📄 An End-to-End Multimodal System for Subtitle Recognition and Chinese-Japanese Translation in Short Dramas
#多模态模型 #端到端 #语音识别 #机器翻译
✅ 7.0/10 | 前50% | #多模态模型 | #端到端 | #语音识别 #机器翻译
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 中
👥 作者与机构
- 第一作者:Jing An (北京第二外国语学院人工智能与语言科学学院)
- 通讯作者:Yanbing Bai (中国人民大学统计学院应用统计研究中心)
- 作者列表:Jing An (北京第二外国语学院人工智能与语言科学学院)、Haofei Chang (中国人民大学信息学院)、Rui-Yang Ju (京都大学信息学研究生院)、Jinhua Su (中国人民大学统计学院应用统计中心 & Simashuhui Ltd.)、Yanbing Bai (中国人民大学统计学院应用统计研究中心)、Xin Qu (北京第二外国语学院人工智能与语言科学学院)
💡 毒舌点评
亮点:系统设计思路清晰务实,将OCR和ASR两条路径的结果通过简单有效的融合策略进行互补,直接解决了短剧字幕识别中“文字准”与“时间准”难以兼得的痛点。
短板:论文最大的弱点在于“端到端”的宣称与实验的割裂——虽然架构图展示了从视频到日语字幕的流水线,但实验部分的“识别”和“翻译”模块是分开评估的,缺乏对整个系统在端到端指标上的验证;同时,构建的翻译数据集规模极小(仅79集短剧),其泛化能力存疑。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开微调后的模型权重或检查点。
- 数据集:论文构建并描述了一个短剧数据集,但未提及是否公开或如何获取。
- Demo:未提供在线演示。
- 复现材料:论文给出了翻译模块微调的详细超参数(LoRA r/α,学习率,batch size,早停策略等),但对识别模块的融合策略参数(时间窗口、相似度阈值)的选择依据和搜索过程未作说明。提供了硬件型号(RTX 3090),但未提及训练时长。
- 引用的开源项目:论文明确依赖以下开源模型/工具:
- Qwen2-VL:用于OCR。
- Whisper:用于ASR。
- Qwen2.5:作为翻译模块的基线及微调基础。
- LoRA:用于高效微调。
- RapidFuzz:用于计算文本相似度。
📌 核心摘要
本文针对中国短剧出海所面临的字幕识别与中日翻译难题,提出了一个端到端的多模态系统。问题核心在于短剧字幕具有口语化、无标点、片段化、上下文缺失等特殊性,且识别过程需同时应对复杂画面和背景噪音。方法核心是采用双通道并行识别:视觉通道使用Qwen2-VL进行OCR提取帧内文字,音频通道使用Whisper进行ASR转写,并设计了一种基于时间对齐和文本相似度的融合策略来选择最优结果。