📄 ARCHI-TTS: A Flow-Matching-Based Text-to-Speech Model with Self-Supervised Semantic Aligner and Accelerated Inference
#语音合成 #流匹配 #自监督学习 #零样本 #多语言
🔥 8.0/10 | 前25% | #语音合成 | #流匹配 | #自监督学习 #零样本
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Chunyat Wu(香港中文大学)
- 通讯作者:未说明(论文中未明确标注通讯作者)
- 作者列表:Chunyat Wu, Jiajun Deng, Zhengxi Liu, Zheqi Dai, Haolin He, Qiuqiang Kong(所有作者均来自香港中文大学,香港,中国)
💡 毒舌点评
亮点:这篇论文最大的“工程巧思”在于发现了非自回归流式解码器中,条件编码器的输出在不同去噪步之间可以安全地重复使用,从而在几乎不损失质量的前提下将推理速度提升了数倍(RTF从0.31降至0.09),这个发现极具实用价值。短板:虽然“语义对齐器”被设计为核心,但论文对其内部学习到的对齐质量缺乏直接、可视化的分析(例如对齐矩阵图),其对合成语音“时序稳定性”的贡献更多是间接推断,说服力可以更强。
🔗 开源详情
- 代码:论文明确指出“code are publicly available”,并提供了项目主页链接 https://archimickey.github.io/architts ,但论文PDF中未给出具体的GitHub等代码仓库链接。
- 模型权重:论文中未提及是否公开模型权重。
- 数据集:使用的是公开数据集(Emilia, LibriHeavy, LibriTTS)。
- Demo:项目主页上应包含音频样本(Audio samples)。
- 复现材料:提供了详细的模型架构描述、超参数设置(如层数、学习率、批次大小、损失函数权重)、训练硬件和时长等关键信息,有利于复现。
- 论文中引用的开源项目:主要依赖和参考了Emilia数据集、ConvNeXt V2(用于文本编码)、Stable Audio的VAE架构、以及用于提取说话人嵌入的CAM++模型。
- 总结:论文有明确的开源计划和部分复现信息,但开源信息(特别是代码链接和模型权重)在提供的PDF中不完整。
📌 核心摘要
- 问题:当前基于扩散/流匹配的非自回归TTS系统面临两大挑战:1)文本与语音之间复杂、灵活的对齐关系难以有效建模;2)迭代去噪过程带来高昂的计算开销,推理速度慢。
- 方法:本文提出ARCHI-TTS,一种非自回归架构。核心方法包括:a) 语义对齐器:通过一个Transformer编码器,将文本特征与长度等于目标语音帧数的、可学习的“掩码嵌入”序列进行交互,从而端到端地学习出对齐的语义表征,无需显式时长标注。b) 高效推理策略:在条件流匹配的解码器中,将负责编码文本、说话人、参考音频等条件的“条件编码器”部分的输出,在多个去噪步骤间共享(重用),避免了每一步都重新计算,从而大幅提升推理效率。
