📄 Arbitrarily Settable Frame Rate Neural Speech Codec with Content Adaptive Variable Length Segmentation
#音频生成 #神经语音编解码 #可变帧率 #语音表示学习
✅ 7.0/10 | 前25% | #音频生成 | #神经语音编解码 | #可变帧率 #语音表示学习
学术质量 6.0/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yukun Qian (哈尔滨工业大学深圳)
- 通讯作者:Mingjiang Wang (哈尔滨工业大学深圳,
mjwang@hit.edu.cn) - 作者列表:Yukun Qian (哈尔滨工业大学深圳)、Wenjie Zhang (哈尔滨工业大学深圳)、Xuyi Zhuang (哈尔滨工业大学深圳)、Shiyun Xu (哈尔滨工业大学深圳)、Lianyu Zhou (哈尔滨工业大学深圳)、Mingjiang Wang (哈尔滨工业大学深圳,通讯作者)
💡 毒舌点评
亮点在于它巧妙地用Viterbi算法将“帧率”这个连续可调参数转化为了一个全局优化问题,这在工程上非常优雅,且实验表明在低帧率场景下确实比固定帧率的SOTA更抗造。短板则是这篇论文的“任意帧率”听起来很酷,但Viterbi算法的动态规划在超长音频或实时流式场景下的计算开销和时延问题被轻描淡写了,这可能限制其在某些实际部署中的应用。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用公开的LibriSpeech和LibriLight数据集。
- Demo:未提及在线演示。
- 复现材料:提供了详细的训练配置(数据集、裁剪长度、帧率采样范围、优化器、学习率、硬件),但未提供检查点或更详细的超参数(如RVQ码本数量、Transformer具体配置)。
- 论文中引用的开源项目:明确基于并比较了DAC [8] 和VRVQ [22] 的架构。
📌 核心摘要
- 要解决什么问题:当前主流的基于残差向量量化(RVQ)的神经语音编解码器采用固定帧率,导致在处理静音或简单音频段时效率低下,造成序列冗余,无法根据内容重要性动态分配码率。
- 方法核心是什么:提出了内容自适应变长分段(CAVLS)框架。该框架首先用帧评分编码器为每个潜在表示帧打分,然后根据目标帧率,利用Viterbi动态规划算法将相似的相邻帧合并为可变长度的段,实现可变帧率(VFR)。段表示经过RVQ量化后,由带有FiLM调制的上下文段解码器利用局部上下文信息重建原始帧序列。
- 与已有方法相比新在哪里:与固定帧率(CFR)的DAC、VRVQ等模型相比,CAVLS首次在基于RVQ的语音编解码器中实现了真正意义上由内容驱动的可变帧率,允许用户指定任意目标帧率,而非仅改变码本数量(VRVQ)或多尺度网络(TFC)。
