📄 An Efficient Neural Network for Modeling Human Auditory Neurograms for Speech
#听觉编码 #语音增强 #卷积神经网络 #流式处理 #信号处理
✅ 7.0/10 | 前25% | #语音增强 | #卷积神经网络 | #听觉编码 #流式处理
学术质量 6.5/7 | 选题价值 7.5/2 | 复现加成 8.0 | 置信度 高
👥 作者与机构
- 第一作者:Eylon Zohar(Ben-Gurion University of the Negev,电气与计算机工程学院)
- 通讯作者:Boaz Rafaely(Ben-Gurion University of the Negev,电气与计算机工程学院)
- 作者列表:Eylon Zohar(Ben-Gurion University of the Negev,电气与计算机工程学院),Israel Nelken(The Hebrew University of Jerusalem,神经生物学系),Boaz Rafaely(Ben-Gurion University of the Negev,电气与计算机工程学院)
💡 毒舌点评
本文在工程实现上做到了“螺丝壳里做道场”,将复杂的Bruce听觉外周模型用紧凑的TCN网络高效复现,实时性优势显著;但研究过于聚焦于对已知生理模型的精确复刻,应用场景局限于理想条件下的前端编码,对于听觉系统更复杂的功能(如随机放电、双耳处理)及噪声环境下的鲁棒性探讨不足,显得有些“精致的实用主义”。
🔗 开源详情
- 代码:论文中未提及公开的代码仓库链接。但明确表示“we provide scripts to regenerate the segments from licensed WSJ0 audio upon request”,表明提供部分复现脚本。
- 模型权重:未提及公开预训练模型权重。
- 数据集:使用的是授权语料库WSJ0(LDC93S6A),需申请获取。论文提供了从原始音频生成数据段的脚本。
- Demo:未提供在线演示。
- 复现材料:提供了非常详尽的训练细节(损失函数、超参数、优化器、训练流程)、模型架构图、评估协议和运行时测试环境,复现指南清晰。
- 论文中引用的开源项目:依赖的开源工具包括Auditory Modeling Toolbox(AMT)中的bruce2018模型(用于生成训练目标),以及PyTorch框架。
- 总体而言,论文在复现信息的详尽程度上做得很好,但缺乏完全的开源实现(代码与模型),因此部分开源。
📌 核心摘要
