📄 An Audio-Visual Speech Separation Network with Joint Cross-Attention and Iterative Modeling
#语音分离 #注意力机制 #迭代建模 #音视频 #时频分析
✅ 7.5/10 | 前25% | #语音分离 | #注意力机制 | #迭代建模 #音视频
学术质量 0.8/7 | 选题价值 0.7/2 | 复现加成 0.8 | 置信度 高
👥 作者与机构
- 第一作者:Fangxu Chen(新疆大学计算机科学与技术学院, 同时隶属于丝路多语种认知计算联合国际研究实验室)
- 通讯作者:Ying Hu(新疆大学计算机科学与技术学院, 同时隶属于丝路多语种认知计算联合国际研究实验室)
- 作者列表:Fangxu Chen(新疆大学计算机科学与技术学院)、Ying Hu(新疆大学计算机科学与技术学院)、Zhijian Ou(清华大学电机工程与应用电子技术系)、Hexin Liu(南洋理工大学电气与电子工程学院)
💡 毒舌点评
亮点在于提出的JCA模块和参数共享的迭代分离模块,成功地在提升分离性能(在多个数据集上取得SOTA)的同时,将模型参数量和推理时间(RTF)控制在极低水平(JCA-Net-4的RTF仅为0.021秒),展现了优秀的效率-性能权衡。短板在于实验评估主要基于标准学术数据集,论文未探讨模型在更极端噪声(如非平稳噪声、强混响)、说话人数量多于2人或跨语言场景下的鲁棒性,其实际应用的泛化能力有待进一步验证。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:
https://github.com/fxuchen/JCA-Net。 - 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:实验使用的是公开数据集(LRS2, LRS3, VoxCeleb2),论文中未提及独家数据。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文提供了较为详细的训练细节,包括数据集预处理方式、STFT参数、优化器(AdamW)、学习率策略、训练轮数、批量大小等,有利于复现。
- 论文中引用的开源项目:
- 视频编码器:预训练的CTCNet-Lip模型。
- 参考框架:RTFSNet[8](用于音频复数域掩码乘法策略)。
- 特定模块:分离模块中的多尺度特征提取器(MSFE)、双路径HOIIFormer(DPH)和时频域自注意力(TFSA)参考自文献[14];时刻通道注意力(MCA)参考自文献[12]。
📌 核心摘要
- 要解决什么问题:传统的纯音频语音分离在强噪声、混响或重叠语音场景下面临瓶颈。本文旨在利用说话人的视觉线索(唇动)来增强分离性能,同时解决现有音视频融合方法仅关注跨模态关系而忽略模内关系,以及分离模块效率低下的问题。
