📄 AMBER2: Dual Ambiguity-Aware Emotion Recognition Applied to Speech and Text
#语音情感识别 #知识蒸馏 #多模态模型 #鲁棒性
🔥 8.0/10 | 前25% | #语音情感识别 | #知识蒸馏 | #多模态模型 #鲁棒性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Jingyao Wu (麻省理工学院)
- 通讯作者:Jingyao Wu (麻省理工学院)
- 作者列表:Jingyao Wu* (麻省理工学院), Grace Lin (未说明), Yinuo Song (未说明), Rosalind Picard (未说明)。
💡 毒舌点评
亮点:论文的核心概念清晰且新颖,首次提出“双重模糊性”(标注者与模态)并设计了统一框架,实验上确实证明了显式建模模糊性对提升分布预测保真度(如JS、BC指标)有显著帮助。短板:作为一篇顶会论文,模型架构本身(两个预训练编码器+MLP头)缺乏足够的新颖性与复杂性,其核心创新完全依赖于一个精巧的损失函数设计,对于追求网络结构创新的读者来说可能略显“取巧”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用公开数据集IEMOCAP和MSP-Podcast,但论文中未提供具体获取方式或链接。
- Demo:未提及。
- 复现材料:提供了非常详细的训练细节、网络参数、超参数设置、评估指标等,可作为复现的重要参考。
- 论文中引用的开源项目:主要依赖两个预训练模型:Wav2Vec 2.0(用于音频)和BERT(用于文本)。
📌 核心摘要
- 问题:情感识别面临两种关键模糊性:标注者间分歧(rater ambiguity)和不同模态(如语音与文本)信息冲突(modality ambiguity)。现有方法多聚焦前者,后者未被系统性地建模。
- 方法核心:提出AmbER2框架,采用师生架构。模态特定头(如音频头、文本头)作为“专家”,一个融合头作为“学生”。训练时使用双重损失:Rater Ambiguity Integrated (RAI) Loss 使学生预测拟合标注者分布的真实软标签;Modality Ambiguity Integrated (MAI) Loss 根据专家预测与真实标签的匹配度,自适应地加权对齐学生与专家。
- 创新之处:首次将标注者模糊性与模态模糊性纳入同一框架联合建模;提出基于Jensen-Shannon散度的自适应加权机制,让更可靠的模态专家提供更强指导。
- 主要结果:在IEMOCAP和MSP-Podcast数据集上,AmbER2在分布指标(JS, BC, R²)上一致性超越交叉熵基线。例如在IEMOCAP上,JS从0.216降至0.193,BC从0.803升至0.825。与SOTA系统(如AER-LLM)相比,也取得了有竞争力或更优的结果(IEMOCAP上JS 0.19 vs 0.35)。分析表明,该方法对高模糊性样本的提升尤为明显。
- 实际意义:该工作强调将“模糊性”视为可利用的信号而非噪声,有助于构建更符合人类情感感知复杂性的鲁棒情感识别系统,对构建自然的人机交互有积极意义。
- 局限性:论文未探讨其他模态(如视频);师生角色分配是否可互换及其影响未充分讨论;在MSP-Podcast数据集上,加权F1分数(W-F1)相比基线有所下降,提示分布优化与硬分类决策之间存在权衡。
🏗️ 模型架构
AmbER2的整体架构基于师生学习范式,旨在同时处理标注者和模态两级的模糊性。
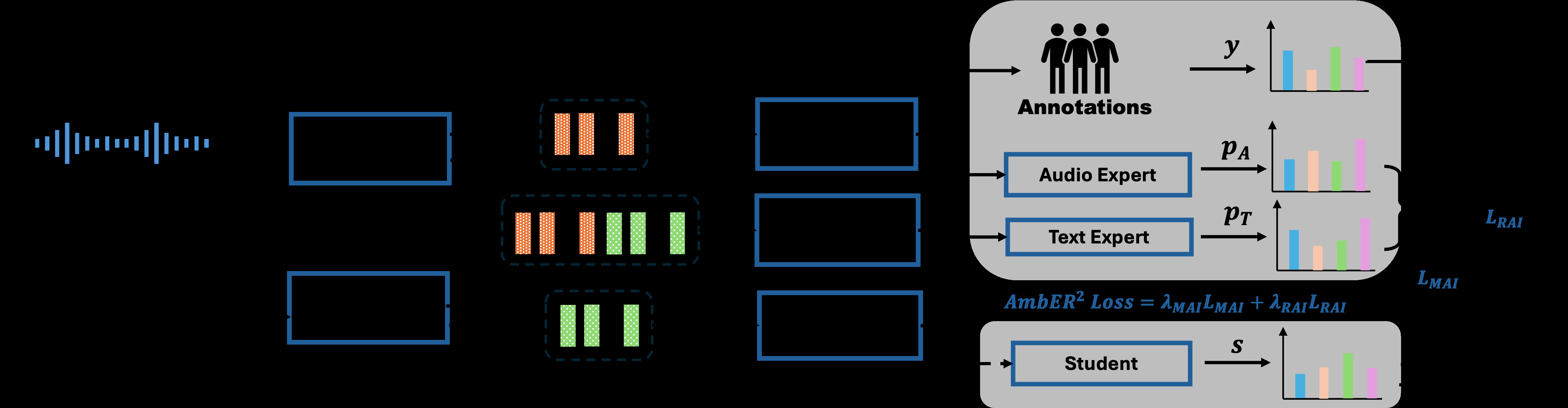
- 输入:配对的音频信号(xA)和文本转录(xT)。