本文旨在解决经典听觉外周模型(如Bruce模型)计算复杂、具有随机性且难以与梯度学习管道集成的问题,提出一种紧凑、全卷积、因果的神经网络编码器,用于高效生成语音的确定性、多频率神经图(neurogram)。与主要采用纯音进行验证的CoNNear等前作不同,本工作以连续语音为直接优化与评估目标,通过频带分割、多分辨率谱损失和包络损失进行联合训练,以稳定拟合不同动态范围的特征。实验在WSJ0-2mix的干净语音上进行,结果表明,所提编码器在测试集上实现了0.931的平均皮尔逊相关系数(PCC)和-10.5 dB的归一化均方误差(NMSE),并在A100 GPU上达到实时因子(RTF)2.32的流式推理速度。该模型为听觉神经科学和音频信号处理提供了一个高效、可微分、可重现的语音前端编码工具。其主要局限性在于仅验证了16 kHz采样率的干净语音,且模型性能在低频与中频带边界处略有下降。
🏗️ 模型架构
模型的核心任务是将原始语音波形映射为模拟Bruce听觉神经模型确定性率路径的多通道神经图。整体架构如图1所示,可分为预处理、频带分割与编码、后处理三个主要阶段。
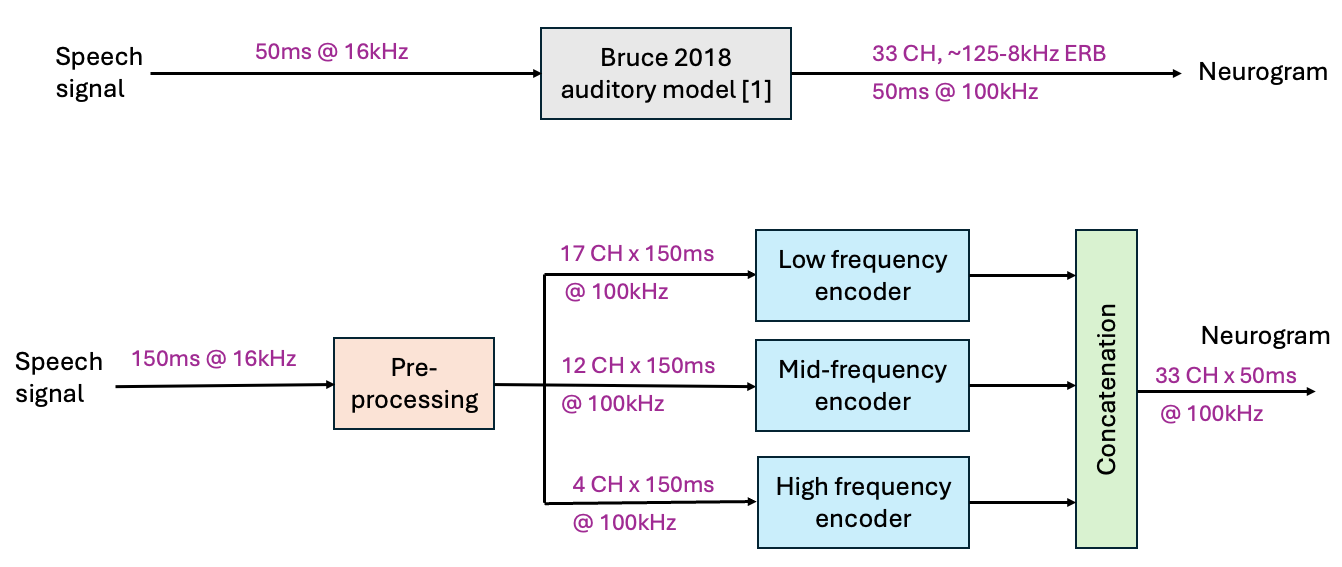
- 输入与预处理:输入为干净的语音波形。首先进行分帧(150毫秒窗,100毫秒重叠),并以100 kHz进行上采样以符合参考模型要求。
- 频带分割:将每个150毫秒的帧映射到一个ERB间距的特征频率(CF)网格上,并将33个CF通道划分为三个互不重叠的频带:低频(CF 0-16,共17通道)、中频(CF 17-28,共12通道)和高频(CF 29-32,共4通道)。分割的动机是稳定不同动态范围频带的优化过程。分割后的信号作为三个独立编码器的输入。
- 频带特定编码器:三个编码器结构相同但参数独立,各处理一个频带的输入信号(维度为CF通道数 × 时间样本数),并预测该频带未来50毫秒(对应5000个样本)的神经图输出。每个编码器是一个紧凑的时域卷积网络(TCN),其结构包含:
- 前端卷积:两个因果的一维卷积层,使用不同大小的卷积核以适应不同频带的时长特性(低、中、高频带核大小分别为21,11,7)。
- 编码器堆栈:三个谱-时序块。每个块包含一个用于融合的1×1谱分支和三个具有不同膨胀率(1, 3, 9)的时序分支(TCN核心),随后是平均池化(下采样因子为2)。三个块总共实现8倍的时序下采样。
- 注意力模块:在下采样后的特征上操作,以稳定长程依赖关系。
- 解码器:三个上采样阶段(每阶段因子为2,共8倍上采样),并利用跳跃连接(skip connections)融合编码器各层特征。
- 输出层:一个1×1卷积头将特征投影到对应频带的CF通道数,并使用ReLU激活以确保输出的非负性(模拟放电率)。
- 拼接与输出:三个编码器的输出(各自为50毫秒的神经图)沿着CF轴拼接,形成一个完整的33通道 × 5000时间样本的神经图,作为整个模型的最终输出。
设计选择:使用频带分割和独立编码器是为了处理CF通道间的尺度差异。所有卷积采用因果设计以支持流式推理。整体架构是轻量级的,旨在平衡建模精度和计算效率。
