📄 An Envelope Separation Aided Multi-Task Learning Model for Blind Source Counting and Localization
#声源定位 #多任务学习 #麦克风阵列 #端到端
✅ 6.5/10 | 前25% | #声源定位 | #多任务学习 | #麦克风阵列 #端到端
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Jiaqi Du(北京大学智能科学与技术学院,通用人工智能国家重点实验室)
- 通讯作者:Tianshu Qu(北京大学智能科学与技术学院,通用人工智能国家重点实验室,邮箱:qutianshu@pku.edu.cn)
- 作者列表:Jiaqi Du(北京大学智能科学与技术学院,通用人工智能国家重点实验室)、Donghang Wu(北京大学智能科学与技术学院,通用人工智能国家重点实验室)、Xihong Wu(北京大学智能科学与技术学院,通用人工智能国家重点实验室)、Tianshu Qu(北京大学智能科学与技术学院,通用人工智能国家重点实验室)
💡 毒舌点评
亮点在于将人耳听觉系统中“时空信息协同”的认知神经科学启发融入模型设计,通过一个可学习的门控机制动态平衡包络(时间)和坐标(空间)信息,这种“生理启发式设计”让模型动机显得很有说服力。短板是整体框架更像是把已有的吸引子网络、多任务学习和PIT进行工程化组合,缺乏更底层的理论突破;此外,所有实验都在精心控制的模拟数据集上完成,对真实世界中复杂声学环境(如非平稳噪声、遮挡)的鲁棒性验证不足,略显“温室里的花朵”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用了FSD50K公开数据集,但训练/测试的模拟FOA数据是作者通过脚本生成的,论文中未提供该生成脚本。
