📄 Aligning Generative Speech Enhancement with Perceptual Feedback
#语音增强 #强化学习 #语音大模型 #基准测试 #模型评估
✅ 7.5/10 | 前25% | #语音增强 | #强化学习 | #语音大模型 #基准测试
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
请基于当前提供的论文内容尽量完整提取作者与机构信息,要求:
- 明确标注第一作者(如论文可判断),否则写"未说明"
- 明确标注通讯作者(如论文可判断),否则写"未说明"
- 列出能确认的作者姓名及其所属机构(大学、实验室、公司)
- 机构信息尽量具体到实验室或部门;如果文本里没有,就写到能确认的层级
- 禁止猜测机构信息;无法确认时明确写"未说明"
输出格式示例:
第一作者:张三(清华大学计算机系)
通讯作者:李四(Google DeepMind)
作者列表:张三(清华大学计算机系)、李四(Google DeepMind)、王五(未说明)
第一作者:Haoyang Li (1)
通讯作者:未说明
作者列表:
- Haoyang Li (1 南洋理工大学)
- Nana Hou (2 独立研究者)
- Yuchen Hu (1 南洋理工大学)
- Jixun Yao (3 西北工业大学)
- Sabato Marco Siniscalchi (4 帕勒莫大学)
- Xuyi Zhuang (1 南洋理工大学)
- Deheng Ye (5 腾讯)
- Wei Yang (5 腾讯)
- Eng Siong Chng (1 南洋理工大学) 注:根据作者编号推断,机构1为“Nanyang Technological University, Singapore”,机构5为“Tencent”。
💡 毒舌点评
亮点:论文首次将DPO(直接偏好优化)引入语音增强领域,并创新性地利用神经MOS预测器(UTMOS)构建偏好数据,为解决语言模型语音增强中“信号准确但听感不佳”的痛点提供了一个简洁有效的框架,实验结果(UTMOS相对提升56%)具有显著说服力。 短板:研究局限于英语单语种场景,且依赖UTMOS作为偏好代理,其与人类真实偏好的对齐程度未深入讨论;此外,DPO优化导致在“无混响”条件下说话人相似度(SECS)下降的问题虽通过组合损失缓解,但暴露了单目标优化在多维度指标上可能产生权衡。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:未提及。训练数据需根据描述自行动态生成。
- Demo:未提及。
- 复现材料:提供了详细的模型架构描述(Transformer层数、维度等)、训练超参数(学习率、批次大小、步数)、优化器设置、数据处理流程(K-means、SimCodec)和关键实验设置(β值、N、K、Z),复现指南较为清晰。