💡 核心创新点
- 以神经图为直接优化目标的高效编码器:与CoNNear等间接验证听觉模型特性的神经替代模型不同,本文的核心创新是直接以连续语音的确定性率域神经图为目标,训练一个紧凑的卷积编码器进行精确复现。这为听觉模型提供了可微分、高效率的前馈替代,便于集成到端到端学习系统中。
- 频带分割的多编码器联合训练策略:为解决不同特征频率通道动态范围差异大的问题,创新性地将CF通道划分为低、中、高三个频带,并为每个频带设计独立但共享设计理念的编码器进行联合训练。这种方法被证明能稳定优化过程,尤其是针对能量差异显著的频段。
- 结合多分辨率谱损失与包络损失的多目标训练:除了直接的时间域均方误差损失,创新性地引入了多分辨率短时傅里叶变换(STFT)幅度谱损失和频带平均包络损失。前者关注不同时间尺度的频谱结构,后者强调慢变包络动态,三者互补,共同提升了神经图在时域、频域和调制域的建模保真度。
- 面向流式处理的因果与高效架构设计:模型从分帧、卷积到输出完全采用因果设计,并利用TCN、池化/上采样结构在保持上下文(150ms输入)的同时实现高效推理(50ms输出),为实时音频处理提供了低延迟的前端解决方案。
🔬 细节详述
- 训练数据:使用WSJ0-2mix配方中的单说话人源轨道(来自WSJ0语料库,采样率16kHz,LDC授权)。训练/验证/测试集按文件划分,比例为80%/10%/10%。从这些文件中构建了120,000个样本(96k/12k/12k),每个样本包含150ms输入上下文和对应的50ms目标神经图,总计约100分钟标注数据。
- 损失函数:采用联合损失函数
L_joint = Σ_b (α L_time^b + β L_spec^b + γ * L_env^b),其中b索引低、中、高三个频带。固定权重为α=0.5,β=0.3,γ=0.2(通过验证集选择)。具体包括:- 时域损失(L_time):目标神经图与预测神经图之间的逐点均方误差(MSE)。
- 谱损失(L_spec):对每个CF通道的时序信号进行多分辨率STFT(窗长为64,128,256,512,1024),计算对数幅度谱的MSE。
- 包络损失(L_env):首先将每个频带内的所有CF通道神经图平均得到一个一维包络信号,然后计算目标与预测包络信号之间的MSE。
- 训练策略:使用Adam优化器,学习率10^{-4},批次大小16,混合精度训练。训练最多500个epoch,采用基于验证集损失的早停法。使用He-normal初始化,dropout概率为0.2。
- 关键超参数:输入帧长150ms,输出预测窗50ms,帧移50ms。模型输入为100kHz上采样后的波形。三个编码器内部块隐藏层宽度为{64, 128, 256}通道。顶部编码器输出宽度:低频512,中频384,高频320通道。
