📄 AR-BSNet: Towards Ultra-Low Complexity Autoregressive Target Speaker Extraction With Band-Split Modeling
#语音分离 #自回归模型 #时频分析 #实时处理 #基准测试
✅ 7.0/10 | 前25% | #语音分离 | #自回归模型 | #时频分析 #实时处理
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Fengyuan Hao(中国科学院声学研究所噪声与音频研究实验室;中国科学院大学)
- 通讯作者:Chengshi Zheng(中国科学院声学研究所噪声与音频研究实验室)
- 作者列表:Fengyuan Hao(中国科学院声学研究所噪声与音频研究实验室;中国科学院大学)、Andong Li(中国科学院声学研究所噪声与音频研究实验室;中国科学院大学)、Xiaodong Li(中国科学院声学研究所噪声与音频研究实验室;中国科学院大学)、Chengshi Zheng(中国科学院声学研究所噪声与音频研究实验室;中国科学院大学)
💡 毒舌点评
论文的亮点在于其明确的工程导向,通过一系列精巧的设计(如感知压缩、分带LSTM、自回归连接),将目标说话人提取模型的计算复杂度大幅压缩至适合边缘设备部署的水平(MACs降至0.91 G/s,RTF仅为0.044),同时保持了具有竞争力的性能。短板则在于,其追求极致效率的代价可能是牺牲了一部分模型容量和在非因果、高精度场景下的性能天花板,且论文并未提供代码,对社区复现和基于此工作的后续研究不够友好。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的WSJ0-2mix和WHAM!数据集,但论文未提供获取方式或数据集本身的链接。
- Demo:未提及。
- 复现材料:论文提供了非常详细的训练配置(损失函数、优化器、学习率、超参数等),具有较好的可复现信息基础。但未提供代码、配置文件或检查点。
- 引用的开源项目:论文未提及依赖的开源工具或模型。
- 总结:论文中未提及开源计划。
📌 核心摘要
- 问题:现有的因果目标说话人提取(TSE)方法虽然性能良好,但计算复杂度高,难以部署在资源受限的边缘设备上。
- 方法核心:提出AR-BSNet,一种超低复杂度的时频域自回归TSE模型。核心包括:a) 基于Mel滤波器组的感知压缩下采样;b) 分带循环建模(带内LSTM和带间BLSTM)以捕获时频模式;c) 引入自回归机制,利用前一帧的估计输出作为当前帧的辅助参考信息。
- 创新点:与现有方法相比,AR-BSNet创新性地将自回归框架、基于感知的频率维度压缩以及高效的分带循环处理相结合,在显著降低复杂度的同时,利用帧间依赖增强了提取效果。