- 论文中引用的开源项目:WavLM-Large、SimCodec、UTMOS、DNSMOS、NISQA、ReDimNet(用于说话人相似度计算)。LibriTTS, VCTK, AudioSet, Freesound, OpenSLR26/28 等数据集。
- 如果论文中未提及,明确说明“论文中未提及开源计划”。
📌 核心摘要
这篇论文旨在解决基于语言模型的语音增强(SE)方法中存在的训练目标与人类感知偏好不匹配的问题。核心方法GSEPF(Generative Speech Enhancement with Perceptual Feedback)分为两阶段:首先,利用基于WavLM的N2S语言模型将带噪音频转换为语义token;然后,基于SimCodec的S2S语言模型利用语义和声学token生成增强后的声学token。其关键创新在于,在S2S模型上应用了DPO(直接偏好优化),并利用神经MOS预测器UTMOS作为人类偏好的代理来构建偏好对(A+和A-),从而直接引导模型生成感知质量更高的语音。与已有基于token级交叉熵损失或复杂RLHF管线的方法相比,GSEPF更简单、稳定且直接对齐感知质量。实验在DNS Challenge 2020测试集上进行,结果显示,GSEPF在DNSMOS、UTMOS和NISQA等客观指标上均有一致提升,其中UTMOS相对提升最高达56%(从2.03提升至3.18)。主观A/B测试也表明,人类听者在23/30个样本中更偏好GSEPF的输出。该工作的实际意义在于为语音增强领域引入了一个新的、以感知为导向的优化范式,可提升通信和交互的自然度。主要局限性包括:DPO优化在无混响场景下会轻微降低说话人相似度;偏好构建依赖UTMOS,其准确性可能受限;以及仅在有限的英语数据上进行了验证。
🏗️ 模型架构
整体架构是一个两阶段的语言建模框架,将语音增强分解为从噪音到语义,再从语义到语音的过程。
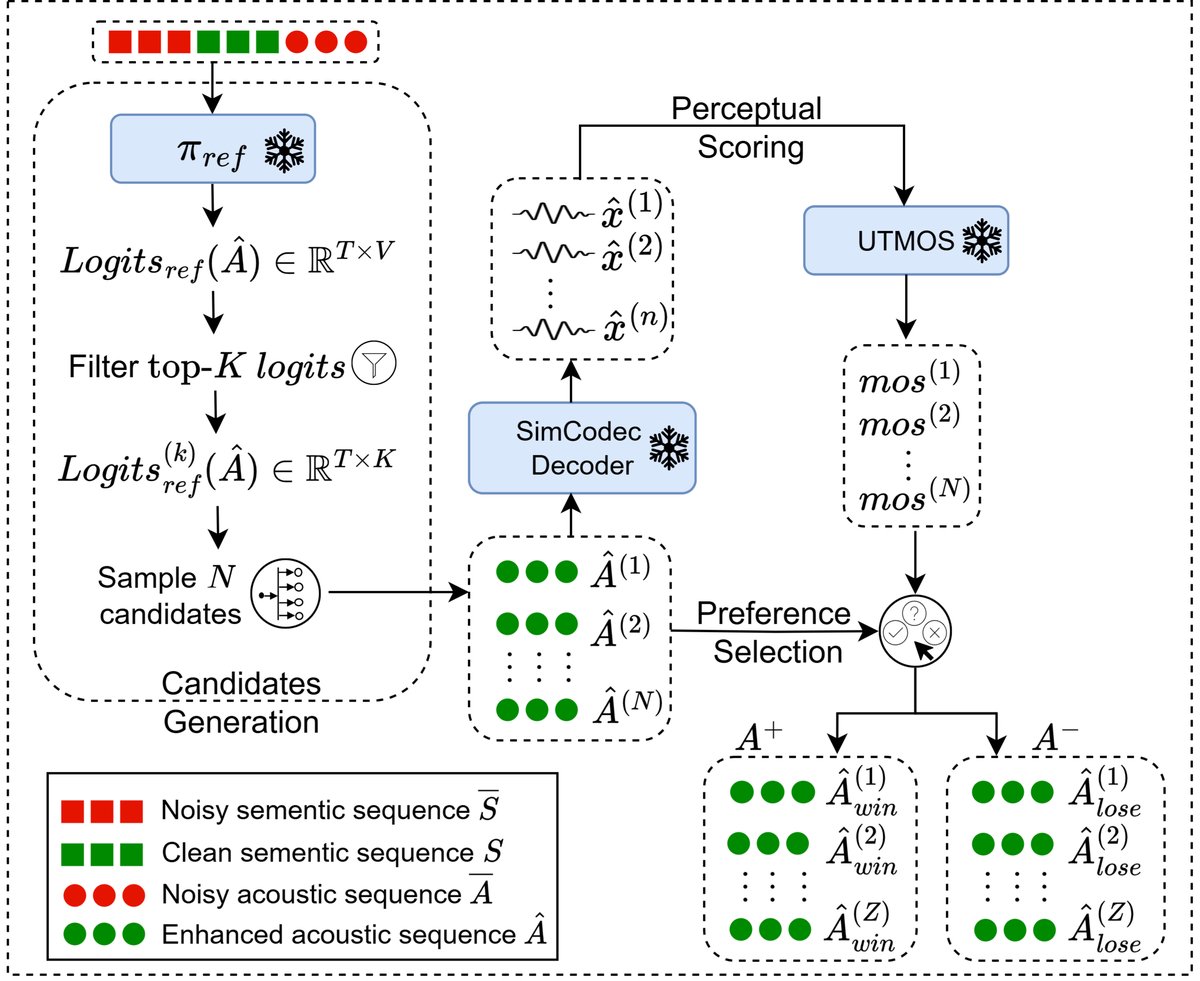
阶段一:噪音到语义的N2S LM
- 输入:带噪音频波形
v。 - 处理流程:首先,使用预训练的WavLM-Large的前6层提取连续的帧级特征。然后,通过一个预训练的K-means模型(1024个簇)将这些特征量化为离散的语义token序列
¯S = {¯s1, . . , ¯sF}。 - 模型:一个自回归语言模型(N2S LM),它以量化后的噪音语义token
¯S为输入,逐帧预测出对应的干净语义token序列ˆS = {ˆs1, . . , ˆsF}。训练时采用教师强制,即输入替换为干净语音的真实语义tokenS。
- 输入:带噪音频波形
阶段二:语义到语音的S2S LM
- 输入:语义token序列
¯S(噪音)、S(干净),以及通过SimCodec(一个神经音频编解码器)将带噪音频v编码得到的声学token序列¯A = {¯a1, . . , ¯aT}。 - 模型:第二个自回归语言模型(S2S LM)。它接收拼接后的上下文