- 特征编码器:
- 音频头:使用预训练的Wav2Vec 2.0模型提取帧级嵌入,经时间维度平均池化得到语音段级表示(hm, m=A)。
- 文本头:使用预训练的BERT模型,通过注意力掩码加权平均最后隐藏状态,得到句子级文本表示(hm, m=T)。
- 模态融合:音频和文本嵌入拼接后,通过一个门控融合机制形成融合表示(hm, m=AT)。
- 模态头:音频头(pA)、文本头(pT)、融合头(pAT)均由一个两层MLP(含ReLU和Softmax)实现,将隐藏表示映射为在C个情感类别上的概率分布。
- 师生角色分配:在主要实验设置中,融合头(AT)被指定为“学生”,音频头和文本头作为“专家”。这种设计允许学生头整合来自单模态专家的互补信息。
- 数据流与交互:训练时,两个损失项共同监督学生头:
- 学生头直接预测分布(s)需与真实软标签(y)对齐(RAI Loss)。
- 学生头(s)需要与两个专家头(pA, pT)的预测对齐,但对齐权重由每个专家预测与真实标签(y)的JS散度动态决定(MAI Loss)。这实现了“自适应知识蒸馏”,可靠专家的指导作用更大。
- 设计动机:该架构旨在显式解耦并建模两种模糊性。师生结构自然引入了模态间的协作与竞争,而加权机制则直接响应了模态可靠性变化的挑战。
💡 核心创新点
- 提出“双重模糊性”建模范式:首次明确指出并系统性建模情感识别中标注者模糊性与模态模糊性并存的挑战,而非孤立处理。这提升了问题建模的完备性。
- 设计自适应加权一致性损失(MAI Loss):这是技术核心。该损失不是简单地让融合头模仿单模态头,而是根据每个专家头预测与真实标注分布的吻合程度(JS散度),自适应地计算其贡献权重。这巧妙地解决了模态冲突:当某个模态提供误导信息时,其权重会自动降低。
- 将分布预测作为统一目标:框架以预测标注者分布的软标签为核心,而非单一硬标签。这使得模型能学习并表达情感内在的主观性和模糊性,从而更符合实际感知。
- 验证对高模糊样本的增益:通过按模糊度分层分析,证明了显式建模模糊性的方法在处理最具挑战性的高模糊样本时优势最明显,这为方法的有效性提供了更细致的证据。
🔬 细节详述
- 训练数据:
- IEMOCAP:约12小时脚本化/即兴对话,4类情感(中性、快乐、愤怒、悲伤),每个话轮由多名标注者标注。采用5折交叉验证(每session一折)。
- MSP-Podcast:自然播客片段,8类情感,至少5名标注者。采用5等份交叉验证(非按说话人分割),以平衡模糊样本。
- 损失函数:
- L_RAI:
JS(y ∥ s),Jensen-Shannon散度,用于监督学生预测(s)与真实标注分布(y)。 - L_MAI:
Σ_{m≠m} u_m JS(s ∥ p_m),加权JS散度。其中权重u_m = exp(-κD_m) / Σ exp(-κD_m'),D_m = JS(p_m ∥ y)。κ为锐度参数。 - 总损失:
L = λ_RAI L_RAI + λ_MAI L_MAI。
- L_RAI:
- 训练策略:
- 优化器:AdamW,学习率3e-4,权重衰减1e-2。
- 批次大小:128。
- 训练轮数:最多30个epoch。
- 超参数搜索:
λ_MAI ∈ {0.3, 0.5, 0.7},κ ∈ {2, 4, 8},基于验证集性能选择。 - 实验重复:每个实验使用5个随机种子,报告均值和标准差。
- 关键超参数:未提供模型具体大小(如参数量)。核心超参数为损失权重
λ和锐度κ。 - 训练硬件:未说明。
- 推理细节:模型输出为概率分布。对于分类指标(F1, ACC),取概率最大的类别作为预测类别。
- 基线:使用相同架构,但仅采用类别平衡交叉熵(CB-CE)损失训练,不建模任何模糊性。