- 创新:与E2-TTS、F5-TTS等通过填充字符来实现隐式对齐的方法不同,ARCHI-TTS显式设计了一个对齐模块。与需要额外蒸馏训练(如DMDSpeech)的加速方法不同,本文的加速策略是训练无关的,直接来自对模型架构特性的洞察。
- 主要实验结果:
- 在LibriSpeech-PC test-clean上,WER为1.98%,SSIM为0.70,RTF为0.21(单卡3090)。
- 在SeedTTS test-en上,WER为1.47%,SSIM为0.68。
- 在SeedTTS test-zh上,WER为1.42%,SSIM为0.70。
- 使用75%共享比例时,在NFE=32下,WER仍保持1.98%,RTF降至0.09。
- MOS主观评测中,其自然度和说话人相似度与F5-TTS和CosyVoice2处于竞争水平。
| 模型 | 参数量 | 训练数据 | WER(%)↓ | SSIM↑ | RTF↓ | 测试集 |
|---|---|---|---|---|---|---|
| F5-TTS | 336M | 100K Multi. | 2.42 | 0.66 | 0.31 | LibriSpeech-PC test-clean |
| ARCHI-TTS | 289M | 100K Multi. | 1.98 | 0.70 | 0.21 | LibriSpeech-PC test-clean |
| F5-TTS | - | - | 1.83 | 0.67 | - | SeedTTS test-en |
| ARCHI-TTS | - | - | 1.47 | 0.68 | - | SeedTTS test-en |
| DiTAR | - | - | 1.02 | 0.75 | - | SeedTTS test-zh |
| ARCHI-TTS | - | - | 1.42 | 0.70 | - | SeedTTS test-zh |
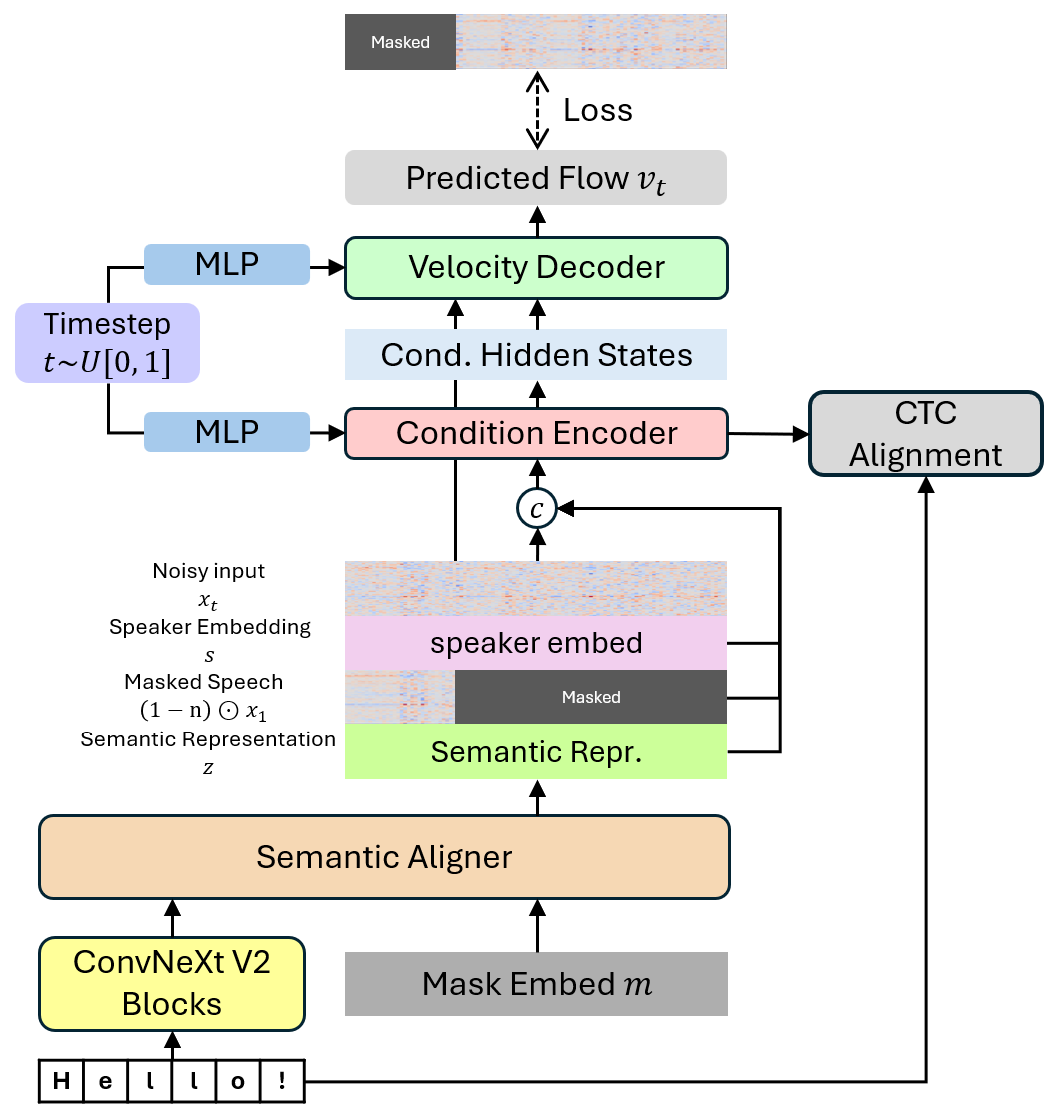 (图1:ARCHI-TTS整体架构概览图,展示了语义对齐器、条件编码器、速度解码器及数据流。)
(图1:ARCHI-TTS整体架构概览图,展示了语义对齐器、条件编码器、速度解码器及数据流。)
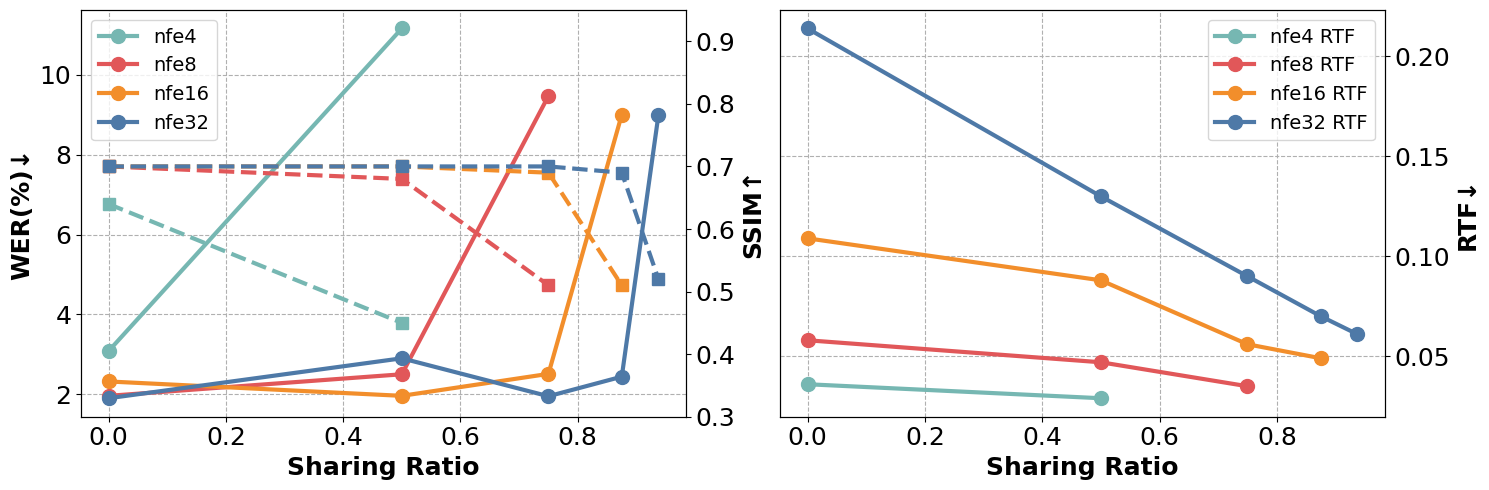 (图2:WER和SSIM(左)、RTF(右)随条件编码器输出共享比例的变化曲线。)
(图2:WER和SSIM(左)、RTF(右)随条件编码器输出共享比例的变化曲线。)
- 实际意义:本文提供了一个高效、高质量的非自回归TTS新方案。其“低令牌率”表征和“训练无关的推理加速”策略,对于降低TTS系统的部署成本(计算、延迟)具有直接的工程价值,推动了非自回归模型在实际应用中的可行性。