{ ¯S, S, ¯A},自回归地生成增强后的声学token序列ˆA = {ˆa1, . . , ˆaT}。 - 输出:将生成的声学token序列
ˆA输入SimCodec的解码器,重建出增强后的音频波形ˆx。
- 输入:语义token序列
感知对齐模块 (GSEPF核心创新)
- 训练目标:最终的S2S LM (πθ) 的训练损失是传统的交叉熵损失(LCE)与新增的直接偏好优化损失(L_DPO)之和:
L_overall = L_CE + L_DPO。 - DPO工作原理:DPO通过最大化人类偏好信号来调整模型。它需要构建偏好对(
A+,A-)。其损失函数(公式2)鼓励模型增加对偏好序列A+的生成概率,同时降低对被拒绝序列A-的生成概率,相对于一个固定的参考模型(πref)而言。 - 偏好对构建流程(如图1所示):
- 候选生成:给定上下文
y,用参考S2S LM (πref) 在教师强制下计算输出logits。对每个时间步的top-K logits进行采样,生成N个候选增强声学序列{ˆA(n)}_{n=1}^N。 - 感知评分:将每个候选序列解码为波形,并使用UTMOS(一个神经网络MOS预测器)为其打分,得到
{mos(n)}_{n=1}^N。 - 偏好选择:根据MOS分数,将得分最高的Z个序列定义为偏好集
A+,得分最低的Z个序列定义为拒绝集A-。
- 候选生成:给定上下文
- 数据流:在训练时,目标模型πθ接收与参考模型πref相同的上下文
y,计算其输出logits。利用πθ和πref对A+和A-序列的概率估计,来计算L_DPO损失,并更新πθ的参数,而πref保持冻结。
- 训练目标:最终的S2S LM (πθ) 的训练损失是传统的交叉熵损失(LCE)与新增的直接偏好优化损失(L_DPO)之和:
💡 核心创新点
- 首次将DPO引入语音增强:将自然语言处理领域兴起的直接偏好优化(DPO)框架成功迁移到语音增强任务中,为解决感知对齐问题提供了一个比传统PPO-based RLHF更简洁、稳定的方案。
- 构建基于神经MOS的偏好数据:创新性地使用UTMOS作为人类听觉偏好的代理,通过从参考模型采样并自动评分的方式,高效构建了用于DPO训练的大规模偏好对数据(
A+和A-),避免了昂贵且耗时的人工标注。 - 提出GSEPF感知对齐框架:在现有的基于语言模型的生成式语音增强(GenSE)框架基础上,无缝集成了DPO训练目标,形成了一个端到端的感知对齐优化流程(
L_overall = L_CE + L_DPO),证明了其广泛适用性。 - 显著的性能提升与范式验证:在标准测试集上,GSEPF在多个未见过的感知指标(如NISQA)上也取得了显著提升(UTMOS相对提升达56%),并通过主观A/B测试验证了其与人类偏好的良好对齐,为“超越token级似然、追求感知偏好”的语音增强新范式提供了有力证据。
🔬 细节详述
- 训练数据:
