📄 Assessing the Impact of Speaker Identity in Speech Spoofing Detection
#音频深度伪造检测 #多任务学习 #自监督学习 #说话人识别
🔥 8.0/10 | 前25% | #音频深度伪造检测 | #多任务学习 | #自监督学习 #说话人识别
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Anh-Tuan DAO(法国阿维尼翁大学计算机实验室, Laboratoire d’informatique d’Avignon)
- 通讯作者:未说明(论文未明确标注,但联系邮箱来自Nicholas Evans)
- 作者列表:Anh-Tuan DAO(法国阿维尼翁大学计算机实验室)、Driss Matrouf(法国阿维尼翁大学计算机实验室)、Nicholas Evans(法国EURECOM, Sophia Antipolis)
💡 毒舌点评
这篇论文的亮点在于它设计了一个巧妙的“可开关”框架(SInMT),能统一评估两种关于说话人信息的对立假设,并且实验设计扎实,在四个数据集上验证了“去除说话人信息”对检测特定高级伪造攻击(A11)的显著效果。然而,其短板在于整体创新属于对现有SSL+多任务框架的特定应用组合优化,且论文未探讨将两种模式(aware/invariant)动态融合的潜力,结论部分稍显仓促。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用的是公开的ASVspoof 5, ASVspoof 2021, ITW和MUSAN数据集,论文中未提供新的或私有数据集。
- Demo:未提及。
- 复现材料:论文给出了详细的训练细节、配置(如优化器、学习率、Batch Size、Epochs、硬件)和关键超参数(α, λ),以及数据增强流程,为复现实验提供了必要信息。
- 论文中引用的开源项目:引用了XLSR预训练模型([10])。
📌 核心摘要
- 要解决什么问题: 研究在基于自监督学习(SSL)的语音伪造检测系统中,说话人身份信息究竟是应该被利用还是被抑制,以及这种信息对模型性能有何具体影响。
- 方法核心是什么: 提出一个名为说话人不变多任务(SInMT)的统一框架。该框架使用预训练的XLSR作为特征提取器,后接两个结构相同的MHFA分类头。核心创新在于通过控制一个梯度反转层(GRL)的开启/关闭,使模型能在“说话人感知(MHFA-spk)”和“说话人不变(MHFA-IVspk)”两种模式间灵活切换。
- 与已有方法相比新在哪里: 以往工作多单独评估多任务学习或不变性学习,SInMT框架首次在单一SSL骨干网络中实现了二者的统一与直接对比。它允许研究者系统评估在相同数据和特征基础上,引入或抑制说话人信息带来的不同效果。
- 主要实验结果如何: 在四个评估集(ITW, ASVspoof 5 评估集, ASVspoof 2021 LA和DF隐藏子集)上,说话人不变模式(MHFA-IVspk) 取得了最佳的整体性能。与基线MHFA模型相比,其平均EER(等错误率)降低了17.2%(从7.41%降至6.13%)。对于最具挑战性的攻击类型A11,MHFA-IVspk实现了48%的相对EER降低(从17.02%降至8.76%)。说话人感知模式(MHFA-spk)也优于基线。
