📄 AnyRIR: Robust Non-Intrusive Room Impulse Response Estimation in the Wild
#空间音频 #信号处理 #鲁棒性
✅ 7.0/10 | 前25% | #空间音频 | #信号处理 | #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kyung Yun Lee(Aalto University, Acoustics Lab, Dept. of Information and Communications Engineering)
- 通讯作者:Sebastian J. Schlecht(Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU))
- 作者列表:
- Kyung Yun Lee(Aalto University, Acoustics Lab, Dept. of Information and Communications Engineering)
- Nils Meyer-Kahlen(Aalto University, Acoustics Lab, Dept. of Information and Communications Engineering)
- Karolina Prawda(University of York, AudioLab, School of Physics, Engineering and Technology)
- Vesa Välimäki(Aalto University, Acoustics Lab, Dept. of Information and Communications Engineering)
- Sebastian J. Schlecht(Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU))
💡 毒舌点评
亮点:巧妙地将无处不在的背景音乐和音乐识别技术(如Shazam)作为“免费”的激励信号,实现了真正意义上的“野外”非侵入式RIR测量,思路非常实用且接地气。短板:核心创新点(用ℓ1范数替代ℓ2范数以抗脉冲噪声)是信号处理领域的经典技巧,论文的新颖性更多体现在将这一技巧与音乐激励、时频处理、高效求解器结合以解决特定工程问题上,技术深度和理论突破性一般。
🔗 开源详情
- 代码:提供。论文中明确指出代码仓库为
https://github.com/kyungyunlee/robust-deconv。 - 模型权重:未提及(本方法非深度学习模型,无需权重)。
- 数据集:未公开提供。论文使用的模拟数据集(音乐、RIR、噪声)来自公开来源(Suno AI, MIT ARSSS, AID),但论文未提供整合后的数据集下载链接。真实数据集的录音未提及公开。
- Demo:提供在线演示,论文末尾提及有相关音频、视频和额外结果,网址为
https://kyungyunlee.github.io/anyRIR-demo。 - 复现材料:提供了部分关键参数(如