随后,通过LoRA微调Qwen2.5模型,在自建的短剧数据集上进行中日翻译。与已有方法相比,该系统的新颖之处在于其多模态融合策略能有效结合OCR的高精度专有名词识别与ASR的流畅性和精准时间戳,同时采用了将整集字幕作为整体输入LLM进行翻译的策略,以保留上下文。主要实验结果显示,融合策略在字幕识别任务上(表1)优于单独的Qwen2-VL和Whisper(CER从0.2984/0.2491降至0.1598);微调后的翻译模型(表2)在chrF++和COMET指标上也优于零样本Qwen2.5基线。该工作的实际意义在于为短剧这一新兴内容的本地化提供了一套可落地的技术方案。其主要局限性在于翻译数据集规模较小,且系统各模块(识别、融合、翻译)是独立评估,未对完整端到端流程进行一体化性能测试与优化。
表1:字幕识别性能比较
| 模型 | CER↓ | Accuracy↑ | BLEU↑ | chrF++↑ |
|---|---|---|---|---|
| Qwen2-VL [10] | 0.2984 | 0.9216 | 72.3279 | 70.4881 |
| Whisper [11] | 0.2491 | 0.7819 | 81.2538 | 57.5461 |
| Ours | 0.1598 | 0.9174 | 85.5974 | 77.963 |
表2:字幕翻译性能比较(五折交叉验证)
| 模型 | BLEU↑ | chrF++↑ | COMET↑ |
|---|---|---|---|
| Qwen2.5 [13] | 9.7665 | 27.8855 | 0.6160 |
| Ours* | 9.8440 | 29.9883 | 0.6437 |
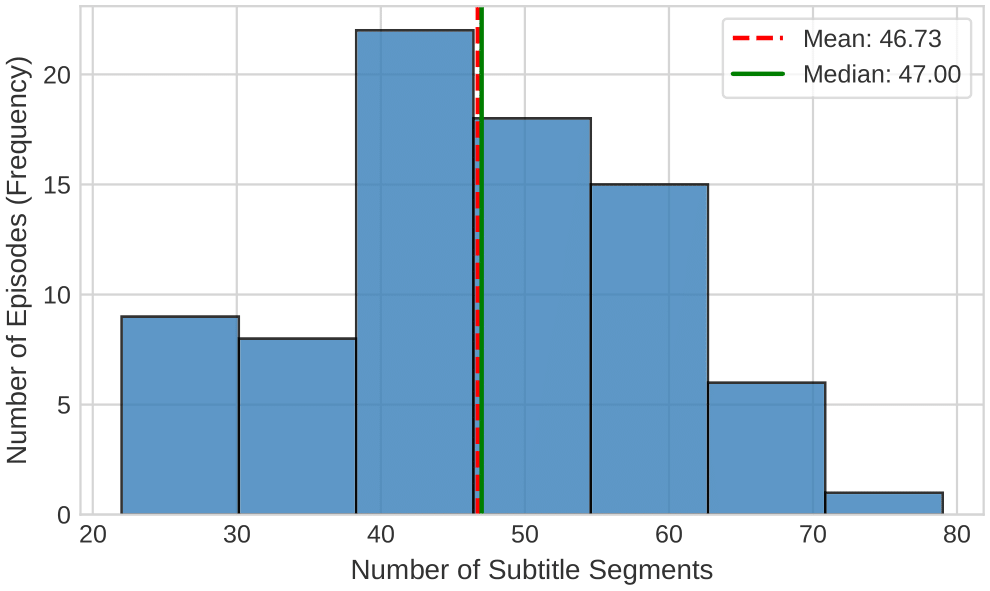 图2描述了自建数据集中,各集短剧包含的字幕片段(subtitle segments)数量的分布情况。图中显示,大多数集的字幕片段数量在40到60之间,但有部分集(如第35、62集)包含的字幕片段数量显著偏多(超过80),表明不同剧集间的字幕密度存在差异。
图2描述了自建数据集中,各集短剧包含的字幕片段(subtitle segments)数量的分布情况。图中显示,大多数集的字幕片段数量在40到60之间,但有部分集(如第35、62集)包含的字幕片段数量显著偏多(超过80),表明不同剧集间的字幕密度存在差异。
🏗️ 模型架构
论文提出的端到端多模态系统架构如图1所示,主要由字幕识别模块和翻译模块两部分串联构成。
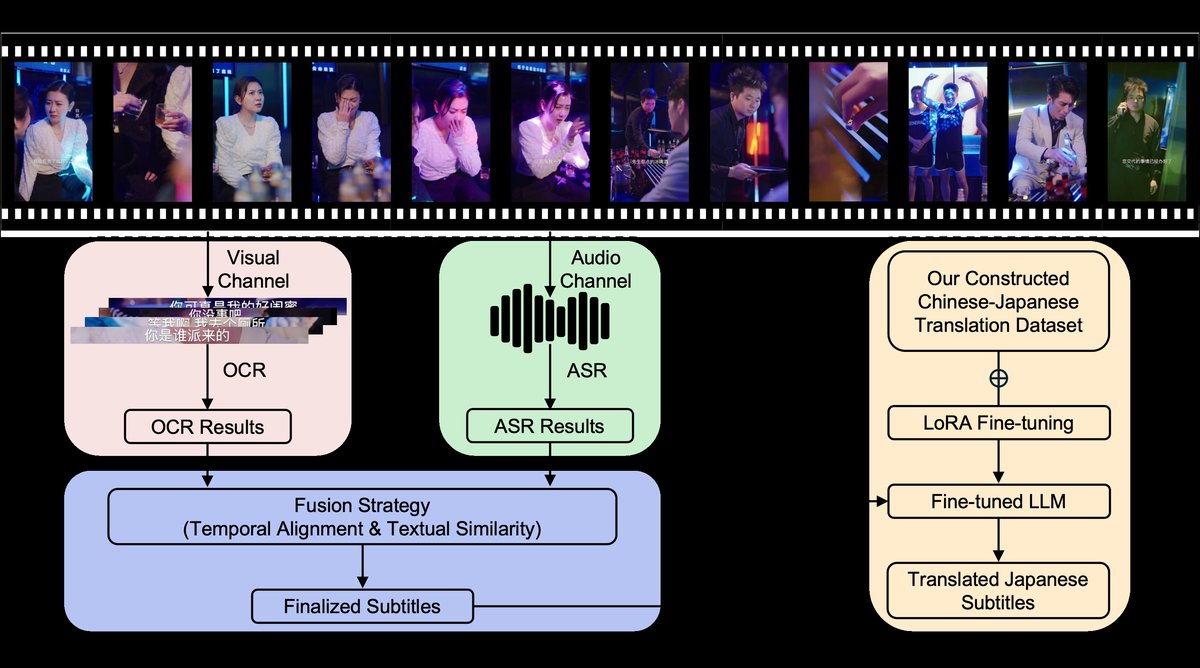 图1展示了系统的整体工作流程:输入短剧视频后,系统并行进行视觉和音频处理。视觉通道以1秒间隔采样帧,送入Qwen2-VL进行OCR;音频通道将整条音轨送入Whisper进行ASR。两个通道的输出(带时间戳的文字片段)进入“多模态融合”模块,该模块以Whisper的时间戳为主锚点,通过时间窗口匹配和文本相似度比较,决定最终采用OCR文本还是ASR文本,并保留Whisper的时间戳。最终,得到准确且时间对齐的中文子幕序列,作为“翻译模块”(基于LoRA微调的Qwen2.5)的输入,生成日文字幕。
