的贡献。同时移除对比学习和自适应混合后,性能大幅下降至CMOT的水平(20.84),这定量证明了两个创新组件协同作用的整体提升效果,也表明ATOM的提升主要来源于这两个模块的组合,而非其他。
对齐损失函数对比(表4):
损失函数 BLEU分数 CTR Loss (本文使用) 21.18 OT Loss 20.75 CAR Loss 20.09 - 分析:此实验在En-De上测试了不同对齐机制的影响。基于对比学习的CTR损失优于直接的OT距离损失和基于注意力的CAR损失,验证了对比学习在构建判别性跨模态表示方面的有效性。
超参数敏感性分析(图2):
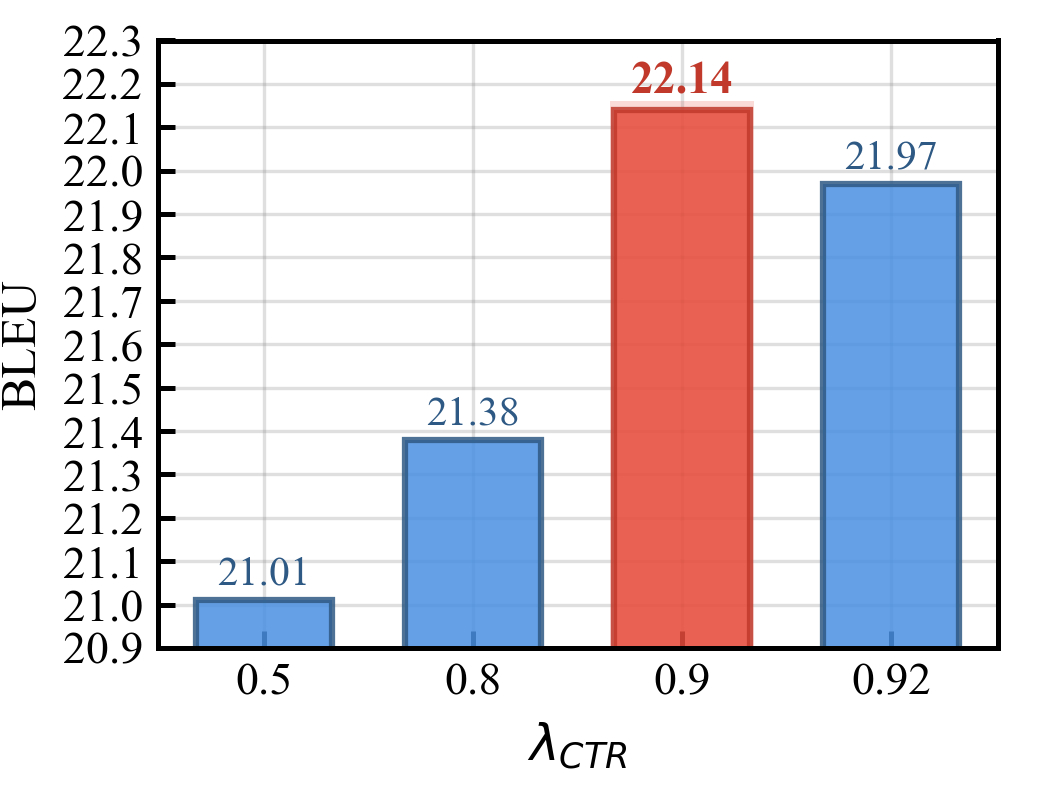
- 分析:该图展示了对比学习损失权重
λ_CTRL对性能的影响。当λ_CTRL = 0.9时取得最优性能。过低(0.5)则梯度信号不足,过高(0.92)则可能过度优化对比学习目标而损害翻译任务本身。这为该超参数的选择提供了依据。
- 分析:该图展示了对比学习损失权重
⚖️ 评分理由
- 学术质量:6.0/7 - 创新点明确且结合有巧思(OT+对比学习+自适应混合),形成了一个完整的框架。技术路线基本正确,实验设计了对比和消融,结果有说服力。扣分项在于:1) 部分方法细节(如混合策略公式中的符号)未完全厘清;2) 与更新或更强大的基线(如基于Whisper等大规模预训练模型的方法)对比缺失;3) 消融实验虽证明了组件有效,但未深入探究其相互作用的机理。
- 选题价值:1.5/2 - 语音翻译是刚需,尤其对低资源语言。本文聚焦此问题,并在低资源藏汉翻译上取得显著提升,应用价值明确,与音频/语音领域研究者高度相关。
- 开源与复现加成:0.5/1 - 论文提供了非常详细的实验设置(框架、超参数、数据、优化器),可复现性基础好。但严重扣分的是,未提供代码、模型权重或复现脚本,这大幅增加了复现门槛。