- 主要实验结果表格(论文中Table 1):
模型 ITW EER(%) ASV5 eval EER(%) ASV21LA EER(%) ASV21DF EER(%) 平均EER(%) AASIST 7.03 5.54 13.66 9.60 8.95 Conformer 5.69 3.85 12.49 10.40 8.10 MHFA 4.31 4.64 12.14 8.58 7.41 MHFA-spk 3.76 5.29 8.67 8.41 6.53 MHFA-IVspk 3.58 4.98 8.41 7.57 6.13
- 主要实验结果表格(论文中Table 1):
- 实际意义是什么: 为设计更鲁棒的语音伪造检测系统提供了新的思路和实证依据。研究表明,在SSL特征基础上,主动抑制说话人特定信息可能使模型更专注于伪造痕迹本身,从而提升对高级、高仿真伪造攻击的检测能力,尤其是在跨数据集、跨说话人的场景下。
- 主要局限性是什么: 论文指出,虽然MHFA-IVspk整体更优,但其在“见过说话人”的闭集场景下可能不如MHFA-spk,这一点因评估集均为开集(说话人与训练集不重叠)而未能验证。此外,框架的通用性受限于其特定的特征提取器(XLSR)和后端分类器(MHFA)。
🏗️ 模型架构
SInMT框架的整体架构如下:
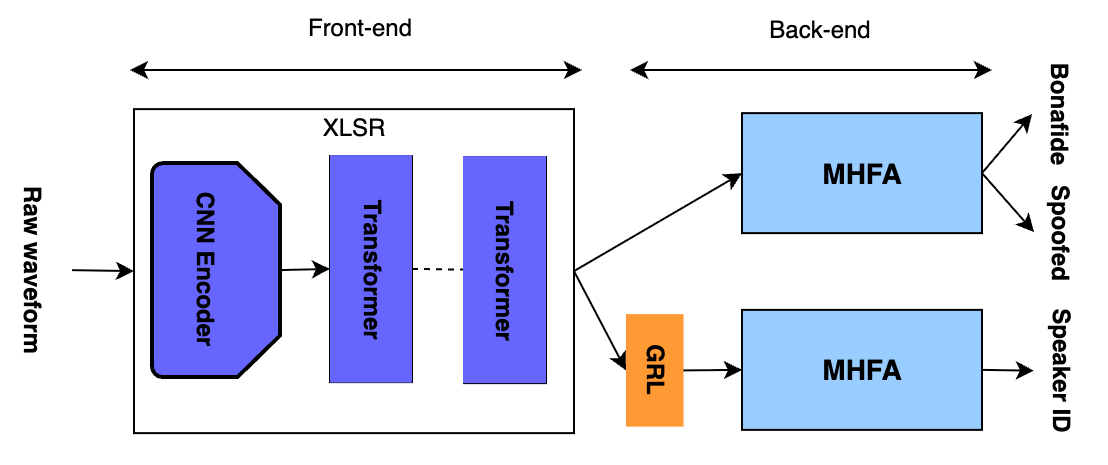 图1: SInMT模型架构示意图
图1: SInMT模型架构示意图
该架构主要由以下组件构成:
- 特征提取器(Feature Extractor):采用预训练的XLSR(Cross-lingual Speech Representation)模型。其输入是原始音频波形,内部包含一个CNN编码器和一个Transformer上下文网络,最终输出一个序列化的、上下文感知的帧级嵌入表示(o_{1:T})。这部分负责从音频中提取丰富的、与任务相关的声学特征。
- 伪造检测分类头(Spoofing Classifier Head):一个MHFA(Multi-Head Factorized Attention)网络。它直接以特征提取器输出的嵌入序列作为输入,最终输出一个二分类预测结果(真实或伪造)。
- 说话人识别分类头(Speaker Classifier Head):另一个结构与伪造检测头完全相同的MHFA网络。它接收来自特征提取器(经过GRL)的嵌入序列,输出对说话人ID(从1到D,D为训练说话人数量)的预测。
- 梯度反转层(GRL):这是实现“说话人不变”训练的关键组件。在前向传播时,GRL等同于恒等映射,不对数据做任何改变。但在反向传播时,它会将从说话人分类头传回的梯度乘以一个负数超参数(-λ)。其作用是鼓励特征提取器生成“欺骗”说话人分类器的特征,即让这些特征尽可能不包含能够区分不同说话人的信息,从而学习到说话人不变的表示。
数据流与模式切换:
- 说话人感知模式(MHFA-spk):此时GRL的λ设为-1(相当于禁用梯度反转)。特征提取器同时接收来自伪造损失和说话人损失的梯度,目标是同时优化这两个任务,利用说话人信息来辅助伪造检测。
- 说话人不变模式(MHFA-IVspk):此时GRL的λ设为1(启用梯度反转)。训练目标变为最小化伪造检测损失,同时最大化说话人识别损失(通过反转梯度实现)。这迫使特征提取器学习对说话人身份不变的特征。