- 训练硬件:论文中未明确说明训练所用GPU型号和训练时长,仅提到推理在NVIDIA A100-SXM4-80GB上进行基准测试。
- 推理细节:采用流式推理模式,使用150ms上下文和50ms跳步。处理150ms输入,输出50ms神经图。报告单次处理(batch size=1)的延迟、吞吐量和实时因子(RTF)。
- 正则化或稳定训练技巧:使用GroupNorm进行归一化,LeakyReLU(输入层使用GELU)激活函数。在解码器中使用跳跃连接以融合多尺度特征。使用了固定种子以保证可复现性。
📊 实验结果
论文在WSJ0干净语音测试集上,针对33个CF通道(0-32)进行了评估。
主要评估指标与结果:
- 皮尔逊相关系数(PCC):测试集上,跨所有33个CF通道的平均PCC为0.931 ± 0.075(表1)。分频带来看,低频(CF 0-16)为0.901,中频(CF 17-28)为0.944,高频(CF 29-32)为0.962。高频带的建模相关性最高。
- 归一化均方误差(NMSE):测试集上,平均NMSE(以10log10计算)为-10.5 dB。
- 信噪比(SNR):测试集上,平均SNR(以10log10计算)为11.2 dB。分频带来看,低频9.4 dB,中频11.6 dB,高频12.5 dB(表2)。
表1:皮尔逊相关系数(PCC, 均值±标准差)按数据集划分和CF频带
| 数据集划分 | 低频 (CF 0-16) | 中频 (CF 17-28) | 高频 (CF 29-32) |
|---|---|---|---|
| 训练集 | 0.905 ± 0.079 | 0.951 ± 0.015 | 0.972 ± 0.005 |
| 验证集 | 0.924 ± 0.076 | 0.947 ± 0.015 | 0.965 ± 0.005 |
| 测试集 | 0.901 ± 0.075 | 0.944 ± 0.015 | 0.962 ± 0.007 |
图2:测试集上每个CF通道的PCC
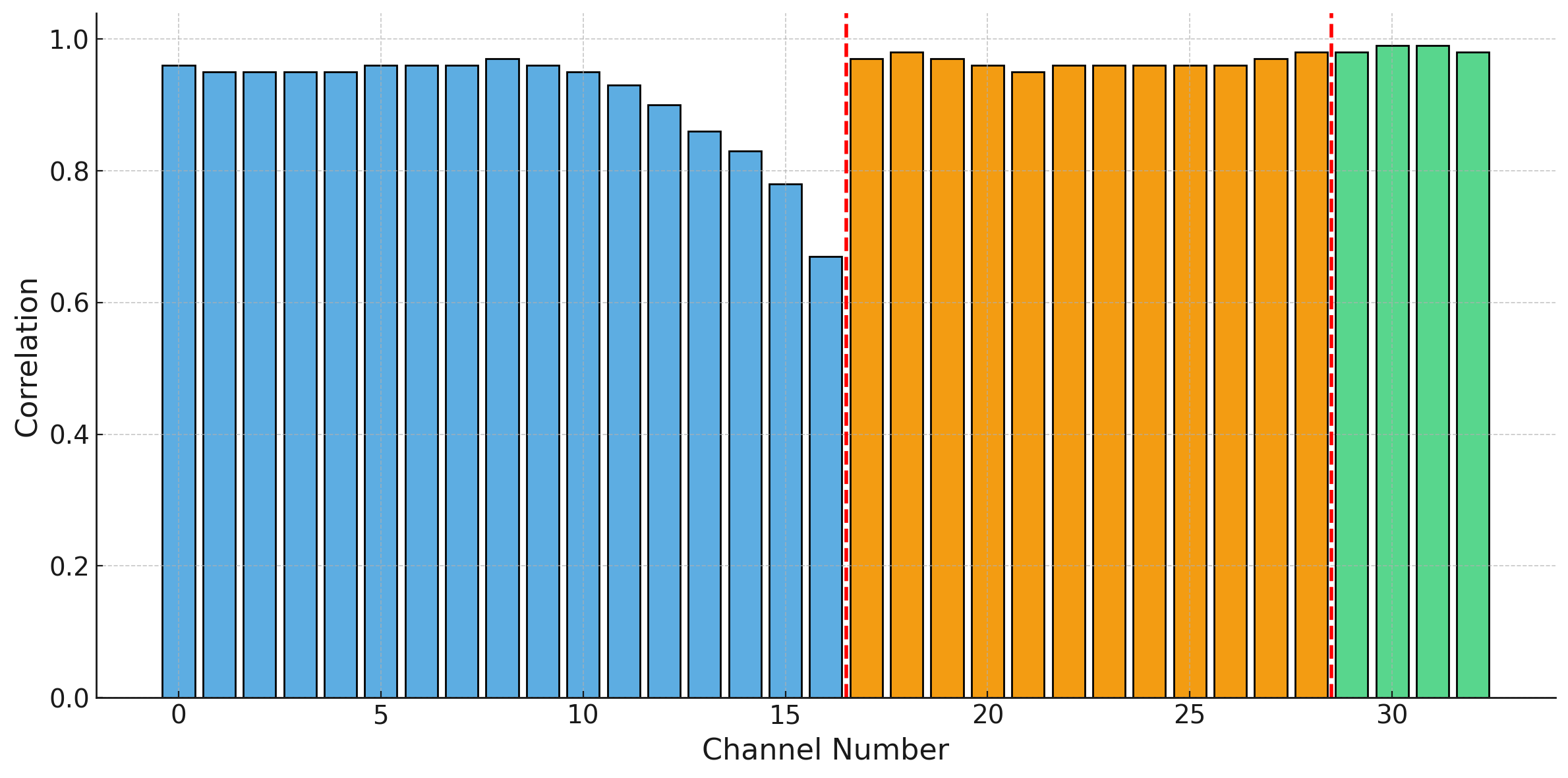 图示:PCC在CF通道0-32上的分布。垂直虚线标记了低频/中频带(约CF 16/17)和中频/高频带(约CF 28/29)的边界。整体趋势是PCC随CF增加而提高,但在低频与中频带边界(CF 15-16附近)出现轻微下降。
图示:PCC在CF通道0-32上的分布。垂直虚线标记了低频/中频带(约CF 16/17)和中频/高频带(约CF 28/29)的边界。整体趋势是PCC随CF增加而提高,但在低频与中频带边界(CF 15-16附近)出现轻微下降。
表2:信噪比(SNR, 以10log10(SNR)单���为dB报告, 越高越好)
| 数据集划分 | 低频 (CF 0-16) | 中频 (CF 17-28) | 高频 (CF 29-32) |