图1展示了系统的整体工作流程:输入短剧视频后,系统并行进行视觉和音频处理。视觉通道以1秒间隔采样帧,送入Qwen2-VL进行OCR;音频通道将整条音轨送入Whisper进行ASR。两个通道的输出(带时间戳的文字片段)进入“多模态融合”模块,该模块以Whisper的时间戳为主锚点,通过时间窗口匹配和文本相似度比较,决定最终采用OCR文本还是ASR文本,并保留Whisper的时间戳。最终,得到准确且时间对齐的中文子幕序列,作为“翻译模块”(基于LoRA微调的Qwen2.5)的输入,生成日文字幕。
视觉通道(OCR):
- 输入:输入视频文件。
- 组件:采样器(以1.0秒间隔提取视频帧)-> Qwen2-VL模型(处理每一帧图像,执行OCR任务,输出文本及其在画面中的位置信息)-> 缓存机制(避免重复计算)。
- 输出:一系列带时间戳的OCR文本片段(每个采样帧一个片段)。
音频通道(ASR):
- 输入:同一输入视频文件的音轨。
- 组件:Whisper模型(处理整条音频,执行ASR任务)。
- 输出:一系列带精确开始和结束时间戳的转录文本片段。
多模态融合模块:
- 功能:整合OCR和ASR的结果,产出最终的高质量中文子幕。
- 关键策略:
- 以Whisper输出的时间戳文本为主锚点。
- 对于每个Whisper片段,设定一个1.5秒的容差时间窗口,寻找该窗口内所有Qwen2-VL的OCR结果。
- 使用RapidFuzz库的
ratio算法计算每个候选OCR文本与Whisper文本之间的编辑距离相似度。 - 若最高相似度超过60%,则采用该Qwen2-VL文本替换Whisper文本,但保留原始Whisper的时间戳。
- 若无满足阈值的OCR结果,则保留原始Whisper片段。
- 动机与效果:此策略旨在利用OCR对视觉呈现文字(特别是专有名词)的高识别精度,同时依赖ASR在时间对齐和转写流畅性上的优势,实现优势互补。
翻译模块:
- 输入:融合模块输出的、时间对齐的中文子幕序列。
- 组件:基于LoRA微调的Qwen2.5-3B模型。系统将整集短剧的字幕序列作为一个整体输入模型,进行翻译。
- 输出:对应的日文字幕序列。
💡 核心创新点
基于互补性的多模态字幕识别融合策略:
- 是什么:一种规则化的决策策略,将OCR(视觉)和ASR(音频)两个通道的识别结果进行融合。
- 之前局限:单独使用OCR可能因背景干扰或非字幕文字而误识别;单独使用ASR可能在人名、地名等专有名词上转写错误,且时间戳虽准但文本可能不完整。
- 如何起作用:通过时间窗口对齐确保内容相关性,通过文本相似度阈值判断OCR是否可靠地识别了更准确的文本。若可靠,则采用OCR文本并借ASR时间戳;否则用ASR文本。
- 收益:在表1的实验中,该策略在字符错误率(CER)上大幅超越两个独立基线(0.1598 vs 0.2984/0.2491),同时BLEU和chrF++指标也达到最优,证明了其有效性。
