📄 APKD: Aligned And Paced Knowledge Distillation Towards Lightweight Heterogeneous Multimodal Emotion Recognition
#知识蒸馏 #情感识别 #多模态模型 #语音情感识别 #轻量化
✅ 7.5/10 | 前25% | #情感识别 | #知识蒸馏 | #多模态模型 #语音情感识别
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yujian Sun(山东理工大学计算机科学学院)
- 通讯作者:Shanliang Yang(山东理工大学计算机科学学院,yangshanliang@sdut.edu.cn)
- 作者列表:Yujian Sun(山东理工大学计算机科学学院),Bingtian Qiao(福州大学莫纳什大学联合国际学院),Yiwen Wang(福州大学莫纳什大学联合国际学院),Shanliang Yang(山东理工大学计算机科学学院)
💡 毒舌点评
APKD框架的亮点在于其问题洞察力——指出异构蒸馏中“特征对齐”与“知识粒度调整”是深度耦合的,并用协同模块优雅地解决了这一矛盾。但短板也很明显:实验仅验证了预设的“大Transformer教师-CNN/MobileViT学生”这一种异构模式,对于其他类型的异构架构(如不同规模的Transformer)是否同样有效缺乏探索,结论的普适性有待加强。
🔗 开源详情
- 代码:提供了GitHub代码仓库链接:https://github.com/ItsDia/AP-KD。
- 模型权重:论文中未提及公开预训练学生模型权重。
- 数据集:使用了CMU-MOSEI和IEMOCAP两个公开数据集,论文中说明了数据集来源,获取方式未详细说明,通常需要按原数据集要求申请。
- Demo:论文中未提及在线演示。
- 复现材料:提供了详细的训练超参数(学习率、优化器、batch size、epoch数、损失权重等)、硬件配置、网络架构细节以及损失函数公式,复现材料较为充分。
- 引用的开源项目:明确引用了作为教师和学生模型的开源预训练模型,包括SSAST、ViT-B/16、RoBERTa、LightSERNet、MobileViT v3和TextCNN。也引用了GRL等基础模块的来源。
📌 核心摘要
- 问题:在基于知识蒸馏的轻量级多模态情感识别中,教师与学生模型在架构和规模上的异质性导致两大耦合挑战:特征空间不匹配、不同模态教师的知识粒度差异大。
- 方法核心:提出APKD框架,包含两个协同工作的模块:结构特征对齐(SFA)模块和自适应知识节奏(AKP)模块。SFA通过标准化将异构特征映射到共享空间;AKP为每个模态引入可学习的节奏系数,动态调整教师知识分布的软硬程度。