- 主要实验结果如何:在匹配比特率(图2a)和匹配帧率(图2b)的对比中,CAVLS在高帧率/高码率时与基线(DAC, VRVQ)持平,但在低帧率/低码率时显著优于基线。例如,在1 kbps码率下,CAVLS的UTMOS分数仅比高码率时下降0.2,而VRVQ已跌破3分。消融实验(表1)显示移除段编码器对性能影响最大。
- 实际意义是什么:为神经语音编解码提供了更高的灵活性和效率,尤其适用于带宽受限的场景(如12.5 Hz的超低帧率传输)。其变帧率表示也可能为下游的语音语言模型提供更紧凑、信息密度更高的离散单元。
- 主要局限性是什么:论文中未讨论Viterbi算法在极长音频序列上的计算复杂度和实时流式应用的可行性;STE在训练中的稳定性影响未深入分析;生成的可变帧率表示是否完全兼容现有依赖固定帧率的下游任务(如某些语音合成模型)也未探讨。
🏗️ 模型架构
CAVLS建立在标准的RVQ-GAN编解码框架之上,核心创新在于编码和解码阶段引入了动态分段机制。
整体流程:
- 编码阶段:输入音频
x首先通过主编码器E(CNN骨干)得到固定帧率的潜在表示序列z ∈ R^{T×D}。此序列被送入帧评分编码器E_s,该编码器共享主编码器的早期层E_1,并额外接一个线性层和Softplus激活,为每帧输出一个非负重要性分数s ∈ R^T,分数越高表示该帧信息量越大。 - 动态分段:在给定目标帧率(对应目标段数
T_FR)和分数s的情况下,动态帧合并编码器执行以下步骤:- 帧合并:将分数归一化并缩放,使其和为
T_FR -1,然后计算累积和。通过将累积和域划分为单位区间,确定一个概率分布P(公式3),表示每帧属于各个段的可能性。然后,利用Viterbi算法在约束(段连续、标签单调、起点终点固定)下求解全局最优的帧到段的分配序列K(公式5、6)。这一步骤是核心,它确保了分段在全局上最优且满足目标段数。 - 段编码:根据最优分配
K,将帧特征z重排为变长的段序列。段编码器Segment Encoder(一个Transformer)对每个段内的帧特征进行上下文建模,然后通过均值池化和线性投影得到固定的段级表示S_r ∈ R^{T_FR×D}。
- 帧合并:将分数归一化并缩放,使其和为
- 量化:对段表示
S_r应用标准的RVQ,得到量化后的段表示S_rq。 - 解码阶段:上下文段解码器
Context Segment Decoder负责从量化段表示恢复出原始帧级表示。对于每个段,它:- 生成基于段内位置的正弦编码查询
x_p。 - 利用一个轻量级MLP将量化段表示
S_rq映射为FiLM参数γ, β,对查询进行调制:x_s = x_p ⊙(1 + γ) + β,使查询能感知段内容。 - 从原始潜在序列
z中收集该段前后各W个帧作为上下文S_c。 - 通过交叉注意力模块(查询
x_s,键值S_c)重建该段对应的帧级潜在表示,最后根据段长度SL截断并拼接得到完整的重建序列z_r ∈ R^{T×D}。 - 最后由解码器