- 通过简单地改变λ的值(启用/禁用GRL),同一套网络参数就可以在这两种截然不同的训练策略间切换。
💡 核心创新点
- 提出SInMT统一框架:这是本文最核心的贡献。它提供了一个灵活的架构,能够在一个统一的SSL骨干网络和后端分类器下,通过控制GRL来无缝切换“利用说话人信息”和“抑制说话人信息”两种策略,从而直接、公平地对比其效果。
- 在SSL特征上系统评估多任务学习:以往多任务学习在伪造检测中的应用多基于特定架构(如ResNet)。本文将多任务学习与强大的自监督学习(SSL)特征(XLSR)相结合,并在后端使用MHFA分类器,系统评估了这种组合的有效性,证实了即使在强大的SSL特征基础上,说话人信息的处理方式依然至关重要。
- 实证发现“去除”策略对特定攻击的有效性:实验不仅证实了“处理说话人信息”(无论利用还是抑制)比完全忽略要好,更具体地揭示了说话人不变(MHFA-IVspk)模式对于检测那些说话人相似度极高、自然度极强的高级伪造攻击(如A10, A11)具有显著优势。这为应对未来更逼真的伪造技术提供了方向。
🔬 细节详述
- 训练数据:
- 数据集:使用ASVspoof 5挑战赛的训练集,包含约180,000条语音样本,来自400名说话人。
- 数据增强:采用常见的数据增强策略。使用MUSAN语料库(包含音乐、语音、噪声)和真实房间脉冲响应(RIR)数据库。每条训练样本会随机应用四种增强之一:混响、语音干扰、音乐干扰或噪声干扰。
- 预处理:训练时,将输入语音随机截取为4秒的片段。评估时,使用完整的音频片段。
- 损失函数:
- 主要使用加权交叉熵损失。总损失由伪造检测损失(Ls)和说话人识别损失(Ld)组成,通过超参数α进行平衡(公式1)。
- 具体损失定义见原文公式。
- 训练策略:
- 优化器:使用Adam优化器。
- 学习率:固定为 10^{-6}。
- 批次大小(Batch Size):32。
- 训练轮数(Epochs):30。
- 训练硬件:使用NVIDIA A100 GPU。
- 两阶段训练:首先训练MHFA-spk模型(λ=-1),然后以其作为初始化点,训练MHFA-IVspk模型(λ=1)。
- 关键超参数:
- 平衡因子 α = 0.1。
- 说话人不变损失中的梯度缩放因子 λ 在MHFA-spk模式中为 -1,在MHFA-IVspk模式中为 1。
- 推理细节:评估时,模型处理完整音频片段,输出每个样本的伪造/真实概率,用于计算EER。
📊 实验结果
- 主要基准与数据集:
- 训练集:ASVspoof 5训练集。
- 评估集:四个数据集,涵盖不同场景和攻击类型。
- ITW (In-the-Wild):真实世界录制的语音。
- ASVspoof 5 评估集。
- ASVspoof 2021 LA 隐藏子集:逻辑访问攻击(LA)。
- ASVspoof 2021 DF 隐藏子集:深度伪造攻击(DF)。
- 评估指标:EER(等错误率),数值越低越好。
- 主要结果对比:
- 基线模型对比(Table 1):在三个基线模型(AASIST, Conformer, MHFA)中,MHFA表现最佳。SInMT框架的两个变体(MHFA-spk和MHFA-IVspk)都进一步超越了最佳基线MHFA。