- N2S和S2S LM训练集:约530小时干净语音(来自LibriTTS子集、VCTK和DNS 2022 read speech),约175小时噪声(来自AudioSet和Freesound),约17小时房间脉冲响应(RIR,来自OpenSLR26/28)。通过动态混合生成带噪数据,添加混响的概率为40%,噪声源混合比例为80%单源/20%双源,SNR在[-5, 20]dB间均匀采样。音频统一为16kHz。
- DPO训练数据:在目标S2S LM (πθ) 的训练过程中,对于每个训练样本(prompt),实时从参考模型πref采样N=32个候选序列,经UTMOS评分后构建偏好对(Z=4对)。因此DPO训练数据是动态生成的。
- 损失函数:
- 交叉熵损失 (L_CE):用于S2S LM的标准token级预测目标(公式1),最大化正确声学token的似然。
- 直接偏好优化损失 (L_DPO):对比损失(公式2),其目标是最大化偏好序列相对于拒绝序列的相对概率差,并由参考模型πref和温度参数β=0.1进行归一化。
- 最终目标:
L_overall = L_CE + L_DPO,两项损失未加权,因其量级相近。
- 训练策略:
- N2S LM:在单张A40 GPU上训练510k步,batch size 8。优化器为AdamW,学习率峰值1e-4,warmup 1k步,余弦衰减。
- 参考S2S LM (πref):在四张A40 GPU上训练44k步,batch size 128,学习率计划同上。训练至DNSMOS分数饱和后停止。这是基线GenSE*模型。
- 目标S2S LM (πθ):从πθ初始化,在单张A40 GPU上微调400步,batch size 128。优化器AdamW,固定学习率5e-5。
- 关键超参数:
- 模型架构:N2S LM和S2S LM均为decoder-only Transformer,12层,隐藏维度1024,8个注意力头。
- DPO超参数:β=0.1。
- 偏好对构建:top-K采样中K=50,每个prompt采样N=32个候选序列,构建Z=4对偏好对(
A+和A-各4个)。
- 训练硬件:如上所述,分别使用了1张和4张NVIDIA A40 GPU。
- 推理细节:论文中未详细说明推理时的解码策略(如是否使用beam search)。根据描述,生成过程是自回归的,但具体采样参数未提及。
- 正则化或稳定训练技巧:DPO训练中使用了冻结的参考模型πref来稳定学习。最终损失结合了CE和DPO,其中CE损失起到了“锚定”作用,防止模型在优化感知质量时过度偏离基础的语言建模能力(如损害说话人相似度)。
📊 实验结果
论文在2020年DNS Challenge的测试集上进行了评估,分为“无混响(w/o Reverb)”和“有混响(w/ Reverb)”两部分。
表1:与基线在DNS Challenge 2020测试集上的对比