- 主要局限性:a) 对语义对齐器的具体作用机制(如内部对齐动态)缺乏深入可视化分析。b) 尽管在自动指标上领先,但在主观MOS评测中,其优势并不显著,甚至在某些维度上略低于对比模型。c) 论文未与最新的非自回归模型DiTAR在所有指标上进行全面对比(如SeedTTS test-zh的WER,DiTAR的1.02优于ARCHI-TTS的1.42)。
🏗️ 模型架构
ARCHI-TTS是一个完全非自回归的语音合成模型,旨在根据输入文本和一段简短的音频提示生成目标语音。其架构(如图1所示)主要包含两个核心部分:语义对齐器和基于流匹配的解码器。
完整输入输出流程:
- 输入:目标文本序列(字符/拼音)、参考音频片段、参考音频转录文本、说话人嵌入(通过外部模型提取)。
- 输出:目标语音的波形。
主要组件:
- 语音潜在表示压缩器(VAE):一个独立训练的变分自编码器,将24kHz语音信号编码为连续的、低令牌率(12.5Hz)的潜在表示。这相比传统的梅尔频谱图(50-100Hz)大大减少了时序冗余,是后续高效生成的基础。VAE在训练前已固定。
- 语义对齐器(Semantic Aligner):
- 功能:接收文本特征序列和目标语音长度信息,输出与语音潜在表示在时序上对齐的语义特征序列(
z)。 - 内部结构:基于Transformer编码器。文本输入经过ConvNeXt V2块编码后,与一个长度等于目标语音帧数(
N)的、由同一个可学习掩码嵌入(m)复制而成的序列,一同输入Transformer。这个复制的掩码序列充当了“均匀的时间画布”,Transformer通过自注意力机制,将文本语义信息聚合并分配到这个时间画布的每一个位置上,从而生成语义特征z。关键设计在于,这种机制解耦了文本令牌长度和语音帧长度,特别适用于文本令牌可能短于语音帧的低令牌率场景。
- 功能:接收文本特征序列和目标语音长度信息,输出与语音潜在表示在时序上对齐的语义特征序列(
- 条件编码器(Condition Encoder):
- 功能:接收语义特征
z、说话人嵌入s(全局嵌入,复制到与语音等长)和音频提示xref(对目标语音潜在表示进行随机掩码后的片段),生成用于指导生成过程的条件隐状态h。 - 内部结构:由多层(论文中为18层)DiT(Diffusion Transformer)块构成。它整合所有条件信息,为速度解码器提供丰富的上下文。
- 功能:接收语义特征
- 速度解码器(Velocity Decoder):
- 功能:预测去噪过程
t时刻的向量场速度vt。 - 内部结构:由较少层数(论文中为4层)的DiT块和最终的投影层组成。它接收噪声潜在表示
xt和条件隐状态h。关键设计:h不是与xt简单拼接,而是作为全局条件,通过与时间步嵌入相加后注入到每个DiT块中。
- 功能:预测去噪过程
- 整体数据流:文本 -> [语义对齐器] -> 对齐的语义特征
z。同时,z、说话人嵌入、音频提示 -> [条件编码器] -> 条件隐状态h。在训练或推理的每一步,噪声xt和h-> [速度解码器] -> 预测速度vt,用于更新xt。
关键设计选择:
- 低令牌率VAE:动机是解决梅尔频谱图时间冗余高、需要额外声码器的问题,实现端到端合成并降低生成序列长度。