- Demo:未提供在线演示。
- 复现材料:给出了训练优化器、学习率、批次大小、轮数等部分细节。但未提供模型权重文件、训练配置文件或评估脚本。
- 论文中引用的开源项目:论文中明确提及并依赖以下开源工具/数据集:
- FSD50K:用于获取原始音频。
- gpuRIR:用于模拟房间脉冲响应。
- 总结:论文中未提及开源计划。虽然依赖一些公开工具,但复现作者特定的实验设置仍需要大量额外工作。
📌 核心摘要
- 问题:在声源数量未知或可变的条件下,实现准确的盲源计数与定位(SSL)是一个挑战。现有方法或受限于固定输出维度,或因独立处理包络分离与定位任务而未能充分利用时空信息的相互增益。
- 方法:提出一种包络分离辅助的多任务学习模型。该模型包含三个模块:1)声学特征提取模块,编码一阶环绕声信号;2)自适应吸引子模块,动态生成吸引子向量来估计声源数量;3)多任务学习模块,通过一个可学习的门控机制,联合优化包络分离与3D坐标回归任务,并使用排列不变训练解决输出顺序歧义。
- 创新:与现有顺序处理(先分离后定位)或独立优化任务的方法相比,该模型通过多任务学习框架实现了包络分离与方向预测的协同优化,利用包络信息作为辅助线索来增强定位精度。
- 结果:在基于FSD50K和模拟房间脉冲响应生成的测试集上,该方法在盲源计数准确率(平均93.4%,相比基线SEET的88.0%)和定位误差(方位角误差10.59°,仰角误差6.74°,距离误差0.64m,相对距离误差22.08%)上均优于现有基线方法(EINV2, Sp-ACCDOA, SEET)。消融实验证明了包络分离辅助模块的有效性。