| 系统 | w/o Reverb | w/ Reverb | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DNSMOS ↑ | UTMOS ↑ | NISQA ↑ | SECS ↑ | DNSMOS ↑ | UTMOS ↑ | NISQA ↑ | SECS ↑ | |||||
| SIG | BAK | OVL | SIG | BAK | OVL | |||||||
| Noisy | 3.39 | 2.62 | 2.48 | - | - | - | 1.76 | 1.50 | 1.39 | - | - | - |
| GenSE [9] | 3.65 | 4.18 | 3.43 | - | - | - | 3.49 | 3.73 | 3.19 | - | - | - |
| GenSE* | 3.65 | 4.16 | 3.41 | 3.91 | 3.916 | 0.691 | 3.50 | 3.96 | 3.16 | 2.03 | 2.505 | 0.445 |
| GenSE*_CE | 3.64 | 4.15 | 3.40 | 3.91 | 3.912 | 0.691 | 3.48 | 3.96 | 3.14 | 2.10 | 2.509 | 0.452 |
| GSEPF_DPO | 3.66 | 4.18 | 3.44 | 4.21 | 4.070 | 0.651 | 3.64 | 4.13 | 3.37 | 3.18 | 2.984 | 0.454 |
| GSEPF_CE+DPO | 3.67 | 4.18 | 3.44 | 4.17 | 4.021 | 0.667 | 3.60 | 4.10 | 3.32 | 2.86 | 2.815 | 0.477 |
关键结论:
- 感知指标大幅提升:与仅使用CE损失的GenSE*_CE相比,引入DPO的GSEPF模型(GSEPF_DPO和GSEPF_CE+DPO)在UTMOS和NISQA指标上均获得显著提升。例如,在“w/ Reverb”部分,GSEPF_DPO的UTMOS从2.03提升至3.18,相对提升56.6%。
- CE损失的“锚定”作用:结合CE和DPO的GSEPF_CE+DPO在说话人相似度(SECS)上表现最佳,尤其是在“w/ Reverb”条件下(0.477),说明CE损失有助于保持说话人特征,防止DPO过度优化。
- 主观偏好验证:图2展示了A/B测试结果。在30个样本中,20位听众投票显示,GSEPF_CE+DPO的输出获得378票,优于基线GenSE*的222票,赢得了23/30个对比案例,证实了其主观自然度和听感舒适度的优势。
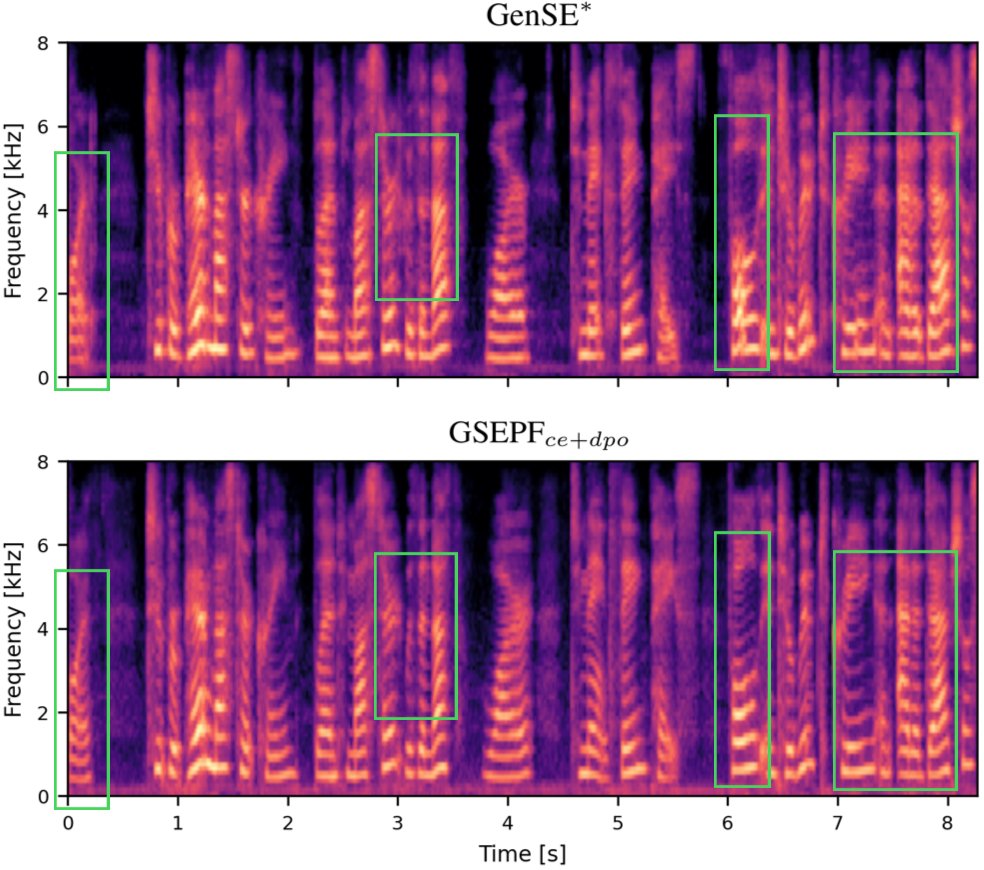 图2:A/B偏好测试结果示意图。左图为支持GSEPF的票数/案例数,右图为支持基线的票数/案例数。GSEPF明显更受青睐。
图2:A/B偏好测试结果示意图。左图为支持GSEPF的票数/案例数,右图为支持基线的票数/案例数。GSEPF明显更受青睐。
表2:偏好对构建策略消融实验