- 自监督语义对齐器:动机是避免使用显式、刚性的对齐信息(如音素时长),通过端到端学习实现更灵活、自然的对齐。
- 条件编码器与速度解码器分离:动机是实现推理加速。条件编码器的计算相对复杂且与输入条件相关,而速度解码器处理的是与当前去噪步相关的噪声。将二者分离后,条件编码器的输出
h可以跨去噪步骤共享,这是本文核心的加速技巧。
💡 核心创新点
自监督语义对齐器:
- 内容:提出一种新的对齐模块,通过Transformer将文本特征与目标长度的可学习掩码序列交互,端到端学习文本到语音的对齐表示。
- 局限:之前方法要么依赖显式时长标注(如Voicebox),要么使用简单的填充策略(如E2-TTS, F5-TTS),后者可能无法建模复杂的对齐关系。
- 作用:提供了一个灵活的框架来生成与语音帧对齐的语义条件,无需外部对齐工具或标注,并解决了文本长度与语音长度不匹配的问题。
- 收益:实验表明,该模块有助于提升文本保真度(WER)和训练收敛速度。
基于条件编码器输出重用的推理加速:
- 内容:在条件流匹配的推理过程中,将条件编码器在时间步
t=0(或初始步)计算得到的条件隐状态h存储起来,并在后续的K个去噪步骤中重复使用,而不是每一步都重新计算。共享比例(sharing ratio)为1 - K/N(N为总NFE步数)。 - 局限:之前加速扩散/流式模型的方法多依赖模型蒸馏(如DMD, E1-TTS),这需要训练一个额外的教师模型或在训练循环中增加前向传播,增加了训练复杂度和开销。
- 作用:利用了分离架构的特性,在推理阶段绕过了计算量最大的组件(条件编码器),直接复用其结果来指导速度解码器。
- 收益:实现了“训练无关”的推理加速。如图2所示,在75%共享比例下,RTF可从0.21降至0.09,同时WER和SSIM仅有微小下降,实现了效率与质量的极佳平衡。
- 内容:在条件流匹配的推理过程中,将条件编码器在时间步
低令牌率VAE表征与CTC辅助损失:
- 内容:采用12.5Hz的VAE潜在表示替代高帧率梅尔谱,并在条件编码器上引入CTC损失以增强其内部表示与文本的对齐。
- 局限:高令牌率表征是许多TTS系统的默认选择。
- 作用:前者从源头上减少了生成序列的长度,是后续高效生成的基石。后者通过多任务学习,显式监督条件编码器学习更好的文本-语音对齐表示。
- 收益:使得模型在极低的RTF下运行(0.21),同时CTC损失在消融实验中被证明能加速收敛并保持性能。
🔬 细节详述
- 训练数据:
- 主数据集:Emilia,10万小时多语言(覆盖不同口音和风格)配对语音和文本数据。
- 消融实验数据:5万小时英语LibriHeavy和600小时英语LibriTTS。
- 预处理:语音信号均为24kHz。VAE潜在表示在训练TTS模型前提取。
- 损失函数:
- 条件流匹配损失
L_CFM(公式2):预测速度vt与真实OT路径速度vt之间的MSE损失,是主要生成损失。 - 速度方向损失
L_DIR:使用余弦相似度,确保预测速度方向与真实方向一致,提升训练稳定性。 - CTC对齐损失
L_CTC(公式3):将条件编码器第i层DiT的隐状态输入CTC解码器,预测文本序列,损失为负对数似然。超参数η = 0.1。 - 总损失