D将z_r重建为波形。
- 生成基于段内位置的正弦编码查询
关键设计选择及其动机:
- Viterbi算法:动机是确保分段是全局最优的、连续的,且恰好产生用户指定的段数(帧率),这是实现“任意设定帧率”的技术保障。
- STE(直通估计器):因为Viterbi算法产生的分配矩阵
M是离散不可导的,为允许梯度回传以训练帧评分编码器E_s,采用了STE技巧。 - FiLM调制:动机是让解码器的查询能够根据不同段的量化内容(
S_rq)自适应调整,而不是仅依赖固定的位置编码,从而增强重建质量。 - 局部上下文窗口:动机是利用音频的局部相关性,通过交叉注意力让解码器在重建一个段时能参考其邻近段的信息,平滑过渡。
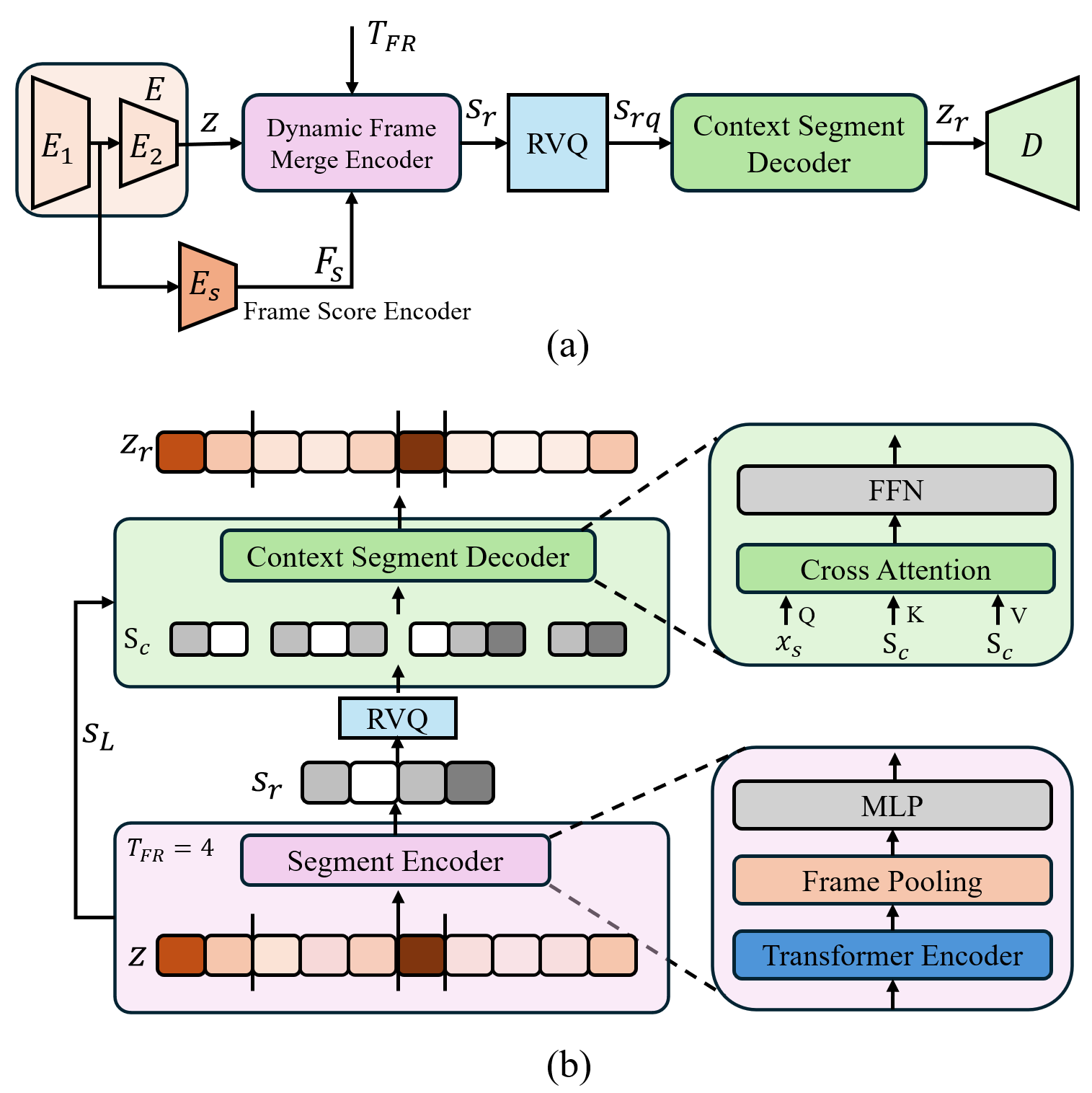 图1展示了CAVLS的架构概览。(a)整体架构图清晰地展示了帧评分编码器、动态帧合并编码器(包含帧合并和段编码器)和上下文段解码器的串联关系。(b)变长分段生成与重建过程图则更直观地展示了分数驱动的分段、量化以及利用上下文解码的步骤。
图1展示了CAVLS的架构概览。(a)整体架构图清晰地展示了帧评分编码器、动态帧合并编码器(包含帧合并和段编码器)和上下文段解码器的串联关系。(b)变长分段生成与重建过程图则更直观地展示了分数驱动的分段、量化以及利用上下文解码的步骤。
💡 核心创新点
提出内容自适应变长分段(CAVLS)框架:
- 局限:以往RVQ语音编解码器几乎都采用固定帧率,无法根据音频内容的复杂度动态调整时间分辨率。
- 如何起作用:通过帧评分编码器评估每帧重要性,并用Viterbi算法根据分数动态合并帧,使静音等简单部分用长段表示,复杂语音部分用短段表示。
- 收益:实现了可变帧率(VFR),在相同码率下(如1kbps)能保留更多关键信息,显著提升低码率下的重建质量(UTMOS指标优势明显)。
引入Viterbi算法进行全局最优分段:
- 局限:简单基于阈值的贪婪合并可能导致次优分割。
- 如何起作用:将分段问题建模为在约束(单调性、端点)下最大化对数似然的序列标注问题,利用动态规划求解。
- 收益:保证了分段在全局上的最优性,并且严格满足用户指定的目标帧率,这是实现“任意可设帧率”的数学基础。
设计帧评分编码器(Frame Score Encoder):
- 局限:先前工作(如TFC)通过多尺度卷积隐式适应不同时间尺度,缺乏显式的、内容驱动的帧重要性评估。
- 如何起作用:共享编码器主干,通过一个带Softplus激活的轻量级头为每帧输出一个标量分数。
- 收益:为动态分段提供了显式的、可学习的指导信号。
提出上下文段解码器,结合FiLM调制与跨注意力:
- 局限:从变长的段表示重建帧级序列是一个挑战,简单的上采样可能导致细节丢失。
- 如何起作用:解码器查询通过FiLM受段表示调制,使其内容感知;然后利用交叉注意力在局部上下文窗口内聚合信息进行重建。