- 意义:提供了一种处理未知声源数定位问题的统一框架,其时空信息协同优化的思路可能对其他多任务音频处理任务有借鉴意义。
- 局限性:1)所有实验在模拟数据上进行,泛化能力未知;2)模型复杂度及计算开销未分析;3)多任务学习权重λ需要手动设置。
🏗️ 模型架构
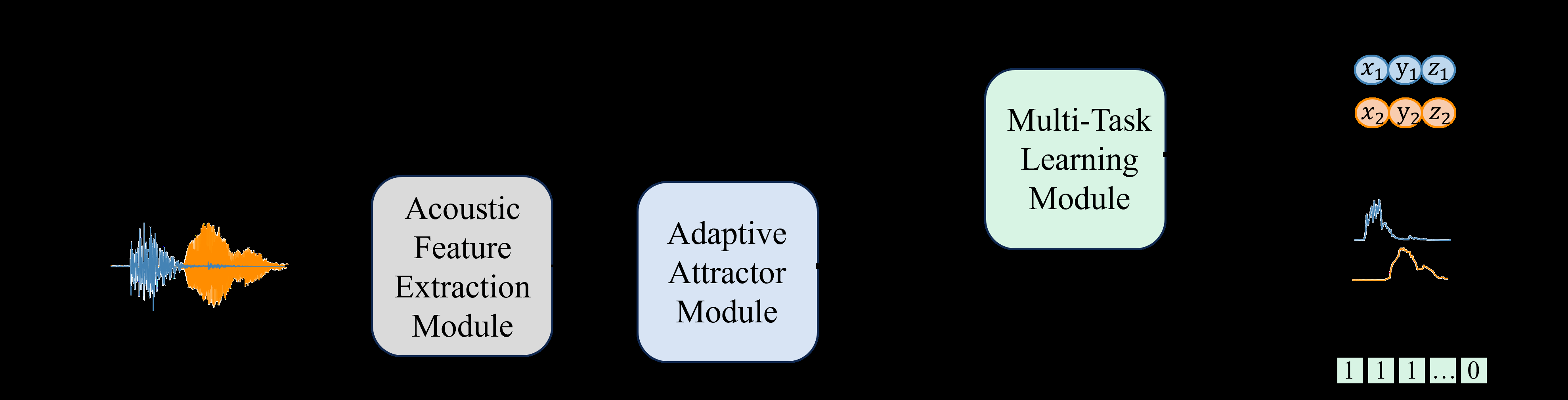
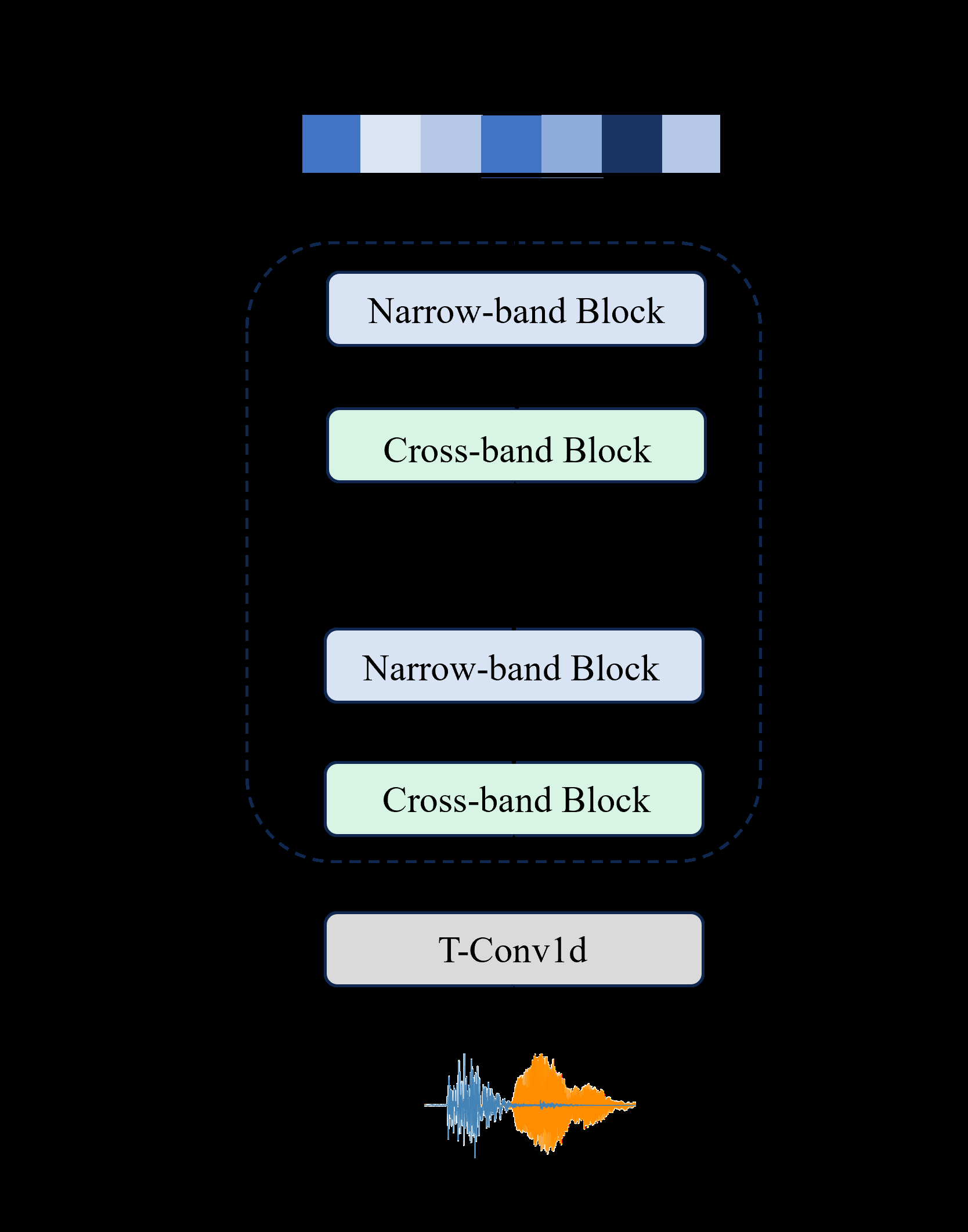 如图1所示,模型整体框架由三个串行模块构成:
如图1所示,模型整体框架由三个串行模块构成:
- 输入与输出:输入为一阶环绕声(FOA)混合信号。输出为对每个活跃声源的四个预测:存在概率、DOA(方向)、距离和包络。
- 声学特征提取模块(AFEM):如图2(a)所示,受SpatialNet启发,将FOA信号经短时傅里叶变换(STFT)转换到时频域,然后通过时域卷积、跨频带模块和窄带模块提取特征,输出混合信号的声学特征嵌入
B_mix(维度 F×T×H)。 - 自适应吸引子模块(AAM):如图2(b)所示,用于解决声源数量未知的问题。将
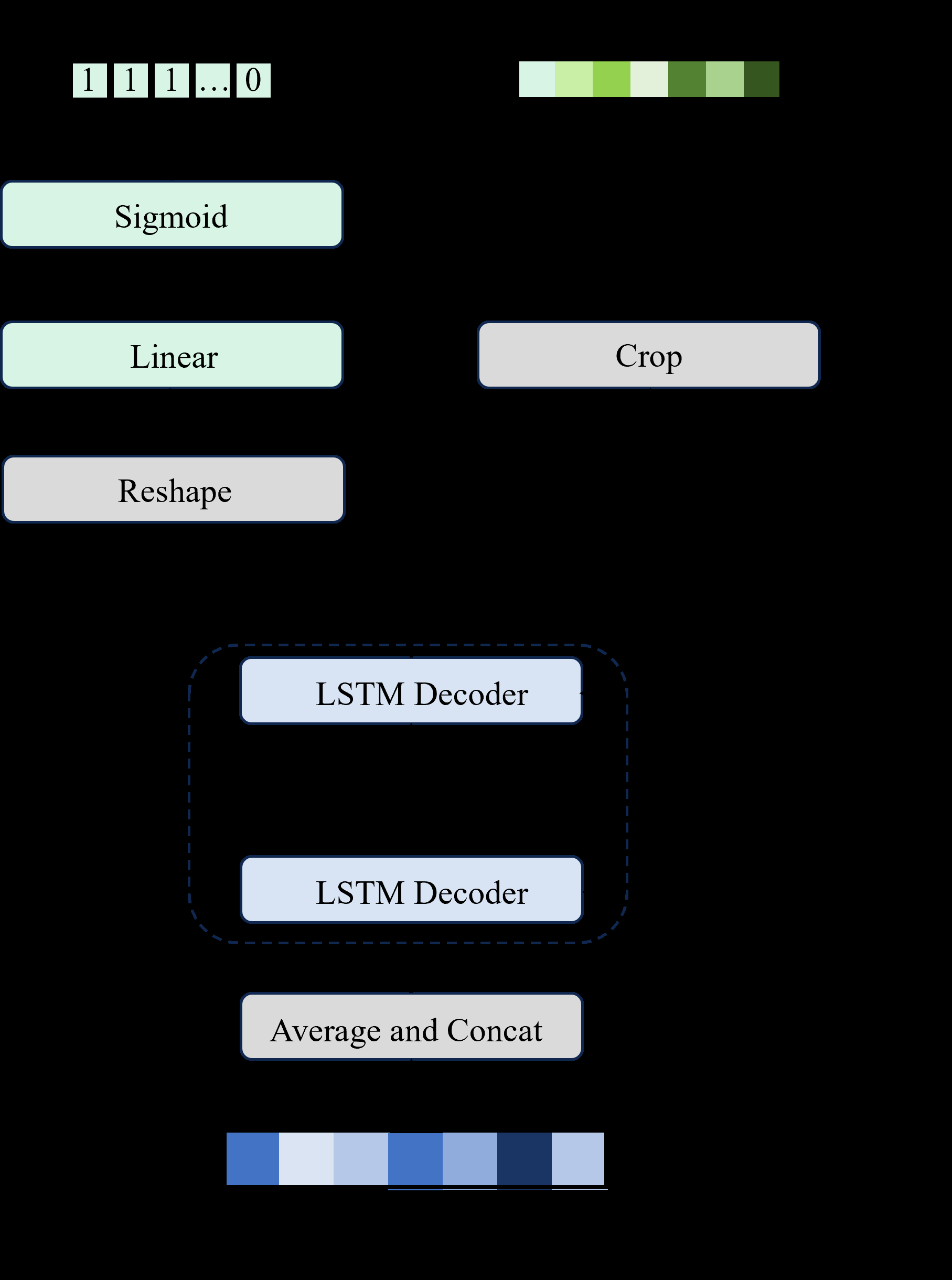
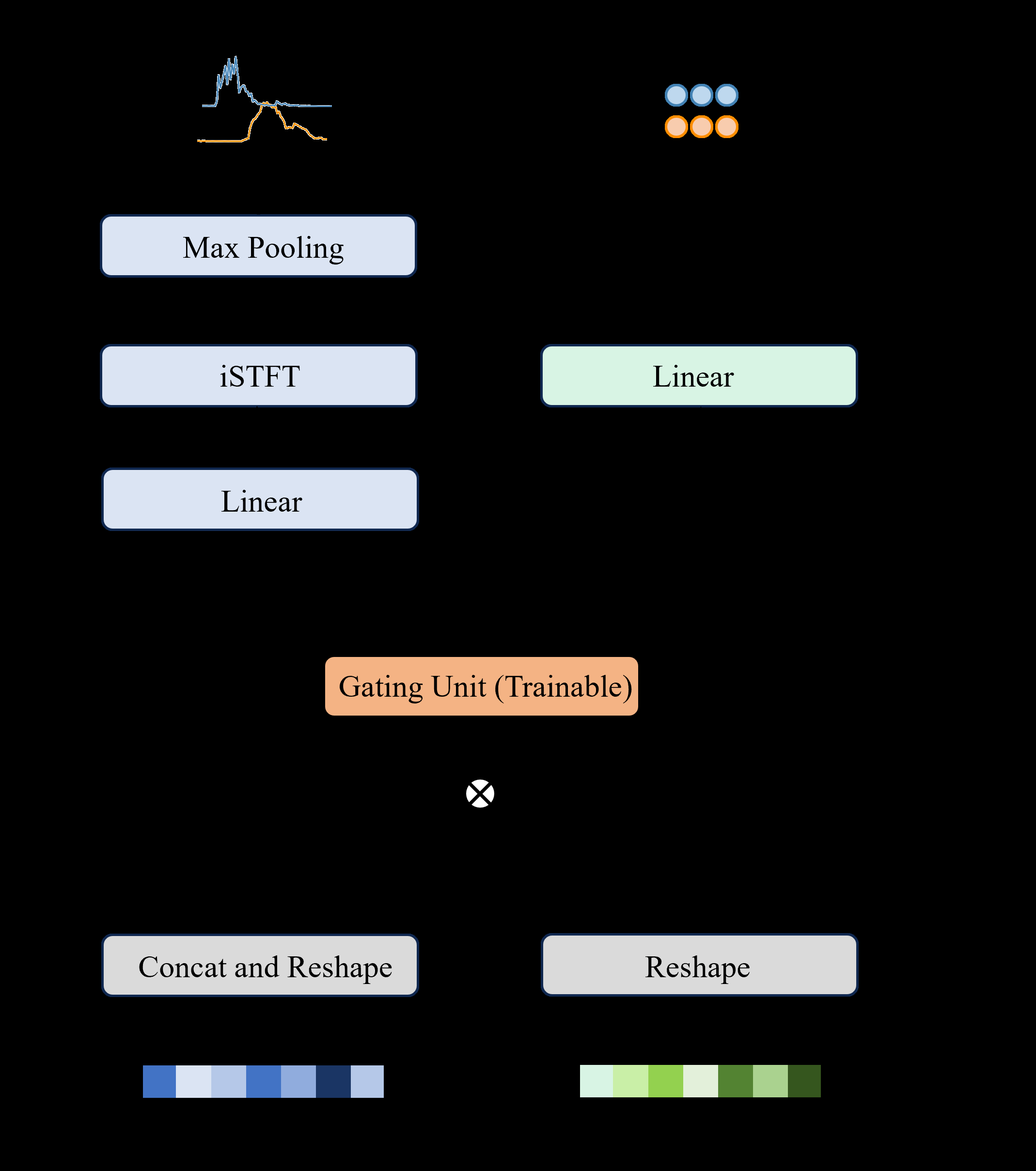
B_mix在时间维度平均并拼接,初始化单向LSTM的隐藏状态。通过循环解码,LSTM在每一步为一个潜在声源生成一个吸引子向量a_s。所有吸引子被拼接并通过全连接层+sigmoid预测每个声源的存在概率P_pred。解码循环直到第s+1个声源的概率低于阈值(τ=0.5)时停止,从而自适应确定声源数量S。 - 多任务学习模块(MTLM):如图3所示,该模块接收来自AAM的吸引子向量