面向短剧的端到端系统设计与翻译范式:
- 是什么:设计了一个从视频输入到目标语言字幕输出的完整流水线,并在翻译阶段采用将“整集字幕”作为上下文输入LLM的策略。
- 之前局限:传统方法常单独处理每个片段,导致翻译缺乏上下文连贯性(如代词指代、对话流)。
- 如何起作用:系统先确保识别出高质量、时间对齐的中文子幕;然后利用LLM的强大上下文理解能力,将整集字幕输入进行翻译,以保留叙事连贯性。
- 收益:该设计更贴合实际生产流程。翻译实验(表2)表明,基于此范式微调后的模型在所有指标上优于零样本基线。
构建短剧领域的中日翻译数据集:
- 是什么:从一个完整商用短剧中构建了包含79集、3692个片段的中日字幕对数据集。
- 之前局限:公开的多模态或字幕翻译数据集可能不专门针对短剧这种口语化、碎片化的场景。
- 如何起作用:提供了领域内数据,用于微调翻译模型,使其学习短剧特有的语言模式(如口语表达、无标点、短句)。
- 收益:微调后的模型在chrF++上提升了约7.5%,COMET提升了4.5%,证明了领域数据微调的有效性。
🔬 细节详述
- 训练数据:
- 翻译数据集:论文自建。来源为一家商业娱乐公司提供的完整中文短剧。包含79集,每集有视频文件(.mp4)、带说话人ID的中文字幕(.srt)和人工翻译的日文字幕(.txt)。总时长130.56分钟,共3692个字幕片段。中文和日文字幕均由母语研究者人工标注和翻译,以保证质量。
- 识别模块:未说明使用何种数据集进行训练或评估。从上下文推测,实验可能直接使用了短剧视频和人工标注的字幕作为ground truth进行评测。
- 损失函数:未提及具体的损失函数。翻译任务微调通常使用语言模型的交叉熵损失。
- 训练策略(针对翻译模块微调):
- 优化器:未说明。
- 学习率:2 × 10⁻⁴。
- Batch size:4。
- 梯度累积步数:4(等效batch size为16)。
- 训练轮数:10 epochs,并采用早停策略(耐心值为3个epoch)。
- 数据划分:五折分层随机划分交叉验证。
- 微调方法:LoRA。秩(r)=16,缩放因子(α)=32。
- 关键超参数:
- 模型大小:识别模块使用Qwen2-VL-2B和Whisper-medium;翻译模块基线及微调使用Qwen2.5-3B。
- 融合策略参数:时间窗口容差1.5秒,文本相似度阈值60%。
- LoRA参数:r=16, α=32。
- 量化:翻译模块微调使用4位量化。
- 训练硬件:所有实验在NVIDIA GeForce RTX 3090 GPU上进行。计算资源来自华为云AI算力服务。
- 推理细节:未提及解码策略(如beam search)、温度等具体推理参数。
- 正则化/稳定训练:使用了早停(patience=3)以防止过拟合。
📊 实验结果
论文在两个子任务上进行了定量评估。
字幕识别性能对比(表1):
| 模型 | CER↓ | Accuracy↑ | BLEU↑ | chrF++↑ |
|---|---|---|---|---|