- 收益:有效融合了段级全局信息和帧级局部上下文,提升了重建的保真度和自然度。
实现真正意义上的任意可设帧率:
- 局限:之前的“变码率”(VBR)方法如VRVQ仅通过改变每帧的码本数量来改变码率,但帧率(时间采样率)依然是固定的。
- 如何起作用:CAVLS的架构设计允许在推理时输入任意整数
T_FR作为目标段数,从而设定任意帧率。 - 收益:为编解码系统提供了极大的灵活性,用户可根据带宽或计算资源需求自由权衡质量与效率。
🔬 细节详述
- 训练数据:使用LibriSpeech和LibriLight的Small与Medium子集,共计约7000小时无标签16kHz音频。训练时随机裁剪2秒片段。测试集包含1500条语音。
- 损失函数:
L_rec:MSE损失,监督解码的潜在表示z_r匹配编码器输出z。L_spa:方差正则化损失−var(s),惩罚过于平滑的分数分布,鼓励模型区分重要和次要帧。L_D:对抗损失,来自RVQ-GAN框架。- 总生成器损失:
L_g = L_rec + L_spa + L_D。论文未说明各损失项的权重。
- 训练策略:
- 优化器:AdamW。
- 学习率:初始学习率
1 × 10^{-4},使用指数衰减调度。 - Batch Size:每GPU 8,4卡训练,全局batch size为32。
- 训练时长:未明确说明总步数或epoch。
- 帧率采样:在每个训练步骤中,从
[0.2, 1.0]区间均匀随机采样一个目标帧率(相对于原始帧率),这使得模型能学习处理任意指定的帧率。
- 关键超参数:
- 下采样因子:320(对应原始帧率50 Hz)。
- CAVLS组件:使用一层的动态帧合并编码器,三层的上下文段解码器,上下文窗口
W=2。 - 模型大小:未明确说明编码器、解码器的具体层数、隐藏维度、参数量。
- RVQ参数(码本数量、大小等):未说明,可能沿用基础架构DAC的配置。
- 训练硬件:4块 NVIDIA A100 40GB GPU。
- 推理细节:解码是非自回归的,直接并行生成。温度、beam size等生成式解码策略不适用。
- 正则化技巧:分数分布的方差正则化
L_spa可视为一种正则化。STE用于梯度传播。
📊 实验结果
主要对比实验: 评估指标包括PESQ(信号保真度)、ViSQOL(感知质量)、UTMOS(自然度)和WER(可懂度,使用HuBERT-Large ASR)。
- 匹配比特率下的性能(图2a):
- 在高比特率(如18 kbps)时,CAVLS、DAC、VRVQ三者性能相当。
- 当比特率降至2 kbps和1 kbps时,CAVLS在所有指标上持续优于另外两种方法。
- 关键数字:在1 kbps下,CAVLS的UTMOS分数仅比高码率时下降约0.2,而VRVQ的UTMOS已低于3.0,DAC也明显下降。此时CAVLS的帧率低至12.5 Hz,但仍比工作在50 Hz下的DAC和VRVQ重建质量更好。