- 创新点:首次明确将异构MER中的特征对齐与知识粒度调整作为耦合问题进行联合优化。AKP模块利用梯度反转层自适应学习每个模态的节奏系数,实现了“按需分配”知识。
- 主要实验结果:在CMU-MOSEI和IEMOCAP数据集上取得SOTA。一个仅2.73M参数的超轻量学生模型,准确率分别达到49.51%和73.96%,超越或持平于参数量大得多的现有方法。消融实验证实SFA和AKP模块均不可或缺。
- 实际意义:为将高性能的多模态情感识别模型部署到计算资源有限的边缘设备提供了有效的解决方案,推动了该技术在实际人机交互场景中的应用。
- 局限性:异质性定义主要基于“大模型教师与小CNN/MobileViT学生”这一范式。对其他异质性组合的普适性未验证。节奏系数τₘ的调整范围(1.0-20.0)是经验值,其理论选择依据未深入探讨。
🏗️ 模型架构
APKD框架的整体架构如图1所示。它遵循“大教师-小学生”的范式,旨在实现高效知识迁移。
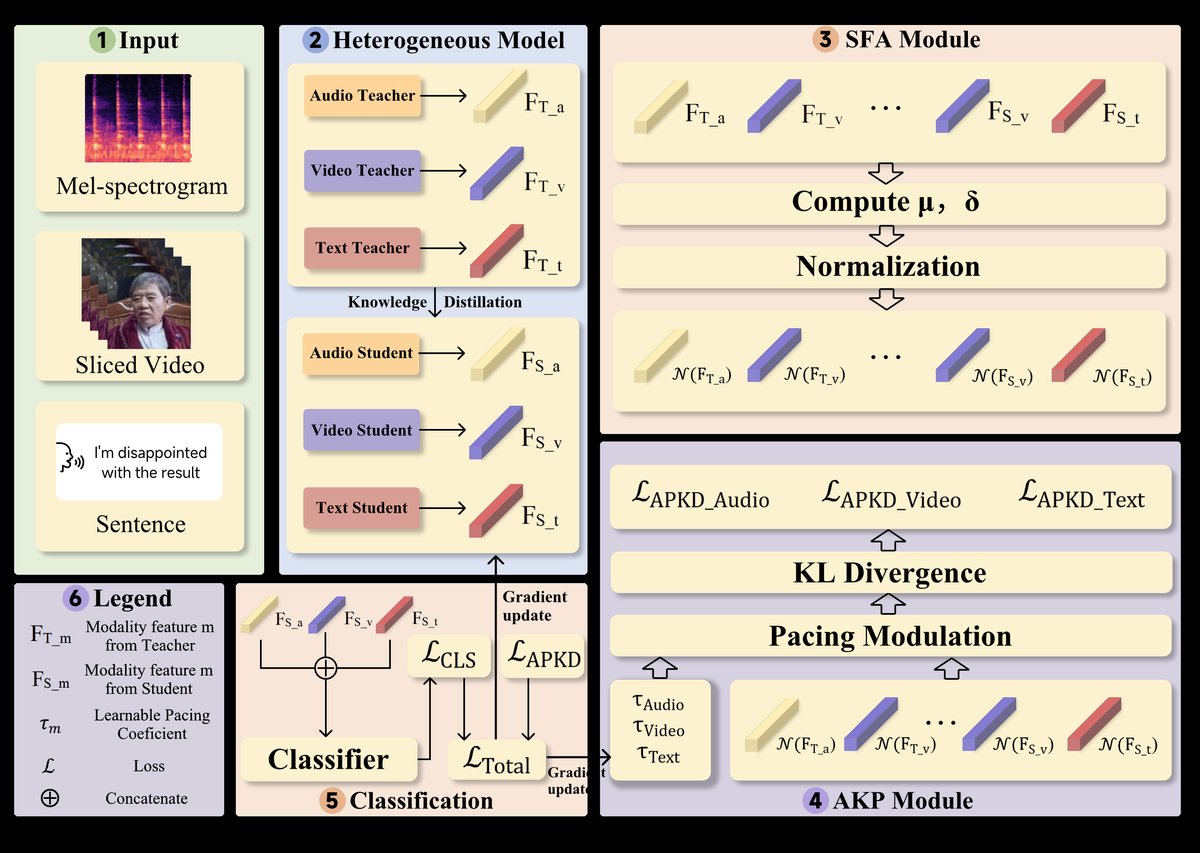
- 输入与特征提取:多模态输入(音频、视频、文本)分别由异构的教师模型(SSAST、ViT-B/16、RoBERTa)和学生模型(LightSERNet、MobileViT v3、TextCNN)处理,提取各模态的特征向量(分类层前)。
- 结构特征对齐模块(SFA):对教师特征Fᵀᵐ和学生特征Fˢᵐ进行标准化处理,公式为:N(F) = (F - μ) / (σ + ε)。这一步将不同模态、不同模型的特征映射到均值为0、方差为1的共享标准空间,为后续知识比较奠定了基础。
- 自适应知识节奏模块(AKP):这是核心创新。它为每个模态m引入一个可学习的节奏系数τₘ。该系数通过一个基于梯度反转层(GRL)的调制过程生成:τₘ = τₘᵢₙ + (τₘₐₓ - τₘᵢₙ) * σ(GRL(θₘ, λ))。τₘ的值在[τₘᵢₙ, τₘₐₓ](设为[1.0, 20.0])范围内自适应调整。较高的τₘ会“软化”(平滑)教师知识分布(如文本模态),较低的τₘ会“硬化”(锐化)知识分布(如视听模态)。
- 蒸馏损失计算:对齐后的特征经softmax(·/τₘ)处理后,计算KL散度,并乘以τₘ²进行缩放,得到各模态的蒸馏损失Lₐₚₖᴰ,ᵐ。最终,总蒸馏损失为各模态损失之和。
- 优化与输出:总训练损失Lₜₒₜₐₗ = γLᶜˡˢ + αLₐₚₖᴰ,其中Lᶜˡˢ是学生分类损失。学生模型和AKP模块的参数在此损失下联合更新。最后由学生分类头输出情感预测。
💡 核心创新点
- 耦合问题识别:明确指出在异构多模态蒸馏中,特征空间对齐与知识粒度调整是相互依赖、不可分割的耦合问题。这是对现有方法将两者独立处理这一局限性的重要洞察。