N_DFT=256, EQ滤波器阶数200),但训练(优化)策略的更多细节(如IRLS最大迭代次数、LSMR容差、δ的具体设置或估计方法)未在文中完全明确。 - 论文中引用的开源���目:提到了CVXPY [17](用于对比基线)、SciPy的STFT/iSTFT函数、FFmpeg(用于模拟编解码器效果)。
📌 核心摘要
- 解决问题:在嘈杂、非受控的真实环境(如咖啡馆)中,传统依赖专用激励信号(如扫频信号)的房间脉冲响应测量方法会受到脚步、说话等非平稳噪声的严重干扰,且侵入性强。
- 方法核心:提出AnyRIR,一种非侵入式RIR估计方法。它利用环境中已有的背景音乐作为激励信号(可通过音乐识别算法获取干净参考),将RIR估计建模为时频域中的ℓ1范数回归问题,并采用迭代重加权最小二乘法(IRLS)和最小二乘最小残差法(LSMR)高效求解,同时对激励和测量信号进行均衡(EQ)预处理以改善条件数。
- 新意之处:与使用ℓ2范数(假设高斯噪声)或频域去卷积的传统方法不同,AnyRIR的ℓ1范数目标函数对非平稳噪声(表现为离群值)具有鲁棒性,通过加权机制自动抑制受干扰的时频单元。它无需专用激励信号,实现了“利用环境本身”进行测量。
- 主要结果:在模拟和真实实验中,AnyRIR性能显著优于ℓ2范数和频域去卷积基线。在存在非平稳噪声时,AnyRIR的估计误差(-36.0 dB)比ℓ2方法(-10.6 dB)低25.4 dB。它对音乐编解码器不匹配也表现出鲁棒性(误差约-22 dB,相比匹配条件恶化约15 dB)。在真实厨房录音中,其估计的能量衰减曲线与扫频法测得的地面真值接近。
方法 仅平稳噪声 (h误差 dB) 平稳+非平稳噪声 (h误差 dB) AnyRIR -42.0 ± 4.8 -36.0 ± 5.0 ℓ2方法 -41.7 ± 4.8 -10.6 ± 6.8 频域去卷积 -7.6 ± 4.9 2.8 ± 4.5 - 实际意义:使得在无法控制噪声或播放专用测试音的公共场所(如商场、餐厅)进行声学特性测量成为可能,为AR/VR音频渲染、智能音箱空间音频校准等应用提供了新的数据获取途径。
- 主要局限性:方法依赖于环境中存在可被识别的背景音乐,且识别出的干净参考音质(如编解码器)会影响最终精度。论文未深入讨论如何处理音乐识别失败或参考音不存在的情况。
🏗️ 模型架构
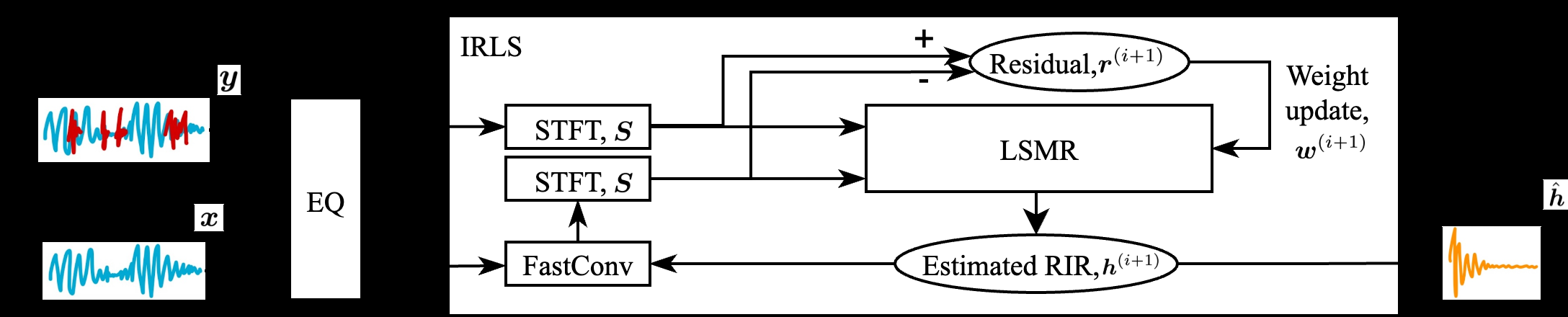
本文没有传统意义上的“神经网络”模型架构,其核心是一个基于优化的信号处理流程。图2(pdf-image-page1-idx1)清晰地展示了该流程。
完整输入输出流程:
- 输入:在含噪环境(如咖啡馆)录制的音乐信号
y(包含激励信号x与房间响应h的卷积,以及加性噪声n),以及通过音乐识别(如Shazam)获取的对应干净音乐参考信号x。 - 预处理:对
x和y进行均衡(EQ)预处理(如下采样、注入高频噪声、应用高阶逆线性预测滤波器),目的是使激励信号的功率谱密度趋于平坦,改善后续优化问题的条件数。 - 核心优化求解:
- 目标:在时频域求解最小化ℓ1范数残差问题:
ĥ = argmin_h ||Sy - SXh||₁。 - 求解器:采用IRLS算法将ℓ1问题转化为一系列加权最小二乘子问题。