- 主要实验结果:在WSJ0-2mix和WHAM!数据集上,AR-BSNet相比SOTA因果方法(如SpEx++, DSINet),在计算复杂度(MACs)上降低了约87.5%(从约7-11 G/s降至0.91 G/s),同时在SI-SDR、PESQ等指标上取得了可比或更优的性能。关键数据见下表:
| 数据集 | 方法 | 域 | 因果 | 参数量(M) | MACs(G/s) | PESQ | eSTOI(%) | SDR(dB) | SI-SDR(dB) |
|---|---|---|---|---|---|---|---|---|---|
| WSJ0-2mix | SpEx++ [10] | 时域 | 是 | 33.81 | 11.44 | 2.93 | 83.86 | 11.9 | 11.2 |
| DSINet [17] | 时频域 | 是 | 2.94 | 8.13 | 3.35 | 90.56 | 16.2 | 15.7 | |
| AR-BSNet | 时频域 | 是 | 0.32 | 0.91 | 3.13 | 87.09 | 13.8 | 13.3 | |
| WHAM! | SpEx+ [9] | 时域 | 是 | 11.14 | 3.76 | 2.04 | 60.01 | 6.1 | 5.2 |
| AR-BSNet | 时频域 | 是 | 0.32 | 0.91 | 2.26 | 57.74 | 5.7 | 4.9 | |
| -> w/ 60s enroll. | 时频域 | 是 | 0.32 | 0.91 | 2.30 | 58.71 | 6.1 | 5.4 |
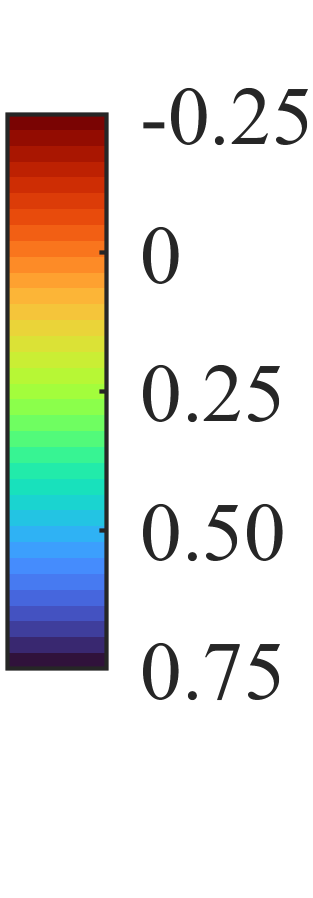 图4:在WSJ0-2mix测试集上,因果SpEx+与AR-BSNet的SI-SDRi改善值分布。AR-BSNet(蓝线)整体分布更靠右,表明其平均性能更好,且在高相似度说话人区域(红点)的错误更少。
图4:在WSJ0-2mix测试集上,因果SpEx+与AR-BSNet的SI-SDRi改善值分布。AR-BSNet(蓝线)整体分布更靠右,表明其平均性能更好,且在高相似度说话人区域(红点)的错误更少。
- 实际意义:成功地将TSE模型的计算开销降低了8倍以上,使其具备了在智能耳机、嵌入式设备等资源受限平台上实时运行的可能性,推动了该技术从实验室向实际应用的转化。
- 主要局限性:a) 在追求极致效率的过程中,部分性能指标(如WHAM!数据集上的SI-SDR)相比最强基线略有损失;b) 论文未提供代码,限制了社区的快速验证和二次开发;c) 模型的自回归特性可能引入一定的推理延迟,尽管文中强调了其流式友好性。
🏗️ 模型架构
AR-BSNet是一个基于时频域、采用编码器-提取器-解码器结构的端到端因果模型。整体架构如图2所示。
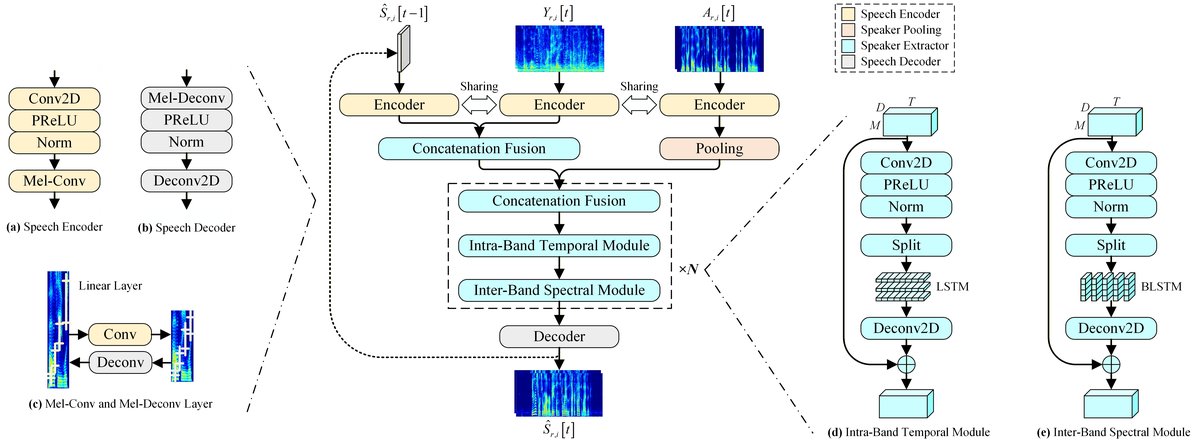 整体流程:
整体流程:
- 输入:当前帧的混合语音复数频谱
Y[t](大小为F x T,但T=1用于单帧处理)和注册语音A(大小为F x Ta),以及前一帧的估计语音复数频谱̂S[t-1](大小为F x 1)。 - 输出:当前帧的目标语音复数频谱
̂S[t](大小为F x 1)。
主要组件:
- 语音编码器:三个参数共享的编码器,分别处理
Y[t]、A和̂S[t-1]。每个编码器先通过一个Conv2D+PReLU+IN层提取特征,再通过一个Mel-Conv层进行基于感知的频率下采样(见2.1节),将频率维度从F压缩到M。这极大地减少了后续处理的维度。 - 说话人池化:如图3(a)所示。将注册语音编码器输出的特征
E(D x Ta x M)通过一个轻量级的U-Net模块处理后,在时间维度上取平均,得到一个与混合语音帧无关的固定说话人表征̄E(D x 1 x M)。这是一种“无嵌入”机制,不使用额外的说话人识别损失。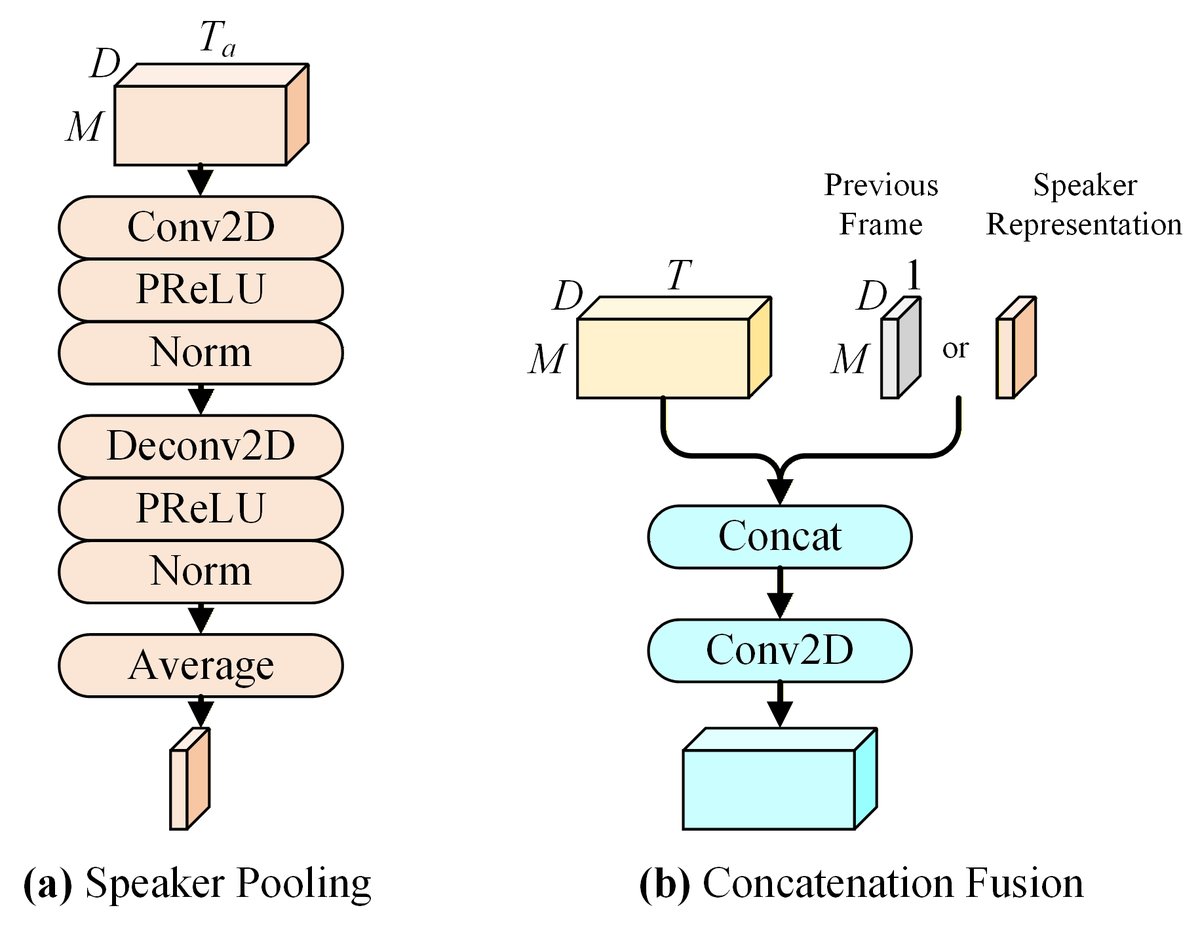
- 说话人提取器:这是模型的核心,由N个相同的块堆叠而成。每个块包含一个带内时序模块和一个带间频谱模块(见2.2节)。
- 输入融合:在进入第一个块之前,将混合语音编码特征、前一帧估计语音编码特征在通道维度拼接,再通过一个Conv2D层融合。参考说话人特征
̄E则通过逐层拼接融合的方式,在每个块的输入处与当前特征拼接后输入。 - 带内时序模块:将输入特征沿频率维度零填充后,划分成多个非重叠的频带(band),每个频带内部使用一个共享的单层LSTM来建模时间依赖,然后通过Deconv2D和合并操作恢复原始频率维度,并加入残差连接。
- 带间频谱模块:与带内模块结构类似,但将输入特征的每个时间帧视为一个独立的序列(长度为频带数),使用一个共享的单层双向LSTM(BLSTM)来建模频带间的频谱依赖。
- 输入融合:在进入第一个块之前,将混合语音编码特征、前一帧估计语音编码特征在通道维度拼接,再通过一个Conv2D层融合。参考说话人特征
- 语音解码器:包含一个Mel-Deconv层(上采样频率维度)和一个Deconv2D层,将提取器的输出解码为目标语音的复数频谱。
关键设计选择动机:
- 感知压缩:利用梅尔尺度不均匀的频率分辨率特性,用较少的特征维度(M=64)覆盖全频带,减少计算量。
- 分带建模:将频谱分割为子带,分别进行高效的时序和频谱建模,平衡了建模能力和计算复杂度。
- 自回归连接:利用语音信号的时序相关性,将前一帧的估计结果作为当前帧处理的额外信息,增强了上下文信息。
- 无嵌入说话人池化:避免了复杂的说话人编码器和分类损失,简化模型并可能减少说话人混淆错误。
💡 核心创新点
- 超低复杂度的自回归时频域框架:首次将自回归机制与高效的时频域处理结合用于TSE,并通过一系列优化(感知压缩、分带建模)将复杂度降至0.91 MACs(G/s),仅为现有因果方法的约12.5%,实现了性能与效率的优秀平衡。