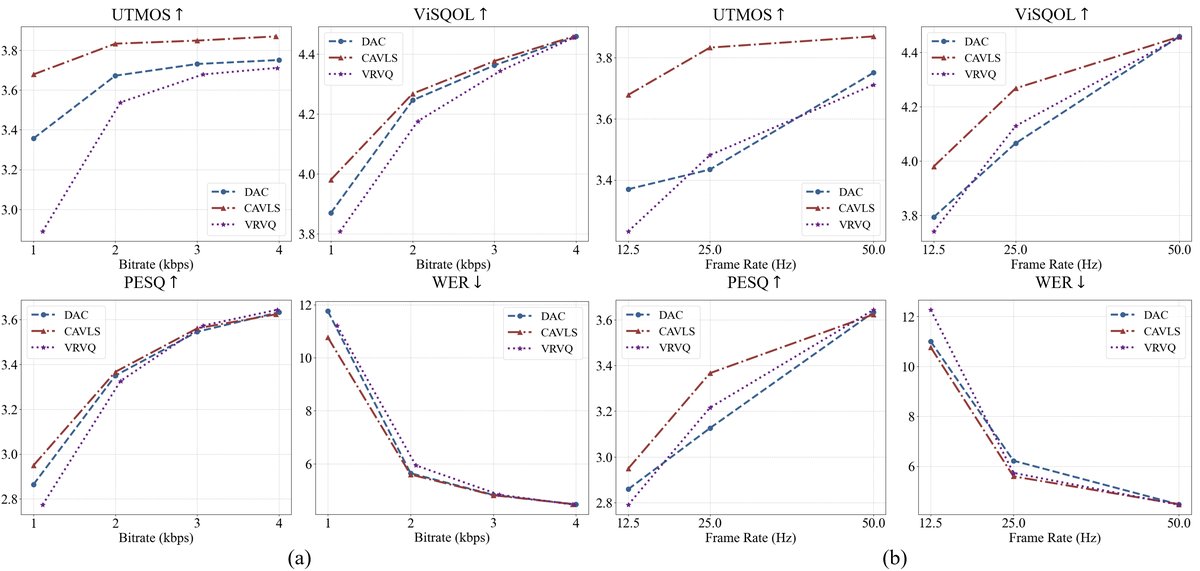 图2(a)显示了匹配比特率下的模型性能。横轴是比特率(kbps),纵轴是各评估指标。可以清晰看到在低比特率区间(左侧),CAVLS(蓝色线)的各项指标曲线均高于DAC(绿色)和VRVQ(橙色),证明其在低码率下的优势。
图2(a)显示了匹配比特率下的模型性能。横轴是比特率(kbps),纵轴是各评估指标。可以清晰看到在低比特率区间(左侧),CAVLS(蓝色线)的各项指标曲线均高于DAC(绿色)和VRVQ(橙色),证明其在低码率下的优势。
- 匹配帧率下的性能(图2b):
- 为了公平比较,将DAC和VRVQ重新训练,通过改变下采样因子实现25 Hz和12.5 Hz的帧率。
- 结果与匹配比特率测试一致:在高帧率时三者相当,帧率降低时CFR方法性能急剧下降,而CAVLS表现稳健。
- 关键数字:在12.5 Hz帧率下,CAVLS的UTMOS和ViSQOL分数显著高于同样工作在12.5 Hz的DAC和VRVQ。
图2(b)显示了匹配帧率下的性能。结论类似,在低帧率区间,CAVLS的优势同样明显。
消融实验: 在37.5 Hz帧率下进行,结果见表1。
表1:消融实验结果
| 方法 | UTMOS ↑ | ViSQOL ↑ | PESQ ↑ | WER ↓ |
|---|---|---|---|---|
| CAVLS | 3.85 | 4.38 | 3.56 | 4.82% |
| - 去掉段编码器(均值池化) | 3.79 | 4.18 | 3.30 | 6.33% |
| - 去掉FiLM调制 | 3.81 | 4.23 | 3.31 | 6.24% |
| - 去掉上下文窗口 | 3.76 | 4.19 | 3.28 | 5.90% |
- 关键发现:移除段编码器(用简单均值池化代替)导致性能下降最大,特别是WER从4.82%大幅增加到6.33%,证明段编码器学习段级表示是核心。去掉FiLM和上下文模块也带来稳定但较小的性能损失,验证了它们各自的价值。
⚖️ 评分理由
- 学术质量:6.0/7。论文提出了一种清晰且技术上合理的可变帧率神经语音编解码方法,创新点明确(CAVLS框架、Viterbi分段、帧评分器)。实验设计较为全面,包含了关键对比和消融研究,结果有说服力地支持了其在低帧率下的优势。扣分点在于:1) 对Viterbi算法实时性的讨论缺失;2) STE对训练稳定性的影响分析可以更深入;3) 部分超参数(如RVQ配置)未公开,略有遗憾。
- 选题价值:1.0/2。研究方向具有前沿性,解决了一个实际痛点(固定帧率效率问题)。对语音编解码、语音表示学习领域有直接价值,但应用范围相对聚焦于语音通信和生成模型前端,潜在影响力中等。
- 开源与复现加成:0.0/1。论文详细报告了训练数据、设置、超参数和硬件,提供了良好的文字复现基础。但因未提供代码、权重或演示,实际复现仍需大量工作,故给中性分。