- 协同框架设计:提出了APKD框架,其中SFA模块为AKP模块提供可比的特征基础,而AKP模块在此基础上对每个模态的知识进行个性化调整,两者协同工作,形成一个完整的蒸馏闭环。
- 自适应节奏调节机制:AKP模块通过引入受GRL调制的可学习系数τₘ,实现了对教师知识分布软硬程度的动态、模态自适应调整。这不同于固定的温度缩放,能根据训练过程和不同模态教师的特性(如文本教师分布过锐、视听教师分布相对平滑)自动优化知识粒度。
- 轻量高效模型验证:实验证明了一个仅2.73M参数的超轻量学生模型,通过APKD能有效从大型异构教师网络学习,并在标准基准上达到SOTA性能,验证了框架的实用性和高效性。
🔬 细节详述
- 训练数据:
- 数据集:CMU-MOSEI(23,453片段,65小时,6类情绪)和IEMOCAP(12小时,9,800样本,6类情绪)。
- 预处理:论文未详细说明具体预处理步骤。
- 数据增强:论文中未提及。
- 损失函数:
- 蒸馏损失:如上文公式(3)所示,为带节奏系数缩放的KL散度。权重α = 0.9。
- 分类损失:交叉熵损失Lᶜˡˢ。权重γ = 0.1。
- 训练策略:
- 优化器:AdamW。
- 学习率:IEMOCAP为5e-4,MOSEI为1e-5。
- 调度策略:余弦退火,衰减率为1e-2。
- 批大小:16。
- 训练轮数:50 epochs。
- GRL超参数λ:遵循原工作自适应调度。
- 关键超参数:
- 节奏系数范围:τₘᵢₙ = 1.0, τₘₐₓ = 20.0。
- 数值稳定项ε = 1e-7。
- 学生模型总参数量:2.73M。
- 训练硬件:2块NVIDIA RTX 4090 GPU (2*24GB), 120GB RAM。
- 推理细节:论文未提及。
- 正则化/稳定训练技巧:使用了GRL防止系数调整过快;特征标准化增强稳定性。
📊 实验结果
表1:与SOTA方法在IEMOCAP和CMU-MOSEI数据集上的性能比较
| 方法 | 参数量(M) | IEMOCAP ACC(%) | IEMOCAP WF1(%) | CMU-MOSEI ACC(%) | CMU-MOSEI WF1(%) |
|---|---|---|---|---|---|
| UniMSE [20] | - | 70.56 | 70.66 | - | - |
| SACL-LSTM [21] | 2.60 | 70.55 | 70.60 | - | - |
| MMGCN [22] | - | - | - | 45.67 | 44.11 |
| DialogueCRN [23] | 3.30 | - | - | 37.88 | 26.55 |
| M3Net [24] | - | 70.92 | 71.07 | 43.67 | 41.12 |
| GraphSmile [25] | *14.30 | 72.77 | 72.81 | 46.82 | 44.93 |