📊 实验结果
表1:基线系统(仅用CB-CE损失)性能(分布指标)
| 数据集 | 模态 | JS ↓ | BC ↑ | R² ↑ |
|---|---|---|---|---|
| IEMOCAP | Text (Pt) | 0.302 ± 0.001 | 0.723 ± 0.001 | 0.540 ± 0.001 |
| Audio (Pa) | 0.275 ± 0.004 | 0.747 ± 0.003 | 0.526 ± 0.003 | |
| Audio+Text (Pa+t) | 0.216 ± 0.001 | 0.803 ± 0.001 | 0.628 ± 0.001 | |
| MSP-Podcast | Text (Pt) | 0.386 ± 0.001 | 0.648 ± 0.001 | 0.355 ± 0.005 |
| Audio (Pa) | 0.388 ± 0.001 | 0.646 ± 0.001 | 0.359 ± 0.002 | |
| Audio+Text (Pa+t) | 0.368 ± 0.003 | 0.664 ± 0.000 | 0.378 ± 0.002 |
表2:基线系统性能(分类指标)
| 数据集 | 模态 | F1 ↑ | W-F1 ↑ | ACC ↑ |
|---|---|---|---|---|
| IEMOCAP | Text (Pt) | 0.581 ± 0.007 | 0.574 ± 0.005 | 0.571 ± 0.006 |
| Audio (Pa) | 0.654 ± 0.004 | 0.538 ± 0.006 | 0.544 ± 0.006 | |
| Audio+Text (Pa+t) | 0.690 ± 0.003 | 0.655 ± 0.003 | 0.654 ± 0.003 | |
| MSP-Podcast | Text (Pt) | 0.247 ± 0.003 | 0.535 ± 0.003 | 0.446 ± 0.007 |
| Audio (Pa) | 0.247 ± 0.001 | 0.522 ± 0.001 | 0.478 ± 0.002 | |
| Audio+Text (Pa+t) | 0.276 ± 0.001 | 0.552 ± 0.002 | 0.473 ± 0.003 |
表3:AmbER2 vs 基线(分布指标)
| 数据集 | 指标 | Baseline (A+T) | AmbER2 |
|---|---|---|---|
| IEMOCAP | JS ↓ | 0.216 ± 0.001 | 0.193 ± 0.002 |
| BC ↑ | 0.803 ± 0.001 | 0.825 ± 0.001 | |
| R² ↑ | 0.628 ± 0.001 | 0.665 ± 0.002 | |
| MSP-Podcast | JS ↓ | 0.368 ± 0.003 | 0.328 ± 0.001 |
| BC ↑ | 0.664 ± 0.000 | 0.707 ± 0.000 | |
| R² ↑ | 0.378 ± 0.002 | 0.425 ± 0.001 |
表4:AmbER2 vs 基线(分类指标)
| 数据集 | 指标 | Baseline (A+T) | AmbER2 |
|---|---|---|---|
| IEMOCAP | F1 ↑ | 0.690 ± 0.003 | 0.695 ± 0.005 |
| W-F1 ↑ | 0.655 ± 0.003 | 0.675 ± 0.004 | |
| ACC ↑ | 0.654 ± 0.003 | 0.683 ± 0.003 | |