A和来自AFEM的特征B_mix,通过矩阵乘法得到源特定的吸引子嵌入特征B_A。关键设计在于引入一个可学习的门控向量gate(在训练初期学习后固定)。- 包络分离分支:输入为
B_A * gate,通过全连接层、iSTFT和最大池化,预测每个声源的时域包络ê。 - 声源定位分支:输入为
B_A * (1 - gate),通过全连接层回归每个声源的3D笛卡尔坐标d̂,并计算距离。 - 联合优化:两个分支的损失通过PIT(排列不变训练)策略进行联合优化,找到最佳排列π以最小化联合损失
L_j,从而解决多源输出顺序匹配问题。最终总损失L为声源存在概率损失L_p和联合损失L_j的加权和。
- 包络分离分支:输入为
💡 核心创新点
- 包络分离辅助的多任务学习框架:创新性地将时域包络分离与3D声源定位作为两个相互辅助的任务进行联合优化。之前的吸引子方法(如SEET)通常将包络估计与定位视为独立、顺序的任务。该框架通过共享嵌入和联合损失,使时间(包络)和空间(坐标)信息能够相互增强,提升了多源场景下的性能。
- 自适应吸引子生成机制:基于LSTM解码器动态生成吸引子,并预测声源存在概率,从而摆脱了固定输出维度的限制,能灵活处理未知且可变的声源数量。这比基于阈值或固定轨迹数的方法更自适应。
- 门控式信息融合:在多任务学习模块中,引入了一个可学习的门控向量
gate,用于在共享的吸引子嵌入B_A上动态加权,分别强调用于包络分离和空间定位的不同信息特征。这种设计提供了模型在时间与空间信息利用上的灵活性。 - 端到端联合优化:模型将声源计数(通过BCE损失)和声源定位(通过联合PIT损失)统一在一个端到端的训练目标
L = L_p + αL_j下进行优化,简化了流程并实现了全局优化。