| APKD (Ours) | 2.73 | 73.96 | 74.15 | 49.51 | 43.33 |
关键结论:APKD以极小的参数量(2.73M)在IEMOCAP的ACC和WF1上,以及CMU-MOSEI的ACC上均取得了最优性能。在CMU-MOSEI的WF1上略低于GraphSmile,但考虑到参数量差距巨大(2.73M vs 14.30M),整体优势明显。
表2:APKD在IEMOCAP和CMU-MOSEI数据集上的消融实验
| 方法 | IEMOCAP ACC(%) | IEMOCAP WF1(%) | CMU-MOSEI ACC(%) | CMU-MOSEI WF1(%) |
|---|---|---|---|---|
| Student-Only | 70.81 | 71.55 | 47.79 | 41.83 |
| APKD w/o SFA | 71.38 | 71.56 | 48.38 | 42.35 |
| APKD w/o AKP | 72.32 | 72.41 | 48.41 | 42.71 |
| APKD (Full) | 73.96 | 74.15 | 49.51 | 43.33 |
关键结论:移除SFA或AKP都会导致性能下降。移除SFA后下降更显著,证明特征对齐是基础。AKP模块(vs 固定τ=10.5)也带来了可观提升,证明了自适应调整的价值。两者协同实现了最佳性能。
图2:不同模态的节奏系数(τₘ)对比
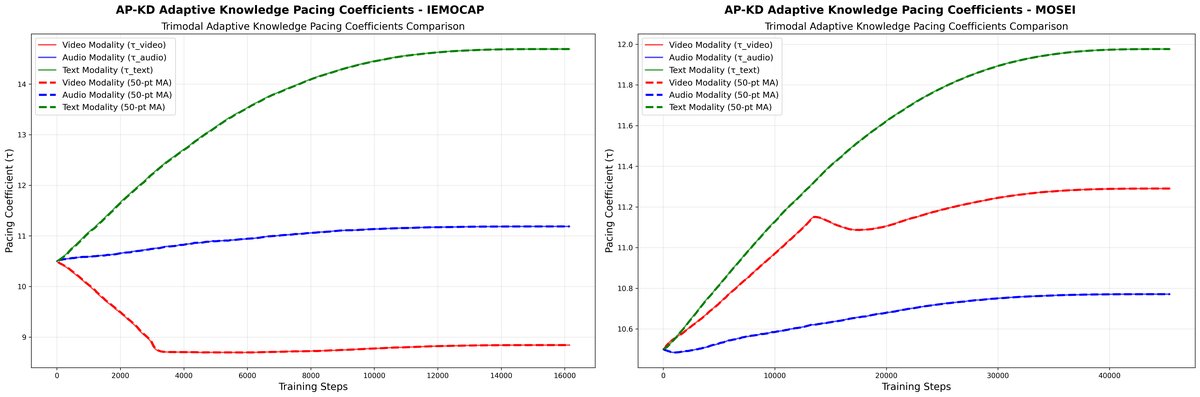 图表说明:图2展示了训练过程中各模态节奏系数的变化。文本模态(RoBERTa教师)的系数最高且呈上升趋势(约15-20),说明其知识分布被自适应地平滑。音频和视频模态的系数较低(约5-10),且视频模态系数更低,说明其知识分布被适度锐化,以帮助学生提取关键信息。这直观验证了AKP模块的工作机制。
图表说明:图2展示了训练过程中各模态节奏系数的变化。文本模态(RoBERTa教师)的系数最高且呈上升趋势(约15-20),说明其知识分布被自适应地平滑。音频和视频模态的系数较低(约5-10),且视频模态系数更低,说明其知识分布被适度锐化,以帮助学生提取关键信息。这直观验证了AKP模块的工作机制。
⚖️ 评分理由
- 学术质量:5.5/7:创新点清晰,针对性强,方法设计完整。实验在标准Benchmark上进行了充分的对比和消融,数据可信。主要短板在于创新深度属于“组合式优化”而非“原理突破”,且异构性定义的普适性验证不足。
- 选题价值:1.5/2:直击轻量化部署的痛点,具有明确的应用前景。多模态情感识别是热门但相对垂直的领域,影响范围受限。
- 开源与复现加成:0.5/1:提供了代码仓库和完整的训练配置,复现友好度高。未提供预训练学生模型权重是一个小缺憾。