- 基于感知的可训练下采样(Mel-Conv):创新性地设计了一个受梅尔滤波器组约束的、可训练的卷积层来进行频率下采样。与简单的池化或固定滤波相比,它能自适应地学习更符合语音感知特性的频率压缩方式,在降维的同时尽可能保留关键信息。
- 无嵌入的说话人池化与分层融合策略:摒弃了传统TSE中显式的说话人识别模块和辅助损失,转而使用简单的U-Net+平均池化来获取说话人表征,并采用“混合-前帧估计先行融合,参考说话人逐层融合”的策略。这简化了模型,并在实验中表现出更低的说话人混淆率(见图4分析)。
🔬 细节详述
- 训练数据:使用动态混合生成无限训练数据。从WSJ0语料库中随机采样目标说话人、干扰说话人和背景噪声(WHAM!数据集)。混合准则:响度归一化;两说话人间相对能量在[-3, 3] dB随机采样;涉及噪声时,信噪比在[-6, 3] dB随机采样。注册语音为同一目标说话人的另一段随机语音(平均时长约7.3秒)。
- 损失函数:多域损失,如公式(7):
L_Total = L_SI-SDR + λ1 L_Mag+RI + λ2 L_eSTOI。L_SI-SDR:尺度不变的信号失真比损失。L_Mag+RI:幅度谱和复数谱的均方误差损失。L_eSTOI:扩展的短时客观可懂度损失。- 论文未提及
λ1和λ2的具体数值。
- 训练策略:使用AdamW优化器,初始学习率为0.001。训练150个epoch,如果验证损失连续3个epoch不下降,则学习率减半。如果6个epoch没有提升,则触发早停。
- 关键超参数:
- FFT大小:256,窗长:32ms,窗移:16ms。
- 频率维度F=129(256/2+1),压缩后M=64。
- 感知压缩阈值δ=0.3。
- 提取器块数N=4。
- 特征维度D=32, C=32。
- 带内LSTM隐藏单元数H=32。
- 带宽L=1(即每个频带只含一个特征维度)。
- 所有Conv2D/Deconv2D卷积核大小为(时间,频率) = 1×3。
- 训练硬件:论文未提及具体GPU型号、数量和训练时长。
- 推理细节:采用流式处理,每帧独立处理。使用LSTM隐藏状态和单元状态作为隐状态传递,实现自回归。缓冲区大小为64.0 KB。
- 其他:未使用并行训练技巧(如教师强制)进行AR建模,以避免性能损失。
📊 实验结果
主要Benchmark:WSJ0-2mix(无噪)、WHAM!(带噪)。
与最强基线对比:
- 在WSJ0-2mix上,AR-BSNet的SI-SDR为13.3 dB,超过了因果SpEx++(11.2 dB)和SpEx+(10.0 dB),但低于DSINet(15.7 dB)。其PESQ(3.13)和eSTOI(87.09%) 表现突出,尤其是PESQ超过了所有基线。计算复杂度MACs(0.91 G/s)远低于所有基线。