| MSP-Podcast | F1 ↑ | 0.276 ± 0.001 | 0.369 ± 0.003 |
| W-F1 ↑ | 0.552 ± 0.002 | 0.445 ± 0.002 | |
| ACC ↑ | 0.473 ± 0.003 | 0.520 ± 0.001 |
表5:与SOTA系统对比
| 数据集 | 方法 | JS ↓ | BC ↑ | R² ↑ | ACC ↑ | F1 ↑ | W-F1 ↑ |
|---|---|---|---|---|---|---|---|
| IEMOCAP | AER-LLM (ZS) | 0.47 | 0.51 | 0.51 | 0.434 | - | 0.429 |
| AER-LLM (FS) | 0.35 | 0.69 | 0.59 | 0.481 | - | 0.492 | |
| Emoent | - | - | - | 0.658 | 0.646 | - | |
| AmbER2 (Ours) | 0.19 | 0.83 | 0.67 | 0.683 | 0.675 | 0.675 | |
| MSP-Podcast | AER-LLM (ZS) | 0.45 | 0.54 | 0.52 | 0.506 | - | 0.505 |
| AER-LLM (FS) | 0.40 | 0.61 | 0.56 | 0.556 | - | 0.562 | |
| AmbER2 (Ours) | 0.33 | 0.71 | 0.43 | 0.520 | 0.369 | 0.445 |
关键结论:
- 与自身基线(CB-CE)相比,AmbER2在两个数据集的分布指标上取得全面显著提升(JS降低超10%,BC和R²提升明显)。
- 在IEMOCAP上,AmbER2全面超越表中所列的SOTA系统,包括AER-LLM的少样本设置和Emoent。
- 在MSP-Podcast上,AmbER2在JS和BC指标上达到最佳,但在R²和W-F1上表现次优,表明在自然、长尾、模糊性强的数据集上,分布优化与传统分类指标间存在权衡。
图表分析:
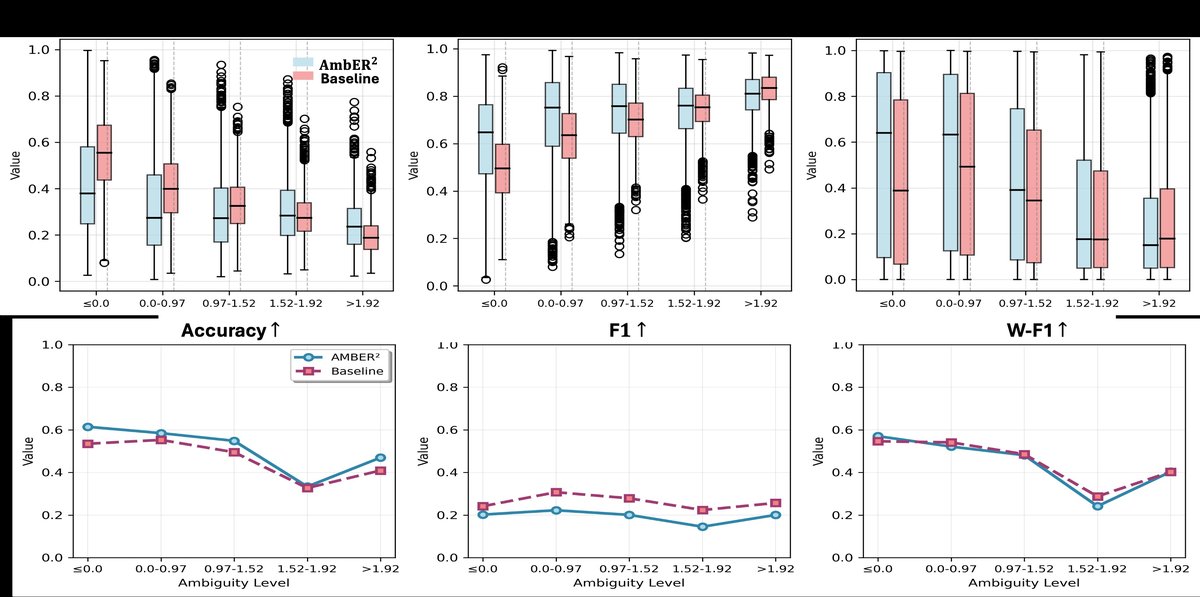
- 上半部分(分布指标):显示AmbER2(蓝色实线)在几乎所有模糊度区间(由标注者熵值划分)上,JS、BC和R²指标均优于基线(橙色虚线)。值得注意的是,在低至中等模糊度区间(前两个bin),提升幅度最大。随着模糊度升高,JS下降、BC上升(因为高熵分布趋向均匀,彼此距离变小),但R²持续下降,表明预测更困难。
- 下半部分(分类指标):显示ACC和W-F1均随模糊度增加而下降,符合预期。AmbER2在大多数区间上略优于或持平于基线,表明其分布建模并未损害甚至略微提升了硬分类性能。
⚖️ 评分理由
- 学术质量(6.0/7):创新性(2.0/2.5):提出了统一建模两种模糊性的新视角和自适应加权蒸馏机制,概念清晰且有效。技术正确性(1.5/1.5):方法设计合理,损失函数有明确数学形式,实验对比公平。实验充分性(1.5/2.0):在两个标准数据集上进行了全面评估,包括分布/分类指标、消融(基线对比)、SOTA对比和按模糊度分层分析。但模型架构(MLP头)本身创新度有限。证据可信度(1.0/1.0):实验设置详细(交叉验证、多随机种子),结果有统计值。
- 选题价值(1.5/2):情感识别是重要应用领域,“模糊性” 作为核心挑战被深入剖析和处理,具有理论价值和实际意义(提升模型鲁棒性和可信度)。与音频/语音处理直接相关。
- 开源与复现加成(0.5/1):论文极其详尽地报告了数据集、模型配置、损失函数、训练超参数、优化器设置等,为复现提供了坚实的文字基础。然而,未提供代码链接、模型权重或明确的开源计划,因此扣分。