- 方法核心是什么:提出了JCA-Net网络,其核心是联合交叉注意力(JCA)模块和参数共享的迭代分离模块。JCA模块通过引入音视频的联合表示,使注意力机制能同时建模模态内和模态间关系。分离模块则被迭代执行R次,每次共享参数,以平衡性能与效率。
- 与已有方法相比新在哪里:主要创新有两点:(1) 在音视频融合上,JCA模块首次将“联合表示”与“交叉注意力”结合,实现了更全面的特征交互,优于简单的拼接、加法或标准跨模态注意力。(2) 在分离建模上,提出了一种轻量级的迭代范式,通过参数共享,用较少的参数量和计算量(MACs)实现了性能的逐次提升,效率远优于基于Transformer的大型双路径网络。
- 主要实验结果如何:在三个主流基准数据集(LRS2, LRS3, VoxCeleb2)上,JCA-Net-12(迭代12次)取得了最佳的SI-SNRi和SDRi。例如,在LRS2上SI-SNRi达到15.6 dB,在VoxCeleb2上达到12.9 dB,均优于所有对比的7种SOTA方法。关键消融实验显示:
- 迭代次数增加带来性能提升但计算量线性增长。
- JCA融合策略显著优于其他融合方法。
- 迭代模块中的AFM和MLFF组件均能独立带来性能增益,组合使用效果最佳。
方法 LRS2 SI-SNRi LRS3 SI-SNRi VoxCeleb2 SI-SNRi 参数量 (M) RTF (s) RTFS-Net-12 [8] 14.9 17.5 12.4 0.74 0.055 JCA-Net-12 15.6 17.7 12.9 1.26 0.049 JCA-Net-4 14.2 15.5 11.3 1.26 0.021
- 实际意义是什么:该研究为嘈杂或重叠语音环境下的语音增强(如助听器、会议转录、语音助手)提供了一个高效且高性能的解决方案。特别是JCA-Net-4模型,其极低的实时因子(RTF)使其具备在资源受限设备上实时处理的潜力。
- 主要局限性是什么:论文未讨论模型对非理想视觉输入(如遮挡、侧脸、光照差)的鲁棒性;实验设置为2人混合,未验证更多说话人的场景;此外,模型性能虽高,但其架构复杂度仍高于最轻量的纯音频模型(如AV-Convtasnet),在某些极端低功耗场景可能仍是挑战。
🏗️ 模型架构
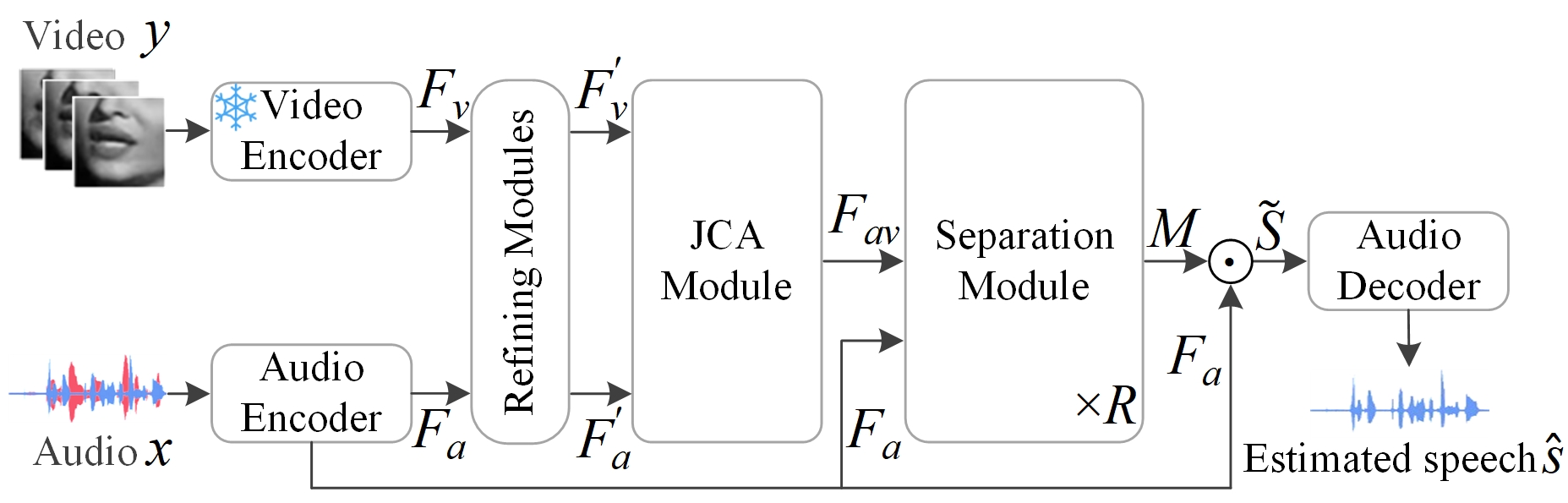 论文提出的JCA-Net整体框架如上图所示。其完整流程如下:
论文提出的JCA-Net整体框架如上图所示。其完整流程如下:
- 输入:混合音频信号
x和目标说话人唇部运动视频y。 - 编码器与特征精炼:
- 视频编码器:使用预训练的CTCNet-Lip模型从唇部区域提取视觉特征
Fv。 - 音频编码器:对混合音频进行STFT得到复数谱图,再通过2D卷积提取音频特征