🔬 细节详述
- 训练数据:使用FSD50K数据集中的音频,结合gpuRIR工具箱模拟的房间脉冲响应生成FOA信号。房间尺寸从3x3x3 m³到10x10x6 m³均匀采样,混响时间T60在0.2-1.0s之间。麦克风阵列为Eigenmike。声源数量随机选择1-3个。共生成20,000个训练样本和4,000个测试/评估样本。
- 损失函数:
L_p:二元交叉熵损失,用于声源存在概率预测。L_j:联合损失,定义为所有排列π中,加权包络损失(λ * L_env)与坐标损失(L_xyz)之和的最小值。L_env:归一化的L2范数损失(见公式7),用于包络预测。L_xyz:L2范数损失(见公式8),用于3D坐标预测。- 总损失:
L = L_p + αL_j,其中α=1,λ=0.01。
- 训练策略:使用Adam优化器,学习率
1 × 10^-4,批次大小为2。最大训练轮数为200。门控向量gate在最初的3个训练周期内进行学习,之后固定。 - 关键超参数:吸引子解码的停止阈值
τ=0.5。损失权重α=1,λ=0.01。门控学习周期n=3。 - 训练硬件:论文中未说明具体的GPU型号、数量及训练时长。
- 推理细节:在推理时,AAM模块的LSTM解码循环持续进行,直到预测的第s+1个声源存在概率低于0.5,此时确定声源数量为s,并输出前s个声源对应的预测结果。
- 正则化技巧:未明确提及如Dropout、权重衰减等正则化技巧。联合损失中的PIT机制本身有助于解决排列歧义,可视为一种结构正则化。
📊 实验结果
实验在模拟的FOA数据集上进行,对比了EINV2、Sp-ACCDOA、SEET等基线方法,并进行了消融实验(w/o ESA vs w/ ESA)。