| 系统 | w/o Reverb | w/ Reverb | ||||||
|---|---|---|---|---|---|---|---|---|
| UTMOS ↑ | NISQA ↑ | SECS ↑ | UTMOS ↑ | NISQA ↑ | SECS ↑ | |||
| GenSE* | 3.91 | 3.916 | 0.691 | 2.03 | 2.505 | 0.445 | ||
| Z=1 (Ground-truth) | 3.92 | 3.913 | 0.688 | 2.06 | 2.498 | 0.456 | ||
| Z=1 | 4.17 | 4.052 | 0.666 | 2.95 | 2.873 | 0.469 | ||
| Z=4 | 4.17 | 4.021 | 0.667 | 2.86 | 2.815 | 0.477 |
消融实验结论:
- 使用真实干净token作为
A+(Z=1 Ground-truth)进行DPO训练几乎无效,性能与基线持平。这表明DPO需要基于同一参考模型生成的、有对比度的偏好对才有效。 - 使用从参考模型采样的偏好对(Z=1和Z=4)均能有效提升感知指标。虽然Z=4的感知分数略低于Z=1,但其说话人相似度(SECS)更好,尤其是在“w/ Reverb”条件下。
定性分析:
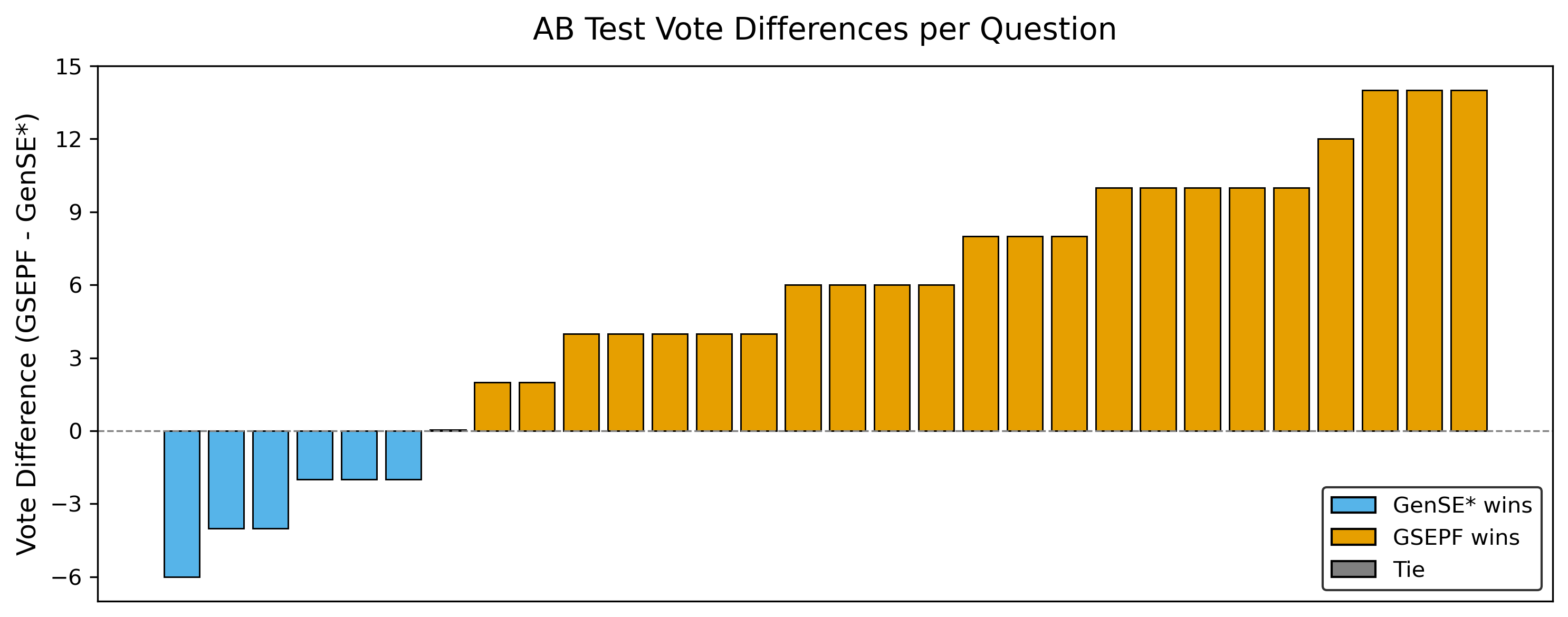 图3:语谱图对比案例。上方为GenSE基线结果,下方为GSEPF_CE+DPO结果。可以看到基线在语音谐波结构(如浊音区域)引入了更多伪影,而GSEPF更好地保留了谐波的清晰度和连续性,这与主观听感中“更自然”的评价相符。*
图3:语谱图对比案例。上方为GenSE基线结果,下方为GSEPF_CE+DPO结果。可以看到基线在语音谐波结构(如浊音区域)引入了更多伪影,而GSEPF更好地保留了谐波的清晰度和连续性,这与主观听感中“更自然”的评价相符。*
⚖️ 评分理由
- 学术质量:5.5/7 - 创新性明确,首次将DPO引入语音增强并结合神经MOS构建偏好数据,技术路线正确且有新意。实验设计全面,包括了多种基线对比、不同的损失组合方案、偏好对构建策略的消融研究以及主观测试,证据可信。主要不足在于,其创新更多是框架层面的迁移应用(DPO from NLP to SE),核心算法本身并无颠覆性改进;且研究场景相对单一(英语,特定噪声条件)。
- 选题价值:1.5/2 - 将人类感知对齐引入语音增强是一个重要且前沿的方向,尤其是在语音合成和对话系统对音质要求日益提高的背景下。该工作为该方向提供了一个简洁有效的解决方案,潜在影响较大。与音频/语音领域的读者高度相关。
- 开源与复现加成:0.5/1 - 论文提供了相当详细的实现细节(模型架构、超参数、训练设置、超参数),为复现奠定了良好基础。然而,论文中未提及代码、模型权重或动态数据集的公开链接,也未提供完整的训练配置文件或预训练模型,这增加了完全复现的难度。因此给予部分加分。