Fa。 - 精炼模块:分别对
Fv和Fa进行精炼,得到增强的视觉嵌入F'v和音频嵌入F'a。
- 视频编码器:使用预训练的CTCNet-Lip模型从唇部区域提取视觉特征
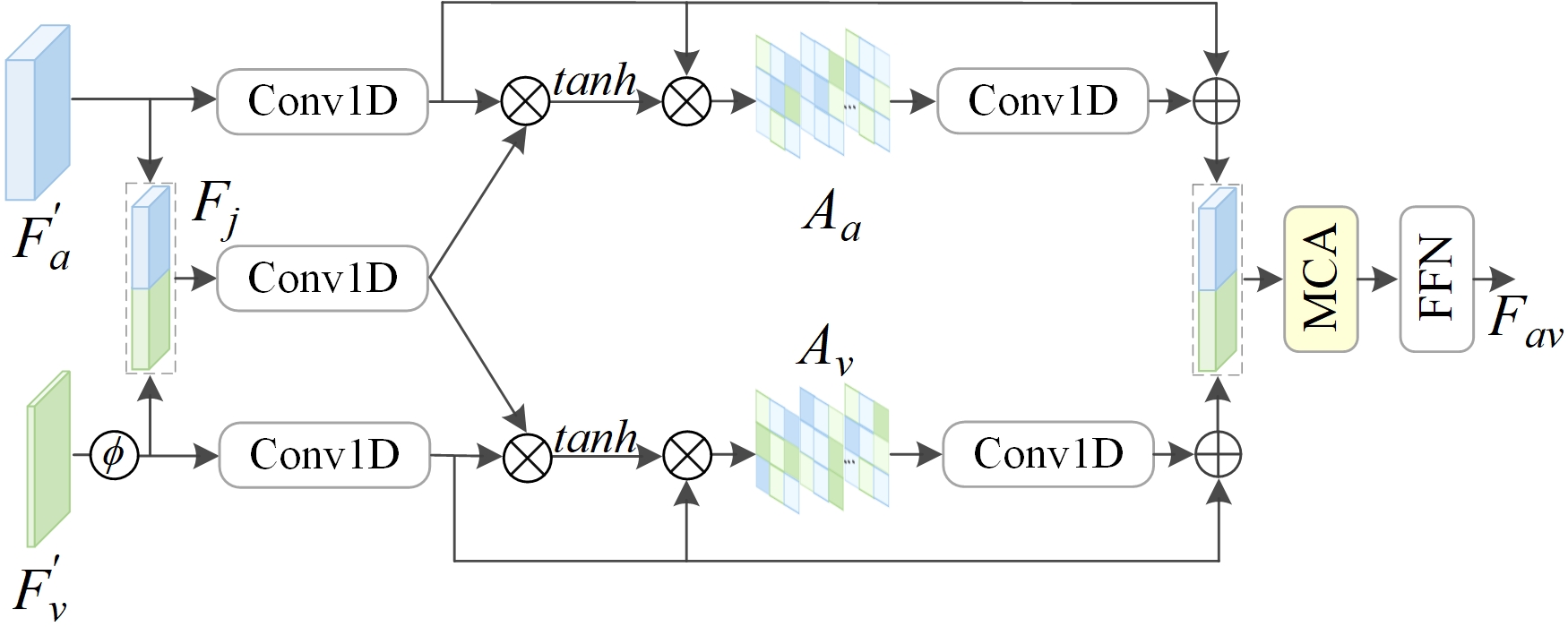
- 联合交叉注意力(JCA)模块(图2):
- 对齐与联合表示:首先对
F'v和F'a在时间维度上进行对齐。然后将两者沿通道维拼接,并通过线性层得到联合表示Fj。 - 相关矩阵计算:分别计算联合表示
Fj与音频嵌入F'a的相关矩阵Ma,以及与视觉嵌入F'v的相关矩阵Mv(公式1)。这两个矩阵融合了模态内和模态间的注意力信息。 - 注意力图与特征:利用
Ma,Mv分别生成音频和视觉的注意力图Aa,Av,并计算对应的注意力特征F'att,a和F'att,v(公式2,3)。 - 融合与校准:将两个注意力特征拼接,通过时刻通道注意力(MCA)块进行通道权重重校准,最后经前馈网络(FFN)输出融合的音视频特征
Fav。
- 对齐与联合表示:首先对
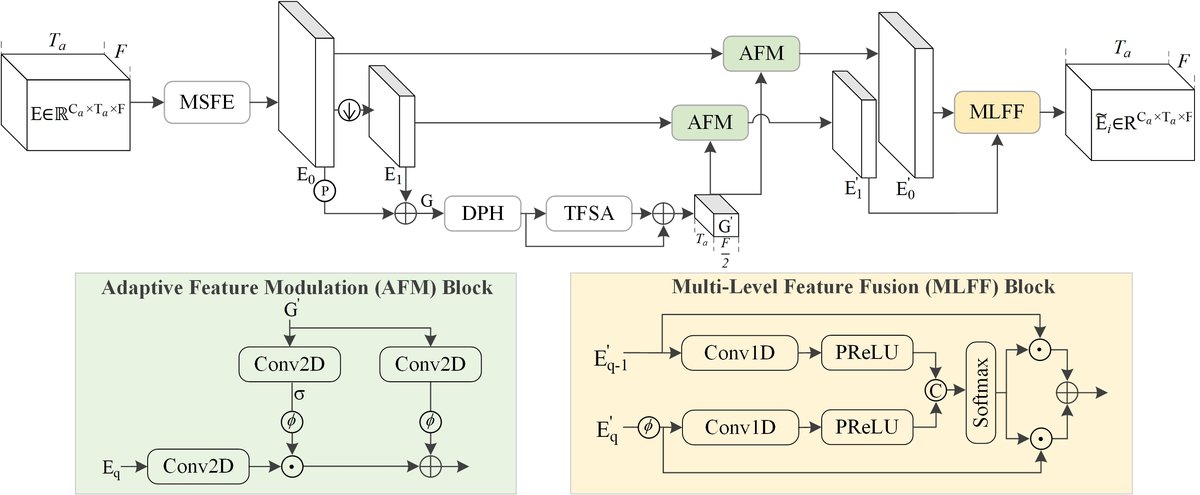
- 迭代分离模块(图3):该模���被迭代执行R次,且所有迭代共享参数。
- 输入:第一次迭代的输入是融合特征
Fav与原始音频特征Fa的和。后续迭代的输入是前一次迭代的输出与Fa的和(跳跃连接)。 - 单次迭代内部流程:输入依次经过多尺度特征提取器(MSFE)、下采样、池化与相加得到全局特征
G;G经双路径HOIIFormer(DPH) 和时频域自注意力(TFSA) 处理得到G';G'用于通过两个自适应特征调制(AFM) 模块分别调制原始输入的中间特征;调制后的特征进入多层次特征融合(MLFF) 模块进行加权融合,输出E~i。 - 最终输出:所有迭代结束后,通过一个卷积层和ReLU激活生成估计的掩码矩阵
M。
- 输入:第一次迭代的输入是融合特征
- 解码器:将掩码
M与原始音频特征Fa在复数域进行点乘,得到目标语音的频域特征S~,再通过转置卷积和iSTFT恢复为目标说话人的时域波形ŝ。
💡 核心创新点
- 联合交叉注意力(JCA)模块:这是音视频融合部分的核心创新。它通过引入音视频特征的联合表示(Fj),使后续的注意力计算(公式1)能够同时捕捉音频与自身、音频与视频、视频与自身、视频与音频之间的相关性。这克服了传统跨模态注意力只关注“模态间”而忽略“模态内”关系的局限。
- 参数共享的迭代分离范式:这是分离建模部分的核心创新。它不是简单地堆叠多个不同的分离模块,而是将同一个分离模块迭代运行R次。每次迭代的输出与原始音频特征相加后作为下一次的输入。这种设计以线性增长的计算成本换取了逐步提升的分离精度,并通过参数共享将模型参数量和复杂度控制在较低水平。
- 自适应特征调制(AFM)与多层次特征融合(MLFF):在分离模块内部,设计了AFM块,利用全局特征