表1:盲源计数准确率(%)对比
| 模型 | 1个声源 | 2个声源 | 3个声源 | 平均值 |
|---|---|---|---|---|
| EINV2 | 97.7 | 2.74 | 100.0 | 66.4 |
| Sp-ACCDOA | 100.0 | 63.1 | 98.1 | 87.3 |
| SEET | 92.6 | 90.5 | 80.3 | 88.0 |
| ours (w/o ESA) | 96.0 | 80.5 | 86.2 | 87.8 |
| ours (w/ ESA) | 96.9 | 90.9 | 91.9 | 93.4 |
- 结论:本文方法在平均准确率上达到93.4%,优于所有基线。特别是在两个声源的挑战性场景下,准确率(90.9%)远高于Sp-ACCDOA(63.1%),也优于SEET(90.5%)和仅使用单任务回归的消融版本(80.5%)。消融实验证明ESA模块显著提升了计数性能。
表2:盲源定位误差对比
| 模型 | 方位角误差 (°) | 仰角误差 (°) | 距离误差 (m) | 相对距离误差 (%) |
|---|---|---|---|---|
| EINV2 | 86.07 | 35.97 | 2.47 | 62.41 |
| Sp-ACCDOA | 21.79 | 12.79 | 1.01 | 34.90 |
| SEET | 17.52 | 10.32 | 0.82 | 25.68 |
| ours (w/o ESA) | 16.31 | 10.09 | 0.75 | 26.69 |
| ours (w/ ESA) | 10.59 | 6.74 | 0.64 | 22.08 |