- 在WHAM!上,AR-BSNet(SI-SDR: 4.9 dB)超过了因果SpEx+(5.2 dB,SI-SDR相近但PESQ更高),且通过使用更长的注册语音(60秒)或使用GRU替代LSTM,性能可进一步提升至SI-SDR 5.6 dB。
关键消融实验(基于WSJ0-2mix,见表2):
| 方法 | MACs(G/s) | PESQ | SDR(dB) | SI-SDR(dB) |
|---|---|---|---|---|
| NAR-BSNet (非自回归) | 0.88 | 3.04 | 12.8 | 12.3 |
| AR-BSNet (默认) | 0.91 | 3.13 | 13.8 | 13.3 |
| -> w/ N=3 (更少块) | 0.69 | 2.92 | 11.6 | 11.1 |
| -> w/ N=5 (更多块) | 1.07 | 3.11 | 13.5 | 13.1 |
| -> w/o eSTOI loss | 0.88 | 3.02 | 12.8 | 12.3 |
| -> w/o MSE loss | 0.88 | 3.00 | 12.5 | 12.0 |
| -> w/o Mel-Conv (无感知压缩) | 1.20 | 2.93 | 12.3 | 11.8 |
| -> w/o U-Net (说话人池化) | 0.78 | 2.94 | 11.7 | 11.1 |
| -> w/ GRU (替代LSTM) | 0.77 | 3.03 | 12.7 | 12.2 |
关键结论:
- 引入自回归(AR vs NAR)带来了显著的性能提升(SI-SDR +1.0 dB),而复杂度增加微乎其微(0.91 vs 0.88 G/s)。
- 感知压缩(Mel-Conv)对维持高频率分辨率和低复杂度至关重要,移除它会导致复杂度显著上升(+32%)且性能下降。
- 多域损失函数(尤其是eSTOI和MSE loss)对提升PESQ和SI-SDR有正面作用。
- 使用GRU可以进一步略微降低复杂度,而性能几乎不变。
⚖️ 评分理由
- 学术质量:5.5/7:论文的创新点清晰、实用,技术方案合理,实验设计充分,对比了多种基线并进行了深入的消融分析,数据支撑有力。技术正确性高。扣分主要在于其性能提升(相较于最佳基线DSINet)并非全面领先,且部分模块(如U-Net)的细节描述可以更深入。
- 选题价值:1.5/2:选题精准切中TSE模型落地的关键瓶颈——计算复杂度,提出的超低复杂度方案具有明确的实用价值和产业化前景,对边缘计算和实时语音处理社区有较高参考价值。
- 开源与复现加成:0.0/1:论文未提供任何代码、预训练模型或开源计划链接,这对社区复现和后续研究是一个显著的缺点。虽然训练细节详尽,但缺乏开源仍会影响该工作的传播和验证效率。