- 子问题求解:每个加权最小二乘子问题通过LSMR迭代求解。LSMR是一种“无矩阵”的迭代法,只需定义前向算子(
SXh:卷积+STFT)和伴随算子(X^H S^H y:iSTFT+相关卷积),避免显式构造巨大的Toeplitz矩阵X和STFT矩阵S。卷积及其伴随操作均通过FFT实现,计算高效。
- 目标:在时频域求解最小化ℓ1范数残差问题:
- 输出:估计出的房间脉冲响应
ĥ。
关键设计选择及动机:
- 时频域处理:非平稳噪声(如语音)在时频域具有稀疏性,便于加权抑制。
- ℓ1范数:对离群值(非平稳噪声)鲁棒,比ℓ2范数更适合本场景。
- IRLS + LSMR:IRLS提供了一种将ℓ1问题转化为易解子问题的框架;LSMR作为无矩阵迭代求解器,能够处理由长激励信号和卷积结构导致的病态大系统,且内存效率高。
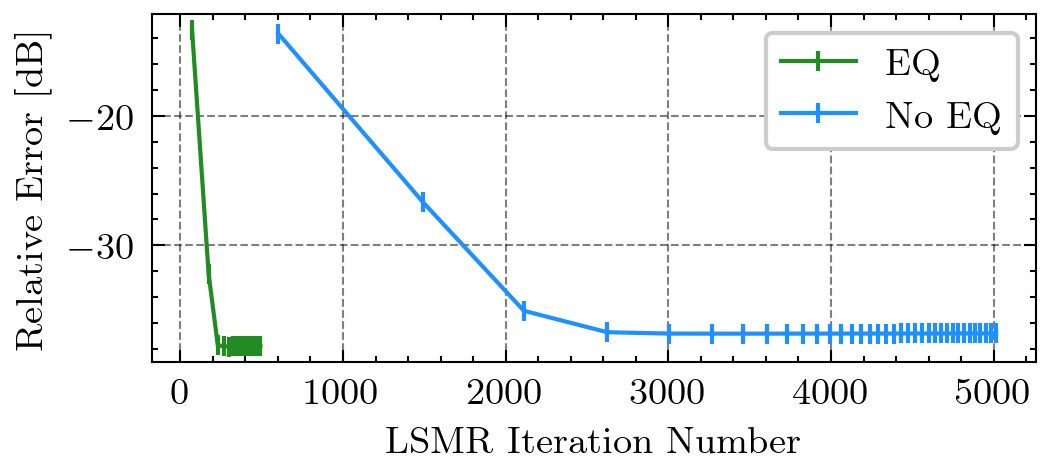
- EQ预处理:作为预条件器,显著改善了LSMR的收敛速度(如图3所示,pdf-image-page2-idx2)。
💡 核心创新点
- 基于音乐激励的非侵入式测量:首次(据作者称)提出将公共环境中的背景音乐作为激励信号,结合音乐识别技术获取干净参考,实现完全非侵入式的RIR估计。这解决了传统方法需要播放专用测试信号的侵入性问题。
- 面向非平稳噪声鲁棒的时频域ℓ1优化:将RIR估计明确表述为时频域中的ℓ1范数回归问题。不同于先前工作将ℓ1用于促进RIR稀疏性,本文纯粹利用其对数据拟合中的离群值的鲁棒性来对抗非平稳噪声。
- 高效的大规模无矩阵求解:通过结合IRLS和LSMR,并利用FFT实现卷积算子,构建了一个可扩展的求解流水线,能够处理实际应用中常见的长激励信号(数十秒音乐),避免了构造巨大系统矩阵的内存和计算瓶颈。
- 针对音乐信号的EQ预处理策略:针对音乐信号频谱非平坦的特点,设计了EQ预处理作为预条件器,有效改善了系统矩阵的条件数,使迭代求解器收敛速度提升约10倍。
🔬 细节详述
- 训练数据:未说明(论文未提及“训练”,这是传统优化方法。模拟数据使用的音乐由Suno AI生成,RIR来自MIT ARSSS数据集,噪声来自AID数据集)。
- 损失函数:时频域ℓ1范数损失:
||Sy - SXh||₁。作用是鲁棒地度量测量值Sy与模型预测值SXh之间的差异,对大的残差(由非平稳噪声引起)不敏感。 - 训练策略:未说明(本文为优化方法,无神经网络训练过程)。
- 关键超参数:
- IRLS迭代中的阈值
δ:解释为背景噪声估计的标准差,用于区分平稳噪声和非平稳噪声。 - LSMR迭代的最大次数:未明确给出,但图3显示EQ预处理后收敛所需的迭代次数大幅减少。
- STFT参数:DFT长度
N_DFT = 256,使用盒形窗,无重叠,零填充。 - 预处理EQ滤波器阶数:200。
- IRLS迭代中的阈值
- 训练硬件:未说明。
- 推理细节:即求解优化问题的过程。LSMR的每次迭代涉及一次前向传播(
SXh,卷积+STFT)和一次伴随传播(X^H S^H y,iSTFT+相关卷积),均基于FFT计算。 - 正则化或稳定训练技巧:EQ预处理是关键的稳定化技巧。在权重更新中,