L(公式4):L = L_CFM + L_DIR + η * L_CTC。
- 条件流匹配损失
- 训练策略:
- 优化器:AdamW,峰值学习率
1e-4。 - 学习率调度:线性预热1000步,然后线性衰减。
- 批次大小:3750个潜在帧(约0.67小时音频)。
- 训练时长/步数:80万次更新(800k updates)。
- 梯度裁剪:设为1.0。
- EMA:使用指数移动平均模型进行采样。
- 音频掩码训练:训练时,随机遮蔽70%-100%的音频潜在表示,进行填充训练。
- 分类器引导训练:以0.3的概率同时丢弃音频提示和说话人嵌入,以0.2的概率丢弃所有条件,用于无条件/有条件引导训练。
- 优化器:AdamW,峰值学习率
- 关键超参数:
- 模型大小:总计289M参数。条件编码器18层DiT,速度解码器4层DiT。
- 语义对齐器:6层Transformer块。
- VAE:输出12.5Hz连续潜在表示。
- CFG强度
ω:默认4.0。 - NFE步数:默认32步。
- 时间偏移(timeshift):3.0。
- 码本大小:消融实验中测试了码本大小加倍的影响。
- 训练硬件:8张RTX 5090 32GB GPU,训练4天。
- 推理细节:
- 求解器:欧拉(Euler)求解器。
- 零样本合成时长估计:根据参考音频的令牌帧率(
Tref/Lref)乘以目标文本长度(Lgen)来估算目标语音长度。 - 语义条件构建:将参考文本和目标文本拼接,一次性通过语义对齐器提取语义特征。
- 加速采样:通过共享条件编码器输出
h实现,共享比例可调。
- 正则化/稳定训练技巧:使用EMA模型采样、logit-normal时间步采样(聚焦训练于生成轨迹的起始和结束点)、梯度裁剪。
📊 实验结果
主要基准测试结果
| 模型 | 参数量 | 训练数据 | WER(%)↓ | SSIM↑ | RTF↓ | 测试集 |
|---|---|---|---|---|---|---|
| Ground Truth | - | - | 2.23 | 0.69 | - | LibriSpeech-PC test-clean |
| Vocos Resynthesized | - | - | 2.32 | 0.66 | - | LibriSpeech-PC test-clean |
| CosyVoice | ~300M | 170K Multi. | 3.59 | 0.66 | 0.92 | LibriSpeech-PC test-clean |
| FireRedTTS | ~580M | 248K Multi. | 2.69 | 0.47 | 0.84 | LibriSpeech-PC test-clean |
| MaskGCT | ~1.1B | 100K Multi. | 2.72 | 0.69 | - | LibriSpeech-PC test-clean |
| E2-TTS | 333M | 100K Multi. | 2.95 | 0.69 | 0.68 | LibriSpeech-PC test-clean |