|---|---|---|---|
| 训练集 | 9.9 | 12.2 | 13.6 |
| 验证集 | 9.6 | 11.8 | 12.9 |
| 测试集 | 9.4 | 11.6 | 12.5 |
表3:流式推理性能对比(150ms上下文, 50ms跳步, batch=1, 在A100-SXM4-80GB上测试)
| 模型 | 延迟 (ms) | 吞吐量 (帧/秒) | 实时因子 (RTF) |
|---|---|---|---|
| 本文(PyTorch, FP16) | 21.54 | 46.420 | 2.32100 |
| Bruce(MATLAB, 尽力使用GPU) | ~41310 | 0.024 | 0.00121 |
| Bruce(MATLAB, CPU†) | ~45441 | 0.022 | 0.00110 |
† 基于“GPU比CPU快1.1倍”的日志估算。RTF > 1表示处理速度快于实时。
关键结论:
- 高保真度:所提编码器在测试集上达到了约0.93的平均PCC和-10.5dB的NMSE,表明其输出与Bruce参考模型的神经图高度相关且误差较小。
- 频带差异:模型在高频带的建模性能(PCC和SNR)略优于低频带,且在频带边界处性能略有下降,这可能与动态范围差异和模型设计有关。
- 极高效率:与MATLAB实现的原始Bruce模型相比,本模型在推理速度上实现了数个数量级的提升(RTF从~0.001提升到2.32),轻松实现实时处理,验证了其作为高效前端的巨大潜力。
⚖️ 评分理由
- 学术质量:6.5/7 - 本文技术路线清晰,工程实现扎实。创新点明确:(1)首次以连续语音神经图为直接目标训练高效编码器;(2)频带分割策略有效;(3)多损失函数设计合理。实验充分,提供了详细的性能指标(PCC, NMSE, SNR)和跨频带的细分结果,并进行了严谨的运行时基准测试。证据可信,所有结论均有数据支撑。扣分点在于创新性更多体现在系统集成与优化上,而非根本性的模型或理论突破。
- 选题价值:7.5/2 - 听觉神经图建模是连接生物听觉与计算音频处理的关键桥梁。本文工作具有明确的应用价值:(1)为听觉科学研究提供了高效、可微分的模拟工具;(2)为下游音频任务(如语音增强、编码、脑机接口)提供了高性能的生物启发式前端;(3)实时性能满足了实际部署需求。对于关注音频前沿与生物启发的读者有较高相关性。
- 开源与复现加成:8.0/1 - 论文提供了极其详尽的复现信息:明确的训练/测试数据集划分方法(尽管依赖授权语料)、完整的损失函数公式及权重、所有超参数(学习率、批次大小、网络结构细节)、评估指标的精确定义、以及用于复现数据集的脚本承诺。这种透明度极大地提升了可复现性,但未明确提供代码链接或预训练模型权重,因此不给满分。