- 与最强基线的差距:说话人不变模型(MHFA-IVspk)将平均EER从MHFA的7.41%降低到了6.13%,相对降低17.2%。在最具挑战性的ASVspoof 2021 LA数据集上,相对降低达30.7%。
- 细分攻击类型分析(Table 2):
- 针对ASVspoof 2021 LA数据集的13种攻击类型(A07-A19)进行了详细分析。SInMT框架的两个变体在所有攻击类型上均优于MHFA基线。
- 关键发现:在最具挑战性的攻击类型A10和A11上,提升最为显著。MHFA-IVspk模型将A11的EER从17.02%降至8.76%,相对降低48%。
- 可视化证据(图2):
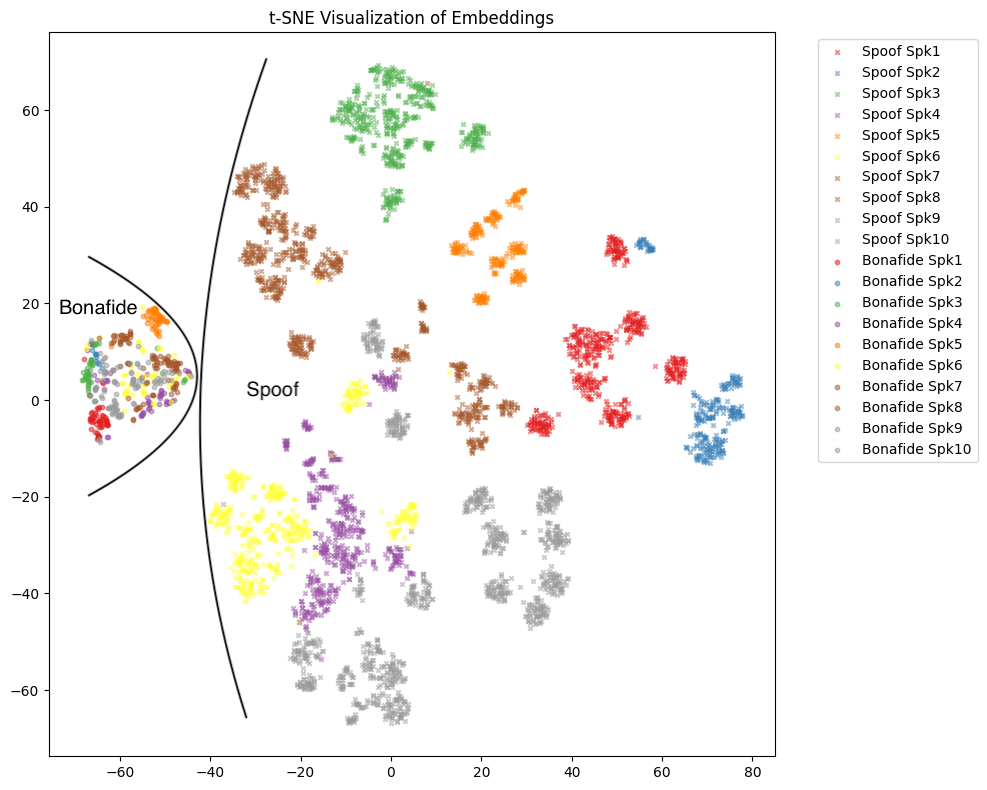 图2: MHFA, MHFA-spk, MHFA-IVspk模型嵌入的t-SNE可视化对比(10个说话人样本)
图2: MHFA, MHFA-spk, MHFA-IVspk模型嵌入的t-SNE可视化对比(10个说话人样本)- MHFA:嵌入空间显示出部分按说话人分离的倾向,但聚类紧密,表明保留了部分说话人信息。
- MHFA-spk:嵌入空间显示出非常清晰的按说话人ID聚类,每个说话人形成独立的小簇,表明该模型显著强化了说话人特定信息的表示。
- MHFA-IVspk:嵌入空间完全没有显示出说话人聚类的结构,验证了梯度反转层(GRL)成功地抑制了特征中的说话人判别性信息。
- 关键消融实验:本文的实验设计本身即构成了核心消融:通过对比MHFA(无额外任务)、MHFA-spk(有辅助任务,无对抗)和MHFA-IVspk(有辅助任务,有对抗),清晰地展示了“有无处理说话人信息”以及“如何处理说话人信息”对性能的影响。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:提出了一个新颖且设计巧妙的统一框架(SInMT),实现了对两种对立策略的直接对比,这是对现有工作方法论上的改进。
- 技术正确性:技术路线清晰,基于成熟的SSL、MTL和GRL技术,实现正确,没有明显的方法论错误。
- 实验充分性:实验设计全面,使用了四个公开评估集,并进行了攻击类型细分��析和可视化,结果有统计意义。对比了多个基线,验证了框架的有效性。
- 证据可信度:所有结论都有实验数据和图表支撑,结果可复现(基于公开数据集和标准设置)。
- 不足:创新点属于对现有技术的组合与特定领域应用,而非提出全新的原理或架构。此外,对于两种模式在何种数据分布下更优的分析还停留在假设阶段。
- 选题价值:1.5/2
- 前沿性:语音伪造检测是音频安全领域的前沿热点,如何利用或消除身份信息是其中一个重要且具体的技术问题。
- 潜在影响:研究结论有助于指导实际伪造检测系统的设计,特别是应对高仿真攻击时,考虑抑制说话人信息可能是一个有效方向。
- 应用空间:直接服务于生物识别安全、内容审核等实际应用。
- 读者相关性:对于从事语音安全、反欺诈、自监督学习应用的音频/语音领域读者具有较高的相关性。
- 开源与复现加成:0.3/1
- 论文未提及代码、模型权重或任何开源计划。
- 但论文提供了较为详细的训练配置(优化器、学习率、batch size、epochs、硬件)、数据增强策略以及超参数设置(α, λ),这使得研究结果在理论上是可复现的。扣分主要因为关键资源的缺失。