G'来动态加权和残差连接,实现特征的自适应调制。MLFF块则对AFM处理的多级特征进行加权聚合。这两个组件共同提升了分离模块内部的信息交互和特征利用效率。 - 效率与性能的显著平衡:通过上述设计,JCA-Net(如JCA-Net-4)在仅用1.26M参数和0.021s RTF(远低于基线模型)的情况下,在LRS2数据集上达到了14.2 dB的SI-SNRi,展现了极高的效率;而增加迭代次数(如JCA-Net-12)则能进一步达到SOTA性能。
🔬 细节详述
- 训练数据:在三个公开数据集上进行实验:LRS2, LRS3, VoxCeleb2。预处理与文献[8]一致。音频为2秒,16kHz采样率。混合音频由随机选择的两个不同说话人语音混合而成,信噪比(SNR)在[-5, 5] dB内随机。视频与音频同步,帧率25FPS,裁剪唇部区域为96x96灰度图。
- 损失函数:使用SI-SNR(尺度不变信噪比)作为损失函数,在预测语音信号与目标语音信号之间计算。
- 训练策略:
- 优化器:AdamW。
- 学习率:采用动态学习率策略(具体公式未说明)。
- 训练轮数:最大200个epoch,采用早停策略。
- 批量大小:在4张NVIDIA A40 GPU上训练,批量大小为4(每张GPU?未明确)。
- 关键超参数:
- 模型大小:根据迭代次数
R不同而变化,例如JCA-Net-4/8/12的参数量均为1.26M(论文表1)。 - 音频STFT参数:Hann窗,窗口点数512,跳跃长度128。
- 特征维度
d:在公式1中出现,论文未给出具体数值。
- 模型大小:根据迭代次数
- 训练硬件:4 NVIDIA A40 GPUs。
- 推理细节:
- 解码:使用与RTFSNet[8]中S3块相同的复数域掩码乘法策略。
- 流式设置:论文未提及是否支持流式处理。
- 正则化或稳定训练技巧:论文未明确提及Dropout、权重衰减等具体技巧,仅提及使用了AdamW优化器(通常包含权重衰减)。
📊 实验结果
论文在三个数据集上与7种SOTA方法进行了对比,关键结果如表1所示。
表1. JCA-Net与现有AVSS方法在三个数据集上的性能对比
| 方法 | 域 | LRS2 SI-SNRi | LRS2 SDRi | LRS2 PESQ | LRS3 SI-SNRi | LRS3 SDRi | LRS3 PESQ | VoxCeleb2 SI-SNRi | VoxCeleb2 SDRi | VoxCeleb2 PESQ | 参数量(M) | RTF(s) | 发表年份 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RTFS-Net-12 [8] | T-F | 14.9 | 15.1 | 3.07 | 17.5 | 17.6 | 3.25 | 12.4 | 13.6 | 3.00 | 0.74 | 0.055 | ICLR’24 |