| F5-TTS | 336M | 100K Multi. | 2.42 | 0.66 | 0.31 | LibriSpeech-PC test-clean |
| DiTAR | ~600M | 100K Multi. | 2.39 | 0.67 | - | LibriSpeech-PC test-clean |
| ARCHI-TTS | 289M | 100K Multi. | 1.98 | 0.70 | 0.21 | LibriSpeech-PC test-clean |
| 模型 | Seed-EN WER(%)↓ | Seed-EN SSIM↑ | Seed-ZH WER(%)↓ | Seed-ZH SSIM↑ |
|---|---|---|---|---|
| Ground Truth | 2.06 | 0.73 | 1.254 | 0.75 |
| Vocos Resynthesized | 2.09 | 0.70 | 1.27 | 0.72 |
| CosyVoice 2 | 2.57 | 0.65 | 1.45 | 0.75 |
| FireRedTTS | 3.82 | 0.46 | 1.51 | 0.63 |
| MaskGCT | 2.623 | 0.717 | 2.273 | 0.774 |
| Seed-TTSDiT | 1.733 | 0.790 | 1.178 | 0.809 |
| E2-TTS | 2.19 | 0.71 | 1.97 | 0.73 |
| F5-TTS | 1.83 | 0.67 | 1.56 | 0.76 |
| DiTAR | 1.69 | 0.74 | 1.02 | 0.75 |
| ARCHI-TTS | 1.47 | 0.68 | 1.42 | 0.70 |
关键结论:
- 领先性能:ARCHI-TTS在LibriSpeech-PC test-clean上取得了最低的WER(1.98%)和最高的SSIM(0.70),且RTF(0.21)显著优于F5-TTS(0.31)等模型。在SeedTTS英文测试集上,WER(1.47%)也优于F5-TTS(1.83%)。在中文测试集上,WER(1.42%)虽略逊于DiTAR(1.02%),但仍具有很强的竞争力。
- 高效率:得益于低令牌率VAE和推理加速,其RTF表现突出。使用75%共享比例后,RTF可降至0.09。
主观评测(MOS)结果
| 模型 | NMOS (自然度) | SMOS (相似度) | CMOS (偏好 vs GT) |
|---|---|---|---|
| Ground Truth | 3.72 | 3.59 | 0 |
| F5-TTS | 3.62 | 3.54 | -0.03 |
| CosyVoice2 | 3.57 | 3.32 | 0.10 |
| ARCHI-TTS | 3.53 | 3.48 | 0.09 |