max(|r|, δ)用于处理微小残差,避免除零。
📊 实验结果
主要Benchmark与结果: 论文在模拟数据和真实数据上进行了评估。
非平稳噪声鲁棒性(模拟数据,50个样本): 指标为RIR估计误差(
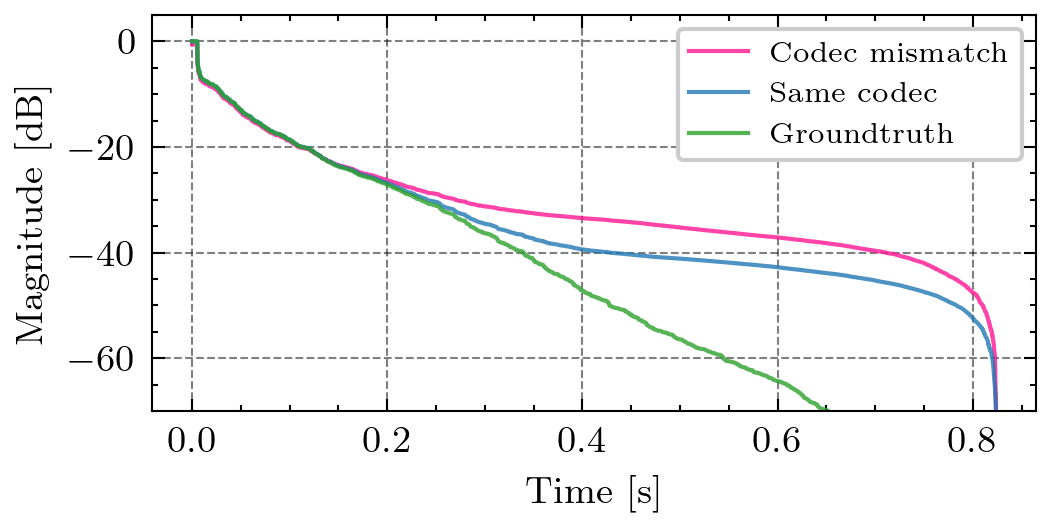
h error,单位dB,均值±标准差)。方法 仅平稳噪声 (SNR 50dB) 平稳 + 非平稳噪声 AnyRIR -42.0 ± 4.8 -36.0 ± 5.0 ℓ2方法 -41.7 ± 4.8 -10.6 ± 6.8 频域去卷积 -7.6 ± 4.9 2.8 ± 4.5 结论:在仅有平稳噪声时,AnyRIR与ℓ2方法性能相当。当加入非平稳噪声后,ℓ2方法和频域去卷积性能急剧下降,而AnyRIR仍保持较低误差,表现出强鲁棒性。 音乐编解码器不匹配影响(模拟数据): 条件:测量信号用MP3@173kbps编码,激励参考信号用MP3@64kbps编码(失配),对比两者使用相同编码(匹配)。 结果:失配条件导致误差约-22 dB,匹配条件下误差约-37 dB,即失配引入了约15 dB的额外误差,主要影响RIR的尾部。
真实世界评估(Aalto声学实验室厨房): 播放AI生成音乐,用扬声器播放,麦克风录制,同时实验室人员制造日常噪声。 结果:图7(pdf-image-page4-idx6)展示了一次录制的RIR能量衰减曲线(EDC)。AnyRIR的估计曲线与通过指数正弦扫频法获得的地面真值曲线非常接近,即使在存在干扰噪声的情况下。更多音频和视频示例见在线补充材料。
关键消融/分析实验:
- EQ预处理有效性:图3(pdf-image-page2-idx2)显示,EQ预处理将LSMR收敛所需的迭代次数减少了约10倍。
- 权重机制可视化:图4(pdf-image-page3-idx3)展示了AnyRIR如何为含噪声的时频单元分配接近0的权重,为干净单元分配接近1的权重,直观证明了其抑制非平稳噪声的机制。
- RIR估计对比:图5(pdf-image-page4-idx4)展示了不同方法估计出的RIR的能量衰减曲线对比,AnyRIR明显更接近地面真值。
⚖️ 评分理由
- 学术质量:6.0/7:论文技术路线清晰,将经典鲁棒优化(ℓ1范数)与现代信号处理工具(音乐识别、时频分析、高效迭代求解)巧妙结合,解决了一个实际工程问题。实验设计合理,包含了模拟对比、条件变化(编解码)和真实场景验证,数据充分。扣分点在于核心算法(IRLS求解ℓ1问题)并非原创,创新更多体现在应用和集成层面,理论深度有限。
- 选题价值:1.5/2:选题直面“野外”声学测量的实际挑战,具有明确的应用前景(AR/VR、智能设备)。虽然空间音频/RIR估计是相对垂直的领域,但其方法论(利用环境中的机会信号进行鲁棒估计)具有启发性。对于音频处理领域的研究者,这是一个有价值的参考案例。
- 开源与复现加成:0.5/1:论文提供了实现代码的GitHub链接,大大增强了研究的可复现性和实用性。然而,未提及是否提供模拟所用的完整数据集、EQ滤波器的具体设计参数、IRLS/LSMR的收敛容差等详细复现信息,也未提供预训练模型(尽管本任务通常不需要),因此复现门槛仍然存在。