| JCA-Net-4† | T-F | 14.2 | 14.4 | 3.02 | 15.5 | 15.7 | 3.07 | 11.3 | 12.2 | 2.89 | 1.26 | 0.021 | - |
| JCA-Net-8† | T-F | 15.1 | 15.3 | 3.11 | 17.0 | 17.3 | 3.20 | 12.2 | 13.4 | 3.00 | 1.26 | 0.036 | - |
| JCA-Net-12† | T-F | 15.6 | 15.9 | 3.14 | 17.7 | 17.9 | 3.25 | 12.9 | 13.8 | 3.03 | 1.26 | 0.049 | - |
| † JCA-Net-R表示分离模块迭代R次。 |
关键结论:JCA-Net-12在三个数据集的所有主要指标(SI-SNRi, SDRi)上均达到了最优。值得注意的是,JCA-Net-4以极低的RTF(0.021s)就达到了与RTFS-Net-12相当的性能,而JCA-Net-12的RTF(0.049s)也低于RTFS-Net-12(0.055s),参数量仅多0.52M。
消融实验:
- 迭代次数的影响(表2):在LRS2上,随着迭代次数
R从2增加到12,SI-SNRi从13.2 dB提升至15.6 dB,但MACs(计算量)和RTF近乎线性增长(从46.65 G到249.10 G)。R SI-SNRi MACs (G) RTF (s) 2 13.2 46.65 0.015 4 14.2 87.14 0.021 12 15.6 249.10 0.049 - 融合策略对比(表3):在LRS2上,JCA模块(SI-SNRi 14.2 dB)优于拼接、加法、标准跨模态注意力及CAF[8]方法。
- 分离模块组件消融(表4):同时使用AFM和MLFF模块(SI-SNRi 14.2 dB, SDRi 14.4 dB)能获得最佳分离性能,证明了两者结合的有效性。
⚖️ 评分理由
- 学术质量(5.5/7):论文提出了清晰的模块化创新(JCA, 迭代分离),技术路线合理,实验对比充分(涵盖多个数据集、多种SOTA方法、详尽的消融研究),结果可信。其主要贡献在于将现有技术(注意力、迭代)进行有效组合,以达到性能与效率的新平衡点,属于扎实的改进型工作。
- 选题价值(1.5/2):音视频语音分离是多模态感知的重要应用,对于解决复杂声学环境下的语音处理问题有直接价值。论文工作在此方向上是有意义的推进,尤其是其对效率的关注,增加了实际部署的可能性。
- 开源与复现加成(0.5/1):论文明确提供了代码仓库链接(
https://github.com/fxuchen/JCA-Net),并在实验部分详细给出了数据预处理、训练策略、损失函数、硬件环境等关键信息,为复现提供了良好基础。