- 结论:本文方法(w/ ESA)在所有定位误差指标上均取得最佳结果。方位角误差降至10.59°,比最强基线SEET(17.52°)降低了约40%。消融实验显示,添加ESA模块使方位角误差从16.31°降至10.59°,相对距离误差从26.69%降至22.08%,验证了多任务学习对定位精度的提升。
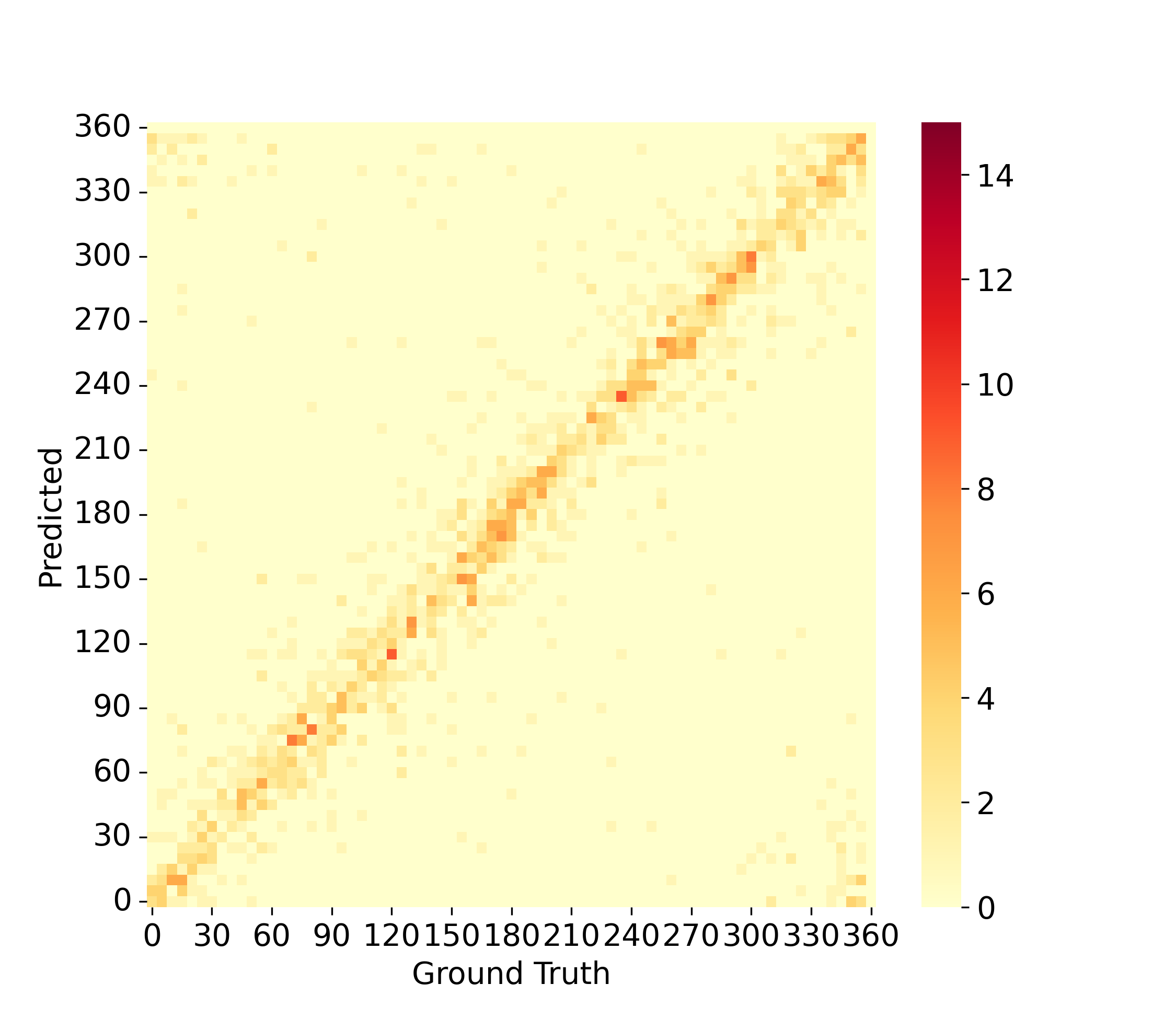
- 图4结论:热力图直观展示了不同方法在1-3个声源混合场景下的性能。本文模型(最后一列)的计数预测更准确,且定位结果围绕真实值形成更尖锐、集中的峰值,表明其精度和鲁棒性更优。
- 图5结论:t-SNE可视化显示,不同声源的吸引子在高维嵌入空间中形成了清晰分离的聚类,证明了自适应吸引子模块能够有效地区分不同声源。
⚖️ 评分理由
- 学术质量:5.5/7 - 论文技术方案完整,从特征提取、声源数估计到联合多任务学习,逻辑链条清晰。实验设计包含了与多种基线的对比和充分的消融分析,验证了核心思想。然而,创新主要在于对已有模块(吸引子网络、多任务学习、PIT)的巧妙组合与优化,而非提出突破性的新理论或新架构。实验环境为模拟数据,其真实世界泛化能力存疑。
- 选题价值:1.0/2 - 声源计数与定位是音频信号处理的基础性挑战任务,在机器人听觉、人机交互等领域有明确应用需求。但该问题本身较为垂直,对于更广泛的音频/语音处理社区,其选题的前沿性和普适影响力可能低于语音识别、生成或理解等大热点。
- 开源与复现加成:0.0/1 - 论文提供了基本的实验设置和关键超参数,这有利于部分复现。但未提供代码、训练好的模型、数据生成脚本或详细的训练日志。核心的模拟数据生成(依赖gpuRIR和FSD50K)需要额外配置,复现门槛较高。因此,开源与复现加成项为0。