关键结论:ARCHI-TTS在自然度(NMOS 3.53)和说话人相似度(SMOS 3.48)上具有竞争力,与F5-TTS和CosyVoice2处于同一水平,但未显示出显著优势。其CMOS得分(0.09)表明,评审者认为其合成质量略低于真实语音。
消融实验结果
| 模型配置 | 训练数据集 | WER(%)↓ | SSIM↑ |
|---|---|---|---|
| ARCHI-TTS Small | LibriTTS | 2.88 | 0.55 |
| - w/o spk embed | LibriTTS | 2.50 | 0.49 |
| ARCHI-TTS (Base) | LibriHeavy | 2.16 | 0.71 |
| - w/o spk embed | LibriHeavy | 2.48 | 0.62 |
| - w/ sem. VQ | LibriHeavy | 2.48 | 0.71 |
| - codebook size×2 | LibriHeavy | 2.15 | 0.71 |
关键结论:
- 说话人嵌入的作用:对于低令牌率VAE表示,说话人嵌入对提升SSIM至关重要。移除后SSIM显著下降。在基线模型上,移除说话人嵌入导致SSIM从0.71降至0.62。
- 语义向量量化(VQ):对语义特征进行VQ能略微提升SSIM(0.71),但WER略有上升。将码本大小加倍后,WER恢复到与原始模型相当的水平(2.15% vs 2.16%),说明VQ正则化是有益的。
推理加速效果
(图2:WER(实线,左轴)、SSIM(虚线,左轴)和RTF(右轴)随条件编码器输出共享比例的变化。)
关键结论:随着共享比例增加,RTF显著下降(推理速度大幅提升),WER和SSIM仅有轻微、缓慢的下降。在NFE=32、共享比例75%时,WER仍保持在1.98%,SSIM为0.70,RTF降至0.09,证明了该策略的有效性和鲁棒性。
⚖️ 评分理由
- 学术质量(6.2/7):
- 创新性(+):语义对齐器和推理加速策略都是新颖的、有洞察力的设计。
- 技术正确性(+):基于成熟的流式模型框架,设计合理,消融实验验证了各部分作用。
- 实验充分性(+):数据规模大,基准测试全面(含多语言),对比了众多SOTA模型,进行了深入的消融研究。
- 证据可信度(+):实验设置透明,结果具体。
- 扣分项:对于核心组件“语义对齐器”的分析深度稍显不足,未展示其内部学习到的对齐模式;在部分基准(如SeedTTS-zh)上,并非绝对最优。因此,给予6.2分,表示其是一篇扎实、有重要贡献的优秀论文,但距离无瑕疵的“里程碑”工作尚有一步之遥。
- 选题价值(1.5/2):
- 语音合成是AI语音领域的核心任务,非自回归方法是重要趋势。本文聚焦于提升效率和改进对齐,具有高前沿性和强实用价值。给予1.5分,因其对推动TTS技术向更高效、更实用的方向发展有明确贡献。
- 开源与复现加成(0.3/1):
- 论文承诺开源代码并提供了样本页面,且给出了相当详细的训练配置,这为复现提供了良好基础。但未给出明确的代码仓库链接和模型权重发布计划,因此给予0.3分的中等加成,表示有开源意愿且信息较充分,但尚不完整。