| Qwen2-VL [10] | 0.2984 | 0.9216 | 72.3279 | 70.4881 |
| Whisper [11] | 0.2491 | 0.7819 | 81.2538 | 57.5461 |
| Ours | 0.1598 | 0.9174 | 85.5974 | 77.963 |
关键结论:本文提出的融合模型在所有四个指标上均取得了最佳或次佳成绩。尤其是在CER(字符错误率)上,相较于两个强基线有显著降低,证明了融合策略在提升识别准确性方面的有效性。Accuracy略低于Qwen2-VL,但结合CER的巨大改善,表明整体文本质量更高。
字幕翻译性能对比(表2,五折交叉验证):
| 模型 | BLEU↑ | chrF++↑ | COMET↑ |
|---|---|---|---|
| Qwen2.5 [13] (零样本) | 9.7665 | 27.8855 | 0.6160 |
| Ours* (微调) | 9.8440 | 29.9883 | 0.6437 |
关键结论:在自建的短剧数据集上,经过LoRA微调的模型在所有三项指标上均优于零样本Qwen2.5基线。其中,chrF++提升了2.1028(相对提升约7.5%),COMET提升了0.0277(相对提升约4.5%),表明微调有效提升了模型在该领域任务上的翻译质量。
数据集特征分析(图2):
图2展示了数据集中每集短剧所含字幕片段的数量分布。横轴为集数,纵轴为片段数。分布显示,大部分剧集的字幕片段数集中在40-60区间,但存在明显波动,例如第35集和第62集超过80个片段,而第68集不足20个。这种波动反映了不同剧集剧情节奏和对白密度的差异,也说明了该数据集具有一定的多样性。
⚖️ 评分理由
学术质量:5.0/7
创新性:系统集成思路清晰,融合策略简单有效,但创新主要体现在工程整合与特定领域应用,核心算法(如LLM微调、融合规则)并非全新。技术正确性:方法描述清晰,实验设计基本合理(如使用标准指标、交叉验证)。实验充分性:对比了强基线,有定量结果。但存在明显不足:1) 缺乏对融合策略中关键参数(如时间窗口、相似度阈值)的消融实验;2) 缺乏端到端系统评测(例如,直接比较“本系统输出日文字幕”与“人工日文字幕”);3) 翻译数据集规模较小(79集),评估的泛化性存疑。证据可信度:结果可复现,但数据集未公开,部分细节(如识别任务的具体数据集)未说明。选题价值:1.5/2
前沿性与影响:短剧出海是当前产业热点,解决其字幕本地化痛点具有明确的现实需求和应用价值。与读者相关性:对从事音视频处理、机器翻译、多模态AI在文娱领域应用的研究者和工程师有直接参考��值。开源与复现加成:0.3/1
论文未提供代码、模型权重或训练好的检查点。提供了自建数据集的详细统计描述,但未公开数据集本身。给出了翻译模块微调的详细超参数(学习率、batch size、LoRA设置等),但缺乏识别模块融合策略的具体参数选择依据以及完整的训练配置。部分细节如优化器、损失函数、完整训练硬件配置(如CPU、内存)未说明。